はじめに
インテルスレッディングビルディングブロック(インテルTBB)ライブラリーは、C ++プログラマーに、アプリケーションとライブラリーに並行性を追加するソリューションを提供します。 インテルTBBライブラリのよく知られている利点は、アルゴリズムがサイクルまたはタスクに基づいている場合、開発者がアプリケーションのスケーラビリティと並列実行のパワーを容易にすることです。 ライブラリの一般的な概要は、ネタバレの下に見ることができます。
図書館について
ライブラリには、一般的な並列アルゴリズム、スケジューラとタスクバランサー、スレッドセーフコンテナー、メモリマネージャー、同期プリミティブなどが含まれます(図1)。 基本的な並列プログラミングテンプレートをこれらのビルディングブロックと組み合わせて使用することで、開発者は、特定のプラットフォームでマルチスレッドメカニズムを実装する問題を抽象化する並列アプリケーションを作成すると同時に、コア数の増加に応じたパフォーマンスを実現します。

図1:「ビルディングブロック」Intel Threading Building Blocks
本「構造化並列プログラミング」[1]は、インテルTBBアルゴリズムに適したいくつかの有用な並列パターンについて説明しています。
Intel TBBライブラリは、任意のC ++コンパイラで使用できます。 また、ユーティリティファンクタークラスを記述する必要がないため、コードの記述と可読性を簡素化するラムダ式などのC ++ 11標準もサポートします。 さまざまなライブラリコンポーネントを個別に使用したり、他の並列プログラミングテクノロジと組み合わせたりすることもできます。
Intel TBB 4.2は、WindowsでのIntel Transactional Synchronization Extensions(Intel TSX)やIntel Xeon Phiコプロセッサーのサポートなど、最新のアーキテクチャー機能のサポートを含む新機能を導入しました。 Windows Store *およびAndroid * [2、3]のアプリケーションのサポートも登場しました。 さらに、現在のコンポーネントが改善されました(ドキュメントを参照)。 インテルTBB 4.2は、インテルINDE、インテルクラスタースタジオXE、インテルパラレルスタジオXE、インテルC ++スタジオXE、インテルComposer XE、インテルC ++ Composer XEなどの製品の一部として、個別に入手できます。
オープンソースライブラリバージョンは、コミュニティの貢献により、より多くのアーキテクチャ、コンパイラ、およびオペレーティングシステムをサポートしています。 このライブラリは、Solaris *オペレーティングシステムと、Intelアーキテクチャコンパイラ用のOracle * C ++コンパイラ、SPARC *互換アーキテクチャ、IBM * Blue Gene *スーパーコンピュータ、およびPowerPC *互換アーキテクチャ用のC ++コンパイラで動作します。 また、ARM *互換アーキテクチャ、FreeBSD *、Robot *、およびGCC *コンパイラに組み込まれたアトミック操作をサポートする他の多くのプラットフォームのAndroid *、Windows Phone * 8、およびWindows RT *オペレーティングシステムでも動作します。 この広範なクロスプラットフォームアプローチにより、Intel TBBライブラリを使用して作成されたアプリケーションは、基本的なアルゴリズムを書き換えることなく、他の多くのオペレーティングシステムまたはアーキテクチャに移植できます。
図1:「ビルディングブロック」Intel Threading Building Blocks
本「構造化並列プログラミング」[1]は、インテルTBBアルゴリズムに適したいくつかの有用な並列パターンについて説明しています。
- parallel_for :マップ、ステンシル(多次元データテーブル)
- parallel_reduce、parallel_scan :削減(削減)、スキャン(部分削減の計算)
- parallel_do :workpile(実行開始時に要素数が不明な多次元データテーブル)
- parallel_pipeline :パイプライン
- parallel_invoke、task_group :fork-joinパターン
- flow_graph :グラフテンプレートの計算
Intel TBBライブラリは、任意のC ++コンパイラで使用できます。 また、ユーティリティファンクタークラスを記述する必要がないため、コードの記述と可読性を簡素化するラムダ式などのC ++ 11標準もサポートします。 さまざまなライブラリコンポーネントを個別に使用したり、他の並列プログラミングテクノロジと組み合わせたりすることもできます。
Intel TBB 4.2は、WindowsでのIntel Transactional Synchronization Extensions(Intel TSX)やIntel Xeon Phiコプロセッサーのサポートなど、最新のアーキテクチャー機能のサポートを含む新機能を導入しました。 Windows Store *およびAndroid * [2、3]のアプリケーションのサポートも登場しました。 さらに、現在のコンポーネントが改善されました(ドキュメントを参照)。 インテルTBB 4.2は、インテルINDE、インテルクラスタースタジオXE、インテルパラレルスタジオXE、インテルC ++スタジオXE、インテルComposer XE、インテルC ++ Composer XEなどの製品の一部として、個別に入手できます。
オープンソースライブラリバージョンは、コミュニティの貢献により、より多くのアーキテクチャ、コンパイラ、およびオペレーティングシステムをサポートしています。 このライブラリは、Solaris *オペレーティングシステムと、Intelアーキテクチャコンパイラ用のOracle * C ++コンパイラ、SPARC *互換アーキテクチャ、IBM * Blue Gene *スーパーコンピュータ、およびPowerPC *互換アーキテクチャ用のC ++コンパイラで動作します。 また、ARM *互換アーキテクチャ、FreeBSD *、Robot *、およびGCC *コンパイラに組み込まれたアトミック操作をサポートする他の多くのプラットフォームのAndroid *、Windows Phone * 8、およびWindows RT *オペレーティングシステムでも動作します。 この広範なクロスプラットフォームアプローチにより、Intel TBBライブラリを使用して作成されたアプリケーションは、基本的なアルゴリズムを書き換えることなく、他の多くのオペレーティングシステムまたはアーキテクチャに移植できます。
次に、ライブラリのいくつかの特定の部分に焦点を当てます。 最初に、 フローグラフの概要があります 。これは、Intel TBB 4.0以降で利用可能です。 次に、インテルTBB 4.2で最初にリリースされたライブラリの2つのコンポーネントについて説明します。 これらは、Intel Transactional Synchronization Extensions(Intel TSX)テクノロジーと、タスクの並行性と分離の高度な制御と管理を提供するユーザー管理タスクアリーナを活用する投機的ロックです。
グラフの計算
インテルTBBライブラリはループ並列化で有名ですが、計算グラフインターフェイス[4]は、データおよび/または実行依存グラフに基づくアルゴリズムの高速かつ効率的な実装の機能を拡張し、開発者がアプリケーションでより高いレベルで並列処理を使用できるようにします。
たとえば、図4に示すように、4つの機能を順番に実行する単純なアプリケーションを考えてみましょう。 2(a)。 ループ並列化アプローチは、開発者がparallel_forやparallel_reduceなどのアルゴリズムを使用してこれらの各関数を並列化することを検討できることを意味します。 これで十分な場合もありますが、他の場合では十分ではない場合もあります。 たとえば、図 図2(b)は、関数Bと関数Dをサイクルで並列化できることを示していますが、この場合、実行時間は短縮されますが、生産性の向上がそれでも十分でない場合はどうでしょうか。
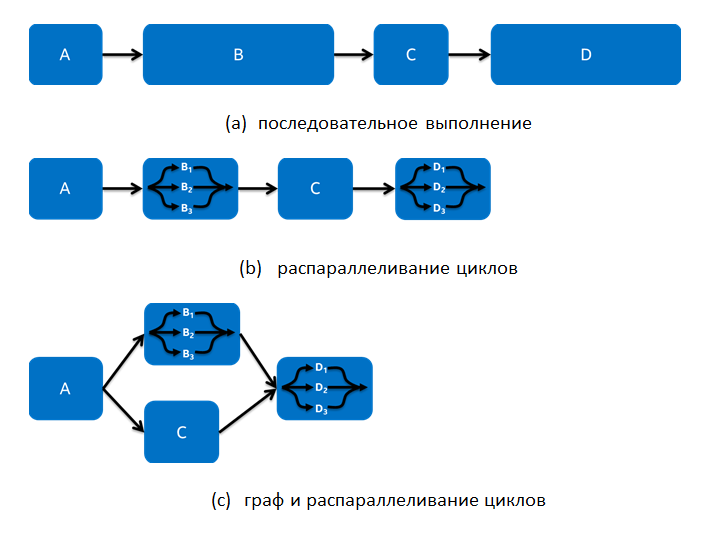
図 2:並行性のさまざまな形式の簡単な例
関数呼び出しには、次のような過度の制限が課せられる場合があります。関数呼び出しの順序は、完全ではなく、関数間の部分的な依存関係の場合でも、厳密に順番に定義する必要があります。 図 2(a)関数は、前の実行中にすべての入力値を受け取った後にのみ関数が実行されるように、開発者によって作成されます。 しかし、関数BとCが関数Aで計算されたデータに依存し、関数Cが関数Bのデータに依存しない場合はどうでしょうか? 図 2(c)は、グラフとループの並列化によるこの例の実装を示しています。 この実装では、サイクルレベルでの並列化が使用され、完全な順序付けが部分的な順序付けに置き換えられます。これにより、関数BとCを同時に実行できます。
インテルTBBフローグラフインターフェイスにより、開発者はグラフレベルの同時実行性を簡単に表現できます。 マルチメディア処理、ゲーム、金融および高性能コンピューティング、ヘルスケアコンピューティングなど、多くの分野で見られるさまざまなタイプのグラフをサポートします。 このインターフェイスはライブラリで完全にサポートされており、Intel TBB 4.0以降で使用できます。
Intel TBBフローグラフを使用する場合、計算はノードで表され、これらのノード間の通信チャネルはエッジで表されます。 ユーザーはエッジを使用して、ノードが実行キューに入れる際に考慮する必要がある依存関係を指定し、Intel TBBタスクスケジューラがグラフトポロジレベルで並列処理を実装できるようにします。 グラフ内のノードがメッセージを受信すると、このメッセージでファンクターを実行するタスクは、Intel TBBスケジューラーによる実行のためにキューに入れられます。
フローグラフインターフェイスは、いくつかの異なるタイプのノードをサポートします(図3):ユーザー定義機能を実行する機能ノード、グラフを通過するメッセージを整理およびバッファリングするために使用できるバッファリングノード、アグリゲーション/デアグリゲーションノード、メッセージの接続または切断、およびその他の有用なノード。 ユーザーは、これらのノードのオブジェクトをエッジで接続して、それらの間の依存関係を示し、これらのノードで作業を実行するオブジェクトを提供します。
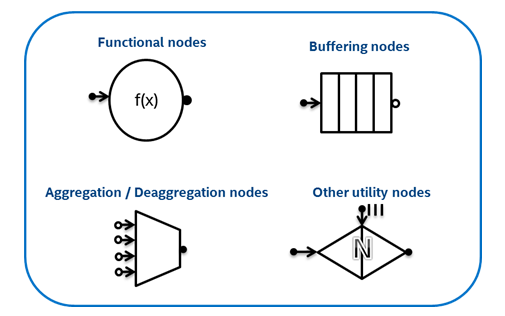
図 3:フローグラフでサポートされるノードのタイプ
単純なフローグラフアプリケーション「Hello World」のソースコードを検討してください。 この例は非常に単純であり、並列処理は含まれていませんが、このインターフェイスの構文を示しています。 この例では、ラムダ式を使用して、 helloとworldの 2つのノードが作成され、それぞれ「Hello」と「World」が出力されます。 タイプcontinue_nodeの各ノードは、インターフェースによって提供されるタイプを持つ関数ノードです。 make_edge呼び出しは、 helloノードとworldノードの間にエッジを作成します。 helloノードによって起動されたタスクが完了するたびに、 ワールドノードにメッセージを送信し、タスクを実行してラムダ式を実行します。
#include "tbb/flow_graph.h" #include <iostream> using namespace std; using namespace tbb::flow; int main() { graph g; continue_node< continue_msg> hello( g, []( const continue_msg &) { cout << "Hello"; } ); continue_node< continue_msg> world( g, []( const continue_msg &) { cout << " World\n"; } ); make_edge(hello, world); hello.try_put(continue_msg()); g.wait_for_all(); return 0; }
上記のコードでは、 hello.try_put(continue_msg())を呼び出すと、メッセージがhelloノードに送信され、オブジェクト本体を実行するタスクが呼び出されます。 タスクが完了すると、 ワールドノードにメッセージが送信されます。 ノードによって開始されたすべてのタスクが終了したときにのみ、 g.wait_for_all()関数からの戻りが実行されます。
Intel TBBフローグラフインターフェイスを使用すると、数千のノード、エッジ、ループ、その他の要素を含む非常に複雑なグラフをプログラムできます。 図 図4は、コレスキー分解の2つの実装グラフの視覚的表現を示しています。これは、[5]で見つかったものと同様のアルゴリズムを使用しています。 図 4(a)Intel Math Kernel Library(Intel MKL) dpotf2m 、 dtrsm 、 dgemm 、およびdsyrkの各関数呼び出しは、グラフ内の個別のノードです。 この場合、グラフは巨大で、行列ブロックごとに多くのノードがありますが、関数呼び出しをノードとエッジの作成に置き換えることにより、最初の連続したネストされたコレスキー分解サイクルを変更することで簡単に実装できます。 このグラフでは、エッジは依存関係を示すために使用されます。 各ノードは、依存するすべてのノードが実行されるまで待機します。 このグラフで並列化がどのように実装されているかを簡単に確認できます。
図 4:フローグラフインターフェイスに基づくコレスキー分解の2つの並列実装 
図 4(a)有向非巡回グラフの使用

図 4(b)コンパクトなデータ依存グラフの使用

図 4(a)有向非巡回グラフの使用

図 4(b)コンパクトなデータ依存グラフの使用
図 図4(b)は、 フローグラフインターフェイスを使用して実装することもできる代替バージョンを示しています。 この小さくてコンパクトなバージョンのグラフには、インテルMKLライブラリの必要なすべての関数を呼び出す責任があるudinノードのみがあります。 この実装では、ブロックはグラフ内のノード間でメッセージとして送信されます。 ノードが特定のタイプのブロックのセットを受け入れると、これらのブロックを処理するタスクを呼び出してから、新しく生成されたブロックを他のノードに転送します。 このようなグラフの並列化は、各グラフノードのオブジェクトの多くのインスタンスを同時に実行するライブラリの機能により実装されます。
実装の詳細は図で説明していますが 4はこの記事の範囲外です;この例は、Intel TBBフローグラフインターフェイスが強力かつ柔軟な抽象化レベルであることを示しています。 例えば、図4(a)のように、大きな有向非循環グラフを作成するために使用できます。開発者は、インテルMKLライブラリーの呼び出しごとに専用ノードを作成します。 一方、Intel TBBフローグラフインターフェイスを使用すると、図5に示すように、ループと条件付き実行を含むコンパクトなデータ依存グラフを作成できます。 4(b)。
フローグラフインターフェイスの詳細については、Intel TBBリファレンスガイドを参照してください。
記事の次の半分では、Intel Transactional Synchronization Extensions(Intel TSX)テクノロジーを利用する投機的ロックと、並列化レベルとタスク分離の高度な制御と管理を提供するユーザー管理のタスクアリーナを取り上げます。 。
継続するには...
書誌
[1] Michael McCool、Arch Robison、James Reinders「構造化並列プログラミング」 parallelbook.com
[2] Vladimir Polin、「Android *チュートリアル:Intel Threading Building Blocksを使用したマルチスレッドアプリケーションの作成」。 software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin、「Windows * 8チュートリアル:Windowsストア用のマルチスレッドアプリケーションの作成* Intel Threading Building Blocksを使用」。 software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss、「Intel Threading Building Blocks Flow Graph」、
博士 Dobb's、2011年10月、 www.drdobbs.com / tools / the-intel-threading-building-blocks-flow / 231900177
[5] Aparna Chandramowlishwaran、Kathleen Knobe、およびRichard Vuduc、「パフォーマンス
高性能マルチコアコンピューティングシステムでの同時コレクションの評価」、
2010並列および分散処理に関するシンポジウム(IPDPS)、2010年4月。
[2] Vladimir Polin、「Android *チュートリアル:Intel Threading Building Blocksを使用したマルチスレッドアプリケーションの作成」。 software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin、「Windows * 8チュートリアル:Windowsストア用のマルチスレッドアプリケーションの作成* Intel Threading Building Blocksを使用」。 software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss、「Intel Threading Building Blocks Flow Graph」、
博士 Dobb's、2011年10月、 www.drdobbs.com / tools / the-intel-threading-building-blocks-flow / 231900177
[5] Aparna Chandramowlishwaran、Kathleen Knobe、およびRichard Vuduc、「パフォーマンス
高性能マルチコアコンピューティングシステムでの同時コレクションの評価」、
2010並列および分散処理に関するシンポジウム(IPDPS)、2010年4月。