
ジョン・マクルーン(国際ビジネスおよび戦略開発ディレクター、Wolfram Research)による翻訳投稿。 元の投稿: じゃんけんで勝つ方法
投稿をMathematicaドキュメントとしてダウンロードする
数学的な観点から、ゲームじゃんけん(最後の付録1を参照)は特に興味深いものではありません。 ナッシュ均衡戦略は非常にシンプルです。ランダムに、そして等しい確率で、3つのオプションから選択します。ゲームの数が多い場合、あなたも相手も勝てません。 ただし、コンピューターを使用して戦略を計算する場合、多数のゲームの後に人を倒すことは可能です。
私の9歳の娘は、Scratchを使用して彼女が作成したプログラムを見せてくれました。 しかし、私はごまかしせずに石はさみで人を獲得する簡単な解決策を紹介します。

常に完全にランダムな選択をする人を獲得することは不可能であるため、人々はあまりランダムではないという事実を期待します。 ランダムに試行する際に行動するパターンにコンピューターが気付くことができれば、それはあなたの将来の行動を予測することに一歩近づきます。
コンピューターベースの数学の概念の一部として、統計コースのトピックの1つとしてアルゴリズムを作成することを考えていました。 しかし、予測アルゴリズムの検索で最初に出会った最初の記事では、コピュラ分布に基づいた複雑な構造を使用してソリューションを調べました。 この決定は、学生にとって理解するのが難しい(そしておそらく私にとっても)ので、簡単な言葉で説明できるより簡単なソリューションを開発することにしました。 また、既に以前に開発されていたとしても、完成した実装を見つけるよりも、独自の方法で作成する方がはるかに楽しいです。
開始するには、ゲームを開始できる必要があります。 当時は、すでに開発されており、じゃんけんをプレイできるデモが開発されていましたが、それは私が必要なものではなかったので、私のバージョンを書きました。 この項目には特別な説明は必要ありません。
[1]で:=

アウト[1] =

ほとんどの場合、このコードはユーザーインターフェイスとゲームルールを記述しています。 コンピュータープレーヤーの戦略全体がこの関数に含まれています。
[2]で:=
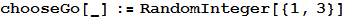
1は石、2は紙、3はハサミに対応します。 これが最善の解決策です。 どのようにプレイしても、コンピューターと同じ数のゲームに勝ち、勝率はゼロ付近で変動します。
したがって、 履歴変数に保存された最新のゲームに関するデータを使用して、 chooseGo関数を書き換えて、選択に関する予測を行うことは興味深いことです。 最初のステップは、最後のいくつかのゲーム中に行われた選択を分析し、シーケンスの発生のすべてのケースを検索することです。 次の各ゲームで人がしたことを見て、特定の行動パターンを見つけることができます。
[3]で:=

関数の最初の引数は、過去のゲームの履歴です。 たとえば、次のデータセットでは、コンピューター(2番目の列は各サブリストの2番目の要素)が、人(番号1)が演奏した石に対して紙(番号2に対応)を再生しました。 これは、リストの最後の要素で確認できます。 また、そのような状況はすでに2回発生しており、両方の場合、人の次の動きが再び石であったことも明らかです。
[4]で:=
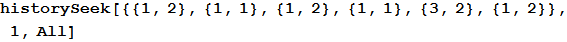
アウト[4] =
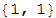
2番目の引数は、検索されるストーリーの最後の要素の数です。 この場合、数値1が関数に引数として渡され、関数はデータの{1,2}の出現のみを検索します。 2を選択すると、関数はシーケンス{3,2}、{1,2}の出現を探し、空のリストを返します。これは、そのようなシーケンスが以前に検出されたことがないためです。
3番目の引数Allは、人の動きとコンピューターの動きの両方が目的の順序で一致する必要があることを示します。 引数を1に変更すると、人の動きの履歴のみを見ることができます(つまり、人間の選択は前の動きだけに依存すると仮定します)。2を変更して、2番目の列、つまりコンピューターの動きの履歴のみに注目します(つまり、その人が行った動きに関係なく、したがって、勝ったか負けたかに関係なく、コンピュータの以前の動きに応答していると仮定します)。
たとえば、この場合、同じゲームでコンピューターを選択したという事実に関係なく、人は石を選んだことがわかります。
[5]で:=
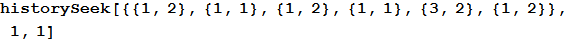
アウト[5] =

大量のデータがあるため、 All引数でのみ実行できます。プログラムは、コンピューターまたは人の動きがより重要である自分自身を決定できます。 たとえば、選択プロセス中にコンピューターの動きの履歴が人によって無視された場合、コンピューターの動きの履歴に対して取得されたデータセットは、以前のゲームに関する十分なデータがあれば、コンピューターの動きの他の履歴と同じ分布になります。 ゲームのすべてのペアを検索することにより、コンピューターの動きの履歴で最初にデータを選択し、次にこのサブセットを上記の機能に使用した場合と同じ結果が得られます。 コンピューターの歴史だけが重要であれば、同じことが起こります。 しかし同時に、これら両方の仮定を別々に検索することにより、歴史上より忠実な一致を得ることができます。これは、ゲームのデータセットが最初は小さい場合に最も顕著です。
したがって、これらの2つのチェックから、最初は100%の評価を与え、次の選択肢は石であり、2番目は人が75%の確率で石を、25%の確率でハサミを選ぶことを示しています。
そして、ここで私は問題を解決するのに幾分停滞しています。
この場合、2つの予測の結果は少なくとも多かれ少なかれ似ていますが、確率の数値は異なります。 しかし、さまざまな長さの履歴を持つ3つの「スライス」データを検索し、予測の結果が矛盾している場合、それらをどのように組み合わせるのでしょうか。
この問題についてのメモを「ブログに書き込む」フォルダーにメモし、数週間前までコンピューターベースの数学で「 統計的有意性 」の概念をカバーする方法について議論があったまで忘れていました。
問題は、受け取った予測をどのように組み合わせるかではなく、どの予測が最も重要であるかを判断する方法であることに気付きました。 予測の1つは、他の予測よりも重要である可能性があります。これは、予測がより顕著な傾向を反映しているか、またはおそらくより大きなデータセットに基づいているためです。 これは私にとって重要ではなかったので、受信した予測を合理化するために、有意性検定のp値(両方のプレイヤーがランダムにプレイするという帰無仮説を使用)を使用しました。
数学的な問題を解決するための最初のステップは「問題を正しく提起する」ことであるという最初の原則に耳を傾けるべきだと思います。
[6]で:=

ここで、最後の結果を取得した場合、最良の予測はp値が0.17の石であることがわかります。 これは、0.17の確率でのみ、この予測に使用されるデータが離散的な一様分布( DiscreteUniformDistribution [{1,3}] )から逸脱し、人間またはその他の人による体系的なエラーによる可能性よりも偶然による可能性が高いことを意味します分布を変える可能性のある別の理由。
[7]で:=
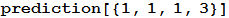
アウト[7] =
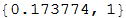
このp値が小さければ小さいほど、実際の動作パターンを見つけたという自信がつきます。 そのため、さまざまな長さの履歴とデータスライスの予測を行い、最小のp値を持つ予測を選択します。
[8]で:=

そして、私たちは人間の選択に勝る選択をします。
[10]で:=

ここに結果が表示されます。 Wolframデモンストレーションから自分でダウンロードして試すことができます 。
[11]で:=

アウト[11] =

プログラムのデータが少なすぎると、ランダムに再生されるため、同じ位置から始めます。 最初に、彼女が学習を始めたばかりのとき、彼女はいくつかの愚かな決定を下すので、あなたは先に進むことができます。 しかし、30〜40ゲーム後、彼女は本当に重要な予測を受け取り始め、勝利の指標がどのようにネガティブエリアに落ち、そこに留まるかがわかります。
もちろん、このような解決策は、ランダムに見える原始的な試みに対してのみ有効です。 その予測可能性は、十分に計算され計画された戦略に対して負けやすい傾向があります。 直感の助けを借りてこのプログラムを打ち負かすことは非常に興味深いです。 それは可能ですが、考えるのをやめるか、一生懸命に考えるとすぐに去ります。 もちろん、同じアルゴリズムを使用してこのプログラムの次の動きを予測し、プログラムでこれを簡単に行うことができます。
このようなアプローチは、ある種の「軍拡競争」の始まりにつながります。これは、はさみのライバルアルゴリズムに勝つアルゴリズムを書く競争であり、これを止める唯一の方法は、 RandomInteger [{1,3 }] 。
追加1
このゲームのプレイ方法がわからない場合、ルールは次のとおりです。あなたと相手が同時に表示する3つのジェスチャーのいずれかを使用して石、はさみ、または紙を選択します。 石はハサミを打ち負かし(鈍くします)、はさみは紙を打ち負かし(カットし)、紙は石を打ち負かします(包み込みます)。 勝者は1ポイントを獲得します;同点の場合、両方のプレイヤーはポイントを獲得しません。
この投稿の翻訳で提供されたヘルプを提供してくれたSergey Shevchukに感謝します。