この問題を解決するための従来のアプローチでは、「趣味」ディレクトリの単一のバージョンを作成し、すべての情報システムに対して(およびそこから)交換フローを設定することをお勧めします。 私たちは別の方法で分散型オープンソースNSI-Recoderを作成することにしました。
私たちが正確に何をしたか、そして製品でLuceneとApache CXFがどのような役割を果たしているかを知りたいですか?
通常、ディレクトリのストレージはどのように解決されますか?
ITディレクターは、ディレクトリの種の多様性を停止することを決定し、会社は単一のディレクトリの構築を開始します。 あらゆる種類の企業データを組み合わせ、最終的に「パッチワークの自動化」と「歴史的遺産」に終止符を打つことが求められます。
問題を解決したら、すぐにすべての問題が解決しますか?
しかし、違います。
中央集権化のひどいマイナスは、数百万ドルのソフトウェアを本当に売りたいと思っている西洋の大企業のプレゼンテーションには書かれておらず、プレスリリースでは伝えられません。 しかし、そのようなプロジェクトを始めると、何年も続く長い退屈な実装に行き詰まってしまいます。 1つの標準に組み込むエンティティは性質が異なるためです。 そして、これは単一のシステム内でそれらを結合することを不合理にします。
信じられない-通常会社で見られるデータ型の表を見てください:
| 彼らは何を説明していますか | テーブル、機械など | 個人、法人、緊急事態/ SP。 | エンティティの属性:教育、職業など |
| 属性真理基準 | 客観的(見ることができる実際のマシンがあります) | 客観的(すべてを尋ねることができる実在の人物または会社があります) | 主観的(専門家の意見、kagbeが正しくない可能性がある、またはシステム) |
| 大きさ | 中(数万台) | 中規模または大規模(数十万および数百万のレコード) | 小(数千単位) |
| 属性の数 | 二次(商品および材料の属性) | 平均(顧客属性) | 小さい(ほとんどの場合、タイプidの構造は名前です) |
| 既存のオブジェクトは時間とともにどのように変化しますか? | まれに | 絶えず変化(住所、婚ital状況、性別の変更...) | 情報システムまたはビジネスプロセスのニーズに応じて予測できない変化 |
実際には、最も速く最も成功した実装は、在庫の問題を個別に解決する企業で発生します-取引先のディレクトリを構築し、途中で分類器を処理するタスクです。
製品情報管理(PIM)は通常、商品と材料に対して実装され、顧客データ統合(CDI)はカウンターパートに対して行われますが、興味深いのは分類子で起こります:彼らにとって、NMI(MDM)はしばしば別々に実装され、単一バージョンの真実が形成されます。
NSIを実装し、分類器の単一バージョンを作成するのは正しいですか? または、この問題を別の方法で解決できますか?
分類子の真実の単一バージョンを持つことは良いですか?
分類子が単一の形式になった場合、通常、シナリオの1つが発生します。
- ソースシステムのすべての組み合わせを考慮したモンスター参照が作成されます。 この複雑な参考書は修正が難しく、長い調整が必要であり、時間が経つにつれてすべてがゆっくりと詰まっていきます。
- すべての人に合う真実の切り捨てられたバージョンを含む単一のディレクトリが作成されます。 大企業で働いていた人は、「白鳥、ガン、カワカマスに合った真実」の検索が成功することはめったにないことを知っていて、もしそうなら、何時間もの激しい会議が必要です。
一般に、真実の単一バージョンは通常高価です。
さらに、単一の標準では、「グレーゾーン」の問題が常に発生します。 これは、ソースシステムの値と、切望された真理の統一されたバージョンの値の違いであり、特別に任命された専門家によって個人的に確認されました。 「グレーゾーン」が存在し、それと連携する必要があるため、NSIの機能(コストを読む)の重要な部分である多数のワークフローと代替フローが出現します。
また、ビジネスは何年にもわたって多数の承認を待つ準備ができているわけではありません。 そのため、最終的には、「一時的な」トランスコードを使用して、データが「テーブルの下」に転送され始めます(これについては後述します)。
真実の単一バージョンを作成しないことは可能ですか?
論理的な問題が発生します:真実の1つのバージョンが非常に高価な場合、それなしで実行できますか?
できること-NSIが実装されていない組織があります。 注意深く見てみると、これらの組織には、異なるシステムのリファレンスブック「Sex」、「Education」などの間の多くの小さな対応表があります。 これらは、Oracleに保存されてからバスに保存されるか、ダウンロード/アップロードおよびエクスポート/インポートのコードに直接保存されます。 なぜなら、同じドメインが人やシステムごとに異なるように指定されている場合、対応表は問題を解決する最も自然な方法だからです。
つまり、地球上のすべての人にエスペラント語を話させる(真実の1つのバージョンを作成する)か、中国とドイツの医療翻訳者を招いて中国とドイツの医師と交渉する(通信テーブルを作成する)ことができます。
したがって、システムの言語を理解し、ビジネスプロセスのフレームワーク内で同じ概念に同意できる同時通訳を作成することにしました。 対応表をトランスコーディングと呼び、システム自体をトランスコーダーと呼びました。
トランスコーダーの主な目的は、ソースシステムのディレクトリのコピーとそれらの間のトランスコードを保存することです。
すべての仕組み
- 作業の開始時に、トランスコーダーはソースシステムのデータベースからディレクトリを読み取り、その後の自動同期のためにそのコピーをデータベースに保存します。 Sybase、MariaDB、Vertica、MS SQL Server、MySQL、Oracle、PostgreSQLと連携しています。
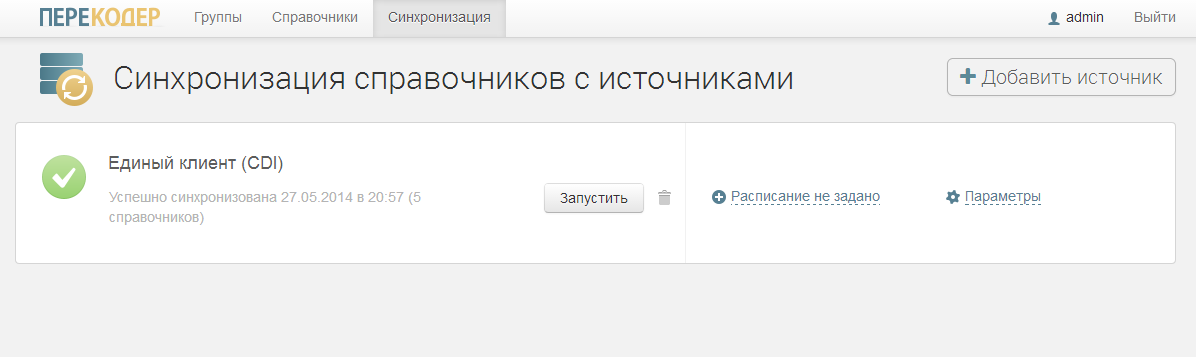
プルーフピーク
- Transcoderインターフェースで、オペレーターはディレクトリー項目の対応表をセットアップします。 たとえば、一方のシステムの男性の性別が「M」と入力され、もう一方のシステムに「1」と入力された場合、オペレータはこれら2つの値を関連付けてトランスコーディングを作成します。
- 現在、別のシステムと情報を交換しているプロセスのシステムは、SOAPまたはRESTインターフェースを介してトランスコーダーから、その分類子からターゲットシステムの言語への値の変換を要求したり、受信したデータを独自の方言に変換したりできます。
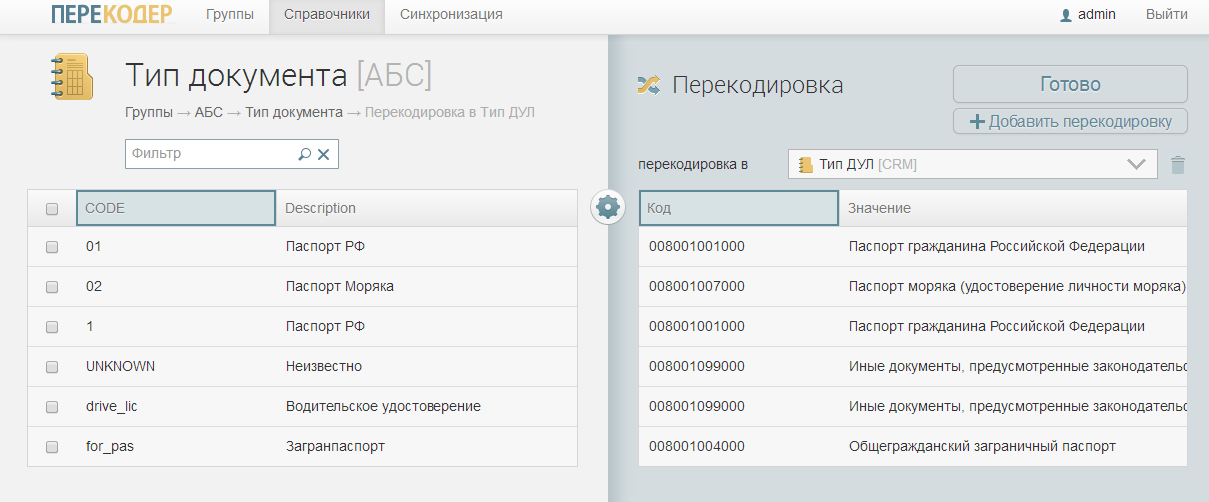
特定の銀行システム(ABS)の「ドキュメントタイプ」ディレクトリからCRMの「DULタイプ」ディレクトリへのトランスコーディング。 パスポートは一般的な外国のパスポートに対応し、運転免許証は他の書類に対応しています。 ABSとCRMはマスターディレクトリと統合する必要はありません。誰もが満足しています。
- トランスコーダーは、元々、情報交換のすべての参加者を満足させるために、毎秒最大1,000のトランスコードの負荷用に設計されました:バス、リアルタイムプロシージャを提供するETLスクリプト、Excelのマクロ、宇宙ステーションなど
トランスコーダーでできること
それは可能であり、必要です:
- ディレクトリ、ディレクトリのグループ、およびトランスコード(作成、編集、削除)を管理します。
- トランスコーダディレクトリとソースシステムの定期的な同期を設定します。
- オンライントランスコーディングを実行し、SOAPおよびRESTインターフェイスを介してソースディレクトリの値を取得します。
- ソースディレクトリの変更に関する自動アラートを受信します。 変換がない値が突然表示された場合、SOAP / RESTはエラーを返し、すべての関係者に通知します。

分類子「Customer Service Program」。属性は何らかの理由で非ロシア語と呼ばれますDescriptionおよびFull Description
フードの下には何がありますか?
システムはモジュールに分割され、API、ビジネスロジック、ストレージを相互に分離します。 Spring Frameworkは、コンポーネント間の接続IoCコンテナーとして機能します。
データフローの技術的なスキームは、次のように表すことができます。
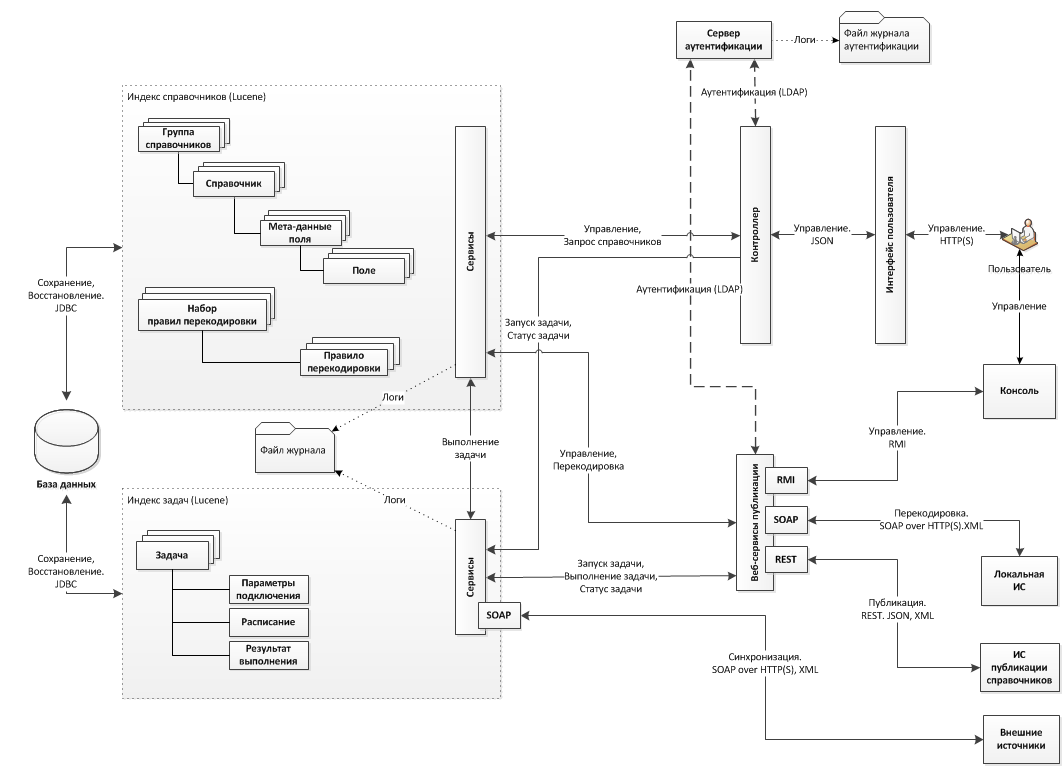
ご覧のとおり、サービスはデータベースと直接対話しません。 代わりに、すべての作業(読み取り/書き込み)はLuceneインデックスを使用して行われ、書き込み操作の結果はデータベースに追加で書き込まれます。 なぜこれが行われるのですか? すべてが単純です。システムの主なタスクは、トランスコーディング(ディレクトリのペアのエントリ間の対応)をすばやく見つけることです。このようなアーキテクチャは、大量のデータでこれに最も効果的に対処します。 さらに、「箱から出してすぐに」すべてのデータの全文検索を取得します。 もちろん、ElasticsearchやSolrなどの高レベルのソリューションを使用することもできますが、独自の欠点があり、独自のコードを書くよりも費用がかかります。
情報の整合性を確保するために、検索インデックスとデータベースの1つのトランザクションでデータ変更が実行されます。 さらに、インターフェイスは、アプリケーションのビジネスロジックがインデックスのみを認識し、DBMSを最小限の変更で別のソリューションに置き換えることができるように設計されています。 実際、いくつかのクラスを実装し、それらをクラスパスに追加する必要があります。Springとクラスコンパイルファクトリ(その場で実行中のコードコンパイル)が残りを行います。
SOAPおよびRESTfullインターフェースのフレームワークはApache CXFです。これにより、APIのバージョンを(突然変更する必要がある場合)構成し、着信/発信メッセージの処理のあらゆる段階に簡単に組み込むことができます。
ソースコード
github.com/hflabs/perecoder
テストスタンド
rcd.hflabs.ru/rcd/admin/login
ログイン:admin
パスワード:デモ
ドキュメント
confluence.hflabs.ru/x/RICSCg
次は何ですか
トランスコーダーの実装を開始したのは、いくつかのお客様です。
機能についてのコメントを歓迎します。好きなもの、そうでないもの、理解できないもの。
まあ、この製品があなたにとって有用であれば、それはこの記事を書く時間を無駄にしていないことを意味します;)