アイデア
逆方向の一部の機能が機能しないと考えられています。 この記事のウィキペディアでは、「計算不可能性」などの概念を使用しています 。 カメラの 1 つでは 、彼らは例として機能を引用しました
X = A MOD B
反対方向のこの機能は解決できないと誰かが言うかもしれません。 この関数は非常に解くことができ、逆方向では無限数のペア(A、B)が得られると信じています。 私たちが望むものではありませんが、おとぎ話の中にいるとは思いませんでしたか? これは、連立方程式から方程式を1つ引き出すことに似ています。システム内の各方程式は集合を与えますが、システムではこれらの集合の交点が少数の解を与えます。 したがって、連立方程式の各方程式を個別に解かないのと同様に、暗号化アルゴリズムを構成する他の関数から分離してこのような関数を考慮することは意味がありません。 したがって、暗号化アルゴリズムの基本操作を個別に見ることは不可能であり、それらを方程式系として見れば、理論的には解決できます。 そして、類推により、逆方向でsha256を計算できるので、リストを操作するという同じ考えをビット単位操作に転送するだけでよいことがわかります。 しかし、もちろん、sha-256ではなく、ささいな例から始めます。
ビット変数a、b、cがあるとします。 また、a&bを取得した結果、0になり、ビット「c」が式に参加しなかったこともお知らせください。 この式を反対方向に「失って」みよう。 入力に到達するオペランドの少なくとも1つがゼロの場合、演算ANDは最後にゼロを与えることを知っています。 したがって、abcの可能な値は、オペランド「a」に表示されるため、1つの正規表現0 **のリストとして表すことができます。 ここで、アスタリスクは0または1を意味します。オペランド「b」に表示される変数abcの可能な値は、regexp * 0 *からのリストで表すことができます。 大きな式では、1つの正規表現では十分ではないため、リストが必要です。 正規表現では、従来の正規表現ではなく、アスタリスクが対応するビットの値を意味する切り捨てられたバージョンを理解しています。
入力に来るリストを論理的な「I」にすると、右の入力への各正規表現と左への各正規表現を組み合わせる必要があります。 このタスクでは、簡単です。含まれている正規表現は1つだけなので、それらを組み合わせます。 「そして」で、出力で0を取得する必要がある場合は、左のリストを右のリストで補うだけです。 概略的に、これをグラフの形で写真に示しました。

説明。 結果fは、下から出力に供給され、矢印とは反対の方向(上方向)に上昇し、最終変数に到達するまでノードで分岐します。 最終的な変数は、結果を得るために必要な変数(この変数の位置から見えるもの)の可能な値のリストを形成します。 変数「a」の場合は0 **、変数「b」の場合は* 0 *です。 実際、これらはすべてアスタリスクですが、変数の位置にあるそのうちの1つだけが着信fに置き換えられます。 さらに、このリストは矢印を下って行き、ノード内で他の同様のリストと結合します。 「c」変数を追加して、式に関与しない変数が気にならず、元の形式のままになることを示しました。 出力では、2つの正規表現で構成されるリストが得られました。 各正規表現は、必要に応じてこの正規表現から簡単に生成できる一連の可能な値を定義します。 これが答えです。
もちろん、リストに多くの要素がある場合、一貫性のある正規表現を組み合わせて重複を除外する必要があります。この瞬間は重要ですが、最適化であるため、アイデアを理解するために不可欠ではありません。 彼については低くなります。
同じことですが、f = 1の場合のみです。 a = 1 **、b = * 1 *を取得します。 関連付けのルール。「および」の出力で1を取得する必要がある場合、それはより困難です。 新しい正規表現のリストを作成しながら、一貫した正規表現を右部分と左部分と組み合わせる必要があります。 私は次の最終ルールを得ました:
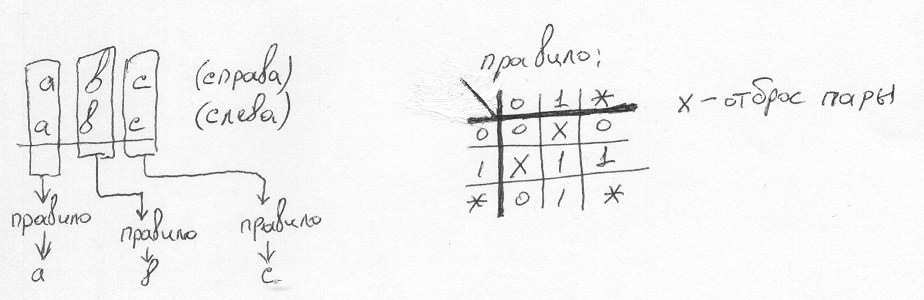
正規表現はビットごとに表示されます。 左右のビットの値に応じて、最も具体的な値を選択するか、互いに矛盾するビットに遭遇した場合、この正規表現のペアを破棄します。
このルールに従って入力を処理すると、次のようになります。

その考えは明確だと思います。 「OR」と「NOT」の場合、同様のルールを作成できます。

また、ここでは、「NOT」ログでは正規表現リストではなく、f自体で操作していることを示しています。 「NOT」を介した正規表現のリストは、変更されずに反転なしで渡されます。
したがって、sha256の場合、グラフを作成し、メッセージダイジェストをビットに分割し、これらのビットを出力に送り、逆変数の可能な値のリストを返します。
最適化
可能な限りアルゴリズムを最適化する目標はありませんでした。 文字を介してビットを操作するのは無駄であり、ビットごとの操作でsとアセンブラーにアルゴリズムをシフトすると、アルゴリズムの速度を大幅に向上できることは明らかです。 ただし、最適化の別の方法があります-操作するリストのサイズを最小化します。 リストを組み合わせると、折りたたむ必要がある重複した矛盾のない正規表現がしばしば発生します。 さらに、2つの正規表現を1つの新しい正規表現に結合して、さらに最適化することができます。 たとえば、000100と001100は00 * 100に組み合わせることができます。このような組み合わせのルールは比較的簡単に推測できます。1ビットの変更のみが許可されます。新しく作成された正規表現が不要な変数値を表さないことが重要です。 したがって、* 0を0 *と組み合わせて**を取得することはできません。これは、**が11を表し、最初の正規表現も2番目の正規表現も許可されないためです。
さらに、リストのノードでキャッシュします-下から来るfごとに1回カウントします。
実験
私は次のことを仮定しました
-元のメッセージは56バイトよりも短い(ビットコインの場合、これは実際、この単純化を拒否するのは難しくないと想定できます)。
-最初の8ビットを除くすべての元のメッセージを知っています。
もちろん、これは噴水ではありません。8個の未知のビットが直接網羅的な検索で選択できるほど小さいことを理解していますが、実験の目的はメソッドを正確に検証することでした。 私はこの方法で文字Tを見つけることができました。「速い茶色のキツネが怠dogな犬を飛び越える」というフレーズからsha-256を知り、文字Tを除くこのフレーズのすべての文字を知っていました。より長く、より多くのメモリが必要になります。 このため、すべての文字を不明と見なすことは不可能です。十分なコンピューティングリソースがないため、実用的なアプリケーションはありません。 文字Tの計算には、3Hzフェノムで82秒かかります。 もちろん、すべての未知のビット(256値)を直接列挙するには1秒未満がかかるため、この意味ではプログラムの実用的な利点もありません。
最適化の可能な方法はあるように思えますが、それはセットのコンパクトな表記法を考え出すことですが、それでもこの方法は直接列挙よりも速く動作しません。
Tという文字を見つけるプロジェクトへのリンク: https : //github.com/chabapok/sha256unroll