 ソーシャルネットワークから何を学べますか? あなたは、サッカーチーム、グループのベーシスト、心の兄弟、 妻を見つけることができ、海のアパート/部屋/別荘を借りる/借りる。 また、データ分析を接続する場合はどうなりますか? あなたは社会であなたの場所を見つけることができます。 たとえば、XXXを聞いて、YYYを読んでZZZを飲むと、このボールには100人しかいません。 そして、私がまだ爪を緑色で塗っているなら、私は間違いなく唯一のものになりますか?
ソーシャルネットワークから何を学べますか? あなたは、サッカーチーム、グループのベーシスト、心の兄弟、 妻を見つけることができ、海のアパート/部屋/別荘を借りる/借りる。 また、データ分析を接続する場合はどうなりますか? あなたは社会であなたの場所を見つけることができます。 たとえば、XXXを聞いて、YYYを読んでZZZを飲むと、このボールには100人しかいません。 そして、私がまだ爪を緑色で塗っているなら、私は間違いなく唯一のものになりますか?
人々が何を好むのか、何を売ることができるのかを理解し、100回目の予測を行い、6回のハンドシェイクの理論をテストすることができます。 ソーシャルネットワーク分析の分野には多くの問題があり、そのうちの1つをSNA Hackathon 2014のオンライン段階で解決することを提案します。
ソーシャルメディアタスク
今日のソーシャルネットワークは、人々、その趣味、思考に関する情報の無尽蔵の情報源です。 毎日、ユーザーは約8テラバイトの写真、テキスト、ビデオを生成します。これらは、新しいソフトウェア製品や強力な予測ツールを作成するためのリソースになります。

ユーザーが生成したテキストデータを分析するタスクに焦点を合わせることにし、ハッカソンの参加者に投稿のコンテンツとその評価の関係を分析するよう依頼しました。
ハッカソンとオンラインステージのタスクについて
オフラインフェーズに参加するには、参加者は投稿が4月10日までに公開されてから一定の時間が経過するまでのいいねの数を予測する必要があります。 または、データを分析しているOdnoklassnikiに関しては、特定のトピックのマークの数が「クラス!」です。

今日、そのようなリーダーボードが形成されました。 モデルが最も正確であることが判明した参加者は、サンクトペテルブルクで開催されるオフラインステージに招待され、Macbook proを獲得するチャンスが与えられます。 そこで、24時間で、約4,400万人のユーザーの実際の出版物を分析し、それらに基づいて製品のプロトタイプを作成する必要があります。 EMC、JetBrains、データマイニングラボ、HSEおよびNES大学の専門家が、小規模なプレゼンテーションを支援およびアドバイスします。
第一段階の初期データ
投稿データは、train_content.csvとtest_content.csvの2つのファイルに保存され、次のフィールドが含まれます。
group_id-投稿が投稿されたグループの匿名識別子
post_id-匿名の投稿ID
タイムスタンプ -発行後の時刻。1970年1月1日午前0時(UTC)からのミリ秒数です。
content-投稿のコンテンツ。 注:このフィールドには、スペース、特殊文字、httpリンク、画像、投票が含まれる場合があります。 著者のスペルと句読点が保存されました。
例:

トレーニングセットの「クラス!」に関するデータは、以下のフィールドとともにtrain_likes.csvファイルに保存されます。
user_id- 「クラス!」を提供したユーザーの匿名識別子
post_id-匿名の投稿ID
タイムスタンプ -時間「クラス!」は、1970年1月1日(UTC)の午前0時から経過したミリ秒数です。
例:

予測は、R2メトリックを使用して推定されます(表示の便宜上、1000倍します)。
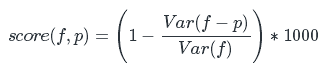
どこで:
f- 「クラス!」の数の実際の値
p- 「クラス!」の数の予測
Var(x)は、 xの標本分散です。
予測の最大スコアは1000であることがわかります。 ハッカソンの第2段階に進むには、ベースライン、つまり私たちが書いたアルゴリズムの精度を克服する必要があります。
デフォルトのアルゴリズム
予備的なデータ処理と基本的な予測の構築を行うRのソースコードは、 githubリポジトリにあります 。
そこには、Rに3つのスクリプトがあります。
prepare.R-データの前処理
features.R-基本機能の検索(文字数、単語数、平均単語長)
baseline.R-モデルの構築(線形回帰を使用)
開始方法
入力(test_content.csv、train_content.csv、train_likes.csv)を./data/src/フォルダーに解凍します。 コマンドラインに入力します。
git clone https://github.com/snahackathon/sh2014.git cd ./sh2014 #<unzip data to ./data> cd R R --vanilla < prepare.R R --vanilla < features.R R --vanilla < baseline.R
テストセットのいいね!の予測数は、データ/送信にあります。 もちろん、これは単なる基本的なアルゴリズムであり、スコアの境界値を克服するものではありません。
あなたが勇敢で、器用で、熟練しているなら...

ハッカソンに参加してください! 私たちの仕事は、熱心で創造的な人々を集めて競争するのが面白くなるようにすることです。競争の結果、正確なモデルと洗練されたアルゴリズムを手に入れます。 まだ勉強していて手を試してみたい方は、ぜひ参加してください。トレーニングとテストデータをダウンロードし、可能な限りすべてを絞り出してください。 すでに学んだ人を招待するだけでなく、専門家や裁判官として行動することもできます。 これを行うには、contact @ sh2014.orgにご連絡ください。