この一連の記事では、従来のモデルとは大きく異なる脳の波動モデルについて説明します。 参加したばかりの人は最初の部分から読み始めることを強くお勧めします。
脳が操作する情報は、一方で、起こっていることを完全に記述し、他方で、脳が必要な操作を実行できるように保存する必要があります。 原則として、情報を記述する形式とそれを処理するアルゴリズムは密接に関連しています。 前者が主に後者を決定します。 したがって、脳に保存されたデータをどのように整理するかについて言えば、私たちは、それが好きかどうかにかかわらず、その後の思考プロセスのシステムを大部分事前に決定します。 思考の原則については後で説明するため、現在の説明の完全性とその後の情報の保存を保証する方法にのみ焦点を当てます。 同時に、思考のポイントに達して、選択したデータ形式が必要なアルゴリズムに適合することが判明した場合、幸運であり、正しい方法で行ったことを意味します。
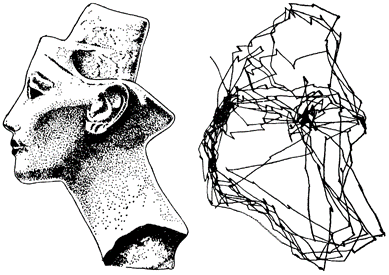
脳がどのような記述形式を使用しているかを理解するために、視覚のシーケンスを追跡しましょう。 画像を見て、サッカード(KDPVに描画)と呼ばれる速い眼球運動で「スキャン」します。 それらのそれぞれは、全体像の断片の1つをビューの中央に配置します。 視覚野のゾーンに説明が表示されます。これは、その瞬間に中央で見たもの、周辺で見たもの、および行われたサッカードの結果としての変位です。 後続の各サッカードは、新しい画像を作成します。 これらの説明は、次々に置き換えられます。
したがって、顔を見ると、たとえば、最初に、片方の目、つまり視線が向けられている目をはっきりと認識します。 顔の残りの要素である視覚の相対的な周辺にあるもの-鼻、口など、より少ないが同じ高確率で学習します。 各サッカードの後、中央のフラグメントは変化しますが、認識される要素の一般的なセットは変更されません。
原則として、サッカードの間に生じるこれらの個別の記述のそれぞれは、私たちが顔を持っていると言って、それが誰に属しているかを見つけることさえ十分です。 しかし、個々の記述はそれぞれ、そのオブジェクトについてのみ確実に語っています。彼にとっては、それは視線の方向にあります。 残りのオブジェクトは、ほぼおおよそ決定されます。
顔のより完全で詳細な画像を取得したい場合は、スキャン中に発生するすべての説明の組み合わせがこれに適しています。 この場合、認識されるオブジェクトの種類を記述するだけでなく、それに伴う目の変化に関する情報も重要になります。 そして、ここで非常に重要なポイントに来ます。 ビジュアルアナライザーが生成する最終的な説明は何ですか? 多くの概念の活動の写真だけですか? これは、現在表示されている説明のその部分にのみ対応しています。 しかし、残りはどうでしょうか? 情報を失わない正しい説明は、次の簡単な説明のパッケージであることがわかります。 このような一時パッケージの各レイヤーが情報の特定の部分のみを説明し、完全な説明がそれらの組み合わせとして取得される場合。 これは、パッケージ内のすべての説明が1つのイベントに対応している場合、つまり、注意がグローバルに移行する前に受信された場合に当てはまります。
大脳皮質の活動のスナップショットを撮ると、何が起こっているかの説明を、そのゾーンのそれぞれでアクティブな概念のリストと比較できます。 しかし、そのような記述には重大な欠点があります。 下の図に示されている静物を説明するとします。
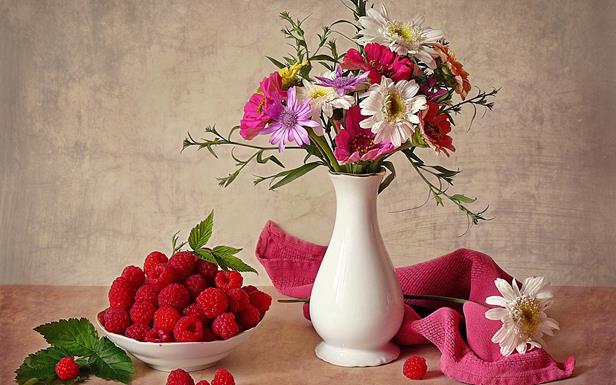
これは、たとえば次のように実行できます。
- 花瓶は中央の少し右にあります。
- 花瓶の花束;
- 花瓶の右側のタオル。
- タオルの上に白い花。
- 左側のラズベリーのボウル。
- ボウルの左側のシート上のラズベリー。
- ボウルの前にある3つのラズベリー。
- 花瓶の右側にあるラズベリー。
一般的な説明は、このような短い説明のセットで構成されています。 それぞれの短い説明は、一部の予約があれば、それに含まれる概念のリストに置き換えることができます。 しかし、短い転送に含まれるすべての概念を単純に加算して最終的な説明を収集したい場合、失敗します。 追加すると、何が何に属しているかが不明になるため、一部の情報が消えます。 しかし、さらに、いくつかの概念を数回使用する必要があることがわかります。 たとえば、左と右、ボウルの前にあるラズベリーです。 そして、この「単純に組み立てられた」記述を、そのような静物が皮質の領域でどのように記述されるかの類推として使用したい場合、「ラズベリー」の同じ一般化があり、同時に「3回アクティブ」ではないことがわかります。 私にとっては理にかなっていると思われるこの状況から抜け出す方法は、バッチ記述を使用することです。 各簡単な説明は、アクティブな概念の平凡な列挙で構成できます。 完全な説明は、簡単な説明のセットとして取得されます。 簡単な説明は時間的に分離されているため、一方ではそれが何を指しているのかが明確であり、他方では、同じ概念が異なるコンテキストのパッケージの異なるレイヤーで何度も発生する可能性があります
このようなパッケージプレゼンテーションは、人の注意の量に関する推論と非常によく相関しています。 注意の特性を研究している心理学者は、人が同時に集中できる物体の数には制限があることを確立しました。 通常、この制限は7つのオブジェクトを超えません。 機械式タキストスコープを使用して注意量を最初に測定したのは、実験心理学のウィルヘルムヴントの創始者です。

タチトスコープ-一貫した視覚刺激を提示できるデバイス
注意の量の評価は非常に簡単です。 前の静物を見て、何個の要素ができるかを計算してみてください。いいえ、覚えていないが、これは違いますが、同時にそれを頭の中に保持します。 または、1145618などの7桁の電話番号を取得し、それを頭の中で「保持」しようとします。 おそらく、それが消えないように、自分で繰り返してループする必要があります。 数字に7桁を超える数字がある場合、すべてをメモリに保持できない可能性が高くなります。 静物のオブジェクトの最大数または同時に知覚される数は、注意の量の推定値を与えます。
大脳皮質内の情報のバッチ表現に関する我々の仮定により、注意の対象となる各オブジェクトを情報パケットのレイヤーの1つと比較することができます。
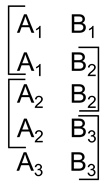
2つのオブジェクト「A」と「B」に関する非常に単純な思考を定式化できる少数の概念で構成される皮質を想像すると、思考に対応するパッケージ:「赤いオブジェクトAは青いオブジェクトBの上にあります」は図のようになります以下。
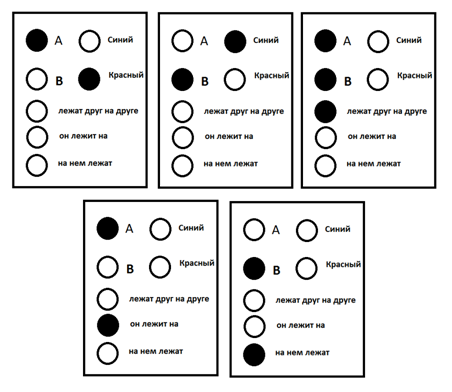
情報パッケージの例
複雑な説明のエンコード
記憶に戻って、どのような種類の情報を体系化し、それに応じて、私たちの脳が機能できる記述の種類を体系化してみましょう。
最初のタイプは、皮質の瞬間的な活動の写真に対応する簡単な説明です。 これは、現在脳によって検出されている概念の組み合わせです。
2番目のタイプは、1つのイベント、1つの思考に対応する簡単な説明のパッケージです。 パッケージでは、説明の順序は重要ではありません。 パッケージのレイヤーを再配置しても、ステートメントの一般的な意味は変わりません。 パッケージを記憶することは、一連の連続した簡単な説明の復元です。
3番目のタイプは、位置の説明です。 この説明では、特定の関係システムにおいて、一部のオブジェクトと他のオブジェクトとの接続が保持されます。 たとえば、このような記述のバリエーションは空間記述です。 空間内の位置を固定するだけでなく、特定の説明と他のオブジェクトの位置を関連付けます。
4番目のタイプは、手順の説明です。 このような記述では、パターンのシーケンスの変化と関係する間隔が重要です。 たとえば、音声の知覚は音のシーケンスによって決定されますが、間隔の比率はイントネーションを形成します。イントネーションは、聞かれるフレーズの一般的な意味に依存します。 手順の呼び出しとは、適切な一連の画像を再現することです。
そして、5番目のタイプは時系列の説明です。 これらのイベントまたは他のイベントが発生したシーケンスおよび時間間隔での長期間の修正。 時系列の記憶を想起する能力は、1つの時系列に関連するすべてを再現するだけでなく、共通の時系列によってそれに関連付けられた、ある記述から別の記述に移動する能力です。
多くの説明が何らかの形で時間に結びついていることに気付くのは簡単です。 バッチ記述は、一連の連続した画像です。 手順の説明では、イベントのシーケンスが考慮されます。 時系列の説明では、時間の経過とともにイベントの位置を考慮する必要があります。
このような記述の時間依存性は、対応するモデルの出現を引き起こしました。 これらの中で最もよく知られているのは、Jeff Hawkins(Hawkins、2011)によって提唱された階層的一時記憶(HTM)の概念です。 彼と彼の同僚は、イベントの時間的変化が、別々の情報画像を互いにリンクさせる唯一のことであるという事実から進んでいます。 このことから、皮質の基本的な情報要素は静止画像ではなく、時系列で機能する必要があると結論付けられました。 HTMの概念では、情報記憶要素は時間を延長した一連の信号です。 認識は、2つのシーケンスの一致の決定です。 HTMの予測能力に特に重点が置かれています。 ニューロンは、慣れ親しんだシーケンスの始まりを認識するとすぐに、自身の経験から、記憶している継続を予測できるようになります。 HTMでの現在の画像の説明は、イベントの現在の変化に応答したニューロンの活動です。
このアプローチの複雑さは非常に明白です。 第一に、時間スケールへのコンプライアンスの要件。 データの受信のわずかな加速または遅延は、認識アルゴリズムに違反する可能性があります。 第二に、皮質が画像を操作する前に、すべての静的画像を一時的なシーケンスに変換する必要がある。 など。
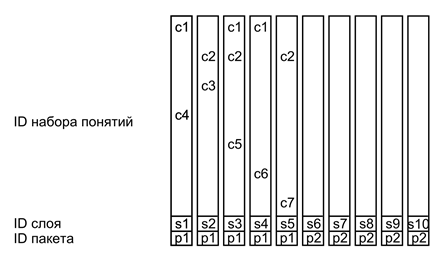
このモデルでは、識別子システムにより、考えられるすべてのタイプのメモリの記述に同様に適した汎用ツールが提供されます。 基本的な考え方は単純です。それぞれの単純な説明は、関連性および時間的関係の両方のセット全体を示すために必要なすべてを含む複合識別子です。
次の図は、このような簡単な説明の条件付き画像を示しています。 簡単な説明は、さまざまなタイプの識別子のいくつかのセットを運ぶウェーブです。 メインコンテンツは、何が起こっているかの本質を説明する概念識別子のセットによってエンコードされます。 レイヤー識別子は、メインコンテンツにマークを付け、残りの簡単な説明から分離します。 パッケージ識別子は、1つの複雑な説明に属する複数のレイヤーを組み合わせます。 場所、時間、およびシーケンスの識別子は、複雑な記述間の対応関係のシステムを作成します。
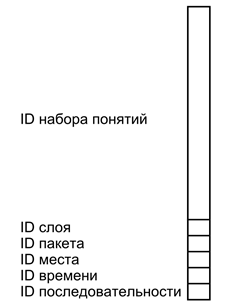
簡単な説明形式
前の例を取り上げ、使用されている概念に対応する識別子の波をC1 ... C7として示します(下図)。
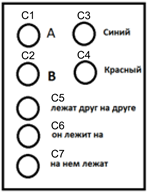
説明に使用される概念
次に、「赤いオブジェクトAが青いオブジェクトBの上にある」という説明は、次の図のようになります。
複雑な説明の例
この例では、パッケージ内の各レイヤーは、独自のレイヤー識別子を持つ簡単な説明です。 すべてのパッケージレイヤーには、共通のパッケージ識別子p1があります。 1つの複雑な記述が終了すると、それに続く他の記述にはパッケージp2の異なる識別子が付けられます(2番目の記述の概念は図に示されていません)。
そのような設計が機能するためには、脳はパッケージを形成する識別子を作成するかなり複雑なシステムを必要とします。 さらに、皮質のゾーンごとに、そのような識別子の独自のセットが必要になる場合がありますが、これは適切です。
たとえば、一連の視覚認識を考えます。 マイクロアカケードと呼ばれる目の痙攣性の微動により、網膜の中心にある画像の小さな部分が目でスキャンされます。 このようなスキャンのプロセスで取得されるすべての画像は、おそらく共通の識別子によって結合されます。 目の微動は、四肢の上部結節によって制御されます。 そのような識別子をエンコードするのは彼らであると想定することができます。 いくつかのマイクロサッケードの後、サッケードと呼ばれる強いジャンプが発生します(サッケードは、上記のネフェルティティの頭部とともに図に示されています)。 各サッカードは、マイクロサッカード識別子の変化を引き起こします。
マイクロアカケードは、一次視覚野にとって基本的に重要であると考えられます。 共通の識別子は、一連の連続した画像が同じオブジェクトを説明しますが、網膜上の異なる位置にあることを皮質に伝えます。これにより、それらを単一の説明に結合し、網膜上の位置に不変の認識を実現できます。
長いイベントは一連のサッカードです。 シリーズは単一の画像を見ることに言及しているため、結果の説明は別の共通の識別子であるサッカード識別子によってリンクすることもできます。 しかし、この識別子は、プライマリではなく、情報の後続処理が発生する視覚皮質のセカンダリレベルおよびより深いレベルでは必須ではありません。 一連のサッカード中に見えるすべてのものが同一の画像であることを皮質に伝える識別子により、網膜の異なる場所で見える同じ画像を関連付けることができます。
調査対象の画像が大幅に変化すると、サッカード識別子は変化するはずです。 たとえば、頭を強く回転させたり、注意を切り替えたり、映画の計画やシーンを変更したりします。 注意の切り替えは、脳の辺縁系の要素によってエンコードされ、これに関連付けられている多くの皮質ゾーンに拡張できます。 同時に、イベントの時空間的記述をエンコードする海馬識別子が記述システムに存在します。 つまり、パッケージを定義する識別子のシステムは非常に複雑であり、クラストの特定の各ゾーンが扱う情報の特徴によって決定される可能性があります。
識別子を使用すると、一連のイベントの修正を簡単に整理できます。 たとえば、2つのフラグメントで構成される識別子を取得し、それらの1つを交互に変更すると、隣接する記述の結合接続を取得できます(以下の図)。
シーケンスコーディング
このような各識別子には、前の識別子と後続の識別子の要素が含まれます。 このような識別子を持つ画像の時系列を記憶しておくと、各画像について、タイムラインで2つの隣接画像を見つけることができます。 識別子を簡単に複雑化できるため、一般的なつながりだけでなく、時間の流れの方向もエンコードできます。
このモデルでは、各メモリに豊富な識別子システムがあることに注意してください。 これにより、多くの完全に異なる関連付けを介してメモリにアクセスできます。 記述の意味の一致に基づいて何かを思い出すことができます。 説明されたイベントの場所または時間で情報画像を関連付けることができます。 単一のイベントに関連する一連の画像を再現できます。 このようなメモリへのアクセスは、従来のリレーショナルデータベースの作成に使用されるアプローチと多くの共通点があることは容易にわかります。
中古文学
継続
前のパーツ:
パート1.ニューロン
パート2.要因
パート3.パーセプトロン、畳み込みネットワーク
パート4.バックグラウンドアクティビティ
パート5。脳波
パート6.投影システム
パート7.ヒューマンコンピューターインターフェイス
パート8.波動ネットワークの要因の分離
パート9.ニューロン検出器のパターン。 逆投影
パート10.空間的自己組織化
パート11.動的ニューラルネットワーク。 連想性
パート12.メモリーのトレース
パート13.連想メモリ
パート14.海馬
パート15.メモリの統合
アレクセイ・レドズボフ (2014)