Yandex.Trafficの原理は非常に単純です。 説明するために別の講義は必要ありません。 GPSを使用するアプリケーションYandex.MapsおよびYandex.Navigatorは、実行中のデバイスの場所を特定し、この情報をサーバーに送信します。 そして、これらのデータに基づいて、彼は渋滞の写真を作成します。
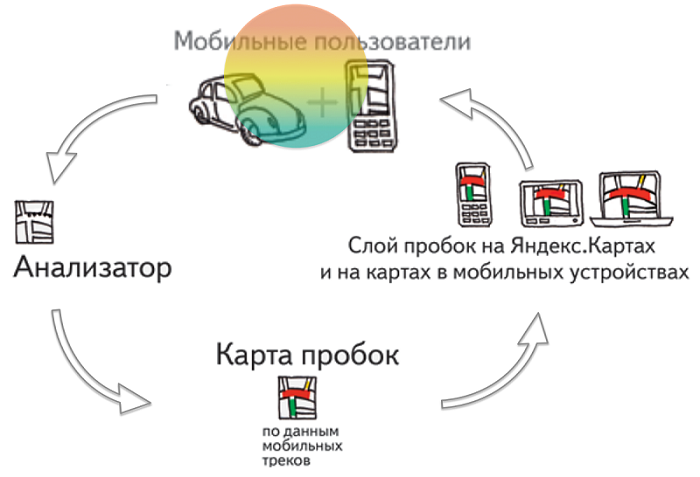
しかし、これはどのように発生しますか? これはすでに特別なアルゴリズムと統計の使用を必要とする完全に重要なプロセスです。 ゆっくりと進むドライバーと歩行者または自転車を区別する方法は? 送信された情報の信頼性を検証する方法は? そして最も重要なのは、交通データを最も正確にする方法ですか?
交通渋滞マップを作成するときに対処しなければならない非常に最初の問題は、GPSテクノロジーが理想からほど遠いことであり、必ずしも正確な位置を特定できないことです。 1つのオブジェクトの動きを追跡することで、かなり奇妙なデータを取得できます。かなり長い距離にわたる瞬間的な動き、道路の脇への移行などです。 その結果、次の図を取得できます。
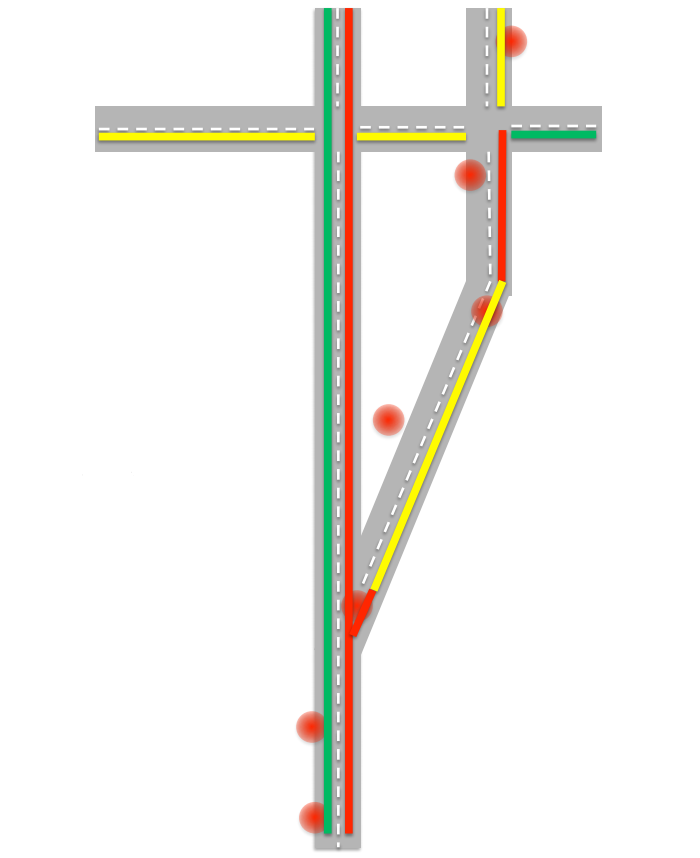
アルゴリズムはそれが何であるかを決定する必要があります。 データを絞り込むために、アルゴリズムは最も可能性が高く許可されているルートルールを見つけようとします。 次に、直面しているオブジェクトを判別する必要がありますか? 実際、交通渋滞では、車は歩行者の速度で運転することができ、GPSの精度では、対象物が道路に沿って移動しているか、道端に沿って移動しているかを確実に言えません。 ここでは、いくつかの要因を考慮することができます。まず、低速で移動するオブジェクトの数が十分に多い場合、この道路に渋滞があり、車はゆっくりと走行していると想定できます。 また、過去数時間にわたるオブジェクトの速度の履歴を考慮することもできます。 過去4時間に1時間あたり10〜15キロメートルを超える速度で物体が発達していない場合、これは歩行者である可能性が高いと仮定します。
そのため、特定の期間における特定の方向のマシンの速度を決定し、特殊なアルゴリズムで処理し、平均化して、その結果、おおよその流れの一般的な速度を取得しました。 これらはすべて、リアルタイムで、数十万台の車で構成されるストリームで発生します。
アルゴリズム
前述のように、アルゴリズムはオブジェクトのタイプ、その速度の決定、およびストリームの速度の平均化に関与します。 しかし、彼らの仕事の質をどのように評価し、あなたが彼らを改善するためにどの方向に進む必要があるかを理解するにはどうすればいいでしょうか?
最初の問題は、市内でテストカーを発売することで解決されます。 通常のユーザーと同様に、彼らは自分の動きに関するデータを送信しますが、同時に実際の状況が正確に何であるかを知っています。 その後、メトリックに基づいて、特定のエリアの実際の渋滞マップを計算されたアルゴリズムと比較し、システムがそのタスクにどれだけうまく対応しているかを判断できます。
実際の状況と複数のアルゴリズムの結果を一度に比較すると、どちらが優れているかを評価できます。 新しいアルゴリズムをテストし、古いアルゴリズムと比較するとします。 67セグメントで実行し、次の結果を取得します。

54の場合、新しいアルゴリズムは古いアルゴリズムよりもうまく機能し、13の場合は悪くなりました。 正解とエラーの割合に関しては、新しいアルゴリズムの方が明らかに優れています。 ここで、比較に別のアルゴリズムを追加することを想像してください。 しかし、彼はより少ないセグメントで走りました-6。

ヒットとエラーの割合は、最初のヒットよりも彼のほうが優れています。 しかし、このような少数のセグメントでの検証を信頼する価値はありますか? この質問に明確に答えるために、統計に目を向けます。
統計
まず、ランダムな値を扱います。 コインを3回フリップしたとしましょう。 私たちはワシをゼロ、尾を1つとしています。 合計で、8つの組み合わせを取得できます。 各組み合わせの低下した値の合計を計算すると、極値の低下頻度が低くなり、中心に近づくにつれて確率が高くなることがわかります。
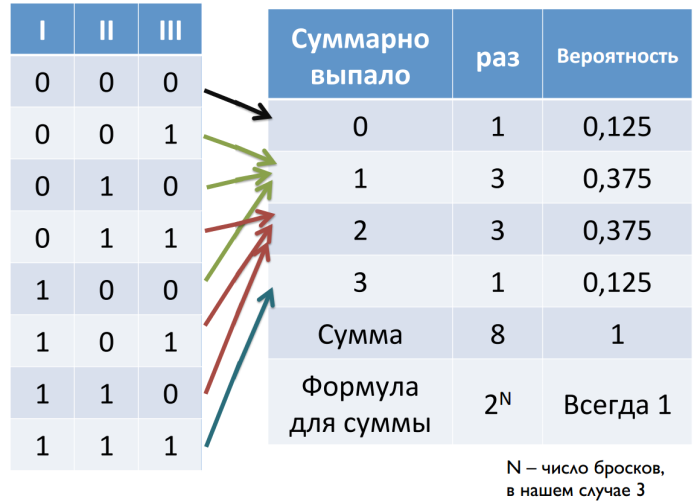
次に、コインをN回投げる例を考えてみましょう。 オブジェクトの数をk、組み合わせの数をCとします。

平均および観測平均
次に、別の問題を提起します。 コインがあり、それが偶数かどうか、つまり 同じ確率で各側に落ちるかどうか。 コインを投げることでこの仮説をテストします。 コインが平らな場合、コインを投げる回数が多いほど、平均値に近い結果が最も多くなります。 同時に、ショットの数が少ない場合、間違った結論を出す可能性がはるかに高くなります。
なぜ事故についても話しているのでしょうか? 実際、渋滞マップを構築するためのアルゴリズムのエラーは、多くの場合、いくつかの客観的な理由で発生します。 しかし、これらの理由のすべてが私たちに知られているわけではありません。 すべての理由を知っていれば、完璧なアルゴリズムを作成でき、二度と改善することはできません。 しかし、これが発生するまで、いくつかのアルゴリズムエラーをランダム変数としてとらざるを得ません。 したがって、フラットコイン仮説とほぼ同じ装置を使用して、アルゴリズムがどの程度機能し始めたかを確認します。 この場合にのみ、基本的な仮説として、アルゴリズムがまったく変更されていないことを受け入れます。 そして、アルゴリズムを実行したデータを使用して、一方向または他の方向に歪みがあるかどうかを判断します。 コインの場合と同様に、できるだけ多くのランがあることが重要です。そうしないと、ミスをする可能性が高くなりすぎます。
2つのアルゴリズムを使用して例に戻ると、最初の新しいアルゴリズムが古いアルゴリズムよりも優れていると自信を持って言うことができます。 しかし、正しい答えとエラーの割合が彼にとってより良いという事実にもかかわらず、2番目はより多くの疑念を提起します。 おそらくそれは本当にうまく機能しますが、これを確認するには、さらにチェックを行う必要があります。
