過去数年間、私はいわゆるノンブロッキングアルゴリズム(ロックフリーデータ構造)を使用してきました。私たちはそれらを自分で書き、テストし、使用し
それが、ロックフリーを強化するために独自のコードをテストしたテクニックのいくつかを初めて適用するアイデアを得たときです。 幸いなことに、アルゴリズム自体をテストする必要はなく、パフォーマンスの測定に集中できます。
この記事を皆さんにとって興味深いものにしようと思います。 まだそのようなタスクに遭遇していない人にとっては、そのようなアルゴリズムが可能なもの、そして最も重要なことには、それらがどこでどのように使用されるべきか、または使用されるべきでないかを調べることは有用です。 ノンブロッキングキューの開発経験がある人にとっては、定量的な測定値を比較することは興味深いかもしれません。 私自身は、少なくともそのような出版物を見たことがない。
はじめに:ノンブロッキングデータ構造とアルゴリズムとは
マルチスレッドの概念は現代のプログラミングにしっかりと入っていますが、スレッドの操作は同期ツールなしでは不可能であるため、ミューテックス、セマフォ、条件変数、およびそれらの子孫が登場しました。 ただし、最初の標準関数はかなり重く、低速で、さらにカーネル内に実装されていました。つまり、各呼び出しへのコンテキスト切り替えが必要でした。 切り替え時間はCPUにわずかに依存するため、プロセッサが高速になるほど、スレッドを同期するためにより多くの相対時間が必要になります。 その後、最小限のハードウェアサポートで、同時に複数のスレッドを操作しながら不変のデータ構造を作成することができるというアイデアが浮上しました。 これについてもっと知りたい人には、 この出版物シリーズをお勧めします。
基本的なアルゴリズムが開発され、長い箱に入れられましたが、まだ時間がありませんでした。 メッセージ処理時間(レイテンシ)の概念が通常のCPU速度よりもほとんど重要になったとき、彼らは第二の人生を迎えました。 それは何ですか?
以下に簡単な例を示します。
メッセージを受信し、処理し、応答を送信するサーバーがあるとします。 100万のメッセージを受信し、サーバーがそれらを2秒で処理したと仮定します。つまり、トランザクションごとに2マイクロ秒であり、私に適しています。 これは帯域幅と呼ばれるものであり、メッセージを処理する際の正しい尺度ではありません 。 後で、私にメッセージを送信した各クライアントが1秒以内に応答を受信したことを知って驚きました。 元気? 考えられるシナリオの1つ:サーバーはすべてのメッセージをすばやく受信し、それらをバッファーに追加します。 その後、それらを1秒ごとに並行して処理しますが、わずか2秒ですべてをまとめて処理します。 すぐに送り返します。 これは、全体として良好なシステム速度であると同時に、許容できないほど高いレイテンシーの例です。
Herb Sutterの インタビューの声明で詳細を読むことができます。彼はわずかに異なる文脈にいますが、彼はこの問題を非常に気まぐれに議論しています。 直感的には、速度と待ち時間の概念は同じであるように見えます。最初の概念が大きいほど、2番目の概念は小さくなります。 しかし、よく見ると、それらは独立しており、相関関係さえないことがわかります。
これは非ブロッキング構造と何の関係がありますか? 最も直接的なことは、待ち時間の場合、フローを減速または停止しようとすると致命的なことです。 ストリームを安楽死させるのは簡単ですが、目覚めることはできません。 オペレーティングシステムのコアだけが
そのような構造の1つについて説明します。
プラットフォームへの最初のアプローチ
任意の数の書き込みおよび読み取りストリームで単方向キューを実装するブースト::ロックフリー::キューのいずれかの構造でのみ動作します。 この構造には2つのバージョンがあります。必要に応じてメモリを割り当て、容量が無限であるオプションと、固定バッファのオプションです。 厳密に言えば、両方ともノンブロッキングではありません。1つ目はシステムメモリの割り当てがロックフリーではないため、2つ目は遅かれ早かれバッファがオーバーフローし、書き込み用のスペースができるまで書き込みストリームが無期限に待機するためです。 最初のオプションから始めましょう。最後に向かって、固定バッファーの結果と比較します。
また、4コアのLinux Mint-15があることも付け加えます。
ここからコードを取り出して実行してみましょう。結果は次のとおりです。
boost ::ロックフリー::キューはロックフリー 40,000,000個のオブジェクトを生成しました。 40,000,000個のオブジェクトを消費しました。 実際の0m15.332s ユーザー1m0.376s sys 0m0.064s
つまり、メッセージごとに約400 nsの簡単な方法で問題にアプローチすれば、十分に満足のいくものです。 この実装はintを渡し、4つの読み取りおよび書き込みストリームを開始します。
コードを少し変更してみましょう。私は任意の数のスレッドを実行したいのですが、統計も確認したいと思います。 テストを連続して100回実行すると、分布はどうなりますか?
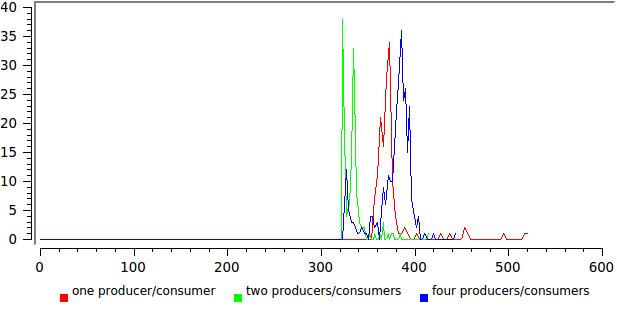
ここでは、かなり合理的に見えます。 X軸では、ナノ秒単位の合計実行時間を送信メッセージの数で割った値、Y軸では、そのようなイベントの数です。
そして、これは異なる数の作家/読者の結果です:
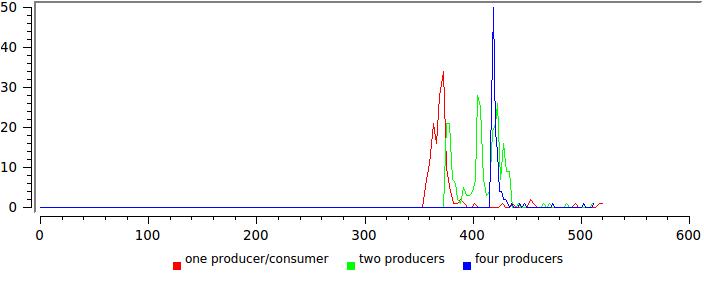
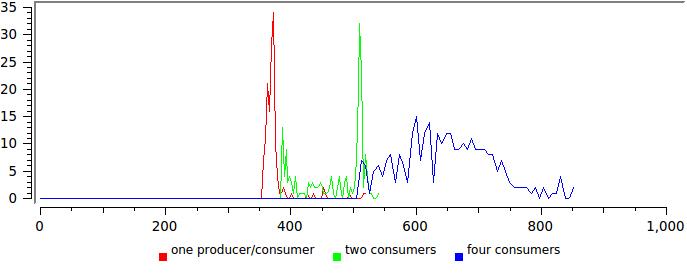
ここでは、すべてがそれほどバラ色ではありません。分布を広げることは、何かが最適に機能していないことを示唆しています。 この場合、このテストの読み取りストリームは制御を決して放棄せず、その数がコアの数に近づくと、システムはそれらを中断するだけです。
プラットフォームへの2番目のアプローチ
無駄なintを渡す代わりに、テストをもう1つ改善して、書き込みストリームが現在の時刻をナノ秒単位で正確に送信できるようにします。 その後、受信者は各メッセージの遅延を計算できます。 実行します:
スレッド:1書き込み、1読み取り 失敗:0プッシュ、3267ポップ 帯域幅:177.864 ns レイテンシ:1.03614e + 08 ns
また、キューからのメッセージの読み取りとキューへの書き込みに失敗した試行回数もカウントします(ここでの最初の試行は、常にゼロになります。これは割り当てオプションです)。
しかし、これは他に何ですか? 直観的に同じオーダー(200 ns)を想定した遅延は、100ミリ秒を突破し、50万倍以上になります! それはできません。
しかし、結局のところ、各メッセージの遅延がわかったので、ここでを押してリアルタイムでどのように見えるかを確認します。プロセスがランダムであることがわかるように、いくつかの同一の開始の結果を次に示します。
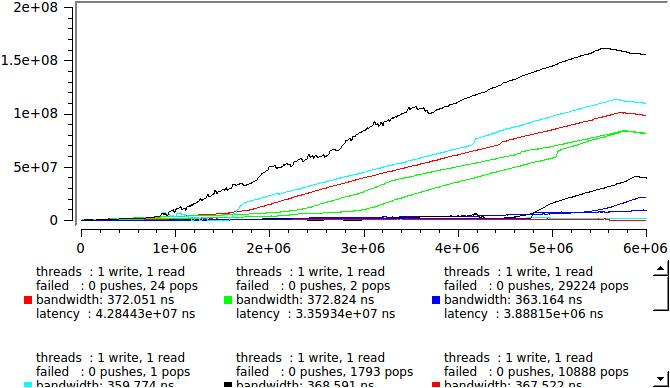
一度に1つのストリームを読み書きする場合、および4つの場合、ここに:
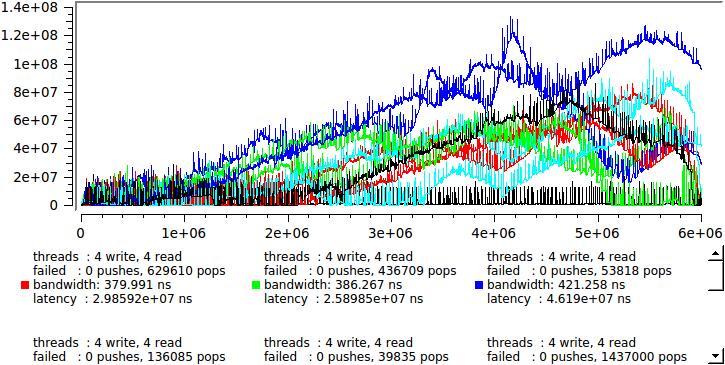
何が起こっているの? 任意の瞬間に、読み取りストリームの一部がシステムによって送信されて休息します。 キューは急速に成長し始め、メッセージはその中にあり、処理を待機しています。 しばらくすると、状況が変わり、書き込みストリームの数が読み取りより少なくなり、キューがゆっくりと解決されます。 このような変動は、ミリ秒から秒の期間で発生し、キューはバッチモードで動作します-100万件のメッセージが記録され、100万件が読み取られます。 同時に、パフォーマンスは非常に高いままですが、個々のメッセージはそれぞれキューで数ミリ秒を費やす可能性があります。
私たちは何をしますか? まず、考えてみましょう。この形式のテストは明らかに不十分です。 私たちの国では、アクティブなスレッドの半分はメッセージをキューに挿入するだけでビジーです。これは実際のシステムでは発生しません。言い換えれば、テストはトラフィックがマシンよりも優れたパワーを生成するように設計されています。
入力トラフィックを制限する必要があります。キューの各エントリの後にusleep(0)を挿入するだけです。 私のマシンでは、これにより良好な精度で50μsの遅延が発生します。 見てみましょう:
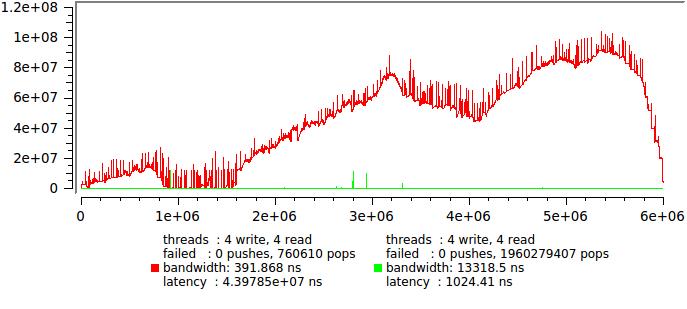
赤い線は遅延なしの最初のテストで、緑の線は遅延ありです。
これはまったく別の問題です。統計を計算できるようになりました。
Xの許容可能なスケールを維持するために、書き込みおよび読み取りストリームの数のいくつかの組み合わせの結果を以下に示します。最大サンプルの1%が破棄されます。
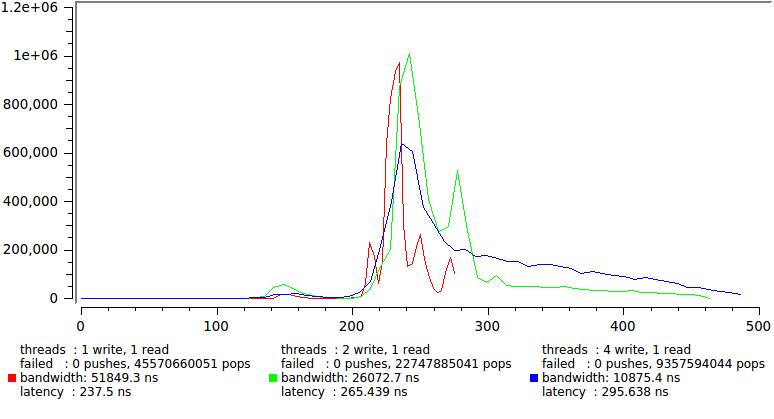
レイテンシは確実に300 ns以内にとどまり、ディストリビューションテールのみがさらに拡大することに注意してください。
そして、それぞれ1つと4つの書き込みストリームの結果を示します。
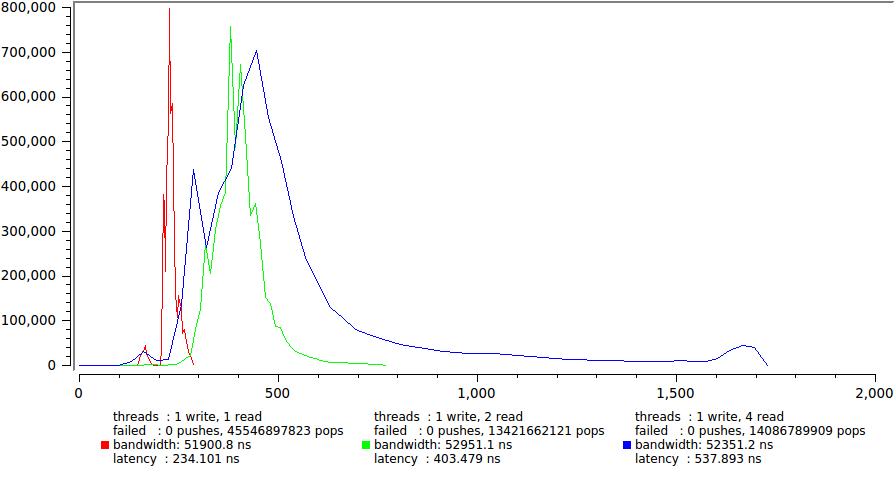
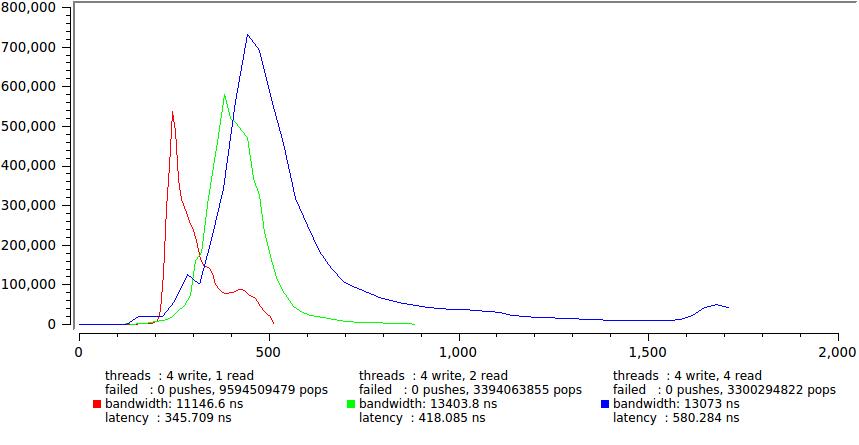
主に尾の急激な成長により、遅延が大幅に増加します。 繰り返しますが、タイムスライスの開発中にアイドル状態が継続的に発生する4つのスレッド(== CPU)があり、制御不能な多数のスローダウンが発生することがわかります。 平均遅延は確実に600 ns以内にとどまりますが、一部のタスクでは、これは既に許容範囲内にあります。たとえば、TKが特定の時間内にメッセージの99.9%を配信することを明確に規定している場合です(これは私に起こりました)。
また、合計実行時間が150回ごとにどれだけ伸びたかにも注意してくださいこれは、最初に作成したステートメントのデモンストレーションです-最小レイテンシと最大速度は同時に達成されません。 不確実性の独特の原則。
実際には、テストから抜け出すことができたのはそれだけです。 遅延を高精度で測定し、多くのモードで平均レイテンシが何桁も大きくなること、より正確には遅延の平均の概念が意味を失うことを示しました。
最後に最後の質問を考えてみましょう。
固定容量キューはどうですか?
固定容量は、boost :: lockfree ::固定サイズの内部バッファ上に構築されたキューの別の変形です。 これにより、一方ではシステムアロケーターへのアクセスを回避できます。他方では、バッファーがいっぱいの場合、書き込みストリームも待機する必要があります。 一部の種類のタスクでは、これは完全に除外されます。
ここでは、同じ方法で作業します。 まず、経験に基づいて、遅延のダイナミクスを見てみましょう。

赤いグラフは、ブーストの例で使用されている128バイトに対応し、緑のグラフは、可能な最大の65534バイトに対応します。
ちなみに
ドキュメントには、最大サイズは65535バイトであると書かれています-それを信じないでください、コアダンプを取得してください
人為的な遅延を挿入しなかったため、キューがバッチモードで動作し、大部分が満たされ、解放されるのが自然です。 ただし、固定バッファ容量により特定の順序が導入され、遅延の平均が少なくとも存在することが明確にわかります。
それでも、このオプションがマルチスレッドプログラムでどのように動作するかを評価してみましょう。
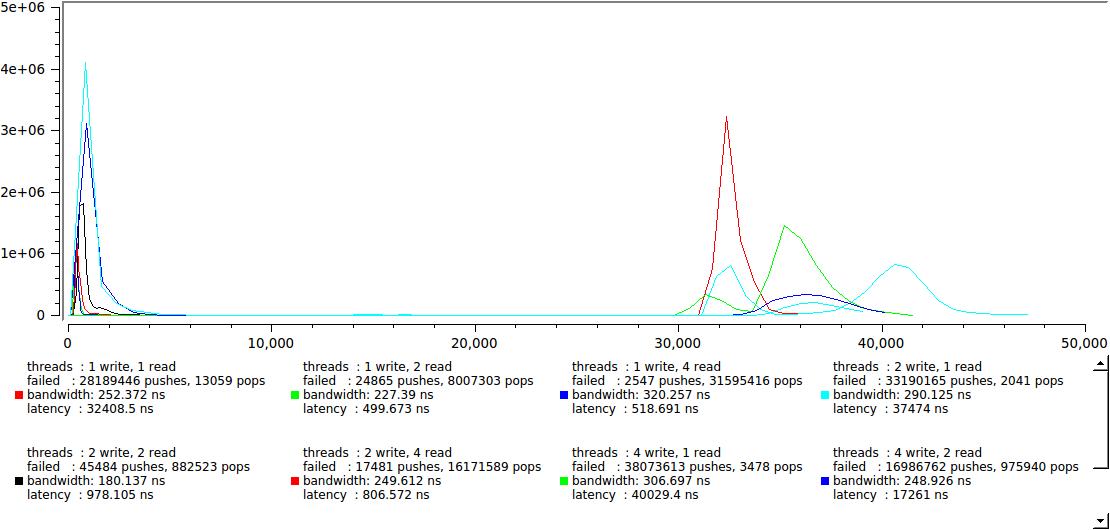
このような明確な2つのグループへの分割を見るのは少し予想外でした。読者の速度が、私たちが切望する数百ナノ秒の速度を超えるライターの速度を上回り、逆に最大で30-40マイクロ秒に跳ね上がり、これが私のマシンのコンテキストを切り替える時だと思われます。 これは128バイトのバッファーの結果です。64Kの場合は非常に似ており、右側のグループのみが数十ミリ秒遠くまでfarい上がります。
それは良いですか悪いですか? タスクに依存しますが、一方で、遅延がどんな条件下でも40μsを超えないことを自信を持って保証できます。これは良いことです。 一方、この値未満の最大遅延を保証する必要がある場合は、苦労します。 たとえば、メッセージ処理のわずかな変更によるリーダー/ライターのバランスの変化は、遅延の急激な変化につながる可能性があります。
ただし、システムが処理できるよりも明らかに速くメッセージを生成し(上記の動的キューに関するセクションを参照)、妥当な遅延を挿入しようとすることを思い出してください。
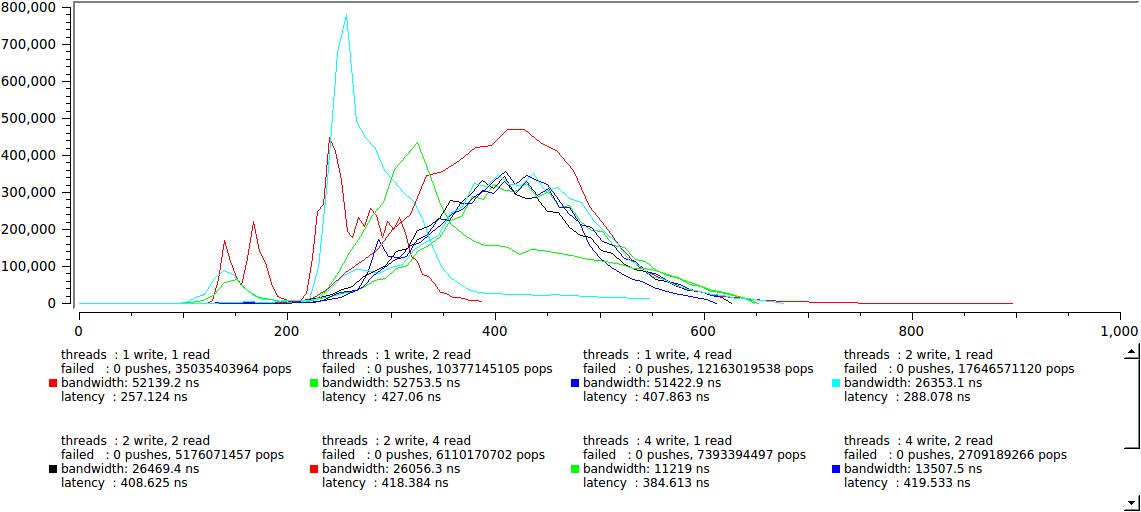
これはすでに非常に優れており、2つのグループは完全にはマージされませんでしたが、正しいグループは最大レイテンシが600 nsを超えないように近づきました。 私の言葉を聞いてください。大きなバッファの統計は64Kで、まったく同じように見えますが、わずかな違いではありません。
結論に移る時です
経験のある人がテスト結果から自分自身に役立つ何かを抽出できることを願っています。 ここに私が自分で思うことを示します
- 速度のみに関心がある場合、すべてのオプションはほぼ同等であり、メッセージあたり数百ナノ秒のオーダーの平均時間が得られます。 この場合、fixed_capacityキューは、一定量のメモリを占有するため、より軽量です。 ただし、たとえば、ロガーなどのアプリケーションでは、読み取りストリームをできるだけ早く「解放」することが非常に重要です。その場合、割り当てキューの方が優れている一方で、メモリを無制限に消費する可能性があります。
- レイテンシの最小化、各メッセージの処理時間を個別に必要とする場合、状況は複雑です。 書き込みストリーム(ロガー)をブロックしたくないアプリケーションの場合、割り当てオプションを選択する価値があります。 メモリが限られている場合、fixed_capacityが最適です。信号の統計に基づいてバッファサイズを選択する必要があります。
- いずれにせよ、アルゴリズムはデータストリームの強度に関して不安定です。 特定の重大なしきい値を超えると、遅延が数桁ジャンプし、実際に(正式ではないが)ラインがブロッキングになります。 原則として、ブロッキングモードに陥ることなくシステムを動作させるには、微調整が必要です。
- 入力ストリームと出力ストリームの完全な分離は、割り当てバージョンでのみ可能ですが、これは制御されていないメモリ消費と制御されていない長い遅延により実現されます。
- Fixed_capacityを使用すると、最大レイテンシを合理的な制限に制限しながら、高速データ転送を実現できます。 fixed_capacityキュー自体は、本質的に非常に軽量な構造です。 主なマイナス点は、読者が何らかの理由で対処またはフリーズできない場合、書き込みストリームがブロックされることです。 私の意見では、大きなサイズのバッファはめったに必要とされません。それらは、割り当てキューに近い、過渡的なダイナミクスを実現します。
- 私にとって非常に不愉快な驚きは、ダイナミクスに対するアイドルリーディングストリームが継続的に機能することの大きな悪影響でした。 スレッドの合計数がCPU以下の場合でも、100%を消費する別のスレッドを追加しても改善されませんが、ダイナミクスが悪化します。 それぞれの重要なスレッドに別々のコアが割り当てられている場合、「大規模サーバー」の戦略は常に機能するとは限りません。
- これに関して、言及されておらず、まだ解決されていない問題の1つは、イベントを待機しているスレッドを効率的に使用する方法です。 あなたがそれをスリープ状態にした場合-他のタスクに使用された場合、レイテンシー
カルマは致命的に損なわれます-タスクからタスクにすばやく切り替える問題が発生します。 理想への適切な近似は、読み取りストリームを追加して:: io_serviceをブーストし、少なくともまれなイベントを効率的に処理できるようにすることだと思います。 誰かが何かアイデアを持っているかどうか聞いてうれしいです。
コードが必要な人向け
#include <boost/thread/thread.hpp> #include <boost/lockfree/queue.hpp> #include <time.h> #include <atomic> #include <iostream> std::atomic<int> producer_count(0); std::atomic<int> consumer_count(0); std::atomic<unsigned long> push_fail_count(0); std::atomic<unsigned long> pop_fail_count(0); #if 1 boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<true>> queue(65534); #else boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<false>> queue(128); #endif unsigned stat_size=0, delay=0; std::atomic<unsigned long>* stat=0; std::atomic<int> idx(0); void producer(unsigned iterations) { timespec t; for (int i=0; i != iterations; ++i) { ++producer_count; clock_gettime(CLOCK_MONOTONIC, &t); while (!queue.push(t)) ++push_fail_count; if(delay) usleep(0); } } boost::atomic<bool> done (false); void consumer(unsigned iterations) { timespec t, v; while (!done) { while (queue.pop(t)) { ++consumer_count; clock_gettime(CLOCK_MONOTONIC, &v); unsigned i=idx++; v.tv_sec-=t.tv_sec; v.tv_nsec-=t.tv_nsec; stat[i]=v.tv_sec*1000000000+v.tv_nsec; } ++pop_fail_count; } while (queue.pop(t)) { ++consumer_count; clock_gettime(CLOCK_MONOTONIC, &v); unsigned i=idx++; v.tv_sec-=t.tv_sec; v.tv_nsec-=t.tv_nsec; stat[i]=v.tv_sec*1000000000+v.tv_nsec; } } int main(int argc, char* argv[]) { boost::thread_group producer_threads, consumer_threads; int indexed=0, quiet=0; int producer_thread=1, consumer_thread=1; int opt; while((opt=getopt(argc,argv,"idqr:w:")) !=-1) switch(opt) { case 'r': consumer_thread=atol(optarg); break; case 'w': producer_thread=atol(optarg); break; case 'd': delay=1; break; case 'i': indexed=1; break; case 'q': quiet=1; break; default : return 1; } int iterations=6000000/producer_thread/consumer_thread; unsigned stat_size=iterations*producer_thread*consumer_thread; stat=new std::atomic<unsigned long>[stat_size]; timespec st, fn; clock_gettime(CLOCK_MONOTONIC, &st); for (int i=0; i != producer_thread; ++i) producer_threads.create_thread([=](){ producer(stat_size/producer_thread); }); for (int i=0; i != consumer_thread; ++i) consumer_threads.create_thread([=]() { consumer(stat_size/consumer_thread); }); producer_threads.join_all(); done=true; consumer_threads.join_all(); clock_gettime(CLOCK_MONOTONIC, &fn); std::cerr << "threads : " << producer_thread <<" write, " << consumer_thread << " read" << std::endl; std::cerr << "failed : " << push_fail_count << " pushes, " << pop_fail_count << " pops" << std::endl; fn.tv_sec-=st.tv_sec; fn.tv_nsec-=st.tv_nsec; std::cerr << "bandwidth: " << (fn.tv_sec*1e9+fn.tv_nsec)/stat_size << " ns"<< std::endl; double ct=0; for(auto i=0; i < stat_size; ++i) ct+=stat[i]; std::cerr << "latency : "<< ct/stat_size << " ns"<< std::endl; if(!quiet) { if(indexed) for(auto i=0; i < stat_size; ++i) std::cout<<i<<" "<<stat[i]<<std::endl; else for(auto i=0; i < stat_size; ++i) std::cout<<stat[i]<<std::endl; } return 0; }