
データベースを一種の参照ユニットと見なすのは間違いです。時間の経過とともに、パフォーマンスの低下、誤動作など、さまざまな種類の望ましくない状況が発生する可能性があるためです。
このような状況の可能性を最小限に抑えるには、安定性と最適なデータベースパフォーマンスを保証するタスクからサービスプランを作成します。
これらのタスクの中で、以下を区別できます。
1.インデックスの最適化
2. 統計の更新
3. バックアップ
これらの各タスクの自動化を順番に検討してください。
更新2019-06-03:
しかし、最初に、この投稿を書いてから5年後にオープンソースプログラムを宣伝したいと思います。 歴史的に、彼は長い間、 SQL Serverにサービスを提供するシステムツールの開発に参加していました。 この間、多くのアイデアが蓄積され、特定の段階で自分の何かをしたかったのです。
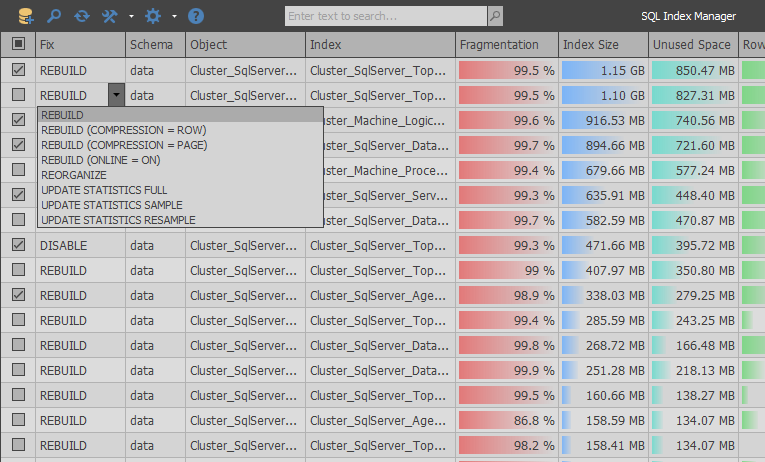
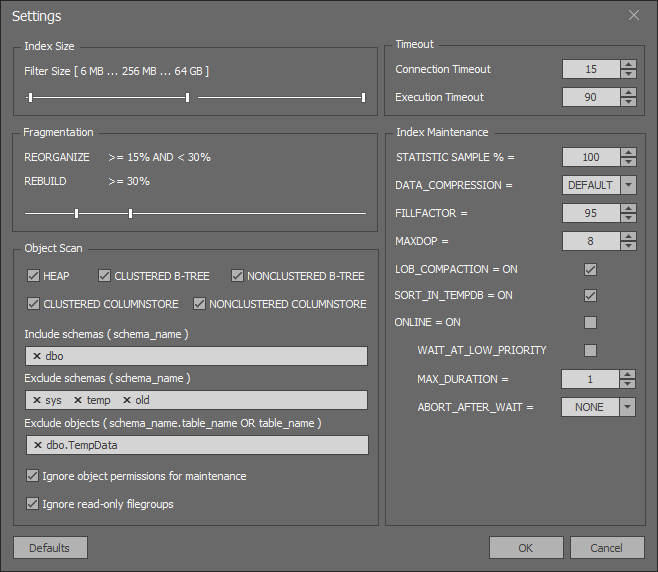
その結果、便利なUIを使用してインデックスを提供できるアプリケーションができます。 RedGateとDevartの有料アナログは、主要な競合他社に採用されました。
SQL Index Managerの主な機能:
- 断片化されたインデックスを取得するための最適化されたアルゴリズム
- 一度に複数のデータベースを提供する機能
- 選択した設定に基づくインデックスの自動アクション選択
- より便利な分析のためのグローバル検索と洗練されたフィルタリングのサポート
- インデックスに関する多数の設定と有用な情報
- インデックスメンテナンススクリプトの自動生成
- ヒープおよび列ストアのメンテナンスサポート
- コマンドラインサポート
- 再構築の代わりにインデックスの圧縮と統計の更新を含める機能
- 結果をエクスポートする機能
- インターフェースのカスタマイズ
- SQL Server 2008+およびAzure SQL Databaseのすべてのエディションのサポート
現在および将来、 SQL Index Managerは 完全に無料です。
アプリケーションの最新バージョンはこのリンクからダウンロードでき、すべてのソースはGitHubにあります 。
しかし、元の投稿に戻りましょう。 だから、最初のポイント...
ファイルシステムとログファイルの断片化に加えて、データファイル内の断片化はデータベースのパフォーマンスに大きな影響を及ぼします。
1.個々のインデックスページ内の断片化
レコードを挿入、更新、および削除した後、必然的にページに空のスペースがあります。 この状況は非常に正常であるため、これは問題ではありません。
弦の長さは非常に重要な役割を果たします。 たとえば、行のサイズがページの半分以上を占めている場合、このページの空き半分は使用されません。 その結果、行の数が増えると、データベース内の未使用領域が増加します。
このタイプの断片化に対処するには、スキームの設計段階にあります。つまり、ページにコンパクトに収まるデータ型を選択します。
2.インデックス構造内の断片化
このタイプの断片化の主な理由は、ページ分割操作です。 たとえば、主キーの構造に応じて、特定のインデックスページに新しい行を挿入する必要がありますが、このページには挿入されたデータを収容するのに十分なスペースがありません。
この場合、新しいページが作成され、古いページのレコードの約半分が移動されます。 多くの場合、新しいページは古いページと物理的に隣接していないため、システムによって断片化されているとマークされます。
いずれにせよ、断片化は同じ量の情報を保存するためのページ数の増加につながります。 これにより、自動的にデータベースサイズが増加し、未使用スペースが増加します。
断片化されたインデックスを参照するクエリを実行する場合、より多くのIO操作が必要です。 さらに、断片化により、サーバー自体のメモリに追加コストがかかり、キャッシュに余分なページを保存する必要があります。
インデックスの断片化に対処するために、 SQL Serverの武器には次のコマンドが含まれています: ALTER INDEX REBUILD / REORGANIZE 。
インデックスの再構築には、古いインデックスの削除とインデックスの新しいインスタンスの作成が含まれます。 この操作は、 FILLFACTORオプションで設定できるページ上の空き領域を確保しながら、断片化を排除し、ページを圧縮することによりディスク領域を復元します。 インデックスを再構築する操作は非常にコストがかかることに注意することが重要です。
したがって、断片化が無視できる場合は、既存のインデックスを再編成することをお勧めします。 この操作では、インデックスを再作成するよりもシステムリソースが少なくて済み、 リーフレベルのページを再編成できます。 さらに、再編成は可能であればインデックスページを圧縮します。
特定のインデックスの断片化の程度は、 sys.dm_db_index_physical_stats動的システムビューで確認できます。
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) WHERE avg_fragmentation_in_percent > 0
このクエリでは、最後のパラメーターがモードを設定します。この値から、インデックスの断片化のレベルをすばやく正確に決定することはできますが、その値からは限定されません( LIMITED / NULLモード)。 したがって、 SAMPLED / Detailedモードを設定することをお勧めします 。
断片化されたインデックスのリストを取得する場所はわかっています。 ここで、それぞれが対応するALTER INDEXコマンドを生成する必要があります。 伝統的に、カーソルはこれに使用されます:
DECLARE @SQL NVARCHAR(MAX) DECLARE cur CURSOR LOCAL READ_ONLY FORWARD_ONLY FOR SELECT ' ALTER INDEX [' + i.name + N'] ON [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + '] ' + CASE WHEN s.avg_fragmentation_in_percent > 30 THEN 'REBUILD WITH (SORT_IN_TEMPDB = ON)' ELSE 'REORGANIZE' END + ';' FROM ( SELECT s.[object_id] , s.index_id , avg_fragmentation_in_percent = MAX(s.avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s WHERE s.page_count > 128 -- > 1 MB AND s.index_id > 0 -- <> HEAP AND s.avg_fragmentation_in_percent > 5 GROUP BY s.[object_id], s.index_id ) s JOIN sys.indexes i WITH(NOLOCK) ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = s.[object_id] OPEN cur FETCH NEXT FROM cur INTO @SQL WHILE @@FETCH_STATUS = 0 BEGIN EXEC sys.sp_executesql @SQL FETCH NEXT FROM cur INTO @SQL END CLOSE cur DEALLOCATE cur
インデックスの再構築プロセスを高速化するには、 SORT_IN_TEMPDBオプションを追加で指定することをお勧めします。 また、 オンラインオプションについても別途言及する必要があります。これにより、インデックスの再作成が遅くなります。 しかし、時には便利です。 たとえば、クラスター化インデックスからの読み取りは非常に高価です。 カバリングインデックスを作成し、パフォーマンスの問題を解決しました。 次に、 REBUILD非クラスター化インデックスを作成します。 この時点で、クラスター化インデックスを再度使用する必要があります。これにより、パフォーマンスが低下します。
SORT_IN_TEMPDBを使用すると、 tempdbデータベースにインデックスを再構築できます。これは、メモリが不十分な場合に大きなインデックスを作成する場合に特に便利です。そうしないと、オプションは無視されます。 さらに、 tempdbデータベースが別のディスクにある場合、これによりインデックスの作成にかかる時間が大幅に短縮されます。 ONLINEを使用すると、このインデックスが作成されたオブジェクトへのクエリをブロックすることなく、インデックスを再作成できます。
実践が示しているように、断片化の程度が低いか、ページ数が少ないインデックスを最適化しても、インデックスを操作する際の生産性の向上に寄与する顕著な改善はもたらされません。
さらに、カーソルを使用せずに上記のクエリを書き換えることができます。
DECLARE @IsDetailedScan BIT = 0 , @IsOnline BIT = 0 DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = ( SELECT ' ALTER INDEX [' + i.name + N'] ON [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + '] ' + CASE WHEN s.avg_fragmentation_in_percent > 30 THEN 'REBUILD WITH (SORT_IN_TEMPDB = ON' -- Enterprise, Developer + CASE WHEN SERVERPROPERTY('EditionID') IN (1804890536, -2117995310) AND @IsOnline = 1 THEN ', ONLINE = ON' ELSE '' END + ')' ELSE 'REORGANIZE' END + '; ' FROM ( SELECT s.[object_id] , s.index_id , avg_fragmentation_in_percent = MAX(s.avg_fragmentation_in_percent) FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, CASE WHEN @IsDetailedScan = 1 THEN 'DETAILED' ELSE 'LIMITED' END) s WHERE s.page_count > 128 -- > 1 MB AND s.index_id > 0 -- <> HEAP AND s.avg_fragmentation_in_percent > 5 GROUP BY s.[object_id], s.index_id ) s JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = s.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)') PRINT @SQL EXEC sys.sp_executesql @SQL
その結果、両方のクエリを実行すると、問題のあるインデックスを最適化するクエリが生成されます。
ALTER INDEX [IX_TransactionHistory_ProductID] ON [Production].[TransactionHistory] REORGANIZE; ALTER INDEX [IX_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID] ON [Production].[TransactionHistory] REBUILD WITH (SORT_IN_TEMPDB = ON, ONLINE = ON); ALTER INDEX [IX_TransactionHistoryArchive_ProductID] ON [Production].[TransactionHistoryArchive] REORGANIZE;
実際、これはデータベースの保守計画を作成する最初の部分です。 次のパートでは、 統計を自動的に更新するクエリを作成します。
この記事を英語圏の聴衆と共有したい場合:
SQL Serverの一般的なメンテナンスプラン:自動インデックスデフラグ
更新2016-04-22:個々のセクションを最適化する機能を追加し、いくつかのバグを修正しました
USE ... DECLARE @PageCount INT = 128 , @RebuildPercent INT = 30 , @ReorganizePercent INT = 10 , @IsOnlineRebuild BIT = 0 , @IsVersion2012Plus BIT = CASE WHEN CAST(SERVERPROPERTY('productversion') AS CHAR(2)) NOT IN ('8.', '9.', '10') THEN 1 ELSE 0 END , @IsEntEdition BIT = CASE WHEN SERVERPROPERTY('EditionID') IN (1804890536, -2117995310) THEN 1 ELSE 0 END , @SQL NVARCHAR(MAX) SELECT @SQL = ( SELECT ' ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(s2.name) + '.' + QUOTENAME(o.name) + ' ' + CASE WHEN s.avg_fragmentation_in_percent >= @RebuildPercent THEN 'REBUILD' ELSE 'REORGANIZE' END + ' PARTITION = ' + CASE WHEN ds.[type] != 'PS' THEN 'ALL' ELSE CAST(s.partition_number AS NVARCHAR(10)) END + ' WITH (' + CASE WHEN s.avg_fragmentation_in_percent >= @RebuildPercent THEN 'SORT_IN_TEMPDB = ON' + CASE WHEN @IsEntEdition = 1 AND @IsOnlineRebuild = 1 AND ISNULL(lob.is_lob_legacy, 0) = 0 AND ( ISNULL(lob.is_lob, 0) = 0 OR (lob.is_lob = 1 AND @IsVersion2012Plus = 1) ) THEN ', ONLINE = ON' ELSE '' END ELSE 'LOB_COMPACTION = ON' END + ')' FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.indexes i ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id LEFT JOIN ( SELECT c.[object_id] , index_id = ISNULL(i.index_id, 1) , is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END) , is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END) FROM sys.columns c LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id AND i.index_id > 0 WHERE c.system_type_id IN (34, 35, 99) OR c.max_length = -1 GROUP BY c.[object_id], i.index_id ) lob ON lob.[object_id] = i.[object_id] AND lob.index_id = i.index_id JOIN sys.objects o ON o.[object_id] = i.[object_id] JOIN sys.schemas s2 ON o.[schema_id] = s2.[schema_id] JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id WHERE i.[type] IN (1, 2) AND i.is_disabled = 0 AND i.is_hypothetical = 0 AND s.index_level = 0 AND s.page_count > @PageCount AND s.alloc_unit_type_desc = 'IN_ROW_DATA' AND o.[type] IN ('U', 'V') AND s.avg_fragmentation_in_percent > @ReorganizePercent FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') PRINT @SQL --EXEC sys.sp_executesql @SQL