まず、私は平凡であり、よく知られている真実を繰り返します。 アプリケーションをスケーリングするには2つの方法があります。
1)垂直スケーリングは、システムの各コンポーネント(プロセッサ、RAM、その他のコンポーネント)のパフォーマンスの向上です。
2)水平、いくつかの要素が一緒に接続され、システム全体が一般的な問題を解決する多くのコンピューティングノードで構成されているため、システムの全体的な信頼性と可用性が向上します。 また、システムにノードを追加することで生産性が向上します。
最初のアプローチは悪くはありませんが、大きなマイナス(1つのコンピューティングノードの制限された電力)があり、プロセッサコアとバス帯域幅の周波数を無限に増やすことは不可能です。
したがって、パフォーマンスの不足によりノード(またはノードのグループ)をシステムに追加できるため、水平スケーリングは垂直兄弟よりも大幅に優れています。
最近、私たちは実際に水平スケーリングのすべての喜びをもう一度理解しました:アメリカンフットボールのファンのための信頼性の高いソーシャルサービスを構築し、毎分200,000リクエストのピーク負荷に耐えました。 したがって、アマゾンウェブサービスインフラストラクチャで高度にスケーラブルなシステムを作成した経験についてお話したいと思います。
通常、Webアプリケーションのアーキテクチャは次のとおりです。
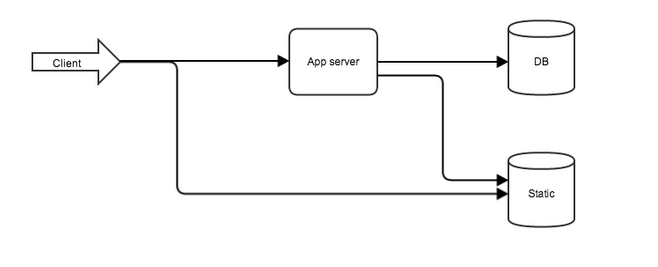
図 1.典型的なWebアプリケーションアーキテクチャ
- Webサーバーはユーザーに最初に「会う」ため、静的リソースを返し、アプリケーションに要求を送信するタスクが肩に割り当てられます。
- さらに、リレーはアプリケーションに渡され、すべてのビジネスロジックとデータベースとのやり取りが行われます。
ほとんどの場合、システムのボトルネックはアプリケーションコードとデータベースであるため、それらの並列化の可能性を考慮する価値があります。 使用したもの:
- 開発言語とコアフレームワーク-Java 7およびRest Jersey
- アプリケーションサーバー-Tomcat 7
- データベース-MongoDB(NoSQL)
- キャッシュシステム-memcached
いかがでしたか、とげを介して高負荷に
ステップ1:分割して征服する
まず、コードとデータベースクエリを可能な限り最適化し、実行するタスクの性質に応じて、アプリケーションをいくつかの部分に分割します。 別々のサーバーで次を取り出します。
- アプリケーションサーバー
- データベースサーバー
- 静的リソースを持つサーバー。
システムの各参加者には個別のアプローチがあります。 したがって、解決するタスクの性質に最も適したパラメーターを持つサーバーを選択します。
アプリケーションサーバー
アプリケーションは、最大数のプロセッサコアを備えたサーバーに最適です(多数の同時ユーザーにサービスを提供するため)。 Amazonは、これらの目的に最適なコンピューター最適化インスタンスのセットを提供します。
データベースサーバー
データベース作業とは何ですか? -多数のディスクI / O操作(データの書き込みと読み取り)。 ここでは、最速のハードドライブ(SSDなど)を備えたサーバーが最適なオプションになります。 繰り返しになりますが、Amazonは喜んでストレージ最適化インスタンスを提供しますが、将来的にはスケーリングするため、汎用(大またはx大)ラインのサーバーも適しています。
静的リソース
静的リソースの場合、強力なプロセッサも大量のRAMも必要ありません。ここでは、Amazon Simple Storage Serviceの静的リソースサービスが選択されます。
アプリケーションを分割して、図に示す回路に持ってきました。 1。
共有の利点:
- システムの各要素は、可能な限りそのニーズに合わせてマシン上で動作します。
- データベースをクラスタリングする機会があります。
- システムのさまざまな要素を個別にテストして、弱点を見つけることができます。
ただし、アプリケーション自体はまだクラスター化されておらず、キャッシュサーバーやセッションレプリケーションもありません。
ステップ2:実験
正確な実験とアプリケーションパフォーマンステストを行うには、十分に広いチャネルを持つ1台以上のマシンが必要です。 ユーザーアクションは、Apache Jmeterユーティリティを使用してエミュレートされます。 サーバーからの実際のアクセスログをテストデータとして使用したり、ブラウザーをプロキシして実行するために数百の並列スレッドを実行したりすることができるため、優れています。
ステップ3:負荷分散
そのため、実験では、結果として得られるパフォーマンスはまだ十分ではなく、アプリケーションを搭載したサーバーは100%ロードされていることが示されました(開発されたアプリケーションのコードは弱いリンクであることが判明しました) 並列化します。 2つの新しい要素がゲームに導入されました。
- ロードバランサー
- セッションサーバー
負荷分散
判明したように、開発されたアプリケーションはそれに割り当てられた負荷に対応していないため、負荷は複数のサーバーに分割する必要があります。
ロードバランサーとして、ワイドチャネルで別のサーバーを起動し、特別なソフトウェア(haproxy []、nginx []、DNS [])を構成できますが、Amazonインフラストラクチャで作業が行われるため、既存のELBサービス(Elastic Loadバランサー)。 設定は非常に簡単で、優れたパフォーマンスインジケータがあります。 最初のステップは、バランサーに2、3台のマシンを追加するためのアプリケーションを使用して、既存のマシンのクローンを作成することです。 クローン作成はAmazon AMIを使用して行われます。 ELBは、メーリングリストに追加されたマシンの状態を自動的に監視しますこれを行うには、アプリケーションはリクエストに200コードで応答する最も単純なpingリソースを実装する必要があり、バランサーに示されます。
そのため、アプリケーションで既に2つの既存のサーバーで動作するようにバランサーを構成した後、私はバランサーを介して動作するようにDNSを構成します。
セッション複製
アプリケーションに追加の作業がない場合、または単純なRESTサービスが実装されている場合、この項目はスキップできます。 それ以外の場合は、バランシングに参加しているすべてのアプリケーションが共通セッションリポジトリにアクセスできる必要があります。 セッションを格納するために、別の大きなインスタンスが起動され、ram memcachedストレージがその上に構成されます。 セッションレプリケーションはtomcatモジュールに割り当てられます:memcached-session-manager [5]
システムは次のようになります(スキームを簡略化するために静的サーバーは省略されています)。
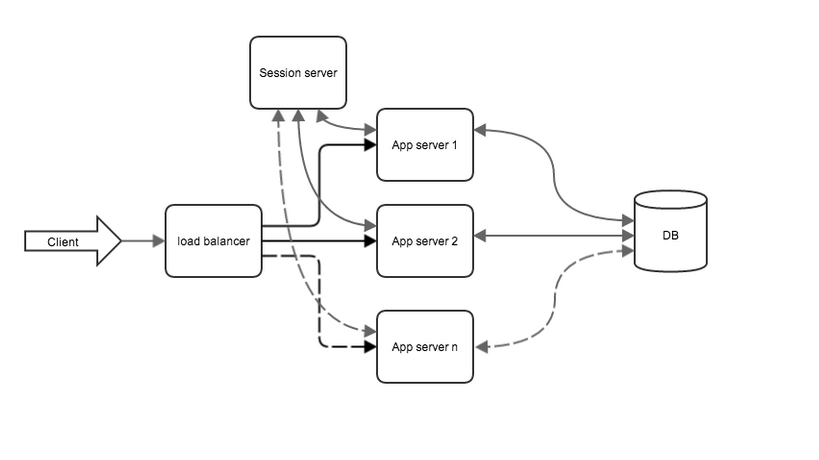
図 2.アプリケーションクラスタリング後のシステムビュー
アプリケーションクラスタリングの結果:
- システムの信頼性が向上しました。 アプリケーションでサーバーの1つに障害が発生した後でも、バランサーはメーリングリストからそのサーバーを除外し、システムは機能し続けます。
- システムのパフォーマンスを向上させるには、アプリケーションに別のコンピューティングノードを追加するだけです。
- ノードを追加することで、1分あたり70,000リクエストのピークパフォーマンスを達成できました。
アプリケーションを使用するサーバーの数が増えると、データベースの負荷も増加しますが、これは時間の経過とともに対処できなくなります。 データベースの負荷を減らす必要があります。
ステップ4:データベースを使用した作業の最適化
そのため、Apache Jmeterを使用して負荷テストを再度実行しますが、今回はすべてデータベースのパフォーマンスに依存します。 データベースでの作業を最適化するには、クエリデータのキャッシュと読み取り要求のデータベースレプリケーションの2つのアプローチを使用します。
キャッシング
キャッシングの主な考え方は、要求されたデータがほとんどの場合RAMに保存されることを確認することであり、クエリを繰り返すときに最初に確認することは、要求されたデータがキャッシュにあるかどうかであり、存在しない場合にのみデータベースにクエリを実行し、クエリ結果を配置しますキャッシュに。 キャッシュのために、memcachedが構成され、十分なRAMを持つ追加のサーバーが展開されました。
DBレプリケーション
アプリケーションの詳細には、書き込みよりも読み取りデータが多く含まれます。
したがって、データベースを読み取り用にクラスター化します。 この場合、データベース複製メカニズムが役立ちます。 MongoDBのレプリケーションは次のように構成されています:データベースサーバーはマスターとスレーブに分割されますが、直接データの記録はマスターのみに許可され、データは既にマスターからスレーブに同期され、読み取りはマスターとスレーブの両方から許可されています。

図 読み取り用の3 DBクラスタリング
最終:1分あたり20万リクエスト
作業の結果、システムは1分あたり200,000件のリクエストを処理するという目的を達成しました。