
ロックフリーアルゴリズムに興味を持つようになると、すぐに質問が苦しみ始めました。コードの「順序を復元する」ためのメモリバリアの必要性はどこから来たのでしょうか。
もちろん、 特定のアーキテクチャに関するマニュアルの数千ページを読んだ後、答えが見つかります。 しかし、この答えはこの特定のアーキテクチャに適しています。 共通点はありますか? 最終的には、コードを移植可能にする必要があります。 また、C ++ 11メモリモデルは特定のプロセッサ向けに調整されていません。
最も受け入れられる一般的な答えは、 ポールマッケニー氏の2010年の記事「 Memory Barriers:a Hardware View of Software Hackers」で出されました。 彼の記事の価値は一般的です。彼は、いくつかの単純化された抽象的なアーキテクチャを構築し、その例に基づいて、メモリバリアとは何か、なぜ導入されたのかを分析しました。
一般的に、ポール・マッケニーは有名人です。 彼はLinuxカーネルで積極的に使用されているRCUテクノロジーの開発者であり、積極的なプロモーターであり、メモリを安全に解放する別のアプローチとして最新バージョンのlibcdsでも実装されています(一般的に、RCUについては別に話したい)。 彼はまた、C ++ 11メモリモデルの作業にも参加しました。
記事が大きいので、前半だけの翻訳をします。 私はいくつかのコメントを追加することを許可しました[このようなテキストで強調表示されています] 。
メモリバリア:ソフトウェアハッカーのハードウェアビュー
CPU設計者がメモリバリアを導入し、それによって開発者に豚を置いたのはなぜですか? 簡単な答えは次のとおりです。メモリアクセスの順序を変更するとパフォーマンスが向上します。また、プリミティブの正確性がメモリアクセスの順序に依存する同期プリミティブ[およびもちろんロックフリーアルゴリズム]などを「クリーンアップ」するには、メモリバリアが必要です。
詳細な回答を得るには、CPUキャッシュがどのように機能するか、そしてそれをさらに改善するために何が必要かをよく理解する必要があります。 したがって、さらに:
- キャッシュの構造を考慮してください。
- キャッシュコヒーレンスプロトコルが異なるプロセッサの各メモリセルの可視性をどのように保証するかを説明します。
- キャッシュが最大のパフォーマンスを達成するために、ストアバッファと無効化キューがどのように役立つかを検討してください。
メモリバリアは、高いパフォーマンスとスケーラビリティを実現するために必要な悪であることがわかります。 この悪の根源は、CPUがメモリやプロセッサとメモリとのインターフェースよりも桁違いに速いという事実です。
キャッシュ構造

最新のCPUは、メモリサブシステムよりもはるかに高速です。 2006年のサンプルプロセッサはナノ秒あたり10命令を実行できましたが、メインメモリからデータを抽出するには数十ナノ秒かかりました。 この速度の不均衡(2桁以上!)は、最新のプロセッサでマルチメガバイトキャッシュにつながっています。 キャッシュはプロセッサに属し、原則として、キャッシュへのアクセス時間は数クロックサイクルです。
ご注意
実際、一般的な方法はいくつかのレベルのキャッシュを持つことです。 ボリューム内の最小キャッシュはプロセッサに最も近く、1クロックサイクルで使用可能です。 2次キャッシュのアクセス時間は約10クロックサイクルです。 ほとんどの生産的なプロセッサには、3つまたは4つのキャッシュレベルがあります
CPUは、キャッシュラインと呼ばれるキャッシュブロックとデータを交換します。 キャッシュラインのサイズは、通常2の累乗で、16〜256バイト(CPUに依存)です。 プロセッサが最初にメモリセルにアクセスするとき、セルはキャッシュにありません。この状況は、 ミス (キャッシュミス、より正確には「スタートアップ」または「ウォームアップ」キャッシュミス)と呼ばれます。 ミスとは、データがメモリから取得されるまで、CPUが数百サイクル待機する(停止する)ことを意味します。 最後に、データがキャッシュにロードされ、このアドレスへの後続のアクセスでキャッシュ内のデータが検出されるため、CPUはフルスピードで実行されます。
しばらくすると、キャッシュがいっぱいになり、ミスが発生すると、キャッシュからデータが絞り出され、新しく要求されたデータに場所が与えられます。 このようなミスは、キャパシティミスと呼ばれます。 さらに、キャッシュは、 バケットサイズが固定されたハッシュテーブル(またはCPU開発者が呼び出すセット )としてハードウェアで編成されているため、キャッシュがいっぱいでない場合でも発生する可能性があります。
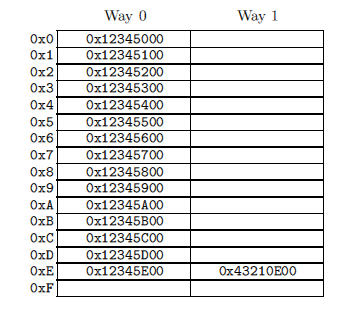
右の図は、256バイトのキャッシュラインを持つ2連想(2ウェイ)キャッシュを示しています。 行は空の場合があります。これは、テーブル内の空のセルに対応します。 左側の数字は、セルに含めることができるアドレスです。 行は256バイトで整列しているため、アドレスの下位8ビットはゼロであり、ハッシュ関数は次の4ビットをハッシュテーブルのインデックスとして選択します。 プログラムコードがアドレス0x43210E00-0x43210EFFにあり、プログラム自体がアドレス0x12345000-0x12345EFFのデータにアクセスするとします。 次に、アドレス0x12345F00に移動させます。 このアドレスは0xF行でハッシュされ、この行の両方のセルは空であるため、256バイトのデータをどちらか一方に入れることができます。 プログラムが0x1233000でアクセスし、そのハッシュが0x0である場合、対応する256バイトのデータを0x0行のセル1(ウェイ1)に配置できます。 プログラムがアドレス0x1233E00(ハッシュ= 0xE)にアクセスする場合、新しい256バイトのデータ用にスペースを解放するために、いずれかの行(ウェイ)をキャッシュからプッシュする必要があります。 後でこのプッシュされたデータにアクセスする必要がある場合、ミスが発生します。 このような失敗は、結合性ミスと呼ばれます。
これはすべてデータの読み取りに関するもので、書き込みを行うとどうなりますか? すべてのCPUはデータに従って一貫している必要があるため、書き込みの前に、他のCPUのキャッシュからデータを削除(無効化)する必要があります。 無効化が完了すると、プロセッサは安全にデータを記録できます。 データがCPUキャッシュにあるが読み取り専用の場合、これは書き込みミスと呼ばれます。 CPUが他のプロセッサのキャッシュにあるそのようなデータを無効にした後にのみ、CPUはこのデータを再書き込み(および読み取り)できます。 さらに、あるCPUがデータへのアクセスを試みているときに、別のCPUが書き込みのためにそれらを無効にすると、データが通信に使用されるときにこのような状況が発生するため、 通信ミスと呼ばれるミスを受け取ります、ミューテックスまたはスピンロック[ミューテックス自体を指し、保護するデータではありません。 mutexは何らかのフラグです] 。
ご覧のとおり、すべてのCPUのデータの一貫性を管理するには、多大な努力が必要です。 こうした読み取り/無効化/書き込みがすべて行われると、データが失われたり、(さらに悪いことに)CPUごとにキャッシュ内のデータが異なることは容易に想像できます。 これらの問題は、データ一貫性プロトコルによって対処されています。
キャッシュ一貫性プロトコル
このプロトコルはキャッシュラインの状態を制御し、整合性を確保してデータ損失を防ぎます。 そのようなプロトコルは非常に複雑で、数十の状態がありますが、ここでは4つの状態を持つMESIプロトコルを検討するだけで十分です。
MESIの状態
MESIは4つの可能なキャッシュライン状態です:Modified-Exclusive-Shared-Invalid。 このプロトコルをサポートするには、データ自体に加えて、各行にその状態を格納する2ビットのタグが必要です。
変更されたステータスは、キャッシュラインのデータがキャッシュのプロセッサ所有者によって書き込まれたばかりであり、変更が他のCPUのキャッシュにまだ現れていないことを保証します。 1つのCPUがデータを所有していると言えます。 そのような行のデータは最も新しいので、キャッシュの行はメモリ(または次のレベルのキャッシュ)に書き込む準備ができており、行を他のデータで埋める前にレコードを作成する必要があります。
Exclusive状態は、キャッシュを所有するプロセッサによってデータがまだ変更されていないことを除いて、Modifiedと非常に似ています。 これは、その行がメモリと一致する最新のデータを含むことを意味します。 CPU所有者は、他のCPUに通知することなく、いつでもこのキャッシュラインに書き込むことができます。また、メモリに書き戻すことなく強制的にキャッシュラインに書き込むことができます。
共有ステータスは、ラインが他のCPUの少なくとも1つの他のキャッシュに複製されていることを示します。 このような行のCPU所有者は、他のCPUとの事前の調整なしにそれに書き込むことはできません。 排他的状態に関しては、ラインはメモリに合わせられ、他のCPUに通知したり、メモリに書き戻したりせずに強制的に出力できます。
無効状態のキャッシュラインは空です。つまり、データが含まれていません(またはガベージが含まれています)。 新しいデータをキャッシュにロードする必要がある場合、可能な限り無効な行に配置されます。
すべてのCPUはシステムのキャッシュ全体の一貫性を維持する必要があるため、プロトコルはすべてのプロセッサーのキャッシュラインのステータスの変化を調整するメッセージを記述します。
MESIプロトコルメッセージ
ある状態から別の状態への遷移の多くは、CPU間の相互作用を必要とします。 すべてのCPUが単一の共有バスに接続されている場合、次のメッセージで十分です。
- 読み取り :このメッセージには、読み取り中のキャッシュラインの物理アドレスが含まれます。
- 読み取り応答 :前の読み取りメッセージで要求されたデータが含まれます。 読み取り応答は、メモリサブシステムまたは別のキャッシュから送信される場合があります。 たとえば、データが既に「変更済み」状態のキャッシュにある場合、そのようなキャッシュは読み取りに応答する可能性があります
- 無効化 : 無効にするキャッシュラインの物理アドレスが含まれます。 他のすべてのキャッシュはデータを削除し、このメッセージに返信する必要があります。
- Invalidate Acknowledge : Invalidateを受信したCPUは、必要なデータを削除し、 Invalidate Acknowledgeで確認する必要があります
- 無効化の読み取り :このメッセージには、読み取り中のキャッシュラインの物理アドレスが含まれます。 同時に、このデータを削除するよう他のキャッシュに指示します。 これは、基本的に読み取りメッセージと無効化メッセージの組み合わせです。 このメッセージには、 Read Response応答と複数のInvalidate Acknowledgeが必要です
- ライトバック :メモリに書き込むためのアドレスと実際のデータが含まれます。 キャッシュが変更状態の対応する行をフラッシュできるようにします。
ご覧のとおり、マルチプロセッサマシンはメッセージングシステムであり、本質的にはプロセッサカバーの下にあるコンピュータです。
質疑応答
2つのプロセッサが同じキャッシュラインを同時に無効にするとどうなりますか?
それらの1つ(「勝者」)が最初に共有バスにアクセスします。 他のCPUは、このキャッシュラインのコピーを無効にし、「無効化確認」で応答する必要があります。 もちろん、「負けた」CPUは即座に読み取り無効化トランザクションを開始できるため、勝ちは短命になる可能性があります。
大規模なマルチプロセッサシステムで「無効化」というメッセージが表示された場合、すべてのCPUは「無効化確認」で応答する必要があります。 そのような答えの爆発的な流れは、システムの完全なシャットダウンにつながりますか?
はい、大規模なシステムがこのように構築されていれば可能です。 しかし、たとえばNUMAのようなシステムは、通常、そのような場合を防ぐためだけに、 ディレクトリベースの [NUMAのディレクトリ-ノード、ノード]キャッシュ一貫性サポートプロトコルを使用します。
それらの1つ(「勝者」)が最初に共有バスにアクセスします。 他のCPUは、このキャッシュラインのコピーを無効にし、「無効化確認」で応答する必要があります。 もちろん、「負けた」CPUは即座に読み取り無効化トランザクションを開始できるため、勝ちは短命になる可能性があります。
大規模なマルチプロセッサシステムで「無効化」というメッセージが表示された場合、すべてのCPUは「無効化確認」で応答する必要があります。 そのような答えの爆発的な流れは、システムの完全なシャットダウンにつながりますか?
はい、大規模なシステムがこのように構築されていれば可能です。 しかし、たとえばNUMAのようなシステムは、通常、そのような場合を防ぐためだけに、 ディレクトリベースの [NUMAのディレクトリ-ノード、ノード]キャッシュ一貫性サポートプロトコルを使用します。
MESI状態図

右側の図の遷移には、次の意味があります。
- 遷移a(M-> E) :キャッシュラインはメモリに書き戻されますが、CPUはキャッシュに残し、変更する権利を持っています。 この移行には、「ライトバック」メッセージが必要です。
- 移行b(E-> M) :CPUはキャッシュラインに書き込みます。キャッシュラインには排他的アクセスがあります。 この移行にはメッセージは必要ありません。
- 遷移c(M-> I) :CPUは、「変更」状態の「読み取り無効化」キャッシュラインメッセージを受信します。 CPUはそのローカルコピーを削除し、「読み取り応答」および「無効化確認」メッセージで応答する必要があります。 したがって、CPUはデータを送信し、自宅にデータのコピーがないことを示します
- 移行d(I-> M) :CPUは、キャッシュにないデータに対して読み取り-変更-書き込み(RMW)操作を実行します。 「読み取り無効化」信号を送信し、「読み取り応答」でデータを受信します。 CPUは、すべての「確認応答の無効化」応答を受信した場合にのみ移行を完了します。
- 遷移e(S-> M) :CPUは、読み取り専用であったデータに対して読み取り-変更-書き込み(RMW)操作を実行します。 「無効化」信号を開始し、「無効化確認」応答の完全なセットを受信するまで待機する必要があります。
- 遷移f(M-> S) :他のプロセッサーがデータを読み取っており、このデータはCPUのキャッシュにあります。 その結果、データは読み取り専用になり、メモリへの書き込みにつながる可能性があります。 この遷移は、読み取り信号によってトリガーされます。 CPUは、要求されたデータを含む「読み取り応答」メッセージで応答します。
- 遷移g(E-> S) :他のプロセッサがデータを読み込んでおり、このデータはCPUのキャッシュにあります。 データは共有されるため、読み取り専用になります。 遷移は、「読み取り」信号を受信することにより開始されます。 CPUは、要求されたデータを含む「読み取り応答」メッセージで応答します。
- 遷移h(S-> E) :CPUは、キャッシュラインにデータを書き込む必要があると判断し、「無効化」メッセージを送信します。 CPUが「無効化確認応答」の完全なセットを受信するまで、移行は完了しません。 他のCPUは、「ライトバック」メッセージを使用してキャッシュからキャッシュラインをスローするため、このデータをキャッシュするのはCPUだけになります。
- 遷移i(E-> I) :別のCPUがCPUが所有するデータに対してRMW操作を実行し、プロセッサがキャッシュラインを無効にするようにします。 遷移は「read invalidate」というメッセージで始まり、CPUは「read response」および「invalidate acknowledge」というメッセージで応答します。
- 遷移j(I-> E) :CPUはデータを新しいキャッシュラインに保存し、「読み取り無効化」メッセージを送信します。 CPUは、「読み取り応答」と「無効化確認応答」の完全なセットを受信するまで、移行を完了できません。 記録が完了するとすぐに、キャッシュラインは遷移(b)により「変更」状態になります
- 遷移k(I-> S) :CPUはデータを新しいキャッシュラインにロードします。 CPUは「読み取り」メッセージを送信し、「読み取り応答」を受信することで遷移を完了します
- 遷移l(S-> I) :別のCPUがデータをキャッシュラインに格納します。キャッシュラインは読み取り専用ステータスです。これは、3番目のCPU(または、たとえば私たちのもの)がデータを共有するためです。 移行は「無効化」を受け入れることから始まり、CPUは「無効化確認」で応答します
質疑応答
鉄は、複数の遅延を必要とするこのような重い遷移をどのように処理しますか?
通常、追加の状態を導入します。 ただし、このような状態はキャッシュラインに保存する必要はありません。つまり、キャッシュライン状態ではありません。 各時点で、遷移状態にできるのは少数のキャッシュラインのみです。 ここで説明する簡略化されたMESIよりも実際のキャッシュコヒーレンシサポートプロトコルをはるかに複雑にするのは、時間的に分散した重い遷移の存在です。
通常、追加の状態を導入します。 ただし、このような状態はキャッシュラインに保存する必要はありません。つまり、キャッシュライン状態ではありません。 各時点で、遷移状態にできるのは少数のキャッシュラインのみです。 ここで説明する簡略化されたMESIよりも実際のキャッシュコヒーレンシサポートプロトコルをはるかに複雑にするのは、時間的に分散した重い遷移の存在です。
MESIプロトコルの例
MESIがキャッシュラインに関してどのように機能するかを、メモリをキャッシュに直接マッピングする4プロセッサシステムの例を使用して見てみましょう。 データはメモリのアドレス0にあります。次の表に、データの変更を示します。 最初の列は操作のシリアル番号、2番目は操作を実行するプロセッサーの番号、3番目は操作、次の4列は各CPUのキャッシュラインのステータス(メモリアドレス/状態の形式)、最後の2列はメモリに正しいデータが含まれている(V)またはない(I)。

まず、CPUのキャッシュラインが「無効」状態にあり、メモリに正しいデータが含まれています。 CPU 0がアドレス0のデータを読み取ると、CPU 0のキャッシュラインは「共有」状態になり、メモリと一致します。 CPU 3はアドレス0のデータも読み取るため、キャッシュラインは両方のCPUのキャッシュで「共有」状態になりますが、それでもメモリと整合しています。 次に、CPU 0はアドレス8のデータをロードします。これにより、キャッシュラインが混み合い、新しいデータが追加されます(アドレス8で読み取られます)。 次に、CPU 2はアドレス0のデータを読み取りますが、データを書き込む必要があることを認識し(RMW操作)、「読み取り無効化」信号を使用してデータの排他コピーがあることを確認します。 「read invalidate」信号は、CPU 3のキャッシュラインを無効にします(ただし、そのデータはメモリと一貫性があります)。 次に、CPU 2は書き込みを行いますが、これはRMW操作の一部であり、キャッシュラインを「変更済み」状態にします。 メモリ内のデータは廃止されました。 CPU 1はアトミックインクリメントを実行し、読み取り無効化信号を使用してデータを受信します。 CPU 2キャッシュからデータを受信し、CPU 2自体ではデータが無効になります。 その結果、CPU 1のキャッシュラインのデータは「変更」状態にあり、まだメモリと整合していません。 最後に、CPU 1はアドレス8のデータを読み取り、キャッシュラインをメモリにフラッシュします(「ライトバック」メッセージを使用)。
「質問と回答」
サンプルを停止したとき、キャッシュにはいくつかのデータが含まれています。 また、すべてのCPUのキャッシュラインを「無効化」状態にするための一連の操作はどうでしょうか。
CPUが特別なキャッシュリセット命令(「キャッシュをフラッシュ」)をサポートしない限り、このようなシーケンスは存在しません。 ほとんどのプロセッサにはこの命令があります。
CPUが特別なキャッシュリセット命令(「キャッシュをフラッシュ」)をサポートしない限り、このようなシーケンスは存在しません。 ほとんどのプロセッサにはこの命令があります。
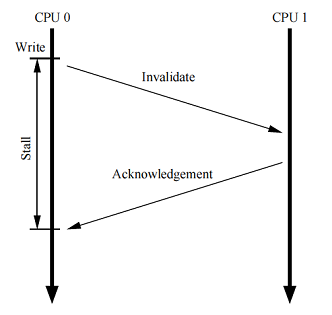
不要な録音ダウンタイム
前に確認したキャッシュ構造は、このデータを所有するCPUに対して優れた読み取り/書き込みパフォーマンスを提供しますが、特定のキャッシュラインへの最初の書き込みのパフォーマンスは非常に低くなります。 これを確認するには、右の図を検討してください。
この図は、CPU 1のキャッシュにあるキャッシュラインのプロセッサ0による書き込み遅延を示しています。CPU0は、キャッシュラインが書き込み可能になるまでかなり長い時間待機する必要があります。キャッシュ1からCPU 0に移行します。キャッシュラインを1つのCPUから別のCPUに転送します。通常、レジスタを操作する命令の期間よりも桁違いに長くなります。
ただし、CPU 0の場合、それほど長く待つ必要はありません。CPU1から送信されたデータに関係なく、CPU 0はそれらを確実に上書きします。
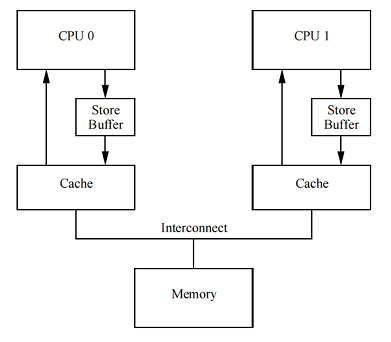
バッファを保存する
不要なダウンタイムに対処する1つの方法は、右の図に示すように、各CPUとそのキャッシュの間にストアバッファーを追加することです。 このようなバッファーを使用すると、CPU 0は単純に書き込み操作をストアバッファーに書き込み、作業を続行できます。 必要なメッセージングの後、キャッシュラインが最終的にCPU 1からCPU 0に移動すると、データはストアバッファーからプロセッサ0のキャッシュラインに移動できます。
ただし、このようなソリューションは追加の問題につながります。これについては、次の2つのセクションで検討します。
ストア転送
自己整合性と呼ばれる最初の問題を確認するには、次のコードを検討してください。
1 a = 1; 2 b = a + 1; 3 assert( b == 2 );
変数「a」と「b」の初期値は0です。変数「a」はプロセッサ1のキャッシュにあり、変数「b」はプロセッサ0のキャッシュにあります。
どうやったらこれ
assert
機能するのでしょうか? ただし、示されているアーキテクチャのプロセッサを誰かが実装した場合、彼は驚いたでしょう。 このようなシステムでは、次の一連のイベントが発生する可能性があります。
- 1. CPU 0は
a = 1
実行を開始します - 2. CPU 0は、キャッシュに「a」があるかどうかを確認し、そうでないものを確認します。
- 3.したがって、CPU 0は、「a」でキャッシュラインの排他的権利を取得するために、「読み取り無効化」信号を送信します。
- 4. CPU 0がストアバッファに「a」を書き込む
- 。 CPU 1は「読み取り無効化」メッセージを受信し、「a」からキャッシュラインを送信し、そのキャッシュラインを削除(無効化)することで応答します。
- 6. CPU 0は
b = a + 1
実行を開始します - 7. CPU 0はCPU 1から応答を受信します。これには、古いゼロの 「a」値も含まれており、その行をキャッシュに入れます
- 8. CPU 0はキャッシュから「a」をロードします- 値ゼロがロードされます
- 9. CPU 0は、ストアバッファに保存されたキャッシュに書き込む要求を実行し、値「a」= 1をキャッシュラインに書き込みます
- 10. CPU 0は1をゼロに加算し、以前に「a」として読み取り、結果をキャッシュライン「b」に保存します(これは思い出すように、CPU 0が所有しています)
- 11. CPU 0は
assert(b == 2)
実行assert(b == 2)
、エラーをスローします-assert
トリガーされます
問題は、「a」のコピーが2つあることです。1つはキャッシュに、もう1つはストアバッファーにあります。
この例は非常に重要な保証に違反します 。 各CPUは常にプログラムで指定された順序 (いわゆるプログラム順序 )で操作を実行する必要があります 。 プログラマにとって、この保証は直感的な要件であるため、ハードウェアエンジニアはストア転送を実装する必要がありました。各CPUは、キャッシュからだけでなく、ストアバッファからもデータを読み取ります。 つまり、各書き込み操作は、キャッシュにアクセスすることなく、ストアバッファーを介して次の読み取り操作に直接転送できます。
ストア転送では、上記の例のステップ8は、ストアバッファから変数「a」の正しい値1を読み取る必要があります。 その結果、「b」の値は2になります。これは必要なものです。
書き込みバッファとメモリバリア
グローバルメモリの順序の違反という別の問題を確認するには、変数「a」と「b」の初期値が0である次の例を考えてください。
1 void foo() 2 { 3 a = 1; 4 b = 1; 5 } 6 7 void bar() 8 { 9 while ( b == 0 ) continue; 10 assert( a == 1 ); 11 }
CPU 0が
foo()
、CPU 1が
bar()
実行し
bar()
。 「a」を含むメモリがCPU 1のキャッシュのみにあり、CPU 0が「b」を含むメモリを所有しているとします。 その後、次の一連のアクションが可能です。
- 1. CPU 0は
a=1
実行a=1
ます。 「a」のキャッシュラインはCPU 0のキャッシュにないため、CPU 0は新しい値「a」を書き込みバッファに配置し、「読み取り無効化」信号を発信します。 - 2. CPU 1は
while (b==0) continue
で実行while (b==0) continue
ますが、「b」はキャッシュにないため、「read」メッセージを送信します - 3. CPU 0は
b = 1
実行します。 彼はすでにキャッシュに「b」を所有しています。つまり、対応するキャッシュラインは「排他的」または「変更」状態にあるため、誰にも言わずに新しい「b」値をキャッシュに保存するすべての権利があります。 - 4. CPU 0はメッセージ「read」を受信し、応答で最新の値「b」を含むキャッシュラインを送信し、同時にこのラインをキャッシュ内の「共有」状態に転送します。
- 5. CPU 1は、「b」のキャッシュラインを受信し、キャッシュに入れます
- 6. CPU 1は、
b == 1
であることがわかるので、while (b == 0) continue
完了し、次の命令に進むことができます。 - 7. CPU 1は
assert(a == 1)
実行assert(a == 1)
ます。 CPU 1は古い値「a」で動作するため、条件は満たされない - 8. CPU 1は「read invalidate」というメッセージを受信し、「a」CPU 0のキャッシュラインを送信すると同時に、キャッシュ内のこのラインを無効にします。 遅すぎる
- 9. CPU 0は、「a」のキャッシュラインを受信し、バッファーから書き込みます(ストアバッファーをキャッシュにフラッシュします)。
質疑応答
ステップ1のCPU 0が「無効化」だけでなく「無効化の読み取り」というメッセージを送信するのはなぜですか?
キャッシュラインには変数「a」の値だけが含まれているわけではないからです。 キャッシュラインサイズは非常に大きいです。
キャッシュラインには変数「a」の値だけが含まれているわけではないからです。 キャッシュラインサイズは非常に大きいです。
プロセッサはプログラム内の変数の関係について何も知らないため、ハードウェアエンジニアはこの場合に支援できません。 そのため、エンジニアは、プログラマーがプログラムで同様のデータ関係を表現できるメモリバリア命令を導入しました。 プログラムの断片は次のように変更する必要があります。
1 void foo() 2 { 3 a = 1; 4 smp_mb(); 5 b =1; 6 } 7 8 void bar() 9 { 10 while ( b == 0 ) continue; 11 assert( a == 1 ); 12 }
メモリバリア
smp_mb()
[これはLinuxカーネルの実際の機能]は、次のキャッシュエントリを作成する前にストアバッファをリセットするようにプロセッサに指示します。 CPUは、ストアバッファが空になるのを待つのをやめるか、ストアバッファ内のすべてのエントリが完了するまでストアバッファを後続のエントリに使用できます[したがって、FIFOの一部がストアバッファに配置されます] 。
プログラムバリアシーケンス
- 1. CPU 0は
a=1
実行a=1
ます。 「a」のキャッシュラインはCPU 0のキャッシュにないため、CPU 0は新しい値「a」を書き込みバッファに配置し、「読み取り無効化」信号を発信します。 - 2. CPU 1は
while (b==0) continue
で実行while (b==0) continue
ますが、「b」はキャッシュにないため、「read」メッセージを送信します - 3. CPU 0は
smp_mb()
を実行し、ストアバッファー内のすべてのアイテム(a = 1
を含むsmp_mb()
をマーク(マーク)します。 - 4. CPU 0は
b = 1
実行します。 彼はすでに「b」を所有しています(つまり、対応するキャッシュラインは「変更済み」または「排他的」状態です)が、書き込みバッファにはマークされた要素があります。 したがって、新しい値「b」をキャッシュに書き込む代わりに、書き込みバッファに「b」を配置しますが、 マークされていない要素として - 5. CPU 0は「読み取り」メッセージを受信し、初期値「b」(= 0)のキャッシュラインをプロセッサ1に渡します。また、キャッシュラインの状態を「共有」に変更します。
- 6. CPU 1は「b」のキャッシュラインを受信し、キャッシュに入れます
- 7. CPU 1は
while (b == 0) continue
完了する可能性がありますが、b=0
であることがわかるため、ループを続行する必要があります。 新しい値「b」は、CPU 0の書き込みバッファにまだ隠されています - 8. CPU 1は「read invalidate」というメッセージを受信し、キャッシュラインを「a」からプロセッサ0に渡し、そのキャッシュラインを無効にします。
- 9. CPU 0は、「a」のキャッシュラインを受信し、以前にバッファリングされたレコードを実行し、そのキャッシュラインを「a」から「変更」状態に変更します。
- 10.エントリ「a」が
smp_mb()
呼び出しでマークされた唯一の要素であるため、CPU 0は「b」を書き込むこともできますが、「b」のキャッシュラインは「共有」状態です。 - 11.したがって、CPU 0は「無効化」メッセージをプロセッサ1に送信します
- 12. CPU 1は「無効化」信号を受信し、キャッシュに「b」を含むキャッシュラインを無効化し、プロセッサ0に「確認応答」信号を送信します。
- 13. CPU 1は
while (b == 0) continue
実行されますが、「b」のキャッシュラインはキャッシュにないため、「read」メッセージをプロセッサ0に送信します - 14. CPU 0は「確認応答」メッセージを受信し、キャッシュラインを「b」から「排他的」状態にし、「b」をキャッシュに保存します。
- 15. CPU 0は「読み取り」信号を受信し、キャッシュラインを「b」からプロセッサ1に渡します。途中で、「b」からのキャッシュラインは「共有」状態になります。
- 16. CPU 1は、「b」のキャッシュラインを受信し、キャッシュに書き込みます
- 17. CPU 1は
while (b == 0) continue
および継続while (b == 0) continue
完了することができます。 - 18. CPU 1は
assert(a == 1)
実行assert(a == 1)
ますが、「a」のキャッシュラインはキャッシュにありません。 CPU 0から値「a」を受け取るとすぐに、実行を継続できます。 値「a」は最新のものであり、assert
は機能しません
ご覧のとおり、直感的にシンプルなことでも、シリコンの多くの複雑なステップにつながります。
記録シーケンスでの不要なダウンタイム
残念ながら、各書き込みバッファは比較的小さくする必要があります。 これは、CPUが大量のレコードを実行すると、ストアバッファが完全にいっぱいになることを意味します(たとえば、各レコードがミスにつながる場合)。 この場合、CPUはすべての無効化が完了するまで待機する必要があるため、CPUはバッファーをキャッシュにフラッシュして実行を継続できます。 これらのレコードがキャッシュミスにつながるかどうかに関係なく、後続のすべての書き込み命令が無効化の完了を待機する必要がある場合、メモリバリアの直後に同じ状況が発生する可能性があります。
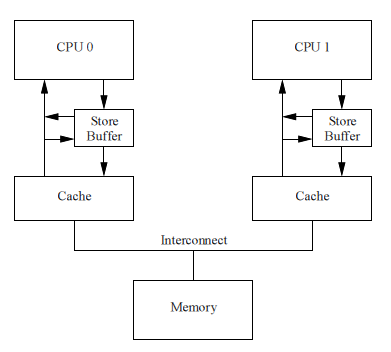
この状況は、「確認応答の無効化」メッセージの処理が高速になれば解決できます。 これを実現する1つの方法は、各CPUに対して「無効化」メッセージキューまたは無効化キューを入力することです。
キューを無効にする
確認応答メッセージの無効化が非常に遅い理由の1つは、対応するキャッシュラインが実際に無効であることをCPUが確認する必要があるためです。 このような無効化は、キャッシュがビジーの場合、たとえばプロセッサがキャッシュ内のすべてのデータを集中的に読み書きする場合、非常に長くなる可能性があります。 さらに、短期間で無効化メッセージのストリーム全体が存在し、CPUがそれらに対処できない場合があり、残りのCPUのダウンタイムにつながります。
ただし、CPUは確認を送信する前にキャッシュラインを無効にする必要はありません。 もちろん、プロセッサがこのキャッシュラインに関する他のメッセージを送信する前にこのメッセージが処理されることを完全に理解して、無効化メッセージをキューに入れることができます。

キューの無効化と障害の確認
右側の図は、無効化キューを持つシステムを示しています。 無効化キューを備えたプロセッサは、キャッシュラインが無効になるのを待つ代わりに、キューに表示されるとすぐに無効化メッセージを確認できます。 もちろん、CPUは無効化メッセージを送信する準備をするとき、そのキューと一致している必要があります。キューにこのキャッシュラインの無効化レコードが既に含まれている場合、プロセッサは無効化メッセージをすぐに送信できません。 代わりに、キューからの対応するエントリが処理されるまで待機する必要があります。
無効化キューに要素を配置することは、本質的に、このキャッシュラインに関連するMESIプロトコル信号を送信する前にこの無効化メッセージを処理することをプロセッサから約束することです。
ただし、無効化信号のバッファリングは、メモリ操作の順序を混乱させる追加の機会につながります。これについては以下で説明します。
キューとメモリバリアを無効にする
プロセッサが無効化リクエストをキューに入れ、すぐに応答するとします。 このアプローチにより、キャッシュの無効化遅延は最小限に抑えられますが、メモリバリアを破ることができます。これについては、次の例で説明します。
変数「a」と「b」は最初はゼロで、「a」は「共有」状態(つまり、読み取り専用)の両方のプロセッサのキャッシュにあり、「b」はCPU 0に所有されています(つまり、キャッシュラインは状態です) 「排他的」または「修正」。 CPU 0が
foo()
、CPU 1が
bar()
し
bar()
。
1 void foo() 2 { 3 a = 1; 4 smp_mb(); 5 b = 1; 6 } 7 8 void bar() 9 { 10 while (b == 0) continue; 11 assert(a == 1); 12 }
操作の順序は次のとおりです。
- 1. CPU 0は
a=1
実行a=1
ます。 対応するキャッシュラインはCPU 0のキャッシュでは読み取り専用であるため、プロセッサは新しい値「a」をストアバッファに入れ、メッセージ「invalidate」を送信して、CPU 1がキャッシュラインを「a」でフラッシュします。 - 2. CPU 1は
while(b == 0) continue
実行されますが、「b」はキャッシュにありません。 したがって、「読み取り」メッセージを送信します - 3. CPU 1はCPU 0から「無効化」を受信し、無効化キューに格納して、すぐに応答します
- 4. CPU 0はCPU 1から応答を受信します。したがって、
smp_mb()
(行4)を自由に実行し、新しい値「a」を書き込みバッファーからキャッシュに入れます。 - 5. CPU 0は
b=1
実行します。 「b」のキャッシュラインを既に所有しているため、新しい「b」値をキャッシュに保存するだけです。 - 6. CPU 0は「読み取り」信号を受信し、新しい値「b」のキャッシュラインをプロセッサ1に送信すると同時に、このラインを「共有」としてマークします。
- 7. CPU 1は「b」のキャッシュラインを受信し、キャッシュに入れます
- 8.これで、CPU 1は
while(b == 0) continue
しwhile(b == 0) continue
完了while(b == 0) continue
、プログラムの次の行に移動できます。 - 9. CPU 1は
assert(a == 1)
実行assert(a == 1)
ます。 古い値「a」がキャッシュにあるため、assert
発生して例外をスローします - 例外にもかかわらず、CPU 1はキューに配置された「無効化」メッセージを実行し、遅延してキャッシュライン「a」を無効化します
質疑応答
手順1で送信された「無効化の読み取り」ではなく「無効化の読み取り」が送信されるのはなぜですか? プロセッサは、同じキャッシュラインにある他の値を本当に必要としますか?
CPU 0には、これらの値がすべてあります。これらの値は、「a」とともに共有読み取り専用キャッシュラインにあるためです。 したがって、CPU 0が必要とするのは、このキャッシュラインのコピーを破棄する必要があることを他のプロセッサに通知することだけです。 これには「無効化」というメッセージで十分です。
CPU 0には、これらの値がすべてあります。これらの値は、「a」とともに共有読み取り専用キャッシュラインにあるためです。 したがって、CPU 0が必要とするのは、このキャッシュラインのコピーを破棄する必要があることを他のプロセッサに通知することだけです。 これには「無効化」というメッセージで十分です。
したがって、障害に対する反応率を改善することは、メモリバリアを無視することにつながる場合にはほとんど役に立ちません。 したがって、メモリバリアは無効化キューと対話する必要があります。プロセッサがメモリバリアを実行するとき、無効化キューが完全に処理されるまで、プロセッサは無効化キュー内のすべての要素をマークし、以降のすべての読み取りを遅くする必要があります。
読み取りと書き込みの障壁
前の章では、メモリバリアを使用してストアバッファ内のアイテムをマークし、キューを無効にしました。 ただし、最後の例では、
foo()
無効化キュー
foo()
やり取りする理由はありません(読み取りがないため)。また、
bar()
書き込みバッファー
bar()
やり取りする理由もありません(レコードがないため)。
多くのアーキテクチャは、読み取り専用または書き込み専用の整理を可能にする、より弱い(そして結果として、より速い)メモリバリアを提供します。 大まかに言うと、読み取りメモリバリアは無効化キューとのみ相互作用し(要素をマーク、つまりキューに何らかの順序を付けます)、書き込みメモリバリアはストアバッファとのみ相互作用します(要素をマークし、順序を復元します)バッファ内)。 完全な障壁が両方と相互作用します。
これらのハーフバリアの効果は次のとおりです。読み取りバリアの順序は、バリアを実行するプロセッサのみを読み取ります。 バリアの前のすべての読み取りが完全に完了し、バリアの後に読み取りが実行され始めます。 同様に、書き込みバリアは、プロセッサのストア(ストア)のみを注文します。バリアが完了する前のすべてのレコードが完了し、その後、ストア(ストア)がバリアの後に実行を開始します。 完全なバリアは読み取りと書き込みを整理しますが、このバリアを実行するプロセッサに対してのみです。
foo
と
bar
が読み取り/書き込みバリアを使用するように例を更新すると、次のようになります:
1 void foo() 2 { 3 a = 1; 4 smp_wmb(); // 5 b = 1; 6 } 7 8 void bar() 9 { 10 while (b == 0) continue; 11 smp_rmb(); // 11 assert(a == 1); 12 }
いくつかのアーキテクチャにはさらに多様な障壁がありますが、説明した3つのオプションを理解するだけで、理論にメモリの障壁を導入できます。

翻訳者のあとがき
これで翻訳は終了です。 オリジナルは、近代建築が提供する障壁を簡潔にレビューします。 興味のある人をオリジナルに送ります-ボリュームに関しては、ほぼ同じ数が残っています。
要約してみましょう。
したがって、キャッシュ/メモリと相互作用するプロセッサの2つの操作-読み取り(ロード)と書き込み(ストア)があります。 2つの操作により、4つの異なるメモリバリアが提供されます。
op1; // store load barrier ; // memory fence op2; // store load
- ロード/ロード -以前のロード命令を後続のロード命令で編成します。 これまで見てきたように、このバリアは無効化キューに「順番に配置」します。このキューを完全に処理するか、キューを将来処理する順序を指定するラベルをそのキューに入れます。 比較的軽いバリア
- ストア/ストア -以前のストアの指示を後続のストアの指示とともに整理します。 それはストアバッファに影響します:蓄積されたバッファを完全に処理します(かなり高価です-書き込み操作は現代のプロセッサにとって常に困難です)、またはおそらく、ストアバッファの現在の内容を何らかの方法でマークします処理します。 この場合、比較的軽いバリア
- ロード/ストア -後続のストアで以前のロード指示を整理します。 彼は何に影響を与えることができますか? それは投機的な録音を防ぐと思います。 また、かなり軽い障壁のようです。
- ストア/ロード -後続のロードで以前のストア指示を編成します。 ストア命令はストアバッファに入ります。 つまり、このバリアはストアバッファを合理化する必要があります-ラベルをそこに置くだけですか? いいえ、それで十分ではないようです。 結局のところ、まだ投機的な読書があり、この障壁はそれを制限する必要があります。 私が現代のアーキテクチャについて知っていることから、この障壁はストアバッファの完全な処理につながると結論付けることができます。これはかなり難しいアクションです。 結論:これはすべての最も重い障壁です
おめでとうございます、私たちはSparcアーキテクチャのメモリ障壁を取り除きました! 
Sparcアーキテクチャ(最も緩和されたRMOモード-緩和されたメモリの順序付け)には、パラメータが常に定数(ビット単位のORと組み合わせることができるビットフラグのセット)が渡される
命令があります。 これらのフラグのニーモニックは
、
、
、
(他の特定のフラグは考慮しません。アプリケーションプログラミングには適用されません)。
命令は、バリアである対応するオペレーション間のコード内に配置する必要があります。
たとえば、Sparcの完全なメモリバリアは、アセンブラでは次のようになります。
原則として、1つの
を除き、すべてのフラグとその組み合わせはかなり軽い障壁を表します。 また、これはSparcアーキテクチャの機能ではなく、実際にはすべての現代の弱順序プロセッサのプロパティです。
Sparcアーキテクチャ(最も緩和されたRMOモード-緩和されたメモリの順序付け)には、パラメータが常に定数(ビット単位のORと組み合わせることができるビットフラグのセット)が渡される
membar
命令があります。 これらのフラグのニーモニックは
#LoadLoad
、
#LoadStore
、
#StoreStore
、
#StoreLoad
(他の特定のフラグは考慮しません。アプリケーションプログラミングには適用されません)。
membar
命令は、バリアである対応するオペレーション間のコード内に配置する必要があります。
-
Load1; membar #LoadLoad; Load2
-
Load; membar #LoadStore; Store
-
Store; membar #StoreLoad; Load
-
Store1; membar #StoreStore; Store2
たとえば、Sparcの完全なメモリバリアは、アセンブラでは次のようになります。
membar #LoadLoad|#LoadStore|#StoreStore|#StoreLoad
原則として、1つの
#StoreLoad
を除き、すべてのフラグとその組み合わせはかなり軽い障壁を表します。 また、これはSparcアーキテクチャの機能ではなく、実際にはすべての現代の弱順序プロセッサのプロパティです。
次へ
そこで、私たちは記憶の壁がどこから来たのかを見ました。 彼らが必要な悪であることを学びました。 私たちは、コード内で何らかの方法でそれらを配置しようとしました。
プリエンプティブスケジューラとメモリバリア
メモリバリアは、ほとんどすべての最新アーキテクチャの独立したアセンブラー命令であることに注意する価値があります(おそらく、Intel Itaniumだけが独立したアーキテクチャとして際立っています-バリアは、ロード/ストア/ RMW命令の一部になります)。 ロックフリーアルゴリズムでは、バリアを正しく配置することが重要です。 しかし、最新のオペレーティングシステムは、圧倒的にプリエンプティブなプロセス/スレッド制御モデルを実装しています。 つまり、ストリームには一定量の時間が割り当てられ、その後、別のストリームに置き換えられます。 押し出し(コンテキストスイッチング)は、メモリバリアの命令の直前に発生する可能性があります。 , – , ?
. - , , . lock-free , , , - .
. - , , . lock-free , , , - .
メモリバリアの配置に対する考慮されたアプローチを、読み取り/書き込みアプローチと呼びます。 C ++ 11標準の開発中に、メモリへのアクセスを整理する問題に対する読み取り/書き込みのアプローチがアーキテクチャにあまりにも関連していると認識され、取得/解放のセマンティクスが開発され、標準の基礎を形成しました。この記事で複数回述べられているように、メモリバリアは、バリアを実行するプロセッサのみに直接影響し、間接的に(MESIプロトコルを介して)他のプロセッサにのみ影響します。取得/リリースモデルの動作は異なります- 異なる並列スレッド(つまり、プロセッサ/コア)がどのように相互作用するかを仮定しますが、実際にこれを達成する方法は何もありません。実際、このモデルの実装は、特定のメモリバリアの使用です。
次のEssentials記事でC ++ 11メモリモデルについて説明します。
ロックフリーのデータ構造