はじめに
今日、マイニングの日付に少しでも興味がある人なら誰でも、おそらく単純な線形回帰について聞いたことがあるでしょう。 それについてはすでにハブに書かれており、Andrew Ngは彼の有名な機械学習コースで詳しく話をしました。 線形回帰は、機械学習の基本的かつ最も簡単な方法の1つですが、構築されたモデルの品質を評価する方法はほとんど言及されていません。 この記事では、R言語でsummary.lm()関数の結果を分析することで、この迷惑な省略を少し修正しようとします。同時に、必要な数式を提供して、すべての計算を他の言語で簡単にプログラムできるようにします。 この記事は、線形回帰を構築することが可能であると聞いたが、その品質を評価するための統計的手順に出くわしたことがない人を対象としています。
線形回帰モデル
そのため、いくつかの独立したランダム変数X1、X2、...、Xn(予測子)とそれらに依存する量Yがあると仮定します(予測子の必要なすべての変換が既に行われていると仮定されます)。 さらに、依存関係は線形であり、エラーは正規分布していると仮定します。
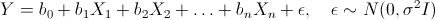
ここで、Iはサイズnx nの単位正方行列です。
したがって、量YとXiのk個の観測からなるデータがあり、係数を推定したいと思います。 係数推定値を見つけるための標準的な方法は、最小二乗法です。 そして、この方法を適用することで得られる分析ソリューションは次のようになります。
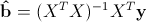
ここで、カバー付きのbは係数ベクトルの推定値、 yは従属量の値のベクトル、Xはサイズkx n + 1の行列です(nは予測子の数、kは観測値の数)。最初の列は単位で構成され、2番目は最初の予測子の値です、3番目-2番目の3番目などで、線は利用可能な観測値に対応します。
関数summary.lm()および結果の評価
次に、R言語で線形回帰モデルを構築する例を考えます。
> library(faraway) > lm1<-lm(Species~Area+Elevation+Nearest+Scruz+Adjacent, data=gala) > summary(lm1) Call: lm(formula = Species ~ Area + Elevation + Nearest + Scruz + Adjacent, data = gala) Residuals: Min 1Q Median 3Q Max -111.679 -34.898 -7.862 33.460 182.584 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.068221 19.154198 0.369 0.715351 Area -0.023938 0.022422 -1.068 0.296318 Elevation 0.319465 0.053663 5.953 3.82e-06 *** Nearest 0.009144 1.054136 0.009 0.993151 Scruz -0.240524 0.215402 -1.117 0.275208 Adjacent -0.074805 0.017700 -4.226 0.000297 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 60.98 on 24 degrees of freedom Multiple R-squared: 0.7658, Adjusted R-squared: 0.7171 F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
galaテーブルには、30のガラパゴス諸島に関するデータが含まれています。 種-島の異なる植物種の数が他のいくつかの変数に線形に依存するモデルを考えます。
summary.lm()の出力を検討してください。
最初に、モデルの作成方法を思い出す行があります。
次に、残基の分布に関する情報があります:最小、最初の四分位数、中央値、3番目の四分位数、最大。 この時点で、残差のいくつかの変位値を見るだけでなく、たとえばシャピロウィルク検定などで正規性をチェックすることも有用です。
次-最も興味深い-係数に関する情報。 ここで少し理論が必要です。
まず、次の結果を記述します。
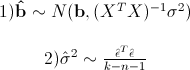
この場合、キャップで二乗されたシグマは、実シグマの二乗の不偏推定値です。 ここで、 bは係数の実ベクトルであり、蓋付きイプシロンは、係数として最小二乗推定値を使用する場合の残差のベクトルです。 つまり、誤差が正規分布していると仮定すると、係数ベクトルも実数値の周囲に正規分布し、その分散を不偏に推定できます。 これは、係数がゼロに等しいという仮説をチェックできることを意味します。したがって、予測子の有意性をチェックできます。つまり、量Xiは構築されたモデルの品質に本当に強く影響します。
この仮説をテストするには、係数biの実際の値が0である場合にスチューデント分布を持つ以下の統計が必要です。
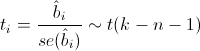
どこで
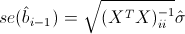 係数推定の標準誤差であり、t(kn-1)は自由度kn-1の生徒分布です。
係数推定の標準誤差であり、t(kn-1)は自由度kn-1の生徒分布です。
これで、summary.lm()関数の出力の解析を続行する準備がすべて整いました。
したがって、次は最小二乗法によって得られた係数の推定値、それらの標準誤差、t統計値とそのp値です。 通常、p値は、0.05または0.01などのかなり小さい事前選択しきい値と比較されます。 また、p統計の値がしきい値よりも小さい場合、仮説は棄却されますが、残念ながらそれ以上の場合、具体的なことは何も言えません。 この場合、スチューデント分布は0に関して対称であるため、p値は1-F(| t |)+ F(-| t |)に等しくなります。ここで、Fはkn-1自由度のスチューデント分布関数です。 また、Rは、p値が非常に小さいアスタリスクの重要な係数を親切に示します。 つまり、0になる可能性が非常に低い係数です。Signif行。 コードには星のデコードのみが含まれます。3つある場合、p値は0〜0.001、2つある場合、0.001〜0.01などになります。 アイコンがない場合、p値は0.1より大きくなります。
この例では、予測子のElevationとAdjacentがSpeciesの値に実際に影響を与える可能性が非常に高いと言えますが、他の予測子については何も言えません。 通常、このような場合、予測変数は一度に1つずつ削除され、モデルの他のインジケーター(たとえば、後で説明するBICまたは調整済みR 2乗)がどれだけ変化しているかを確認します。
残差標準誤差の値は、キャップ付きシグマの推定値に対応し、自由度はkn-1として計算されます。
そして今、最初に見る価値がある最も重要な統計:R-squaredおよびAdjusted R-squared:
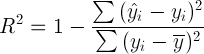
ここで、Yiは各観測のYの実際の値、キャップ付きのYiはモデルによって予測された値、ダッシュ付きのYはYiのすべての実際の値の平均です。
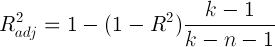
R 2乗の統計から始めましょう。これは、決定係数とも呼ばれます。 モデルの条件付き分散がYの実際の値の分散とどれだけ異なるかを示します。この係数が1に近い場合、モデルの条件付き分散は非常に小さく、モデルがデータを適切に記述している可能性が非常に高くなります。 Rの2乗係数がはるかに小さい場合、たとえば0.5未満の場合、高い確実性で、モデルは実際の状況を反映しません。
ただし、R平方統計には1つの重大な欠点があります。予測子の数が増えると、これらの統計は増加するだけです。 そのため、すべての新しい予測子が従属変数に影響を与えない場合でも、予測子の数が多いモデルは、予測子の数が少ないモデルよりも優れているように見える場合があります。 ここでは、 オッカムのカミソリの原理を思い出すことができます。 それに続いて、可能であれば、モデル内の不必要な予測子を取り除く価値があります。これは、モデルがより単純で理解しやすくなるためです。 これらの目的のために、統計補正されたR平方が発明されました。 これは通常のR 2乗ですが、多数の予測変数に対しては罰金が科せられます。 主なアイデア:新しい独立変数がモデルの品質に大きく貢献する場合、これらの統計の値は増加しますが、そうでない場合は逆に減少します。
たとえば、以前と同じモデルを考えますが、5つの予測子の代わりに2つの予測子を残します。
> lm2<-lm(Species~Elevation+Adjacent, data=gala) > summary(lm2) Call: lm(formula = Species ~ Elevation + Adjacent, data = gala) Residuals: Min 1Q Median 3Q Max -103.41 -34.33 -11.43 22.57 203.65 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.43287 15.02469 0.095 0.924727 Elevation 0.27657 0.03176 8.707 2.53e-09 *** Adjacent -0.06889 0.01549 -4.447 0.000134 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 60.86 on 27 degrees of freedom Multiple R-squared: 0.7376, Adjusted R-squared: 0.7181 F-statistic: 37.94 on 2 and 27 DF, p-value: 1.434e-08
ご覧のとおり、R 2乗統計量の値は減少していますが、調整されたR 2乗値はわずかに増加しています。
次に、予測子のすべての係数がゼロに等しいという仮説を確認します。 つまり、Yの値が一般にXiの値に線形に依存するかどうかの仮説です。 これを行うには、次の統計を使用できます。すべての係数がゼロに等しいという仮説が真の場合、自由度cnおよびkn-1のフィッシャー分布があります。

F統計値とそのp値は、summary.lm()関数の出力の最終行にあります。
おわりに
この記事では、係数の有意性を評価する標準的な方法と、構築された線形モデルの品質を評価するためのいくつかの基準について説明しました。 残念ながら、これはモデルの妥当性をチェックするかなり重要な要素ですが、これにより記事が2倍になるため、残差の分布を考慮して正規性をチェックするという問題に対処しませんでした。
ある種の依存関係を単純に評価し、その結果がどのように推定されるかを示すアルゴリズムとして、線形回帰の標準概念をわずかに拡張できたことを本当に願っています。