 この記事では、Proxmox 3.0ホストマシンでdrbdミラーリングを作成する方法を説明します。 マシンをproxmoxクラスターに結合することは、これらの操作の前に理にかなっていますが、一般に違いはありません。
この記事では、Proxmox 3.0ホストマシンでdrbdミラーリングを作成する方法を説明します。 マシンをproxmoxクラスターに結合することは、これらの操作の前に理にかなっていますが、一般に違いはありません。
この資料とインターネット上で普及している多くの資料の主な違いは、2番目に接続された新しい物理ドライブではなく、唯一の使用可能なドライブ内のlvmパーティションでパーティションをdrbdすることです。
このようなアクションの適切性の問題は十分に議論の余地があります-drbdが「生の」ディスク上で高速になるかどうかですが、いずれにしても、これは100%テスト済みのオプションです。 いわば、貯金箱。 はい、「生の」ディスクで作業することは、この命令の特別な場合にすぎません。
実際、インストール中のProxmox 3.0(およびその前身である2.0)は、パーティションの問題に悩まされず、ディスクサイズとメモリサイズの合計のみを考慮して、すべてを壊します。 / pve / dataパーティションを取得します。これはディスクの大部分を占有し、Proxmoxでローカルストレージとして表示されます。 彼が行動を起こすのは彼によるものです。
1.パッケージを最新に更新する
#aptitude update && aptitude full-upgrade
2.必要なパッケージをインストールします
#aptitude install drbd8-utils
3.新しいセクション用のスペースを解放します。
/ dev / pve / data(別名/ var / lib / vz)をアンマウントします。 手順3の以下の手順はすべて、マウントされていないリソースでのみ実行できます。したがって、その前に、このノードでローカルストレージを使用するすべてのVMを消滅させます。 本当に必要な場合は、残りに触れることはできません。
#umount /dev/pve/data
3.1。 / dev / pve / dataを減らします。
原則として、次のいくつかの手順はコマンドに置き換えることができます
#lvresize -L 55G /dev/mapper/pve-data
#mkfs.ext3 /dev/pve/data
まあ、もう少し詳しく。 そして、私の意見ではもう少し正確です。
#lvremove /dev/pve/data
#lvcreate -n data -l 55G pve
#mkfs.ext3 /dev/pve/data
しかし、同時に、ローカルストレージにあるものはすべて失われます。 Proxmoxを新たにインストールした場合(この種の操作に一般的に推奨されます)、それですべてです。手順4に進みます。それでもデータをローカルストレージに保存する場合は、別の方法で対処します。
3.2。 情報を失うことなく、/ dev / pve / dataを削減します。
ローカルは50G未満だと思います。 状況が異なる場合は、チームの「新しいサイズ」を変更するだけです。
#umount /dev/pve/data
必須チェック、それなしではresize2fsは機能しません
#e2fsck -f /dev/mapper/pve-data
e2fsck 1.42.5 (29-Jul-2012)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/mapper/pve-data: 20/53223424 files (0.0% non-contiguous), 3390724/212865024 blocks
ファイルシステムを50Gに圧縮します。 この手順をスキップすると、lvresizeの後に90%の確率でシステムが破損します。 さらに、その数は結果のセクションよりも意図的にわずかに少なくなります。 マージンあり。
#resize2fs /dev/mapper/pve-data 50G
resize2fs 1.42.5 (29-Jul-2012)
Resizing the filesystem on /dev/mapper/pve-data to 13107200 (4k) blocks.
The filesystem on /dev/mapper/pve-data is now 13107200 blocks long.
#e2fsck -f /dev/mapper/pve-data
/ pve / dataセクションを直接55Gに圧縮します
#lvresize -L 55G /dev/mapper/pve-data
WARNING: Reducing active logical volume to 55.00 GiB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce data? [y/n]: y
Reducing logical volume data to 55.00 GiB
Logical volume data successfully resized
使用可能なすべてのスペースをシステムに占有します。 原則として、前のステップでの「マージン」が大きくない場合、これは実行できません。 なぜマッチを保存するのですか? ;)
#resize2fs /dev/mapper/pve-data
resize2fs 1.42.5 (29-Jul-2012)
Resizing the filesystem on /dev/mapper/pve-data to 14417920 (4k) blocks.
The filesystem on /dev/mapper/pve-data is now 14417920 blocks long.
システムに/ dev / pve /データを返します。
#mount /dev/pve/data
4. drbdのパーティションを作成する
空きスペースを確認します。 これまでのすべてのステップで、かけがえのないものが得られたと確信しています。 つまり、/ dev / sda2パーティションの空き容量
#pvdisplay
--- Physical volume ---
PV Name /dev/sda2
VG Name pve
PV Size 931.01 GiB / not usable 0
Allocatable yes
PE Size 4.00 MiB
Total PE 238339
Free PE 197891
Allocated PE 40448
PV UUID 6ukzQc-D8VO-xqEK-X15T-J2Wi-Adth-dCy9LD
すべての空き領域に新しいセクションを作成します。
#lvcreate -n drbd0 -l 100%FREE pve
Logical volume "drbd" created
5. drbd設定ファイルを準備します
#nano /etc/drbd.d/r0.res
リソースr0 {
スタートアップ{
wfc-timeout 120;
degr-wfc-timeout 60;
両方がプライマリになる。
}
ネット{
cram-hmac-alg sha1;
共有秘密「proxmox」;
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri切断;
}
syncer {
レート30M;
}
p1で{
デバイス/ dev / drbd0;
ディスク/ dev / pve / drbd;
アドレス10.1.1.1:7788;
メタディスク内部。
}
p2で{
デバイス/ dev / drbd0;
ディスク/ dev / pve / drbd;
アドレス10.1.1.2:7788;
メタディスク内部。
}
}
wfc-timeoutパラメーターを0に設定することを推奨する人もいます。その意味は、開始時にdrbdネイバーが表示されない場合、wfc-timeout秒後に再起動することです。 0-このアクションを無効にすることを意味します。
レート30M-drbdホスト間の転送制限。 値は1G接続に対応します。 ホスト間の実際のチャネル帯域幅の30%として推奨。 次の例では、「ウサギのテスト」では、100M接続の帯域幅は約11Mb / sです。つまり、レートは3Mに下げられます。 ホスト間の10G接続では、明らかに増加する意味があります。
6.メタデータを作成し、drbdパーティションを起動します。
#modprobe drbd
#drbdadm create-md r0
md_offset 830015008768
al_offset 830014976000
bm_offset 829989642240
Found some data
==> This might destroy existing data! <==
Do you want to proceed?
[need to type 'yes' to confirm] yes
Writing meta data...
initializing activity log
NOT initialized bitmap
New drbd meta data block successfully created.
Success
#drbdadm up r0
次のような結果を表示できます。
#cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)
GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:51
0: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r----s
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760
7. 2番目のホストを準備する
2番目のホストマシンで手順1〜6を実行します。 重要なポイント(!)。 drbdパーティションサイズは、両方のホストで同一である必要があります。
8.同期。
ホストの1つを使用します(どちらを使用してもかまいません)。 プライマリが完全に同期されるまで呼び出しましょう。 2番目はそれぞれセカンダリです。 完全な同期の後、それらは同等になります-これが設定したモードです。
#drbdadm -- --overwrite-data-of-peer primary r0
# cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)
GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:51
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r----s
ns:0 nr:0 dw:0 dr:664 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760
その後、両方のホストで
#drbdadm down r0
#service drbd start
プライマリでは、結果は次のようになります。
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........
***************************************************************
DRBD's startup script waits for the peer node(s) to appear.
- In case this node was already a degraded cluster before the
reboot the timeout is 60 seconds. [degr-wfc-timeout]
- If the peer was available before the reboot the timeout will
expire after 120 seconds. [wfc-timeout]
(These values are for resource 'r0'; 0 sec -> wait forever)
To abort waiting enter 'yes' [ 18]:
.
二次的に:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........
***************************************************************
DRBD's startup script waits for the peer node(s) to appear.
- In case this node was already a degraded cluster before the
reboot the timeout is 60 seconds. [degr-wfc-timeout]
- If the peer was available before the reboot the timeout will
expire after 120 seconds. [wfc-timeout]
(These values are for resource 'r0'; 0 sec -> wait forever)
To abort waiting enter 'yes' [ 14]:
0: State change failed: (-10) State change was refused by peer node
Command '/sbin/drbdsetup 0 primary' terminated with exit code 11
0: State change failed: (-10) State change was refused by peer node
Command '/sbin/drbdsetup 0 primary' terminated with exit code 11
0: State change failed: (-10) State change was refused by peer node
Command '/sbin/drbdsetup 0 primary' terminated with exit code 11
.
エラー\すべてを同時に再起動したという事実による遅延。 通常の状況では、起動は簡単に見えます。
#service drbd start
Starting DRBD resources:[ d(r0) s(r0) n(r0) ].
# cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)
GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:51
0: cs:SyncSource ro:Primary/Primary ds:UpToDate/Inconsistent C r-----
ns:199172 nr:0 dw:0 dr:207920 al:0 bm:11 lo:1 pe:24 ua:65 ap:0 ep:1 wo:b oos:810340664
[>....................] sync'ed: 0.1% (791348/791536)M
finish: 19:29:01 speed: 11,532 (11,532) K/sec
ここで、ディスクの同期が開始されていることがわかります。
このプロセスの監視を開始し、散歩に行きます。 ディスクのサイズとホスト間の接続の速度に応じて、数時間から1日まで歩くことができます...
#watch –n 1 “cat /proc/drbd”
そして、私たちは大切な100%を待っています
cs:SyncSource ro:Primary/Primary ds:UpToDate/ UpToDate
9. lvmボリュームグループの作成
プロセスは長いため、プライマリホストで続行します。
#vgcreate drbd-0 /dev/drbd0
No physical volume label read from /dev/drbd0
Writing physical volume data to disk "/dev/drbd0"
Physical volume "/dev/drbd0" successfully created
Volume group "drbd-0" successfully created
10.グループをProxmoxに接続する
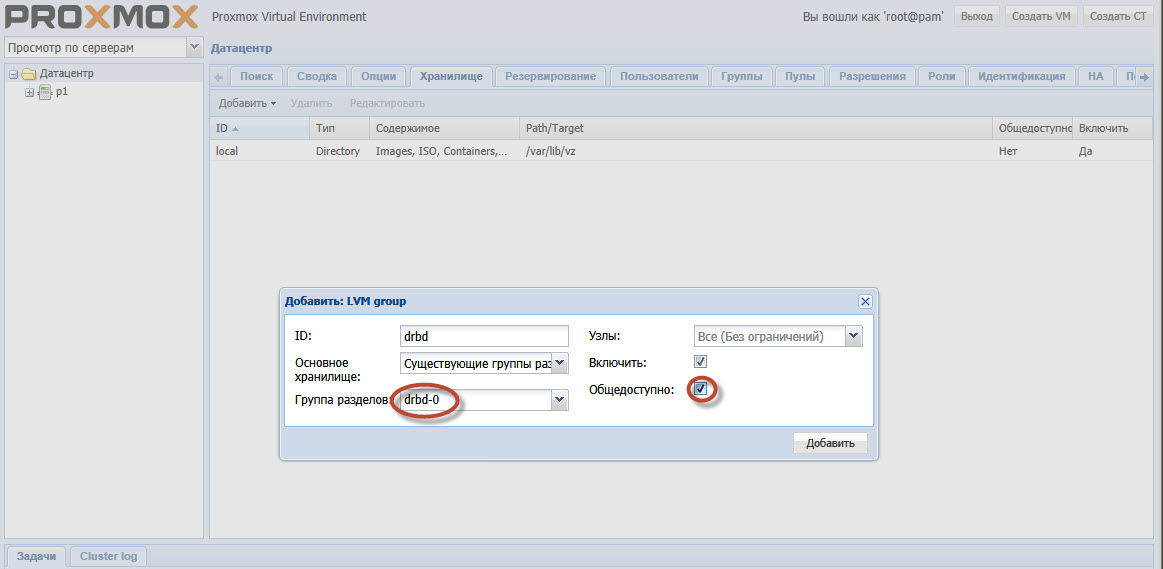
Proxmox GUIでData Center-Storageセクションを選択します。 追加します。 タイプ-LVM、IDは任意です-それは単なる名前です。 パーティショングループdrbd-0、+有効、+一般公開。
ハイライトされたポイントに注意してください。 drbd-0は、手順9で作成されたグループです。
まあ、パブリック可用性は、Proxmoxが移行プロセス中にマシン自体のホストイメージをコピーしようとしないように設定されています。
11.それだけです。
同期が完了した後、イメージディスクストレージとしてdrbdを選択してマシンを作成し、ホストマシンにサービスを提供する仮想マシンとの接続を失うことなくクラスター内のホストからホストに転送できます。 一般に、すべてが高可用性クラスターを構築する準備ができています-Proxmox