1つの指標は、公開されている科学論文の数です。 SCIMAGO Webサイトでは、出版されたドキュメントの総数、引用されたドキュメント(記事、レビュー、会議レポート)の数、引用数など、国ごとの出版物の統計を見つけることができます。
同時に、これらの国の科学の発展レベルを比較するために、米国とチェコ共和国などの出版物の数を単純に比較することは奇妙です。 何らかのスケーリングインジケーターを使用する必要があります。 GDPを使用する最も簡単な方法(購買力平価で)。 GDPと記事数の関係は必ずしも線形ではありません。 さまざまな国のGDPを取得するには、Wikipediaを強奪する必要があります。 このために、Nokogiri拡張機能を備えたRubyを使用します。 ウィキペディアのページを奪います。
プロジェクトコードはGithubにあります。
その結果、csvファイルの形式で、GDP、記事数、最初の50か国の引用数に関するデータを記事数で取得します。
このファイルを処理するには、R環境を使用し、データをRにロードします。
dataf = read.csv("test.csv", sep=";", header=F)
names(dataf) = c("country", "gdp", "articles", "citations")
GDPの10億ドルあたりの記事数と引用数を計算します(GDPの科学的性質の特定の指標)。
dataf$articles_per_gdp = dataf$articles/dataf$gdp
dataf$citation_per_gdp = dataf$citations/dataf$gdp
記事の読みやすさを損なわないように、データは別のテーブルに配置されます。
表1.最初の近似値 。
興味深いデータが判明しました。 少しがっかり。 まず第一に、米国の非常に低い率。 より信頼できる別の指標が必要です。
グラフ上の記事数のGDPへの依存性をプロットしてみましょう。
plot(dataf$articles ~ dataf$gdp, lwd="3", xlab=", USD", ylab=", ")
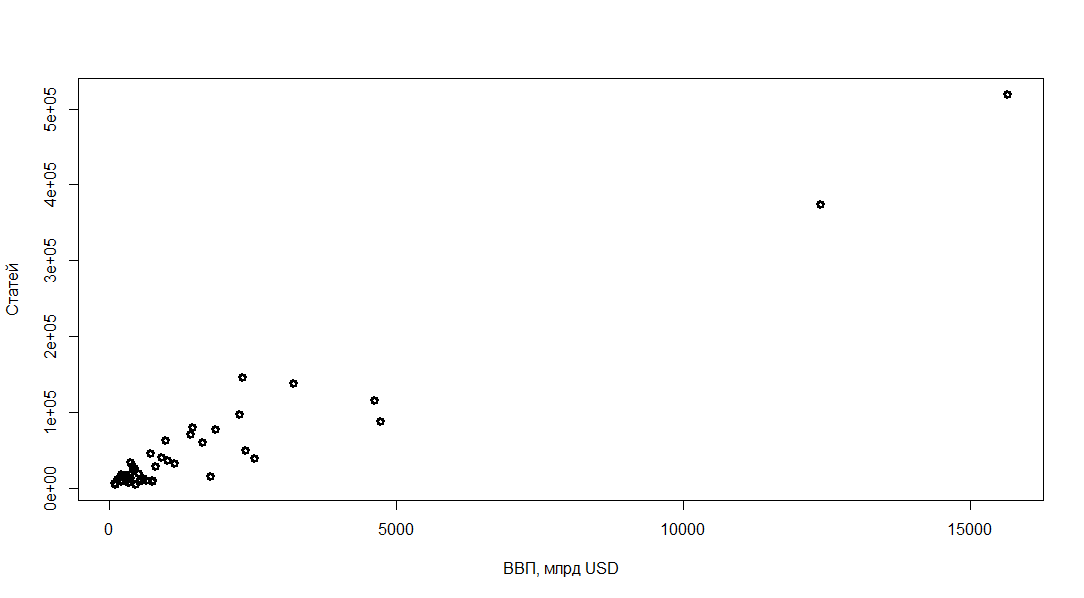
正直なところ本当にありません。 すべてのポイントは、チャートの先頭に集中しています。 対数座標でグラフをプロットしてみましょう。
plot(log(dataf$articles) ~ log(dataf$gdp), lwd="3", xlab="Log(GDP)", ylab="Log(Articles)")
abline(lm(log(dataf$articles) ~ log(dataf$gdp)), lwd=3, col="blue")

良く見えます。 そして、記事の数のGDPへの依存を構築することができました。
summary(lm(log(dataf$articles) ~ log(dataf$gdp)))
0.74の相関が得られ、これは50ポイントに非常に適しています。 国のGDPに関する科学記事の数を予測できます。
記事= 140 * GDP ^ 0.79
次に、国の科学の発展(PR1)として、公開された記事の数と予測数(100を掛けた数)の比をパラメータとして取ります。 実際、記事の予測数は、特定のGDPの平均値です。 PRが100を超える場合、その国は、経済発展が類似している国の世界平均よりも科学に注目しています。 2番目のパラメーター(PR2)として、同じインジケーターを使用しますが、引用のために計算されます。 表2の結果。
PR1によると、ロシアは他の商品国の中で41位(54ポイント)にランクされています。 PR2(記事の引用に関連)によると、それは46位です。