背景
約2年前、経営陣はデータセンターの仮想化プロジェクトへの投資を決定しました。 タスクは非常に単純で、約50台のサーバー、ほとんどがWindows、2台のLinuxマシン、非標準のものはありませんでした。 データセンターは、小さいながらも非常にどうした
採用されたルールに従って、冗長性とフェールオーバーを年2回テストします。仮想化サービスの場合、プロセスを2つの段階に分けることにしました。 最初のステップは、ハイパーバイザーのホストのみの障害をシミュレートすることでした(実際には電力を削減しました-これは少し失礼ですが、それがテストプロセスの説明です)。 予想どおり、VMWare HAとFTは期待どおりに機能し、委員会はプロトコルにチェックを入れてサインアップしました。 第二段階では、ハイパーバイザーとともに、ストレージデバイス(LeftHand)も削減され、奇跡は起こりませんでした。 HP Centralized Management Consoleにエラーがあり、データは利用できませんが、バックアップデバイスはオンになっていてアクセス可能ですが...クォーラムはありません。 稼働容量を復元することはできませんでした。すべてをオンに戻すことが急務であり、フェールオーバーは実現しませんでした。私たちは見つけ始めました。
自動化されたfeyloverには3つのデータセンターが必要であることがわかっていました。販売前の会議で、HPの担当者はこれについて何度も警告しました。 管理者は会議に招待されず、明確な質問はされませんでした。何らかの理由で、管理者は「自動feyloverは3つのデータセンターでのみ可能」と判断し、「手動で2つのデータセンターで十分」と判断しました。 しかし、いいえ、要求に応じて、HPサポートは、3番目のデータセンターがなければ発熱は手動でも自動でもできないと答えました。 原理はここで説明したものと似ています (この場合、システムは多少異なりますが、一般的には同じ場合です)。 要するに、すべてがフェールオーバーマネージャー(FOM)に結び付けられています-メインデバイスの障害時には、バックアップデータセンターがネットワークからアクセスできる必要があります-並列機能の状況を回避するために-スプリットブレイン。 FOM自体にはデータが含まれておらず、目撃者として失敗した場合にのみ必要です。 控えめな要件(2Ghz、1GB RAM、13Gb HDD)を超える通常の仮想マシンであるFOMを機能させるには、iSCSI VLANへのアクセスのみが必要です。 すぐに把握し、管理者にクラウド内のWindowsサーバーとiSCSI VLANのVPN、およびFOMを実行する無料のVMWareサーバーのオプションを提示しましたが、プロジェクトはコメントで拒否されました。
要するに、すべてがフェールオーバーマネージャー(FOM)に結び付けられています-メインデバイスの障害時には、バックアップデータセンターがネットワークからアクセスできる必要があります-並列機能の状況を回避するために-スプリットブレイン。 FOM自体にはデータが含まれておらず、目撃者として失敗した場合にのみ必要です。 控えめな要件(2Ghz、1GB RAM、13Gb HDD)を超える通常の仮想マシンであるFOMを機能させるには、iSCSI VLANへのアクセスのみが必要です。 すぐに把握し、管理者にクラウド内のWindowsサーバーとiSCSI VLANのVPN、およびFOMを実行する無料のVMWareサーバーのオプションを提示しましたが、プロジェクトはコメントで拒否されました。 - a)自動feyloverは必要ありません。
- b)ストレージネットワークでのクラウドホストサーバーの使用は、IBポリシーに反しています。
そして、ここに問題を解決した方法があります:
- バックアップデータセンターのいずれかのESXiホストで、ローカルストレージをアクティブにします(SANに障害が発生した場合にアクセスできるようにするため)
- バックアップデータセンターのホストに、メインFOMの完全なコピー(すべてをコピーし、最も重要なのはiscsiネットワークに接続された仮想ネットワークカードのMACアドレスをコピーします)
- スタンバイモードでバックアップデータセンターにFOMを残す
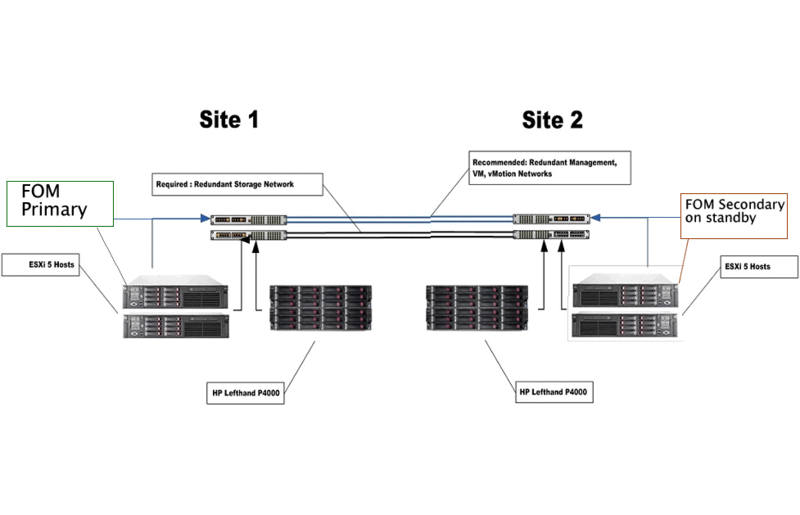
申し訳ありませんが、英語の写真のテキストはレポートからコピーされています