もちろん、私は画像や認識の経験がなく、フォームの認識のためにライブラリを検索し始めました。 残念ながら、無料のものを見つけることはできませんでした。 それで私は袖をまくり、自分で書き始めました。
このようなシステムを作成する際の主な問題は作業のアルゴリズムであると考えているため、ここではコードを書きません。
だから...
まず、フォームが作成されました。 各方法論には独自の方法がありますが、質問の数と質問の回答の数のみが異なります。

私の言葉からのフォームは、良き友人と仕事仲間によって作成されました。 これらは元々Excelで作成され、PDF形式で保存されました。
フォームの最も重要な詳細は黒い四角です(マーカーに名前を付けました)。 上部中央マーカーは、フォームの上部と下部を決定するために必要です。 心理診断では、対象者は希望のセルに斜めの十字を描くように求められます。 次のことを前提としています。
1.被験者の学歴が低い場合があります。
2.これは試験ではなく、対象が間違っているため、何度も取り消します。
3.被験者は鉛筆、ボールペン、さまざまなインク色のジェルペンを使用します。
4.被験者は指示するのが難しく、ダニではなくダニです。
テストフォームの認識システムで作業するというまさにそのタスクの段階的な形式化:
1.入力デバイスから空白の画像を取得します。
2.画像を特定の標準形式にします。
3.画像で、認識する必要のある細胞を見つけます。
4.セルを認識します。
5.回答を保存します。
さて、まず最初に。
1.処理用の画像を取得します。
最も安価で最も一般的な画像取得手段として、フラットベッドスキャナーを選択しました。 ネイティブC#オペレーティングシステムには、スキャナーを操作するための2つの主要なAPIがあります。TWAINとWIAです。 WIAに問題はありませんでした。 このテクノロジーは、Windowsで十分にサポートされ、十分に文書化されており、ネット上には多くの例があります。 最も難しいのは、スキャンオプションを設定することでした。
WIAテクノロジーの厄介な点は、 サポートされているデバイスのリストです 。 彼らは少ないです。 そのため、TWAINスキャナーを操作する機能を追加する必要がありました。 無料のTwainDotNetライブラリを使用しました。 唯一の欠点は、スキャンの開始時にスキャナーの互換性をチェックすることです。 たとえば、古いスキャナーは自動回転画像機能がないため、テストに合格しません。 オープンソースを考えると、私は状況をすぐに修正しました。
両方のAPIを使用するとき、標準のGUIを無効にしました。 画像サイズA4と解像度100 DPIを設定します。 完全を期すため、Scannerクラスにファイルから画像を選択する機能をカプセル化しました。
2.画像の正規化。
画像を普遍的な外観にすることは、段階に分けられます。
1.画像を100 DPIの解像度にします。
2.画像の二値化。
3.マーカーの検索。
4.画像の回転。
画像の操作には、 AForge.NET Frameworkを使用しました 。 多くの画像操作アルゴリズムを書く必要がないため、特に速度のために安全でないコードを書く必要があるため、無料で便利です。私はC#に不慣れです。 将来的には、この特定のライブラリのクラスを参照します。
そのため、最初は着信画像が100 DPIに縮小されます。 解像度が低いと2値化の問題が発生し、解像度が高いと処理速度の問題に直面します。 次に、画像をカラーモード「グレースケール」に変換します。 この操作には、 GrayScaleクラスを使用します。 画像を二値化するために、 BradleyLocalThresholdingを使用しました 。 このアルゴリズムは、明るさの小さな閉塞に対処します。
認識を成功させるための複雑なニュアンスの1つは、画像の正しい向きです。 3〜4度回転し、すべてがなくなった。 ストリーミングフィードなし、フラットベッドスキャナー、しわのあるブランク。 一般に、 DocumentSkewCheckerを使用してフォームの回転角度を決定しました。 そして、画像RotateBilinearを回転させるため、高速です。 この回転により、画像は0〜45度の範囲で整列しましたが、反転したままになる可能性があります。 したがって、マーカーを見つけて、フォームの上部を中央で決定する必要があります。
BlobCounterを正常に適用して、画像内のオブジェクトを検索しました。 マーカーを決定するために、サイズとFullnessプロパティで見つかったすべてのオブジェクトをフィルターで除外し、しきい値を0.8に設定しました。 上部に3つのマーカーが見つからなかった場合、画像を180度回転させました。
このような簡単な操作により、すべての画像が単一の外観と形式に縮小されます。
3.認識のための回答セルを見つける
最も簡単な方法で応答セルを見つけました。 各方法論の参照空白フォームを取り、各質問の最初の(左)セルの中心をデータベースに保存しました。 また、各質問のセルの中心間の距離とセルのサイズを保存しました。 したがって、認識の領域を決定するために、データベースからデータを取得しました。 ここで行う2つの非常に重要なポイント。 スキャンしたフォームにしわがある場合、参照フォームは均一であるため、認識領域は正しくありません。 エラーの割合が高すぎます。 これを無視するとどうなりますか:
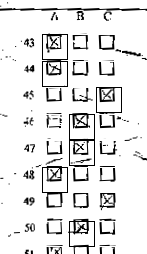
簡単に解決できます。 最初のセルの領域は中心から伸びています。 次に、この領域でBlobCounterを使用してオブジェクトを検索します。 展開された領域内のセルを検出した後、検出された中心に対して領域が圧縮されます。 次のようになります。
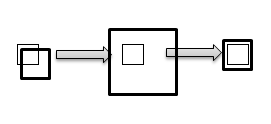
これらの操作は、各質問の最初のセルでのみ実行され、残りのセルの座標は、それに対して相対的にカウントされます。
また、画像サイズ(認識領域)はわずかに異なる場合があるため、セルに関するデータは元の画像の絶対座標ではなく、マーカーに対する相対的な位置に保存する必要があります。 これは、マーカーの2番目の重要な機能です。
座標を知らなくても認識領域を見つけることができることは注目に値します。 これは、垂直および水平の輝度ヒストグラムに基づいて行われます。 ただし、このアルゴリズムは使用しなかったため、説明しません。
4.細胞認識
ここで立ち往生しています。 認識は基本的に分類作業です。 課題を考えると、3つのクラスのセルがあります。
1.空(無料)。
2.被験者による報告(クロス)。
3.被験者が誤って指摘した(ミス)。
無料のクラスでは、すべてが明確です。 これは完全に空のセルであり、テストペンは触れていません。 しかし、クロスクラスにはすでに問題があります。セルには何でもあります。 優れたブリーフィングにもかかわらず、テストを受けている人は斜めの十字をあまり熱心に書き留めていません。 さらに、被験者は、自分が間違っていて、回答のバリエーションを修正したい場合にセルを陰にするように指示されました。 これはミスクラスです。
概して、分類アプローチには2つのオプションがありました。輝度レベルでセルを分割することと、機械学習法を使用することです。 ニューラルネットワークの古いファンとして(私はvbaで書いたことがあります)、 Encogライブラリを使用して、20の完成したテストフォームで多層パーセプトロンをトレーニングしました。 そして、間違った答えの15-35%のエラーを受け取りました。 より細かいアルゴリズム(畳み込みネットワーク、ネットワークのアンサンブル、学習アルゴリズムの組み合わせ)を使用する必要があることが明らかになりました。 この場合、次のようなセルクラスのさまざまなオプションをネットワークに提示する必要がありました。

すべての試行錯誤の結果、明るさによる分類に戻りました。 セルのすべてのピクセルの明るさの合計ではなく、感度が高すぎないことがわかりました。 ピクセルセルの明るさの合計の垂直ヒストグラムにVerticalIntensityStatisticsクラスを使用しました。 以下は、クロスヒストグラムと無料のヒストグラムです。
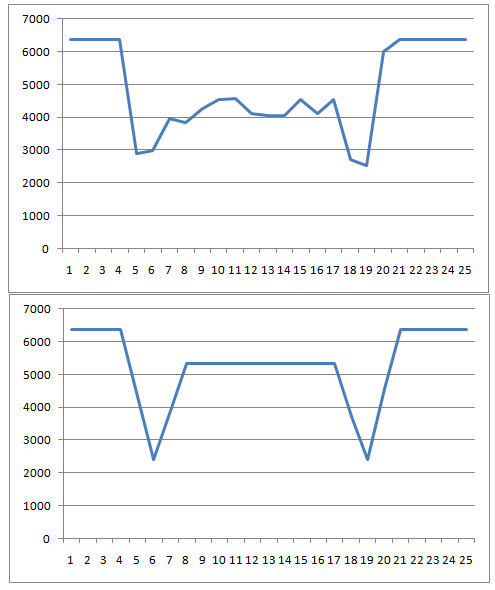
8〜17の垂直ピクセルのヒストグラム値を取り(低域をトリミング)、次の式を使用しました。しきい値= 1-平均(輝度のヒストグラム値)/最大輝度。 しきい値の値によって、セルのクラスを決定しました。 原則として、クラスは次のように分割されました。
0から0.18クラス無料、
0.18から0.6クロスクラス、
0.6から1クラスのミス。
5.応答を保存します。
システムは自動ではなく自動化されているため、認識中に発生したエラーは手動で修正できます。 その後、クロスクラスのセルIDがデータベースに送信されます。
外部では、認識インターフェイスは次のようになります。
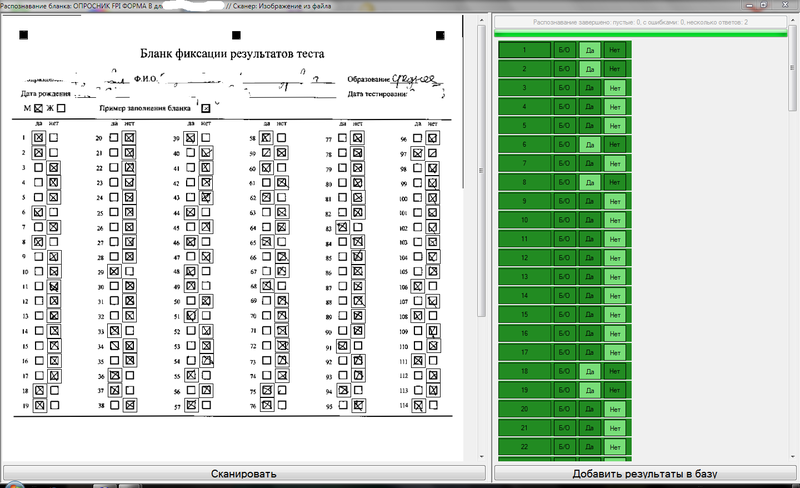
要約すると:
C#言語を学習する3か月間、私は心理テストフォームの認識のための無料のアプリケーションを作成しました。 使用前では、1分半で約1ブランクのスループットが示されました。 認識前に個人データを手動で入力することを考えると、これは非常に良いことです。
今、
あるいは、この記事は、少なくとも私の良き友人や同僚のような単純なニーズのために、フォームを認識するための素晴らしい無料のフレームワークを書くことを一部のプロに奨励するでしょう...