1週間の海戦を続けて、最適な射撃戦略を構築する別の方法を提供したいと思います。 それは、ゲーム理論で非常に一般的な戦略のツリー表現を使用します。 解の表の形式での問題の提示は、前世紀の70年代に人気があり、特に電子回路の障害の監視と診断に使用されたテストの理論から借用されています。 この方法を使用すると、最適な戦略を見つけることができますが、計算が非常に複雑になります。 残念ながら、10x10フィールドのゲームは分析できませんでした。
決定木
そして、イギリス、そしてドイツがドレッドノートを構築したとき、それらの間の戦争は避けられなくなりました。 なぜなら、少なくとも何らかの形で推測的に答えることができる新しい船を使用する戦術についての質問に加えて、理論的に答えることは絶対に不可能なものがあったからです。 次のように聞こえました:「誰がより良いダニですか?!」(E. Grishkovets「ドレッドノート」による劇からの無料引用)
始めるために、決定木の形で戦略を提示する便利な方法を取得しましょう。 たとえば、3x3フィールドで巡洋艦と2隻のボートを撃つ方法を次に示します。
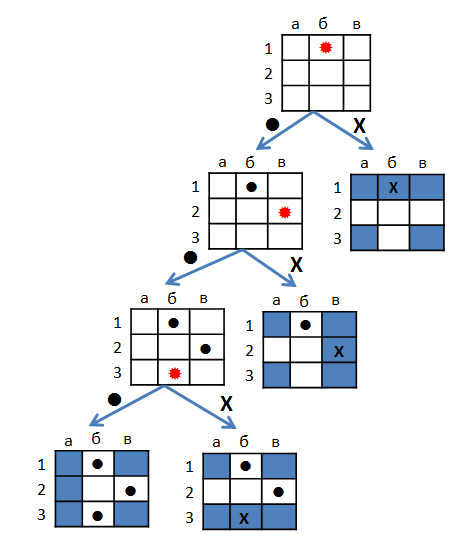
木のてっぺんには、すでにショットが取られた競技場があります。 現在のショットは赤でマークされています。 ショットの結果はrib骨に起因します:ミス(。)またはヒット(x)。 葉は船の場所を示しています。 戦略はこのような言葉で説明できます。 まず、 b1で撮影します。 ヒットすれば、船がどのように配置されているかが明らかになり、それらを完成させるために残ります。 そうでない場合は、 B2で撮影します。 私たちが倒れたら、すべてがはっきりしています。 見逃した場合、場所には2つのオプションがあり、 b3のショットは最終的な明瞭さをもたらします。
どのような射撃戦略でもこの方法で説明できることは明らかで、紙で十分でした。 しかし、良い戦略を見つけるためには、私たちが本当に望むものを形式化する必要があります。 戦略は「すべての場面で」プレイヤーのアクションを記述しますが、船の位置を示す特定のゲームは、ルートから葉の1つまでのツリー内のパスによって記述されることに注意してください。 終わりに勝ち、勝ったので、敵の船にパイプがあったのと同じ回数になります。 ルールを次のように再定式化できます。各プレイヤーは敵の戦隊が完全に破壊されるまで撃ち、その後ミスの少ない方が勝ちます。 したがって、良い戦略は、ミスの量が少ないこととは異なります。 そして今、2つの可能性があります。
最悪の場合に何回ミスするかによって戦略を評価できます。 次に、2つの戦略のうち、ルートからリーフへのミスの最大数を持つ戦略は最小です。 そして、敵が偶然に同じ確率で場所を選択し、 予想されるミスの数を減らすことを試みると仮定できます。 次に、2つの戦略のうち、各リーフリーフのルートからのすべてのパスで合計が最小のものが最小になります。 たとえば、この戦略では、3回以下のミスを行うことで船舶の破壊を保証し、予想されるミスの数は(3 + 2 + 1 + 0)/ 4 = 1.5です。
ところで、あなたは両方の意味で最高の戦略を見つけようとすることができます。 魅力的に聞こえますか? 残念ながら、両方の問題はNP困難な集合をカバーする問題にあまりにも似ており、簡単な解決アルゴリズムが存在しないことを約束します。 しかし、忍耐とマシンタイムを蓄えながら、私たちはまだ何かをしようとしています。
決定表と戦略構築アルゴリズム
いわゆる決定表の形式で問題を想像してみましょう。 列が競技場のセルに対応し、行が船の場所のすべての種類のオプションに対応する長方形のテーブルを構築します。 行と列の交点にある表のセルには、競技場の指定されたセル内の指定されたセルに船がある場合は「X」、「。」 そうでなければ。 たとえば、次の表は、巡洋艦と3x3フィールドの2つのボートの場所の4つの可能なオプションを説明する表です(右側の各行には巡洋艦の中央が位置するセルが割り当てられます-この例では、船の位置を一意に決定します)。
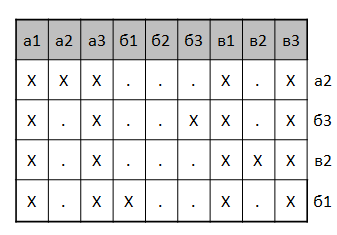
テーブルを見ると、どの構成にも船が存在しないため、 B2を撮影する意味がないことがわかります。 a1 、 a3 、 b1 、 b3のショットはヒットを保証しますが、船の位置に関する追加情報は提供しません。 彼らは敵を脅すために最初に実行することができます。 ヒットしたときに残りのセルのそれぞれでショットが一意に行を決定し、ミスした場合、仮説の数を1つ減らします。 このプロセスは、蓄積された情報と矛盾するテーブル行から削除することを想像できます。
近似貪欲アルゴリズムは、ルートからツリーを構築します。 アルゴリズムはテーブルの列(ショットのセル)を選択するため、このセルに船がある行の割合は可能な限り1/2に近くなります。 選択されたセルはツリーのルートに帰属し、ミス/ヒットに対応する2つのエッジがルートから描画され、2つの新しい頂点がエッジの端で中断されます。 新しい頂点のそれぞれは、最初のショットの結果と矛盾する線が消されたサブテーブルを取得します。 すべての結果テーブルに行が1つだけ含まれるまで、各リーフに同じ手順が適用されます。 対応する頂点が葉になり、アルゴリズムが終了します。
別のアルゴリズムは動的プログラミングを使用します。 彼はサブテーブルの巨大なグラフを分析しますが、見つかったソリューションが最適であることを確認します。 残念ながら、彼に関する詳細な話は別の投稿に値します。 どういうわけか私は自分の力を集めて書きます。そして今、私はその存在を信じて実験的な部分に行くことを提案します。
実験
理論家は自分にできること、必要なことを決定し、施術者は自分に必要なこと、できることを決定します。
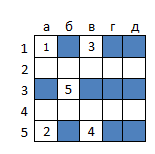
尊敬されるMrrlによって表明された構成の数 (1.85 * 10 15 )は、コードを書く過程で私を捕らえ、私の熱意をかなり冷やしました。 考えて、フィールドのサイズを縮小しながら、問題を終わらせることにしました。 正確なアルゴリズムは、5x5のフィールドで1隻の巡洋艦、2隻の駆逐艦、3隻の艦隊の射撃タスクを実行することに合意しました。 可能な構成の数は1428だけですが、サブタスクのグラフは、10 191 257の印象的な頂点と214 464 800のエッジで構成されています。 最適なアルゴリズムを使用すると、飛行隊を破壊し、ミスを7回までに抑えることができ、平均で4.51回のミスを許します。 下の図は、5回のミスで船の位置を決定する方法を示しています(つまり、決定木の右端の分岐を実装するとき)。
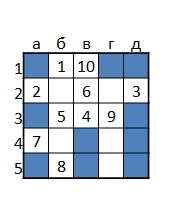
同じタスクの貪欲なアルゴリズムは、最悪の場合に11のミスを許容する戦略を構築し、予想ミス数は5.46でした。 次の図は、ミスシューティング戦略(決定木の右端の分岐)を示しています。
まとめ
古典的な欲張りアルゴリズムはうまく機能しませんでした。 彼はツリー内のパスの長さを最小化するのに良い仕事をするだろうと思います。ミスの数は明らかに、ショットのためのセルを選択する異なる経験主義を必要とします。 正確なアルゴリズムは、フィールドの4分の1の半分の船で問題を克服したため、自慢できることは何もありません。 この小さなタスクの場合、最適な戦略のミスの数が同じであることがわかった(最悪の場合は7、平均は4.51)という魂が少し温まります。 これが同僚が近似アルゴリズムを構築するのに役立つとうれしいです。
更新する
1)考慮された問題は、プレイヤーが「ヒット」という答えを与える「殺される」のではなく、古典的な「海戦」とは異なります。 3番目の回答の紹介では、以前のショットと互換性のある場所のリストのみでサブタスクを説明し、ソリューションに動的プログラミングを適用することはできません。 実績のある最適でない分岐を除いて直接列挙しない限り、古典的な問題に最適なアルゴリズムを検索する方法を想像することはできません。
2)各ステップで最大数の記号Xを持つ列を選択する(つまり、船を見つける可能性が最も高いショットのセルを選択する)貪欲なアルゴリズムは、最適に近い結果を示します:最悪の場合で8ミス、平均で4.595です。 「killed」という回答を導入すると、パフォーマンスが大幅に向上します。最悪の場合は4ミス、平均で2.04ミスです。
追加してくれたMrrlに感謝します。