特にHabrahabrについては、このプロジェクトに関与した人々にインタビューし、何のために必要なのか、どのように機能するのか、どの要素を考慮に入れるのか、そしてその利点をどのように測定するのかを尋ねました。
昔々、人の検索結果を表示するために、検索エンジンには十分なユーザークエリと独自のインデックスがありました。 これら2つのエンティティは簡単に想像できます。 しかし、時間が経つにつれて、別の非常に重要なことがあることが明らかになりました-要求コンテキスト。 誰が、どこで、いつ設定するか。
3年前、検索結果を生成するときに、ユーザーの地域を考慮し始めました。
重要なクエリの最も簡単な例は、ピザの配達です。 モスクワとヴォルゴグラードの人々は、市内で彼らのために働く配達会社へのリンクを見るべきです。 また、サービスがまだ開発されていない一部の都市では、「ピザ」のリクエストに応じて、そのレシピをすべて表示する必要があります。 Yandexの検索では人の位置が考慮されるようになったため、地域を指定するクエリは30%ずつ入力される頻度が少なくなりました。
昨年の夏、 レイキャビク検索プラットフォームを開始しました 。 彼女はユーザーの言語設定を理解し、検索結果を英語で開く頻度を考慮しました。 英語のリソースをより頻繁に探している人々に対して、検索はそれらへの多数のリンクで応答し始め、逆もまた同様です。
現在、次の検索プラットフォームであるカリーニングラードについて話しています。カリーニングラードは、ユーザーにパーソナライズされた検索のヒントとパーソナライズされた検索結果を提供します。
各部分について詳しく説明します。
パーソナライズド検索のヒント
インターネットナビゲーションツールとしての検索は、目標を達成するための最短ルートを見つけるのに役立ちます。 これらのタスクは、検索ヒントによって数年間解決されます。 それらは、正確に、そして最も重要なことには、迅速にリクエストを作成するのに役立ちます。 コンテキストにも焦点を当てた多数の要因を考慮に入れることも学んだという事実について話しました。 sjestのパーソナライズに役立つ最も重要な起動の1つは、ユーザーの以前の要求を考慮することでした。 つまり、ユーザーが[Titanic]を検索した場合、検索行に文字「k」を入力すると、[Kate Winslet]と[Titanicの削除方法]プロンプトが最初に表示され、[contact]と[metro map]は表示されません。
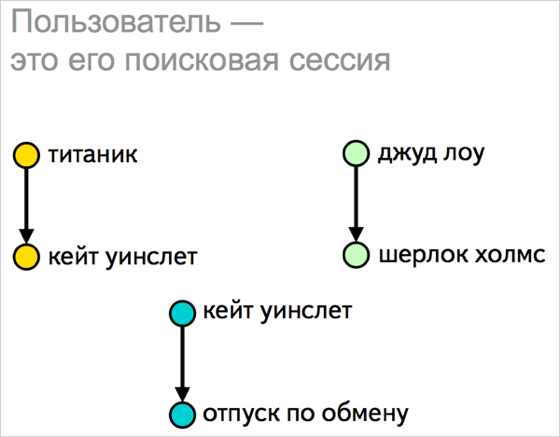
ユーザーがYandexに尋ねる現在のすべてのクエリの半分は、前のクエリに関連しています。 将来の行動を予測するために使用できるデータをユーザーの行動から抽出することを学びました。 検索のヒントでは、Yandexとの関係の履歴を考慮します。どのクエリを実行し、どのリンクをたどったか、これらのアクションはどのように配信されてきたか。
Yandex検索のユーザーは次のように見えることに注意してください。
つまり、リストされたデータを明示的な形式で保存しません。 それらが処理された後、各人に対して比較的小さな数のセットが生成されます。 その中で、それぞれがユーザーが興味を持っている特定のトピックを特徴づけています。 さらに、彼にとって今どれほど重要であるかを考慮に入れています。
検索候補をよりパーソナライズすることはすぐに可能ではありませんでした。 たとえば、 k-means法を使用して 、ユーザーのクラスターを区別できるように思われました。 しかし、そのような機械的方法はあまりうまく機能しないことが判明しました。 そして、セマンティックトピックを強調して、他の方法に進むことにしました。 その最小値は400,000であるべきであることが判明しました。人間の興味の広さも私たちを驚かせました。
その過程で、私たちはそのような関心がどれほど早く時代遅れになるかにも気付きました。 実際、関数型言語でのプログラミングに興味がある人でも、今は自分のアパートの修理を心配しているかもしれません。 そして、彼が彼の興味の1つを考慮することができることを理解することは重要でしたが、実際には今では別のものです。 開発のために、これは、この特定のユーザーにとって時代遅れになる時間がないように、データの配信と処理を整理する必要があることを意味しました。
目標を達成したかどうか、また個人的なものと呼べるようにヒントを作成できるかどうかを理解するために、2つの方法を使用しました。 まず、これがすべて履歴データで機能することを確認しました。 ユーザーが以前に実行した一連のアクションがあります。 それらを使用して、次のことを予測しようとしました。 システムがパーソナライズせずにリクエストを認識するサインを見ました。 このようなオプションは、最初に5人に、次にユーザーの10%に含めました。 次に、同じサイズのプロンプトとコントロールサンプルとの相互作用を比較しましたが、sjestの古いバージョンとの相互作用です。 ご理解のとおり、Yandexユーザーの5〜10%は数百万人です。 この実験では、新しいシステムをすでに含めることができることが示されました-ユーザーはそれを気に入っています。
パーソナライズされた検索結果
本日発表した変更の2番目の部分は、パーソナライズされた検索結果です。 先に述べたように、検索結果は人が住んでいる都市や場所によって異なる場合がありますが、今ではすべての人が自分に合った結果を得る機会があります。
実際、現在、Yandex検索ユーザーと同じ数のオプションがあります。 その人に関する知識、彼の興味、彼が好むサイトなどを考慮に入れます。
実際には、これは、たとえば、異なる人々に対するクエリ[ノーザンライト]への応答が異なることを意味します。 旅行者に、自然現象、ショッピングに興味のある白雲母、ショッピングセンター、映画ファン、映画に関する情報へのリンクについての答えを示します。
パーソナライズにより、各ユーザーのリクエストの75〜80%の回答を改善できます。 パーソナライズによる検索改善の効果を詳細に測定しました。 たとえば、ユーザーは、パーソナライズされていない最初の結果よりもパーソナライズされた最初の結果をクリックする頻度が37%高くなります。 これを達成するために、10を超える異なるランキング式とチューニングメカニズムを使用して実験を実施しましたが、この間に5,000万人を超えるユーザーが実験結果を確認しました。
特徴
もちろん、必要に応じて、 検索設定でパーソナライズをオフにすることができます 。
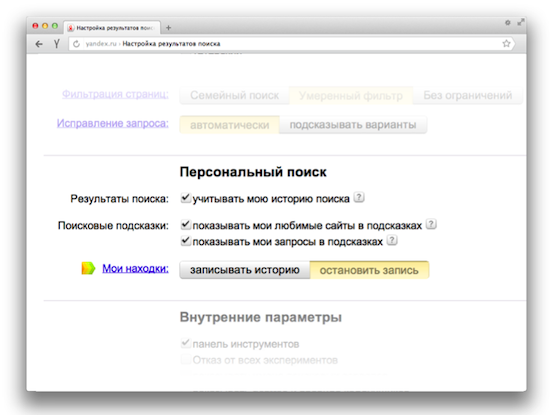
推定によると、全体としてのパーソナライズにより、Yandexを使用する各ユーザーは、自分が来た答えをすばやく受け取ることで、14%の時間を節約できます。