
メモリの割り当てに個別のソリューションが必要になることもあります。 たとえば、並列タスクで
その結果、標準の保守的なアロケーターは、pthread_mutex / criticalセクションへのすべての要求をキューに入れます。 そして、私たちのマルチコアプロセッサはゆっくりと悲しいことに最初のギアに乗っています。
そして、それについてどうすればいいですか? スケーラブルロックフリーダイナミックメモリ割り当て方式の実装の詳細を詳しく見てみましょう。 Maged M. Michael。 IBMトーマスJ.ワトソン研究所。
私が見つけた最も簡単なコードは、Scott SchneiderとChristos AntonopoulosによるLGPLの同志の下で書かれたものです。 検討します。
遠くから始めましょう

だから-どうすれば不要なロックを取り除くことができますか?
答えは表面にあります-ロックフリーリストにメモリを割り当てる必要があります。 良いアイデア-しかし、そのようなリストはどのように構築されますか?
原子操作は私たちを助けるために急いでいます。 InterlockedCompareExchangeであるもの。 しかし、待ってください-期待できる最大値は長く、__ int64です。 そして何をすべきか? そして、ここに何がある-タグで独自のポインタを定義します。
アドレスサイズを46ビットに制限することで、必要なアドオンを64ビットで隠すことができます。これらは後で必要になります。
#pragma pack(1) typedef struct { volatile unsigned __int64 top:46, ocount:18; } top_aba_t;
ちなみに、8/16バイトのアラインメントを考えると、2〜46度ではなく、さらに数度を取得できます。 標準的な方法-発行されたアドレスは奇数であってはならず、浮動小数点に合わせて調整する必要があります。
そしてもう1つ-コードが非常に長くなります。 つまり、標準のフットクロス
desc->Next = queue_head; queue_head = desc;
そのようなパスタに変わります
descriptor_queue old_queue, new_queue; do { old_queue = queue_head; desc->Next = (descriptor*)old_queue.DescAvail; new_queue.DescAvail = (unsigned __int64)desc; new_queue.tag = old_queue.tag + 1; } while (!compare_and_swap64k(queue_head, old_queue, new_queue));
これによりコードが大幅に長くなり、読みにくくなります。 したがって、明らかなものはネタバレの下で削除されます。
ロックフリーFIFOキュー

これで独自のポインタができたので、リストを作成できます。
// Pseudostructure for lock-free list elements. // The only requirement is that the 5th-8th byte of // each element should be available to be used as // the pointer for the implementation of a singly-linked // list. struct queue_elem_t { char *_dummy; volatile queue_elem_t *next; };
そして、私たちの場合-たとえば、このように整列を忘れないでください
typedef struct { unsigned __int64 _pad0[8]; top_aba_t both; unsigned __int64 _pad1[8]; } lf_fifo_queue_t;
アトミック関数での作業のラップ

コードを移植できるように、いくつかの抽象化を定義しましょう(たとえば、Win32の場合、これは次のように実装されます)。
Win32のAtomラップ
#define fetch_and_store(address, value) InterlockedExchange((PLONG)(address), (value)) #define atmc_add(address, value) InterlockedExchangeAdd((PLONG)(address), (value)) #define compare_and_swap32(address, old_value, new_value) \ (InterlockedCompareExchange(\ (PLONG)(address), (new_value), (old_value))\ == (old_value)) #define compare_and_swap64(address, old_value, new_value) \ (InterlockedCompareExchange64(\ (PLONGLONG)(address), (__int64)(new_value), (__int64)(old_value)) \ == (__int64)(old_value)) #define compare_and_swap_ptr(address, old_value, new_value) \ (InterlockedCompareExchangePointer((address), \ (new_value), (old_value)) \ == (old_value))
パラメーターを__int64にキャストしてポインターで渡すことで気が散らないように、別のメソッドを追加します。
#define compare_and_swap64k(a,b,c) \ compare_and_swap64((volatile unsigned __int64*)&(a), \ *((unsigned __int64*)&(b)), \ *((unsigned __int64*)&(c)))
これで、基本機能(追加と削除)を実装する準備ができました。
リストを操作する基本的な機能を定義する
static inline int lf_fifo_enqueue(lf_fifo_queue_t *queue, void *element) { top_aba_t old_top; top_aba_t new_top; for(;;) { old_top.ocount = queue->both.ocount; old_top.top = queue->both.top; ((queue_elem_t *)element)->next = (queue_elem_t *)old_top.top; new_top.top = (unsigned __int64)element; new_top.ocount += 1; if (compare_and_swap64k(queue->both, old_top, new_top)) return 0; } }
何に注意する必要があります-追加の通常の操作はループに包まれており、その方法は-古い値の上に新しい値を正常に書き込みましたが、同時に誰かが古い値を変更していません。 まあ、変更された場合-その後、すべてを繰り返します。 そして別の瞬間-私たちのカウントでは、成功した試みの数を書きます。 些細なことであり、各試行は一意の64ビット整数を与えます。
ロックフリーのデータ構造が構築されるのは、このような単純なシャーマニズムです。
同様に、FIFOリストの先頭からの削除が実装されています。
lf_fifo_dequeueと同様
static inline void *lf_fifo_dequeue(lf_fifo_queue_t *queue) { top_aba_t head; top_aba_t next; for(;;) { head.top = queue->both.top; head.ocount = queue->both.ocount; if (head.top == 0) return NULL; next.top = (unsigned __int64)(((struct queue_elem_t *)head.top)->next); next.ocount += 1; if (compare_and_swap64k(queue->both, head, next)) return ((void *)head.top); } }
ここで、まったく同じことがわかります。削除するものがある場合は、削除しようとするサイクルで、古い値がまだ正しいように-優れていますが、いいえ-再試行します。
そしてもちろん、そのようなリスト項目を初期化するのは簡単です-ここにあります:
lf_fifo_queue_init
static inline void lf_fifo_queue_init(lf_fifo_queue_t *queue) { queue->both.top = 0; queue->both.ocount = 0; }
実際にアロケーターのアイデア

アロケーターに直接進みます。 アロケーターは高速でなければなりません-したがって、メモリーをクラスに分割します。 大きい(システムから直接取得)、小さい、サイズが8バイトから2キロバイトの範囲の多くの多くの小さなサブクラスにbeatられています。
馬とのこのような動きにより、2つの問題を解決することができます。 最初の-小さな破片は超高速で目立ち、テーブルに分割されているという事実により、1つの大きなリストに載ることはありません。 また、大量のメモリが足元に干渉することはなく、断片化の問題につながりません。 さらに、各サブクラスには同じサイズのすべてのブロックがあるため、それらの操作は大幅に簡素化されます。
そしてもう一瞬! 選択した小片をスレッドに添付します(ただし、リリースはそうではありません)。 したがって、1石で2羽の鳥を殺します-割り当ての制御が簡素化され、スレッドにローカルに割り当てられたメモリアイランドが再び混ざりません。
次のようなものが得られます。
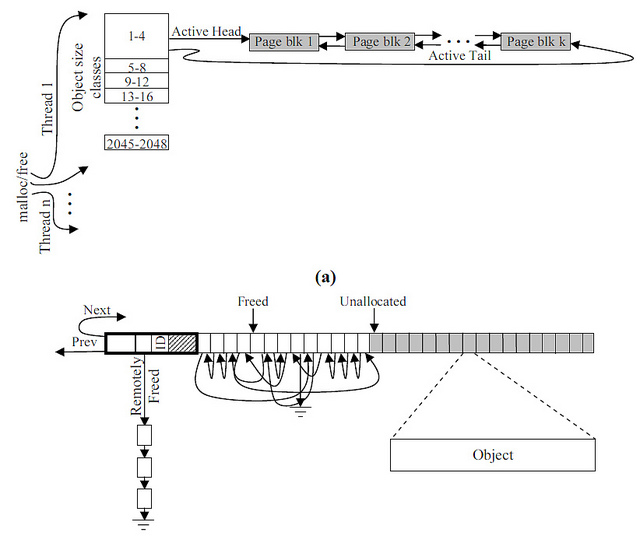
そして、これはデータがスーパーブロックに表示される方法です:
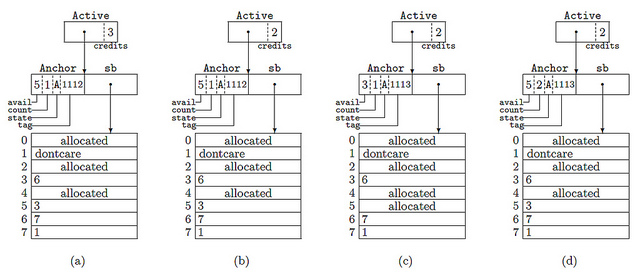
写真には4つのケースがあります
- アクティブなスーパーブロックには、リストに編成された5つの要素が含まれ、そのうちの4つが使用可能です。
- そして、次の要素を予約しました(クレジットを参照)
- その結果、ブロック番号5を発行しました
- そして、それは戻されました(しかし、部分的なリストに到達しました)
ヒップおよびブロック記述子について説明します

女神テクノに祈って、始めましょう。
いくつかの定数を定義する
Balnalism a la GRANULARITYおよびPAGE_SIZE
struct Descriptor; typedef struct Descriptor descriptor; struct Procheap; typedef struct Procheap procheap; #define TYPE_SIZE sizeof(void*) #define PTR_SIZE sizeof(void*) #define HEADER_SIZE (TYPE_SIZE + PTR_SIZE) #define LARGE 0 #define SMALL 1 #define PAGESIZE 4096 #define SBSIZE (16 * PAGESIZE) #define DESCSBSIZE (1024 * sizeof(descriptor)) #define ACTIVE 0 #define FULL 1 #define PARTIAL 2 #define EMPTY 3 #define MAXCREDITS 64 // 2^(bits for credits in active) #define GRANULARITY 8
そして、創造力を発揮して、必要なデータ型を定義しましょう。 したがって、ヒップはたくさんあります-それぞれ独自のクラスで、はい、現在のスレッドに関連付けられています。 スーパーブロックには、アクティブリストと再配布リストの2つのポインターがあります。
あなたは尋ねます-それは何ですか?なぜそれがそんなに難しいのですか?
まず、それが主なものです。要素ごとにリスト要素を選択することは、採算が取れないことです。 つまり、数百万の要素を持つ古典的な一方向のリストが地獄とイスラエルに変わります。 リストの各要素に対して、データ自体とリストの次の要素への2つの不幸なポインタを格納するために、8/16バイトを割り当てる必要があります。
それは有益ですか? 明らかに、いいえ! そして、何をすべきか? そのとおりですが、リスト記述子を500(たとえば)要素のグループ(ストライプ)にグループ化します。 そして、要素ではなくグループのリストを取得します。 経済的で実用的で、クラシックバージョンと同様に要素を操作できます。 すべての質問は、メモリの非標準の割り当てのみです。
さらに、ブロック内のすべてのNextは、単に配列の次の要素を指しているだけであり、ストリップを選択するとすぐに明示的に初期化できます。 実際、ストリップの最後のNextは次のストリップを示しますが、リストを操作するという観点からは何も変わりません。
メモリブロック記述子がそのように構築されていることは簡単に推測できます。
それでも、アクティブは、バイト単位で事前に割り当てられたメモリの断片を持つアクティブストリップであり、FIFOの原則に従ってメモリを発行します。 ストリップに場所がある場合は、そこから取り出します。 そうでない場合は、すでに古典的な部分リストを探しています。 そこにもそこにもなければ-素晴らしい、新しいストライプを強調します。
第二に、このような「バンディング」はメモリオーバーランを引き起こします。64バイトの配列の形式で8バイトのメモリにストライプを割り当てることができ、すべてのいくつかのピースが要求されるためです。 それでも、スレッドごとに異なるアクティブなストライプが存在するため、問題がさらに悪化します。
ただし、実際にメモリを積極的に使用している場合は、速度が大幅に向上します。
こちらはヒップそのものです
struct Procheap { volatile active Active; // initially NULL volatile descriptor* Partial; // initially NULL sizeclass* sc; // pointer to parent sizeclass };
そして、彼が必要なものは次のとおりです。
このアクティブ/パーシャルは何ですか?
typedef struct { unsigned __int64 ptr:58, credits:6; } active; /* We need to squeeze this in 64-bits, but conceptually * this is the case: * descriptor* DescAvail; */ typedef struct { unsigned __int64 DescAvail:46, tag:18; } descriptor_queue; /* Superblock descriptor structure. We bumped avail and count * to 24 bits to support larger superblock sizes. */ typedef struct { unsigned __int64 avail:24,count:24, state:2, tag:14; } anchor; typedef struct { lf_fifo_queue_t Partial; // initially empty unsigned int sz; // block size unsigned int sbsize; // superblock size } sizeclass;
記述子自体はフラグメントの記述子です。
struct Descriptor { struct queue_elem_t lf_fifo_queue_padding; volatile anchor Anchor; // anchor to superblock exact place descriptor* Next; // next element in list void* sb; // pointer to superblock procheap* heap; // pointer to owner procheap unsigned int sz; // block size unsigned int maxcount; // superblock size / sz };
どうやら-超自然的ではない。 メモリは1つのスレッドで割り当てられ、別のスレッドで解放されるため、記述子にヒープとスーパーブロックの説明が必要です。
さあ始めましょう

まず、ローカル変数(ヒープ、サイズなど)を定義する必要があります。 このようなもの:
グローバル変数なし
/* This is large and annoying, but it saves us from needing an * initialization routine. */ sizeclass sizeclasses[2048 / GRANULARITY] = { {LF_FIFO_QUEUE_STATIC_INIT, 8, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 16, SBSIZE}, ... {LF_FIFO_QUEUE_STATIC_INIT, 2024, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2032, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2040, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2048, SBSIZE}, }; #define LF_FIFO_QUEUE_STATIC_INIT {{0, 0, 0, 0, 0, 0, 0, 0}, {0, 0}, {0, 0, 0, 0, 0, 0, 0, 0}} __declspec(thread) procheap* heaps[2048 / GRANULARITY]; // = { }; static volatile descriptor_queue queue_head;
ここでは、前のセクションで検討されたすべてが表示されます。
__declspec(thread) procheap* heaps[2048 / GRANULARITY]; // = { }; static volatile descriptor_queue queue_head;
これはスレッドごとのヒップです。 そして-すべてのプロセスごとの記述子のリスト。
Malloc-仕組み
メモリ割り当ての実際のプロセスをより詳細に検討してください。 つまり、いくつかの機能を簡単に確認できます。
- 要求されたサイズに小さいサイズのヒップがない場合は、システムに問い合わせてください
- メモリを順番に選択します-最初にアクティブリストから、次にフラグメントのリストから、最後に-システムに新しいピースを要求します。
- システムには常にメモリがあり、そうでない場合はループで待機する必要があります
これが解決策です。
void* my_malloc(size_t sz) { procheap *heap; void* addr; // Use sz and thread id to find heap. heap = find_heap(sz); if (!heap) // Large block return alloc_large_block(sz); for(;;) { addr = MallocFromActive(heap); if (addr) return addr; addr = MallocFromPartial(heap); if (addr) return addr; addr = MallocFromNewSB(heap); if (addr) return addr; } }
トピックを掘り下げ、各部分を個別に検討します。 最初から始めましょう-システムから新しいピースを追加します。
MallocFromNewSB
static void* MallocFromNewSB(procheap* heap) { descriptor* desc; void* addr; active newactive, oldactive; *((unsigned __int64*)&oldactive) = 0; desc = DescAlloc(); desc->sb = AllocNewSB(heap->sc->sbsize, SBSIZE); desc->heap = heap; desc->Anchor.avail = 1; desc->sz = heap->sc->sz; desc->maxcount = heap->sc->sbsize / desc->sz; // Organize blocks in a linked list starting with index 0. organize_list(desc->sb, desc->maxcount, desc->sz); *((unsigned __int64*)&newactive) = 0; newactive.ptr = (__int64)desc; newactive.credits = min(desc->maxcount - 1, MAXCREDITS) - 1; desc->Anchor.count = max(((signed long)desc->maxcount - 1 ) - ((signed long)newactive.credits + 1), 0); // max added by Scott desc->Anchor.state = ACTIVE; // memory fence. if (compare_and_swap64k(heap->Active, oldactive, newactive)) { addr = desc->sb; *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor **)addr) = desc; return (void *)((char*)addr + PTR_SIZE); } else { //Free the superblock desc->sb. munmap(desc->sb, desc->heap->sc->sbsize); DescRetire(desc); return NULL; } }
奇跡はありません-スーパーブロック、記述子を作成し、空のリストを初期化するだけです。 そして、アクティブなブロックのリストに新しいブロックを追加します。 ここで、割り当てのループがないことに注意してください。 失敗した場合、失敗しました。 なぜそう 関数はすでにループから呼び出されており、リストに挿入できない場合は、誰かがそれを挿入したことを意味し、最初にメモリを割り当てる必要があります。
次に、アクティブなブロックのリストからブロックを選択します。結局、スーパーブロックを選択する方法などはすでに学習しました。
MallocFromActive
static void* MallocFromActive(procheap *heap) { active newactive, oldactive; descriptor* desc; anchor oldanchor, newanchor; void* addr; unsigned __int64 morecredits = 0; unsigned long next = 0; // First step: reserve block do { newactive = oldactive = heap->Active; if (!(*((unsigned __int64*)(&oldactive)))) return NULL; if (oldactive.credits == 0) *((unsigned __int64*)(&newactive)) = 0; else --newactive.credits; } while (!compare_and_swap64k(heap->Active, oldactive, newactive)); // Second step: pop block desc = mask_credits(oldactive); do { // state may be ACTIVE, PARTIAL or FULL newanchor = oldanchor = desc->Anchor; addr = (void *)((unsigned __int64)desc->sb + oldanchor.avail * desc->sz); next = *(unsigned long *)addr; newanchor.avail = next; ++newanchor.tag; if (oldactive.credits == 0) { // state must be ACTIVE if (oldanchor.count == 0) newanchor.state = FULL; else { morecredits = min(oldanchor.count, MAXCREDITS); newanchor.count -= morecredits; } } } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (oldactive.credits == 0 && oldanchor.count > 0) UpdateActive(heap, desc, morecredits); *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor**)addr) = desc; return ((void*)((char*)addr + PTR_SIZE)); }
アルゴリズム自体は単純で、面倒な形式の記述のみが少し混乱します。 実際、取るものがあれば、スーパーブロックから新しいピースを取り出し、この事実に注意します。 途中で、最後のピースを取得したかどうかを確認し、取得した場合はこれに注意します。
ここには微妙な点が1つあります。つまり、スーパーブロックから最後のピースを取得したことが突然判明した場合、次の要求は既に使用されているものの代わりに新しいスーパーブロックの追加につながります。 そして、これを発見するとすぐに、ブロックが割り当てられているという事実を記録する場所がなくなります。 したがって、選択した部分を部分リストに入力します。
UpdateActive
static void UpdateActive(procheap* heap, descriptor* desc, unsigned __int64 morecredits) { active oldactive, newactive; anchor oldanchor, newanchor; *((unsigned __int64*)&oldactive) = 0; newactive.ptr = (__int64)desc; newactive.credits = morecredits - 1; if (compare_and_swap64k(heap->Active, oldactive, newactive)) return; // Someone installed another active sb // Return credits to sb and make it partial do { newanchor = oldanchor = desc->Anchor; newanchor.count += morecredits; newanchor.state = PARTIAL; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); HeapPutPartial(desc); }
このエッセイの最後の部分に移る前に、記述子の操作を検討する時が来ました。
メモリブロック記述子

手始めに、ハンドルの作成方法を学びます。 しかし、どこに? 実際、誰かが忘れた場合-私たちは単にメモリ割り当てを書きます。 明白で美しい解決策は、一般的な割り当てと同じメカニズムを使用することですが、悲しいかな-これはよく知られているジョークpkunzip.zipになります。 したがって、原則は同じです。記述子の配列を含む大きなブロックを選択し、配列がオーバーフローするとすぐに、新しいブロックを作成し、前のブロックとリストにマージします。
Descalloc
static descriptor* DescAlloc() { descriptor_queue old_queue, new_queue; descriptor* desc; for(;;) { old_queue = queue_head; if (old_queue.DescAvail) { new_queue.DescAvail = (unsigned __int64)((descriptor*)old_queue.DescAvail)->Next; new_queue.tag = old_queue.tag + 1; if (compare_and_swap64k(queue_head, old_queue, new_queue)) { desc = (descriptor*)old_queue.DescAvail; break; } } else { desc = AllocNewSB(DESCSBSIZE, sizeof(descriptor)); organize_desc_list((void *)desc, DESCSBSIZE / sizeof(descriptor), sizeof(descriptor)); new_queue.DescAvail = (unsigned long)desc->Next; new_queue.tag = old_queue.tag + 1; if (compare_and_swap64k(queue_head, old_queue, new_queue)) break; munmap((void*)desc, DESCSBSIZE); } } return desc; }
さて、問題はそれほど強力なソーサリーではありません-記述子を戻すことも学ぶ必要があります。 ただし、同じFIFOに戻ります。誤って受け取った場合にのみ戻る必要があるため、この事実はすぐに明らかになります。 だから問題ははるかに簡単です
降伏
void DescRetire(descriptor* desc) { descriptor_queue old_queue, new_queue; do { old_queue = queue_head; desc->Next = (descriptor*)old_queue.DescAvail; new_queue.DescAvail = (unsigned __int64)desc; new_queue.tag = old_queue.tag + 1; } while (!compare_and_swap64k(queue_head, old_queue, new_queue)); }
ヘルパー

また、リストなどを初期化するための補助関数も提供します。関数は自明であるため、なんとか説明しても意味がありません。
組織リスト
static void organize_list(void* start, unsigned long count, unsigned long stride) { char* ptr; unsigned long i; ptr = (char*)start; for (i = 1; i < count - 1; i++) { ptr += stride; *((unsigned long*)ptr) = i + 1; } }
organise_desc_list
static void organize_desc_list(descriptor* start, unsigned long count, unsigned long stride) { char* ptr; unsigned int i; start->Next = (descriptor*)(start + stride); ptr = (char*)start; for (i = 1; i < count - 1; i++) { ptr += stride; ((descriptor*)ptr)->Next = (descriptor*)((char*)ptr + stride); } ptr += stride; ((descriptor*)ptr)->Next = NULL; }
mask_credits
static descriptor* mask_credits(active oldactive) { return (descriptor*)oldactive.ptr; }
スーパーブロックはシステムから単に要求されます:
static void* AllocNewSB(size_t size, unsigned long alignement) { return VirtualAlloc(NULL, size, MEM_COMMIT, PAGE_READWRITE); }
同様に、ブロックヘッダーにもう少し要求することで大きなブロックを取得します。
alloc_large_block
static void* alloc_large_block(size_t sz) { void* addr = VirtualAlloc(NULL, sz + HEADER_SIZE, MEM_COMMIT, PAGE_READWRITE); // If the highest bit of the descriptor is 1, then the object is large // (allocated / freed directly from / to the OS) *((char*)addr) = (char)LARGE; addr = (char*) addr + TYPE_SIZE; *((unsigned long *)addr) = sz + HEADER_SIZE; return (void*)((char*)addr + PTR_SIZE); }
これは、目的のサイズに適合したヒープのテーブル内の検索です(サイズが大きすぎる場合はbkbゼロ):
find_heap
static procheap* find_heap(size_t sz) { procheap* heap; // We need to fit both the object and the descriptor in a single block sz += HEADER_SIZE; if (sz > 2048) return NULL; heap = heaps[sz / GRANULARITY]; if (heap == NULL) { heap = VirtualAlloc(NULL, sizeof(procheap), MEM_COMMIT, PAGE_READWRITE); *((unsigned __int64*)&(heap->Active)) = 0; heap->Partial = NULL; heap->sc = &sizeclasses[sz / GRANULARITY]; heaps[sz / GRANULARITY] = heap; } return heap; }
リストのラッパーは次のとおりです。 それらは単に説明の目的で追加されます-アトムの周りにパスタで十分なコードがあり、1つのyt関数で比較とスワップの周りに12サイクルを追加します
ListGetPartial
static descriptor* ListGetPartial(sizeclass* sc) { return (descriptor*)lf_fifo_dequeue(&sc->Partial); }
ListPutPartial
static void ListPutPartial(descriptor* desc) { lf_fifo_enqueue(&desc->heap->sc->Partial, (void*)desc); }
削除は簡単に構築されます-リストを一時的なリストに再構築することにより:
ListRemoveEmptyDesc
static void ListRemoveEmptyDesc(sizeclass* sc) { descriptor *desc; lf_fifo_queue_t temp = LF_FIFO_QUEUE_STATIC_INIT; while (desc = (descriptor *)lf_fifo_dequeue(&sc->Partial)) { lf_fifo_enqueue(&temp, (void *)desc); if (desc->sb == NULL) DescRetire(desc); else break; } while (desc = (descriptor *)lf_fifo_dequeue(&temp)) lf_fifo_enqueue(&sc->Partial, (void *)desc); }
そして、部分リストのいくつかのラッパー
RemoveEmptyDesc
static void RemoveEmptyDesc(procheap* heap, descriptor* desc) { if (compare_and_swap_ptr(&heap->Partial, desc, NULL)) DescRetire(desc); else ListRemoveEmptyDesc(heap->sc); }
HeapGetPartial
static descriptor* HeapGetPartial(procheap* heap) { descriptor* desc; do { desc = *((descriptor**)&heap->Partial); // casts away the volatile if (desc == NULL) return ListGetPartial(heap->sc); } while (!compare_and_swap_ptr(&heap->Partial, desc, NULL)); return desc; }
HeapPutPartial
static void HeapPutPartial(descriptor* desc) { descriptor* prev; do { prev = (descriptor*)desc->heap->Partial; // casts away volatile } while (!compare_and_swap_ptr(&desc->heap->Partial, prev, desc)); if (prev) ListPutPartial(prev); }
最後のジャーク-割り当て/解放する準備ができました!

そして最後に、ストライプではなくメモリ割り当てを実装する準備ができました。これにはすでにすべての可能性があります。
アルゴリズムは単純です-リストを見つけ、その中の場所を予約し(同時に空のブロックを解放し)、クライアントに返します。
MallocFromPartial
static void* MallocFromPartial(procheap* heap) { descriptor* desc; anchor oldanchor, newanchor; unsigned __int64 morecredits; void* addr; retry: desc = HeapGetPartial(heap); if (!desc) return NULL; desc->heap = heap; do { // reserve blocks newanchor = oldanchor = desc->Anchor; if (oldanchor.state == EMPTY) DescRetire(desc); goto retry; } // oldanchor state must be PARTIAL // oldanchor count must be > 0 morecredits = min(oldanchor.count - 1, MAXCREDITS); newanchor.count -= morecredits + 1; newanchor.state = morecredits > 0 ? ACTIVE : FULL; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); do { // pop reserved block newanchor = oldanchor = desc->Anchor; addr = (void*)((unsigned __int64)desc->sb + oldanchor.avail * desc->sz); newanchor.avail = *(unsigned long*)addr; ++newanchor.tag; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (morecredits > 0) UpdateActive(heap, desc, morecredits); *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor**)addr) = desc; return ((void *)((char*)addr + PTR_SIZE)); }
次に、メモリをリストに戻す方法を検討します。 一般に、古典的なアルゴリズム:渡されたポインターと記述子に格納されたアンカーによって記述子を復元します-必要なスーパーブロックの場所に行き、必要な部分を空きとしてマークし、そのビールをまだ読んでいる人をマークします。 そしてもちろん、いくつかのチェック-スーパーブロック全体を解放する必要があるかどうか、そうでなければ、まだ解放されていない最後のチェックです。
void my_free(void* ptr) { descriptor* desc; void* sb; anchor oldanchor, newanchor; procheap* heap = NULL; if (!ptr) return; // get prefix ptr = (void*)((char*)ptr - HEADER_SIZE); if (*((char*)ptr) == (char)LARGE) { munmap(ptr, *((unsigned long *)((char*)ptr + TYPE_SIZE))); return; } desc = *((descriptor**)((char*)ptr + TYPE_SIZE)); sb = desc->sb; do { newanchor = oldanchor = desc->Anchor; *((unsigned long*)ptr) = oldanchor.avail; newanchor.avail = ((char*)ptr - (char*)sb) / desc->sz; if (oldanchor.state == FULL) newanchor.state = PARTIAL; if (oldanchor.count == desc->maxcount - 1) { heap = desc->heap; // instruction fence. newanchor.state = EMPTY; } else ++newanchor.count; // memory fence. } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (newanchor.state == EMPTY) { munmap(sb, heap->sc->sbsize); RemoveEmptyDesc(heap, desc); } else if (oldanchor.state == FULL) HeapPutPartial(desc); }
注意する必要があるもの-解放されたピースは部分リストに分類され、チェックを追加するのが良いでしょう-アクティブなストライプの一番上に達すると、縮退したケース「ループ内で選択して解放」の効率が向上します。 しかし、これはすでに宿題です。
結論

この非常に退屈で長い作業の中で、ロックフリーFIFOリストにアロケーターを構築する方法を検討し、それが何であるかを学び、アトミックを操作するための多くのトリックを学びました。リストをストライプにグループ化する機能が、メモリマネージャの作成だけでなく役に立つことを願っています。
追加資料
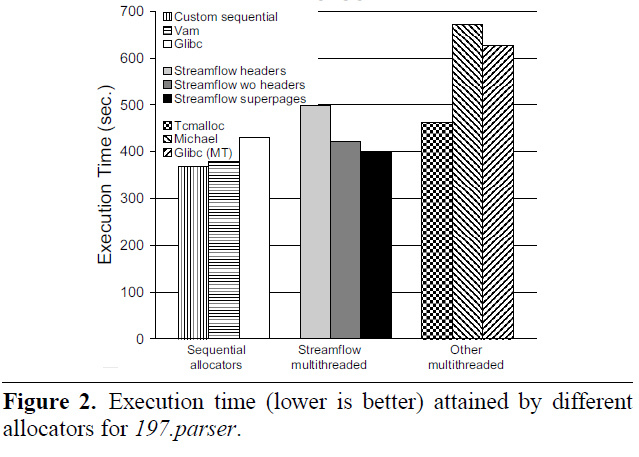
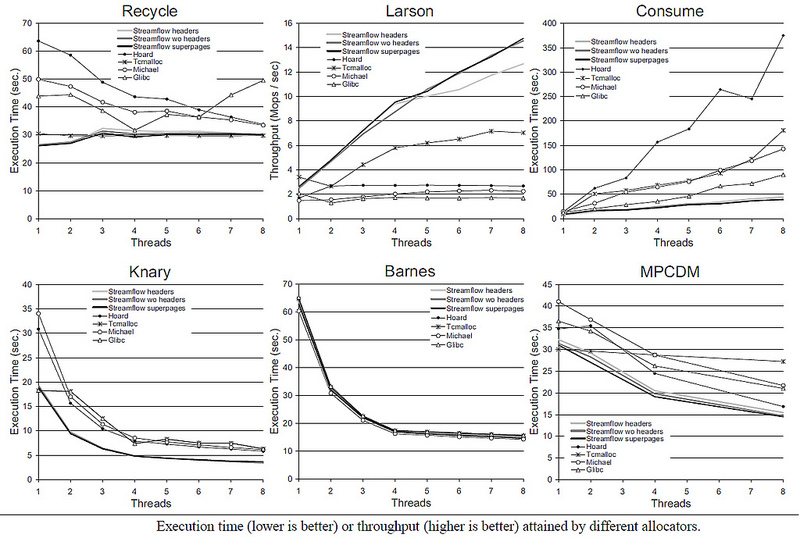
結論として、さまざまなアロケーターの速度に関する[3]の図をいくつか示します(写真をクリックできます)。ご覧のとおり、アルゴリズムは明らかに単純ですが、最高のサンプルのレベルで機能します。その多くは後で登場します。更新:詳細な説明をしてくれたSkidanovAlexに感謝します: ocountが必要な理由は記事から明らかではありません。これは、いわゆるタグ付きポインターの実装です。そうでない場合、そのようなシナリオは可能だということです(ABA問題と呼ばれる-したがって、記事の構造はtop_aba_tと呼ばれます):ポップ操作は次のようになります。
do { long snapshot = stack->head; long next = snapshot->next; } while (!cas(&stack->head, next, snapshot));
deque , ocount. : , B ( A -> B). snapshot = A, next = B.
A, C, . :
A -> C -> B.
pop , CAS (stack->head == snapshot, A), stack->head B. C .
ocount , A ocount, CAS .
しかし、ocountは確かに実際にのみ節約します。理論的には、スナップショットを覚えてから次のスレッドまで、ocountが以前と同じ値をとるまで別のスレッドがA 2 ^ 18回削除でき、ABA問題が再び発生します。
もちろん、最新のハードウェアでは、誰もポインターに48ビットを割り当てません。代わりに、2つの64ビット変数を連続して使用します。1つ目はポインターの下、2つ目はocountの下にあり(要素Aの挿入を伴う理論上のシナリオはさらに理論的になります)、二重casが使用されます。