データの性質
監視システムでは、特定のユーザーに関連付けられていないデータを収集します。 分類子(各テーブルに1つまたは複数)によってデータを集計します。これにより、データの総量を大幅に圧縮できます。 同時に、実質的に何も失うことはありません。特定の時点でのすべてのユーザーの合計アクティビティに関する十分な情報があります。
イベントの正確な時間は記録しませんが、5分ごとにデータを集計します。 また、データ量を大幅に削減し、ブラウザで認識および表示しやすい「より簡単な」グラフを作成できます。
ロガー
サイトのほぼすべてのサーバー(および4000以上)で、各アプリケーションはLog4jに基づくLoggerライブラリを使用します。これは、テーブル、5分、および非同期モードの分類子のすべてのログを集約します。 集約はメモリ内で実行されます。つまり、ディスクでの作業はまったく発生しません。
集計の結果、データを1000回圧縮します。ラッシュアワーの5分間で200億レコードではなく、2,000万レコードしか取得しません。 控えめに言っても、これは非常に大きな違いです。
5分に1回、ロガーは集約データを中間データストアにフラッシュし、メモリから消去します。 さらに、このデータを2分でリセットする必要があります。これにより、できるだけ早く最終消費者に到達し、容量の余裕があります(データリセットに割り当てられる最大時間は5分です。その後、データは次の5分間リセットされるため)。
2つのアプローチを比較してみましょう。 平均書き込み長は200バイトです。
1)非集計データ
1秒あたりのデータ量-20,000,000,000(レコード)* 200(バイト)/ 120秒= 33 GB /秒
1日あたりのデータ量-2,000,000,000,000(レコード)* 200(バイト)= 400 TB /日
2)集計データ
1秒あたりのデータ量-20,000,000(レコード)* 200(バイト)/ 120秒= 33 MB /秒
1日あたりのデータ量-2,000,000,000(レコード)* 200(バイト)= 400 GB /日
データを集約しなかった場合、統計のためだけに33 GB * 8 = 264 Gb / sのネットワーク容量が必要になります。
このアプローチでは、サーバーのリソース(CPUとメモリ)の一部をデータ集約に使用しますが、この部分は非常に小さいため、あまり気にしません。
中間データウェアハウス:進化
中間ストレージがない場合、DWHサーバーの共有は、1秒あたり33 MBの速度でデータを書き込む4000の並列セッションになります。 このような負荷と並行して、データ処理は不可能になります。
中間データウェアハウスのタスク:
1)4000 Loggerアプリケーションから受信したデータをすばやく保存します。
2)DWHサーバーに新しいデータをすばやく提供します。
3)古いデータをDWHにアップロードした後、すぐに削除します。
これは簡単に聞こえますが、私たちが現在持っている、私たちに合った中間データウェアハウスのアーキテクチャにはすぐには行きませんでした。
2008年
2008年にはまだDWHがありませんでしたが、20のテーブルを持つ1つのデータベースにログを書き込む300台のサーバーがありました。 別のアプリケーションが、同じデータベース内のデータに直接アクセスすることでグラフィックを生成しました。 各テーブルには、特定の期間にわたる高速読み取りを保証するために、日付と時刻によるクラスター化インデックスがありました。
サーバーの数とデータの量が増えるにつれて、グラフィックスの生成はますます遅くなりました。 新しいレコードの受け入れを停止するように、ベースを簡単にロードできました。 そのため、彼らは、このデータベースから抽出し、ビジネス分析アプリケーションからの要求を効率的に処理する別個のデータウェアハウスを作成することにしました。
2009年
私たちの新しいシステムは、ログのデータベースからデータを送り出しました。これを「中間ストレージ」と呼び始めました。 古いグラフとロガーは変更せずに動作し続ける必要があるため、データ構造は変更されませんでした。
日付と時間でアンロードするデータをフィルタリングしました。 同時に、同時に多くのデータがあり、それらは非同期に表示されました。 「大きな安全マージン」でデータをアップロードする必要がありました。 そのため、各テーブルに自動インクリメントのbigint ID列を追加し、この列にインデックスを作成しました。 その後、1つのレコードを一度だけアンロードできます。
しばらくの間、これはうまくいきました。 サーバーの数は700台に増えました。そして、突然、ログデータベースが「ゴムではない」ことがわかりました。ディスク領域が不足しています。 DWHにアップロードされた古いログは削除する必要がありましたが、これを行う効果的な方法はありませんでした。 DELETEコマンドを使用することはできません。大きなボリュームでは重すぎて操作が遅いためです。 テーブルを再作成してレコードを削除する必要があったため、データが失われ、サービスが利用できなくなりました。
2010年
サーバーとデータボリュームの数は急速に増加しています。 このような非効率的な方法での古いログは、より頻繁に削除する必要がありました。 これは解決しなければならない本当の問題に変わり、ロガーもDWHも書き直さなくて済むようになっていることが望ましい。
ビューとトリガーを使用してこれを行うことができました。
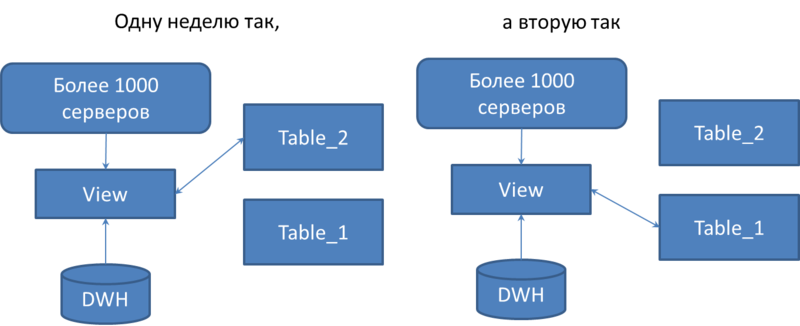
テーブルごとに同一のペアが作成され、名前が変更され、末尾に_1と_2が追加されました。 元のテーブルと同じ名前のビューを作成しました。 サーバーはこのビューに書き込みます。 挿入の代わりにトリガーをビューに追加しました。これは、1週間の_1でテーブルに書き込み、2週の終わりで2週間目をテーブルに書き込みます。
切り替えは2段階で行われます。 まず、トリガーのみが切り替えられ、ビュー自体が前のテーブルからデータを読み取ります。 DWHが前のテーブルからすべてのデータをダウンロードした後、ビューが切り替わります。
その後、truncate tableコマンドを使用して、古いテーブルのデータを効果的に削除します。
したがって、ロガーを変更せずに、ダウンタイムとデータ損失なしでデータを削除できるソリューションを取得しました。
時間の経過とともに、古いチャート作成システムは使用されなくなりました。つまり、日付と時刻によるクラスターインデックスの必要性はなくなりました。 そのため、それを削除し、IDによるインデックスをクラスター化しました。 これにより、システムはさらに効率的になりました。
2011年
サーバーの数が3000を超えました。ビューとトリガーを使用したソリューションは、かなり低いディスクキューで非常に負荷の高いサーバーCPUになりました。 負荷を減らす必要がありましたが、トリガーが存在するため、これは許可されませんでした。 Loggerを1週間で_1、2週間目で_2でテーブルに書き込むように、Loggerを再実行する必要があると判断しました。 彼らはそうしました。
インフラストラクチャの一部が新しいロガーに移されました。 CPUの負荷は低下しましたが、ディスクキューは重大なレベルまで増加しました。 ベースの構造は可能な限りシンプルです-改善するものはありません。 別の解決策を探す必要がありました。
2012年
ディスクキューは、MS SQL Log Managerによって作成され、データベースログファイルを操作します。 その瞬間、MS SQL 2005 Standard Editionデータベースがありました。 専門家は、MS SQL 2008 Log ManagerはMS SQL 2005よりも1桁優れていると主張しました。これを確認することを決定し、MS SQL 2008 Enterprise Editionに切り替えました。 ディスクキューは本当に桁違いに減少しました!
同時に、パーティションテーブルを使用してデータを削除することにしました。 つまり、2009モデルに戻りましたが、IDによるクラスターインデックスのみが2000万レコードのパーティションに分割されました。 パーティションが100%いっぱいになり、すべてのDWHサーバーがデータをダウンロードした後、これらのパーティションは削除されます。
SQLサーバーのパーティションは開発者には「見えない」ため、このソリューションはコードを複雑にしません。 パーティションの削除と追加はオンラインで行われ、接続とデータの損失は発生しません。
結果は、次のアーキテクチャです。

回路内の中間ストレージはログベースと呼ばれます。 それらはすべて構造が同一であり、可能なテーブルの完全なセットが含まれています。 5分に1回集約されたすべてのデータは、これらのテーブルにダンプされます。 サイト管理者は、インストールされた各アプリケーションのロガーを構成して、すべてのログデータベースに負荷が均等に分散されるようにします。 さらに、情報は複製されません。つまり、同じ情報はLogsデータベースの1つにしか入ることができません。
当初、このようなベースが1つありましたが、現在はいくつかあります。 その理由は次のとおりです。
1)問題をホストするときにすべての統計情報が失われないように、各大規模なホスティングには1つのLogsデータベースが必要です。
2)収集されたデータの量が増加すると、ログデータベースはタスクの処理を停止します。
中間データウェアハウスからデータをアンロードする
Logsデータベースへの書き込みと並行して、データはLogsデータベースからDWHデータベースに送られます。
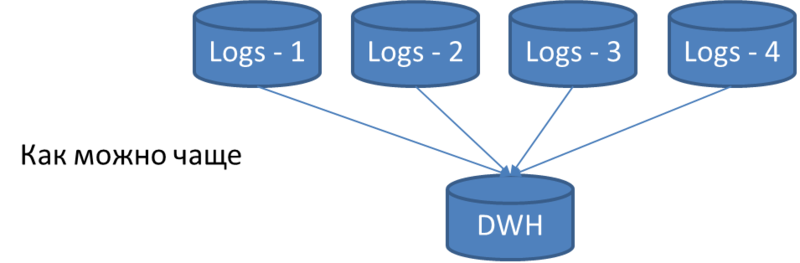
単一スレッドのDWHサーバーは、すべてのLogsデータベースの各テーブルをポーリングし、以前のポンピングの後に出現したすべての新しいレコードをポンピングします。
5分以内に維持するために、データのアップロードがどれだけ速くなるかを計算してみましょう。 ポーリングされたテーブルの数は300 * 4 = 1200です。1つのテーブルに平均300/1200 = 0.25秒が割り当てられていることがわかります。 平均的な表にもっと時間がかかるとどうなりますか? スケール! 別のDWHサーバーを配置し、テーブルの半分を1つのサーバーにアップロードし、残りの半分を2番目のサーバーにアップロードします。

さらにテーブルまたはデータがあり、再び2分以内に維持できない場合は、別のDWHサーバーなどを配置します。 現在、このようなDWHサーバーが3台あります。
次の記事で
次の記事では、DWHサーバーでのデータロードの構築方法と、テーブルあたり平均0.25秒で費やされることについて説明します。