 ハブラハブリ人に対する賢明な批判に関連して、私はこのポストを根本的に再編しました。 このオプションがより積極的に評価されることを願っています。
ハブラハブリ人に対する賢明な批判に関連して、私はこのポストを根本的に再編しました。 このオプションがより積極的に評価されることを願っています。
ほぼ2年間、私はアーカイブとライブラリのコレクションをデジタル化する会社で働いています。 情報のスキャンはストリーム上に置かれ、1日に数万のグラフィックイメージを受け取ります。これを認識して顧客にアップロードする必要があります。 私の仕事は、グラフィック画像から情報を認識するためのコンベア技術を作成することです。
この投稿では、私の経験を共有し、手書き認識技術についてお話したいと思います。
自動認識テスト
入力されたテキスト
ABBYY FineReaderは、このセグメントの議論の余地のないリーダーです。 認識プログラムは、ソフトウェアの主な消費者である企業の標準文書に焦点を当てて開発されています。 これらは非標準形式用に設計されていないため、プログラムは80%を超える信頼レベルを与えることはできません。
10〜20年前にライブラリカードを処理する場合、ABBYY FineReaderは60%を超える信頼性を得ることができません。 下のスクリーンショットをご覧ください。
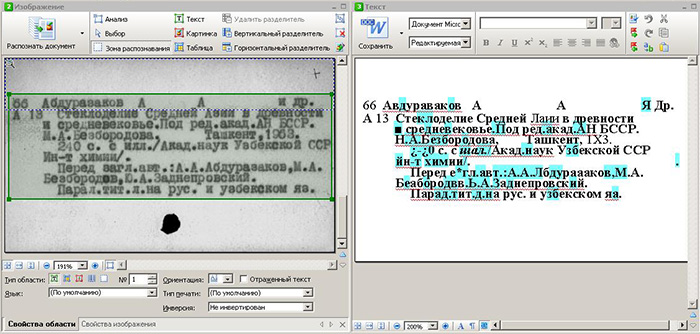
手書きテキスト
ABBYY FineReaderには、トレーニング後にテキストを認識するプログラムのバージョンがあります。 結論は簡単です-製品は空のニューラルネットワークです。 ユーザーは手動で入力する必要があります。 ユーザーが複数の手書きを認識しようとすると、プログラムは結果を生成できません。 このようなソフトウェアソリューションの学習に1週間を費やした結果、最終的には良い結果が得られませんでした。
手書き認識に自動プログラムを使用することは、今日ではほとんど不可能です。 オペレータがグラフィックイメージから情報を入力することが、デジタル化された情報を取得する唯一の方法です。 下のスクリーンショットをご覧ください。
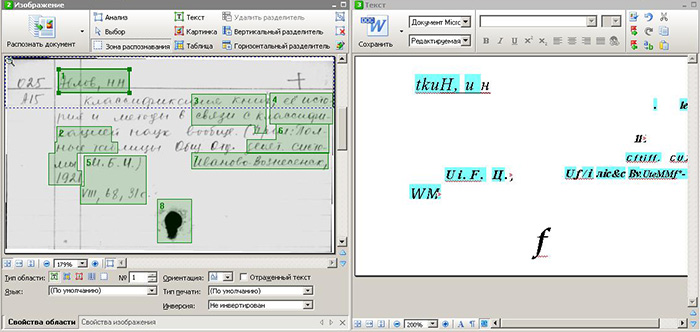
手動認識技術の作成
次に、作成する必要のあるテクノロジーについて説明します。 実装に半年かかったアルゴリズムがありました。 認識されたテキストを取得する手順は次のとおりです。
- スキャン-ストリーミングスキャナーはそれ自体を実行します。
- サブカテゴリの属性によるグラフィックイメージの配列の分離-このステップおよび以降のすべてのステップは、ユーザーが実行します。 この段階では、入力効率を高めることができます。
- 前のステップで行われた作業の検証。
- データ入力。 すべての情報は論理的にフィールドに分割され、部分に入力されます。 各データ配列には、独自の詳細と独自の入力ルールがあります。
- 情報が機密情報である場合-画像は自動的に部分に分割され、各オペレーターは入力のために情報の一部のみを受け取ります。
- 多数のフィールドがある場合-1枚のカードのフィールドは複数の演算子に分割されます。
- 入力データの検証。 エラーの存在は、データを入力する人の賃金に影響します。
- 多くの一般的な自動チェックがベースで実行されます。
- アレイの完成部品の顧客への出荷。
このプロジェクトは「リモート雇用センター」と呼ばれ、勢いを増し始めました。 最初の1か月は、慣らし運転中に発生したエラーを常に修正する必要がありました。 さらに、プロセスが調整され、ソフトウェアは安定して動作し、既製のデータ配列をアンロードし始めました。
負荷が増大するにつれて、アルゴリズムの最適性とその処理速度に関する新しい問題がサーバーで発生し始めました。 それらはローカルで解決されていますが、システム全体の最適化がすぐに必要になる可能性が非常に高いです。
プロジェクト全体は、ウクライナ文化観光省の支援を受けて実施されました 。詳細については、こちらをご覧ください。
システムについて簡単に
プログラミング言語:PHP。
データベース:MySQL。
CMS、フレームワーク:なし、開発はゼロから実行されました。
最後に
ABBYY FineReaderの結果のさまざまなオプションを確認したい人のために、追加のスクリーンショットをここに投稿しました 。
この投稿が肯定的に受け入れられた場合、継続を公開し、CIS諸国の図書館自動化技術がどのように構築されているかについてお話します。 興味深い機能を備えたモジュールに特別な注意を払います。この機能は、インターネットで情報を表示する役割を果たします。