この記事では、コサインメジャーを使用して決定されたユーザーの類似性の協調フィルタリングアルゴリズムと、Pythonでの実装について説明します。

入力データ
ユーザーが製品に付けた評価のマトリックスがあるとします。プレゼンテーションを簡単にするために、製品には1〜9の番号が割り当てられています。

csvファイルを使用して指定できます。最初の列はユーザー名、2番目は製品ID、3番目はユーザーの評価です。 したがって、次の内容のcsvファイルが必要です。
alex,1,5.0 alex,2,3.0 alex,5,4.0 ivan,1,4.0 ivan,6,1.0 ivan,8,2.0 ivan,9,3.0 bob,2,5.0 bob,3,5.0 david,3,4.0 david,4,3.0 david,6,2.0 david,7,1.0
まず、上記のcsvファイルを読み取る関数を開発します。 推奨事項を保存するために、Pythonの標準dictデータ構造を使用します。各ユーザーには、「product」:「rating」という形式の評価のディレクトリが割り当てられます。 次のコードが判明します。
import csv def ReadFile (filename = "<csv_file_location>"): f = open (filename) r = csv.reader (f) mentions = dict() for line in r: user = line[0] product = line[1] rate = float(line[2]) if not user in mentions: mentions[user] = dict() mentions[user][product] = rate f.close() return mentions
類似度
ユーザー番号1に製品を推奨するには、ユーザー数1に評価が最も似ている2-3-4などのユーザーが好む製品から選択する必要があることは直感的に明らかです。 ユーザーのこの「類似性」の数値表現を取得する方法は? M個の製品があるとします。 個々のユーザーが設定した評価は、製品のM次元空間のベクトルであり、ベクトルを比較できます。 可能な対策には次のものがあります。
- コサインメジャー
- ピアソン相関係数
- ユークリッド距離
- 谷本係数
- マンハッタン距離など
より詳細には、さまざまな手段とその適用の側面について、別の記事で検討します。 現時点では、推奨システムではコサイン測定と谷本の相関係数が最も頻繁に使用されていると言えば十分です。 これから実装するコサインメジャーをさらに詳しく考えてみましょう。 2つのベクトルのコサイン測定値は、それらの間の角度のコサインです。 数学の学校のコースから、2つのベクトル間の角度の余弦は、2つのベクトルのそれぞれの長さで割ったスカラー積であることに注意してください。
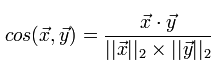
多くのユーザー評価がdict“ product”:“ rating”という形式で表示されることを忘れずに、この測定の計算を実装します。
def distCosine (vecA, vecB): def dotProduct (vecA, vecB): d = 0.0 for dim in vecA: if dim in vecB: d += vecA[dim]*vecB[dim] return d return dotProduct (vecA,vecB) / math.sqrt(dotProduct(vecA,vecA)) / math.sqrt(dotProduct(vecB,vecB))
実装中、ベクトルのスカラー積自体がベクトルの長さの2乗を与えるという事実が使用されました。これはパフォーマンスの観点からは最適なソリューションではありませんが、この例では速度は基本的ではありません。
協調フィルタリングアルゴリズム
そのため、ユーザー設定のマトリックスがあり、2人のユーザーがどのように似ているかを判断できます。 現在、協調フィルタリングアルゴリズムを実装する必要があります。これは、次のもので構成されています。
- 嗜好が問題の嗜好に最も似ているLユーザーを選択します。 これを行うには、各ユーザーに対して、問題のユーザーに関連して選択したメジャー(この場合はコサイン)を計算し、最大のLを選択する必要があります。 Ivanについては、上の表から次の値を取得します。

- 各ユーザーについて、計算された測定値で評価を乗算します。これにより、「類似」ユーザーの評価は、製品の最終的な位置により強く影響します。これは、下の図の表に見ることができます
- 各製品について、最も近いユーザーのLの較正された推定値の合計を計算し、結果の量を選択したユーザーのメジャーLの合計で除算します。 金額は、図の文字列「sum」、文字列「result」の合計値に示されています
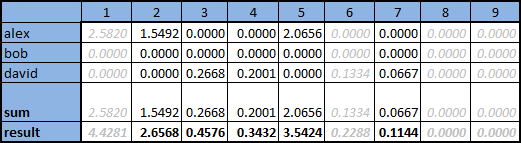
問題のユーザーによって既に評価されている製品の列は灰色でマークされており、ユーザーに再提供することは意味がありません
式の形式では、このアルゴリズムは次のように表すことができます
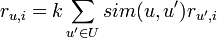
ここで、sim関数は選択した2人のユーザーの類似性の尺度、Uはユーザーのセット、rは割り当てられたグレード、kは正規化係数です。
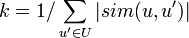
今では適切なコードを書くだけです
import math def makeRecommendation (userID, userRates, nBestUsers, nBestProducts): matches = [(u, distCosine(userRates[userID], userRates[u])) for u in userRates if u <> userID] bestMatches = sorted(matches, key=lambda(x,y):(y,x), reverse=True)[:nBestUsers] print "Most correlated with '%s' users:" % userID for line in bestMatches: print " UserID: %6s Coeff: %6.4f" % (line[0], line[1]) sim = dict() sim_all = sum([x[1] for x in bestMatches]) bestMatches = dict([x for x in bestMatches if x[1] > 0.0]) for relatedUser in bestMatches: for product in userRates[relatedUser]: if not product in userRates[userID]: if not product in sim: sim[product] = 0.0 sim[product] += userRates[relatedUser][product] * bestMatches[relatedUser] for product in sim: sim[product] /= sim_all bestProducts = sorted(sim.iteritems(), key=lambda(x,y):(y,x), reverse=True)[:nBestProducts] print "Most correlated products:" for prodInfo in bestProducts: print " ProductID: %6s CorrelationCoeff: %6.4f" % (prodInfo[0], prodInfo[1]) return [(x[0], x[1]) for x in bestProducts]
その健全性を確認するには、次のコマンドを実行できます。
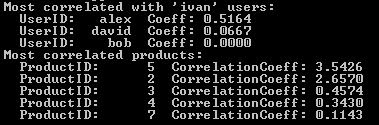
rec = makeRecommendation ('ivan', ReadFile(), 5, 5)
これにより、次の結果が得られます。
おわりに
例を見て、コサイン類似度測定を使用した協調フィルタリングの最も単純なオプションの1つを実装しました。 協調フィルタリングには、 他 のアプローチ 、製品評価を計算する他の式 、類似性の他の尺度があることを理解することが重要です( 記事 、「参照」セクション)。 このアイデアのさらなる開発は、次の分野で実施できます。
- 使用されるデータ構造の最適化 。 Pythonにデータを辞書として保存する場合、特定の値にアクセスするたびにハッシュが計算され、名前文字列が長くなると状況が悪化します。 実際のタスクでは、 スパース行列を使用してデータを保存し、テキストのユーザー名と製品名の代わりに、数値識別子(すべてのユーザーとすべての製品に番号を付ける)を使用できます。
- パフォーマンスの最適化 。 明らかに、各ユーザーの連絡先の推奨を計算することは非常にコストがかかります。 この問題にはいくつかの回避策があります。
- ユーザーをクラスタリングし、同じクラスターに属するユーザー間でのみ類似性の尺度を計算する
- 製品間類似度係数の計算。 これを行うには、use-productマトリックスを転置する必要があります(product-userマトリックスを取得します)。その後、各製品について、同じコサインメジャーを使用し、 k個の最も近いものを記憶して、最も類似した製品のセットを計算します。 これはかなり時間がかかるプロセスなので、 M時間/日ごとに1回実行できます。 しかし、これに類似した製品のリストがあり、ユーザー評価に製品類似度の値を掛けると、 O(N * k)の推奨が得られます。Nはユーザー評価の数です
- 類似性の尺度の選択 。 コサインメジャーは最も一般的に使用されるものの1つですが、メジャーはシステムデータの分析結果に従ってのみ選択する必要があります
- フィルタリングアルゴリズムの変更 。 おそらく、別のフィルタリングアルゴリズムが特定のシステムでより正確な推奨事項を提供します。 繰り返しますが、さまざまなアルゴリズムの比較は、特定のシステムに適用された場合にのみ実行できます。