
未来は、データを製品に変える企業と人々に属します
人類はまだ立ち止まったことがありません-厳しい生存法則により、人類は常に前進し続けています。 人類の発展の歴史の中で、革命は常に起こりました。ある社会は別の社会に置き換わり、時代遅れの技術はより高度な技術に置き換わりました。 最新の情報革命は、20世紀の80年代のパーソナルコンピュータの出現に関連しています。 デジタルという新しい形で情報を蓄積することを可能にする新しい技術の出現の結果として、産業社会に取って代わる情報社会が形成され始めました。 情報社会とは、大多数が情報の生産、保管、処理、販売に携わっている社会です。 すべての努力が商品の生産と消費に向けられている産業社会と比較して、情報社会は知性と知識を消費し、これが精神労働のシェアの増加につながります。 情報技術の発展は、社会構造を体系的に変化させており、意思決定方法にも影響を与えています。 情報の生成、送信、処理を提供する人々、すなわち 情報通信技術の専門家。 多数の人々に関する情報社会の決定は、投票に基づいて過半数によって行われます。 イベントへの反応時間は数分であり、イベント自体はほとんどすぐにわかります。 それにもかかわらず、現代社会で起こっている進化の過程を理解していない一部の政府は、新しい社会で最も価値のある商品である情報へのアクセスを制限しようとしています。 議論のテーマが人為的に制限され、一部の人は禁止されている社会で育った人々は、情報に自由にアクセスできる社会で育った人々と比べて満腹になることはありません。 必要な検閲は、社会自体によって実行されます-そして、そのような社会の発展レベルが高いほど、自己検閲のレベルが高くなります。 社会の情報モデルへの完全な移行がスムーズであり、ショックや革命がなければよい。 問題を抱えた時代を経験しなければならないのは本当に悪いことです。 さて、今後のイベントの展開をフォローする機会があります。 しかし、私はこれについて話したくありませんでした。
情報社会における主な価値と商品は、情報、またはむしろ知識です。 現在、企業の蓄積データの量は18か月ごとに2倍になり、倍増期間は絶えず減少しています。 2012年の世界のデジタルデータの総量は約2.7ゼタバイトです。これらは27と20のゼロです。 2011年と比較した場合の増加はほぼ50%で、2005年の20倍です。 2015年までに、総データ量は0.8ヨタバイト-10 24になると予測しています。

データボリュームの成長曲線を見ると、指数関数形式をとっていることがわかります。 また、このデータのほとんどは基本的にデジタルビデオ、写真、音声情報ですが、テキストデータの量は比較的多くなります。 最近生まれた「ビッグデータ」という用語が、今やますます頻繁に聞けるようになったことは驚くことではありません。 特定のツールまたは製品がビッグデータフィールドに属するかどうかを判断するには、3つのVのルールを使用して比較的単純です。これは、ボリューム-ボリューム、速度-速度、バラエティ-多様性です。 問題のオブジェクトが3 Vのルールの定義内にある場合、そのオブジェクトはビッグデータ領域に属します。 多種多様な情報通信技術の開発から、現時点では、仮想化、クラウド、および大量のデータ(ビッグデータ)のストレージと処理に関連する領域という3つの主な傾向があります。 そしてその前は、データは研究と分析の対象でしたが、現在この現象は真にグローバルな規模を獲得しています。 誰もデータウェアハウスにデータを無料で保存することを望みません。 DIKWの階層情報モデルを詳しく見ると、データ自体は重要ではないことがわかります。 値を取得する前に、いくつかの段階を経る必要があります。 より正確に言えば、データレベルはまさにその基盤であり、DIKWモデルによる次のステップはデータにコンテキストを追加する情報であり、すでに適用可能で価値がある知識があり、最後のステップはデータから事実を取得することができる知恵です意思決定の基礎。 DIKWモデルは、データ管理の概念の根底にあります。 しかし、大量のデータを保存および処理するための技術的基盤はすでに存在し、世界中で積極的に実装されていますが、理論上の領域はそれに遅れをとっています。 これが、いわゆるデータサイエンス、つまりデータサイエンスの原因です。 データサイエンスという用語は、データサイエンス:統計分野の技術領域を拡大するための行動計画を書いたウィリアムクリーブランド教授によって10年以上前に造られました。 そして今年、EMCはラスベガスで最初のデータサイエンスサミット2012を開催し、この分野のデータ、定義、および問題の処理に関連する問題を取り上げました。 ちなみに、EMCはロシアにデータサイエンティストの空席を開設しました。これは、この分野の開発に対するEMCの関心を示しています。
この記事では、データサイエンスという用語の背後に隠されているものと、データサイエンティストについて詳しく見ていきたいと思います。
実際、データサイエンスは、大量のデータを分析するための方法とテクノロジーの組み合わせのミッシュマッシュであるため、現時点では本格的な科学とは見なされません。 それにもかかわらず、その誕生は私たちの目の前で起こり、現在、データ科学に関連する特定の技術と方法を呼ぶ権利の再分配があり、この科学の主題についての議論もあります。 より広い意味では、データサイエンスは、データセットから知識を抽出できるようにするものです。 データサイエンスは、より複雑なアプローチの点で通常の統計とは異なります。分析には、ドライ統計を含むテーブルだけでなく、他のデータも含め、すべての可能なソースが分析に関与します。
彼らは単に存在しないため、これはこの分野の専門家の検索を著しく複雑にします。 スペシャリストは、好奇心、数学的統計の知識、情報技術分野の幅広い展望、新しいものを発見する能力と欲求、ビッグデータの分野における最新の成果に精通し、さまざまなデータを引き付ける能力とそれらを処理する方法など、まれな資質のセットを組み合わせる必要があります。 Michael Lukidisは、O'REILLY RADARで公開された記事「What is Data Science」で、データサイエンティストに対する要件を非常によく表しています。 また、これらの要件は、次の図の3つの円の交点で表すことができます。
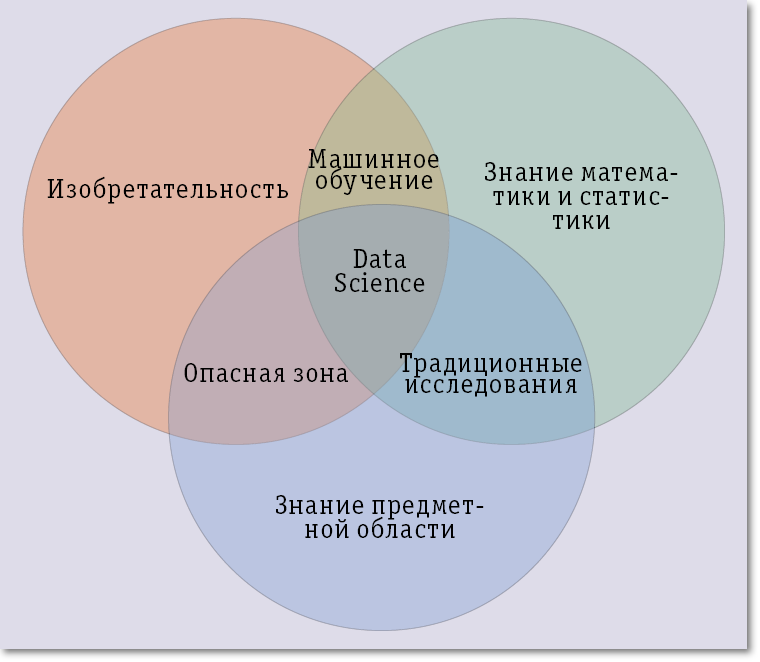
それにもかかわらず、データサイエンティストを白衣の科学者に紹介して、研究室で革新的な技術を発明しないでください。 最も可能性が高いのは、データ科学者を、数学的統計の方法を知っている人、基本的なツールに精通している人、過去にこの分野で理論的な研究に従事していた情報技術分野、特にビッグデータの分野に精通している人として特徴付けることです。
前回のData Science Summit 2012カンファレンスでの議論の主要なトピックの1つは、世界のそのような専門家の検索とその将来の展望に関連するトピックでした。 データの成長のダイナミクス、および情報通信技術の急速な発展を見ると、将来このような専門家の必要性は増加するだけであり、それらの需要は絶えず増加すると結論付けるのは簡単です。 一部の政府はすでに見通しを評価し、適切な措置を講じています- 米国国立科学財団は、ビッグデータのトピックを科学分野と同一視し、ビッグデータに関する学際的研究の資金調達のための新しい分野を発表しました。これは一連の春の発表と一致します。
データサイエンティストが誰であるかをよりよく理解するために、この欠員の申請者に尋ねることができる質問のリストを提供します。 残念ながら、知り合いやデータサイエンティストのリストは必要ありません:(
質問1:
ループを使用せずにRの行列の列の分散をどのように計算しますか?
質問2:
1-名、2-姓の2列のCSVファイルがあるとします。 スクリプト言語を使用してコードを記述し、1列目に姓、2列目に名を持つCSVファイルを作成します。
質問3:
Map / Reduceについて説明し、お気に入りのプログラミング言語でそれを使用して簡単な例を記述します。
質問4:
あなたがGoogleで、広告のクリック率(CTR)を評価したいとします。 1000件のリクエストがあり、それぞれが1000回呼び出されています。 各リクエストには10個の広告が表示され、すべての広告は一意です。 各広告のCTRを見積もります。
質問5:
10個の変数で回帰を実行し、そのうちの1つが95%の信頼区間で有意であるとします。 データの10%がランダムに失われ、Y値が削除されたことがわかります。 失われたYの値をどのように予測しますか?
質問6:
銀行の2つの支店のいずれかに行く機会があるとします。 最初の支店には10人のレジがあり、それぞれ10人の顧客の別々の行があり、10人のレジの2番目の支店には100人の顧客に1つの共通の行があります。 どの部門を選択しますか?
質問7:
ランダムフォレストが通常の回帰ツリーとどのように異なるかを説明してください。