
Maxwell Renderを使用してレンダリングされた画像。
悪いところから始めましょう
アンビアスが出現したとき、それらは不十分に最適化され、鉄ははるかに弱かった。 少なくともCISでは、クアッドコアでさえまれでした。 多くのデザイナーは、ノイズが画像を離れるのに長時間待たなければならないという事実を考慮して、そのようなレンダリングを放棄しました。 多くの専門家は、Maxwellでレンダーボタンを押して許容可能な品質、たとえば8(またはそれ以上)の時間を待つよりも、Vrayでグローバルライティングを設定し 、Photoshopで一般に2〜3時間で後処理を行う方がはるかに簡単です。 時には、ある種の屈折によるノイズが数日間消えたがらないことがありました。
そして、それらの良いところは何ですか?
物理的に正確な効果:
- グローバル照明 、( 苛性アルカリを含む);
- 被写界深度 (DOF)およびシェイク (モーションブラー);
- 地下分散 ;
- 分散をサポートするレンダリングもあります。
-ソフトシャドウ、現実的な反射、一般に、すべてが人生のようです。
これらの効果はすべて、レンダリングの最初の数秒で見られます。
レンダリング時間は、三角形の数にほとんど依存しません。これにより、三角形の数のリソースを節約できなくなります。
さらに、ハードウェアは静止しておらず、プロセッサーのパフォーマンスは徐々に向上しています。さらに興味深いことに、ビデオカード( GPGPU )での汎用コンピューティングテクノロジーの開発により、計算にGPUのシェーダーコアを使用するレンダリングが表示され始めました。 そして、レンダリング自体が同じ計算コストで最高の画像を生成し始めました。
見てみましょう
レンダリングプロセスは次のようになります。

Core i5 2500 3.3GHz、Maxwell Render 2.6、400kトライアングル、3ds Maxモデルで個人的に作成。
ランデブーレンダリングの中心にあるのは、さまざまなタイプの最適化によるパストレースです。
(おそらく、GPUへのパスのトレースに関する投稿をすでに公開および公開していることに気づいた訪問者もいました。しかし、このトピックをより深くより広範囲にカバーすることにしました。)
***
アルゴリズム
パストレース(PT)は、モンテカルロ統合に基づいています。 1ピクセルごとに計算するサンプルが多いほど(ピクセルの色=この時点でのすべてのサンプルの色の算術平均)-結果はより正確になります。
サンプルは、(カメラから光源への)シーンを介して反射と屈折のパスを通過したレイであり、画像内の特定のポイントでペイントされたピクセルの色を形成します。
ボクセル化のほぼ直後(後で)画像のプレビュー(ノイズの多い画像)を取得します。
サンプルの数を無限にすることはできません。 「理想的な」絵は決してありません;それは無限の時間がかかります。 ノイズが目に見えない場合、レンダリングは完了したと見なすことができます。 (通常、ピクセルあたり1000〜10000サンプル、またはFullHDイメージごとに20〜200億サンプル、さらに特別な場合)。 また、わずかなノイズが画像をよりリアルにすることも忘れないでください。
光線が進む経路が複雑になるほど、ノイズは遅くなります。
光源をレンダリングする最も簡単な方法。 光源からの光線は直接カメラに入射します。
光源からの直接光線で照らされたオブジェクトをレンダリングすることはより困難です。
さらに複雑なのは、光源で照らされた別のオブジェクトで照らされたオブジェクトです。
などなど。 内部では、複雑なパスを計算するためにより多くのコンピューティングリソースが使用されるという単純な理由により、この機能により、内部よりもレンダリングが難しくなります。

左から右に、直接光、1回目の反射、2回目の反射、3回目の反射が生じます。
ほとんどのレンダリングでの反射と屈折の最大深度は設定可能で、デフォルトでは8に等しくなっています。
一部の(たとえば、Maxwell、Fry)では、反射の深さははるかに大きい数によって制限され、表面のパラメーターに依存します。 たとえば、暗褐色のテーブルの大きな反射深度を計算するのは意味がありませんが、ガラス内部の屈折を計算するには、反射深度を大きくする必要があります。
ソフトシャドウ
PTでソフトシャドウを取得するアルゴリズムは非常に単純です。 カメラから表面上の点に向かって放射されるビームは、光源の任意の場所に向けられます(「ランダム性の程度」は、指定された表面のパラメーターによって異なります)。
ビームが光源に正常に到達した場合(緑)、このピクセルを目的の色でペイントします。
途中でビームが障害物(赤)に遭遇すると、画面上の対応するピクセルは塗りつぶされません。
(ちなみに、このアルゴリズムはレイトレーシングでのシャドウのレンダリングに似ています)

ピクセルごとのサンプル数:左側に1つ、右側に5つ。
説明のために、二次反射はありません。
反射と屈折
反射機能は主に粗さの程度に依存します。 そして、粗さの程度は、反射ビームからの偏差の誤差の大きさによって決まります。
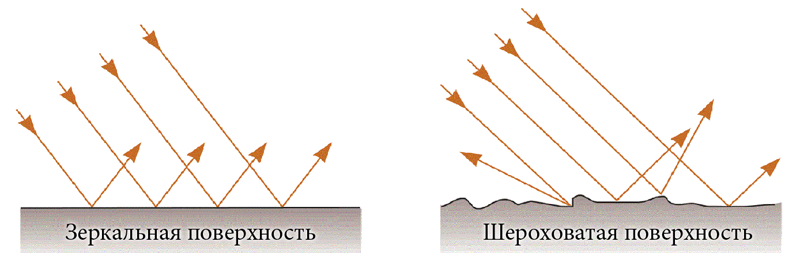
偏差の程度= 0の場合、鏡像が得られます。 1 (または100%)の場合 -入射ビームは任意の方向に反射できます。 0から1まで、さまざまな程度の粗さの反射が得られます。

表面の粗さの度合い(0〜1)。
反射関数はより複雑になる場合があります(たとえば、 異方性表面 )。
屈折の粗さアルゴリズムは反射に似ています。ビームのみがオブジェクトに浸透し、このオブジェクトの屈折率に従って方向を変えます。
素材
材料は、通常、いくつかの層で構成されます。

プラスチックの表面の簡略化されたモデル。
多くのバイアスレンダリング(Maxwell、Fry、Indigo、Lux)では、実際の表面下の分散を計算できます。 光線の一部は表面の下を通過して散乱し、結果の画像で補正されます。
被写界深度
写真で知られている効果は、PTで実際に追加の計算コストなしで達成されます。

***
最適化方法
重要度サンプリング
「重要なサンプリング」は、コンピューターが「クリーン」な領域で計算能力を浪費しないようにするために必要です。 多くの場合、直接光で照らされた表面は「クリーニング」されますが、屈折または反射光で照らされた領域は非常に長い間ノイズが残ります。

赤で強調表示された領域は、ノイズが増加しています。
双方向パストレース
純粋なPTはめったに使用されません。 仮想カメラから発する光線が光源に到達する確率は非常に小さく、光源のサイズに大きく依存します。 光源が小さいほど、ビームが「入り込む」ことが難しくなります。
BDPTアルゴリズムは、光源とカメラから同時に光線を放射します。 これにより、「痛みを伴わずに」光源をシーンに導入することができます。
最も公平なGPUレンダリングで使用されます。
メトロポリスライトトランスポート
MLTミューティングビームアルゴリズムは、同じサンプル数でより少ないノイズを可能にします。 アルゴリズムは、結果のイメージに強く影響する光線の「ノード」(反射点)を保持し、ビームの元の方向からわずかに逸脱します。 また、ビームの経路に追加のノードを導入することもできます。 その後、方向の変化がビーム強度にどの程度影響したかをチェックし、このビームをさらに突然変異させるかどうかを決定します。
CPUを使用するすべての公平なレンダリングで使用されます。
(変化する光線を最適化する別の方法があります-Energy Redistribution Path Tracingですが、それはどこでも使用されておらず、それに関する情報はほとんどありません。)
どのように機能するか、ビデオをより明確に見ることができます(MLT対BDPT)。
ここでは、レンダリングの最適化の各方法の有効性を確認できます。
ボクセル化
レンダリングの前に、ボクセル化が必要であるため、プログラムは1つのレイとの交差の可能性についてすべての三角形をチェックしません。 アルゴリズムは、ビームのパスに三角形を配置できない空間の領域を破棄します。
オブジェクトは、ジオメトリの変更が発生するたび、または新しいオブジェクトが追加されるたびにボクセル化する必要があります。 ただし、カメラを動かしたり、オブジェクトや環境のマテリアルを変更する場合は必要ありません。
さらに、PTにボクセルレンダリングアルゴリズムを導入できます。
***
GPU
最新のGPUはCPUよりもはるかに優れたフロート計算に対応しているため、パスのトレースは徐々に肩に置かれます。
リアルタイムレンダリング
愛好家はすでにPTを使用してゲームを作成し始めています。 十分に強力なカードがある場合は、 自分でゲームを試すことができます (OpenCLを使用) (CPUでプレイすることはできますが、かなり遅くなります) 。
次のビデオの著者( 彼のサイトを見ることをお勧めします )は、近い将来、PTグラフィックエンジンがゲームで使用されると主張しています。 このビデオは、2 GTX580を使用してリアルタイムでレンダリングされます。
GPUの使用方法
CUDA-ソフトウェアおよびハードウェアアーキテクチャにより、C ++をコンパイルし、Nvidiaグラフィックカードで計算を実行できます。
ATIFirestreamも同じですが、ATIカードのみです。
OpenCLは、すべてのOpenCL互換(最新のCPUおよびGPU)デバイスでコンピューティングするためのフレームワークです。
DirectCompute-Microsoftのフレームワーク。DX10、11をサポートするビデオカードでサポートされています。
GLSLは、すべてのグラフィックアクセラレータで動作するシェーダープログラミング言語です。
次のビデオは、さまざまなプログラミングプラットフォームを使用した物理演算の速度を示しています。 そして、グラフィックスのような物理学には、優れた浮動小数点パフォーマンスが必要なので、このビデオはこの記事に適用できると思います。
( GLSLはCUDAレベルで速度を示しますが、なぜGLSLにPTが存在しないのですか? )
***
その他
最も有名なアンビアスレンダリング:
Maxwell Renderは、最も人気のある不偏レンダリングです。
Indigoには、IndigoRTに対応するGPUがあります。
RandomControlのFryRenderレンダーには、GPUに対応するArionレンダーがあります。
LuxRenderオープンソースレンダリングは、GPUアクセラレーションをサポートしています。 このサイトでは、完全なGPUレンダリング-SmallLuxGPUも見つけることができます。
Octane Renderは完全なGPUレンダリングです。
iRayは、最新の3ds Maxが同梱されており、CUDAとプロセッサを使用しています。
Cycles Render (Blenderに統合され、CUDAとOpenCLの両方をサポート)。
人気の誤り
V-Ray RTはアンビアスレンダリングであるという一般的な誤解があります。 いいえ、そうではありません。 これは、適応型アンチエイリアスレイトレーシングです。 もちろん、シャドウのサンプリングとレンダリングは、パストレースアルゴリズムに似ています。 ただし、グローバルな照明とコースティクスは、当時の一般的な設定の影響を受けるため、特定のケースごとに調整する必要があります。
Bunkspeed HypershotおよびLuxeon Keyshot(iRayに切り替える前の以前のバージョン)についても同様です。
要約すると:
V-Ray oldfagsはVireaのすべての美しさを実現でき、正しいと言うでしょう。 結局のところ、レンダリングは主なものではありません。 主なものは、頭、まっすぐな腕、魂に創造性を持つアーティストです!
しかし、公平なレンダリングは、レンダリングの技術的な設定に注意を払うのではなく、創造的なプロセスに集中するのに役立ちます。