HabréでR環境の機能について何度か話しましたが、Rはさまざまな分野に適用できる非常に興味深い強力なツールであるため、追加情報が役立つと思います。 Twitterのトレンドの1つの外観の分析の例を使用して、これを証明しようとします。 これを行うには、twitteRライブラリが必要です。このライブラリを使用すると、APIを介してTwitterを操作できます。 しかし、最初に、Rについて詳しく説明します。
統計データ処理およびプログラミングRのシステムは、コマンドラインインターフェイスの使用に焦点を当てています。 Rシステムでのデータ処理は、ソースデータ、計算、および結果のテキストまたはグラフィック出力を読み込むための一連のコマンドです。 このようなシーケンスは、コマンドライン(インタラクティブモード)とテキストファイル(バッチモード)の両方を使用してユーザーが生成でき、計算のテキストまたはグラフィックの結果を画面に表示したり、対応するファイルに書き込むことができます。
グラフィカルインターフェイスに精通しているユーザーにとって、このアプローチは不快で時代遅れに思えるかもしれませんが、幸いなことに、これは単なる誤解にすぎません。 基本的なスキルを習得した後、キーボードとコマンドラインインターフェイスを使用したデータ処理の効率は低下しませんが、マウスとグラフィカルインターフェイスを使用した場合よりも高くなります。 理由の1つは、統計分析で使用される数百の関数をメニューおよびピクトグラムで使用することは、可能な限り非常に困難であり、Rコマンドラインはインタープリターの観点から正しい関数の任意の組み合わせを受け入れることです[1]。
Rは、Twitterソーシャルネットワークのユーザーの気分を分析することで実証できる十分な機会を提供します。
2月26日の夜遅く、英国の有名な俳優ローワン・アトキンソンの悲劇的な死についての情報がユーザーに広まり始めました。 この事実は確認されませんでしたが、メッセージの数が増え、ビーン氏を演じた俳優の死のニュースはすぐにTwitterのトレンドになりました。 俳優の死に関するメッセージには、RIP Rowan Atkinsonというフレーズが含まれていました。 Rの機能を使用して、問題のイベントを分析し、情報発信の段階を視覚化できます。
分析されたデータは、送信者、日付、時刻、およびメッセージテキストに関する情報を含むテキスト配列です。
データは次のように取得されます。
library(twitteR)
tweets = searchTwitter("RIP Rowan Atkinson", n=1500)
data = twListToDF(tweets)
取得したデータを使用して、情報フローを作成するプロセスを視覚化し、ユーザーが最もアクティブだった時間を追跡することが可能です。
図1は、ユーザーが1日ごとに生成するメッセージの数を示しています。 グラフによれば、最初のメッセージの出現、メッセージ数の増加、および朝のピークの達成を追跡できます。 次に、このトピックに対するユーザーの関心が徐々に低下し、衰退しています。

図1. 1日あたりのメッセージ数
グラフは次のように構成されます。
library(ggplot2)
c <- ggplot(data, aes(created))
c + geom_bar()
図2は、送信されたメッセージの時間ごとの分布を示しています。 グラフは、2月26日の20時間後に最初のメッセージが表示され始め、2月27日の朝に最大数のメッセージが落ちたことを示しています。
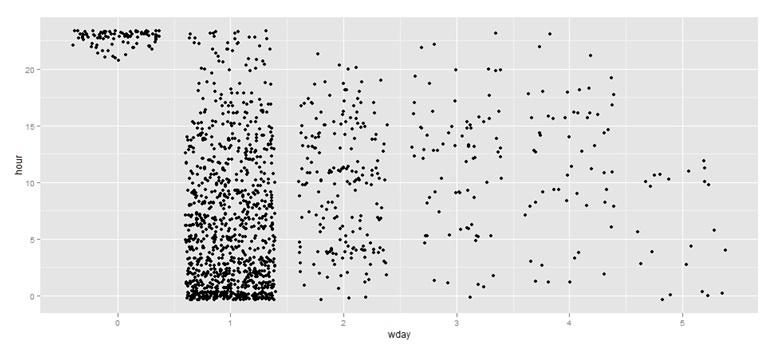
図2.時間ごとの送信メッセージの分布
グラフは次のように構成されます。
library(ggplot2)
data$month=sapply(data$created, function(x) {p=as.POSIXlt(x);p$mon})
data$hour=sapply(data$created, function(x) {p=as.POSIXlt(x);p$hour})
data$wday=sapply(data$created, function(x) {p=as.POSIXlt(x);p$wday})
ggplot(data)+geom_jitter(aes(x=wday,y=hour))
図3は、ユーザーメッセージで最も一般的な単語のクラウドを示しています。

図3.メッセージ内の最も一般的な単語のクラウド
グラフは次のように構成されます。
library("tm")
text = Corpus(DataframeSource(data.frame(data[1])))
text = tm_map(text, removePunctuation)
text = tm_map(text, tolower)
tdm = TermDocumentMatrix(text)
m = as.matrix(tdm)
v = sort(rowSums(m),decreasing=TRUE)
library("wordcloud")
wordcloud(names(v), v^0.3, scale=c(5,0.5),random.order=F, colors="black")
上記の例は、Rの可能性がどれほど広いかを示しています。すでにこのような小さなデータサンプルで、Rで作成されたグラフを使用して、情報の普及の社会的側面を分析し、いくつかのパターンを強調することができます。
現在、R実装は、GNU / Linux、Apple Mac OS X、およびMicrosoft Windowsの3つの最も一般的なオペレーティングシステムファミリに存在します。 2010年9月末に、CRANシステムの分散ストレージ施設で2548個の拡張パックが利用可能になりました。これは、計量経済学と財務分析、遺伝学と分子生物学、生態学と地質学、医薬品と医薬品などで生じる特定のデータ処理タスク向けです。適用領域。 近年、ヨーロッパおよびアメリカの大学の大部分は、高価な商業開発の代わりに、教育および研究活動でRの使用に積極的に移行しています[1]。
文学
1.システム内のデータの統計分析R. Textbook / A.G. Bukhovets、P.V. モスカレフ、V.P。 ボガトヴァ、T.Ya。 ビリュチンスカヤ; エド。 教授 Bukhovets A.G.-Voronezh:VGAU、2010年-124秒