カットの下の詳細。
装備品
実行されたテストのパフォーマンスをよりよく理解するには、何が行われたかを伝える価値があります。 自宅のコンピューターでデスクトップカテゴリでテストを実行しました。
- プロセッサー:Pentium Dual-Core T4300 2100 Mhz
- RAM:DDR2 2048Mb
Windows Phoneでのテストは、HTC 7 Mozartで実行されました。
試験準備
テストでは、単純なxmlファイルが使用されました。 各要素のIDはランダムに生成され、レコードの数はテストによって異なり、それぞれ1、10、100、1,000、100,000個になりました。 結果のファイルは次のようになりました。
<? xml version ="1.0" ? >
< items >
< item id ="433382426" />
< item id ="1215581841" />
< item id ="2085749980" />
........
< item id ="363608924" />
</ items >
* This source code was highlighted with Source Code Highlighter .
エラーを減らすために、各テストを100回実行し、得られたデータを平均しました。 また、レコードに対するいくつかのアクションをシミュレートするために、空のProcessId(id)メソッドが呼び出されました。
XmlDocument.Load
私の意見では、この方法でデータを読み取ることの実装は最も単純で最も理解しやすいものです。 しかし、最後に見るように、これは非常に高いコストで実現されます(記事の最後では、XPathを使用しないこのメソッドの実装が示されていますが、個人的には結果はそれほど変わりません)。 メソッドコードは次のとおりです。
private static void XmlDocumentReader( string filename)
{
var doc = new XmlDocument ();
doc.Load(filename);
XmlNodeList nodes = doc.SelectNodes( "//item" );
if (nodes == null )
throw new ApplicationException( "invalid data" );
foreach ( XmlNode node in nodes)
{
string id = node.Attributes[ "id" ].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .
LINQ to XML
また、Linq-to-XMLを使用すると、メソッドの実装が非常に簡単で簡単になります。
private static void XDocumentReader( string filename)
{
XDocument doc = XDocument .Load(filename);
if (doc == null || doc.Root == null )
throw new ApplicationException( "invalid data" );
foreach ( XElement child in doc.Root.Elements( "item" ))
{
XAttribute attr = child. Attribute ( "id" );
if (attr == null )
throw new ApplicationException( "invalid data" );
string id = attr.Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .
Xmlreader
最後に、XMLからデータを読み取る最後の方法は、XmlTextReaderを使用することです。 この方法が最も理解しにくいと言う価値があります。 xml-fileを読み取るプロセスでは、ファイルを上から下に移動し(反対方向に移動する可能性はありません)、データを抽出する必要があるかどうかを確認する必要がありますか? したがって、メソッドコードは次のようになります。
private static void XmlReaderReader( string filename)
{
using ( var reader = new XmlTextReader (filename))
{
while (reader.Read())
{
if (reader.NodeType == XmlNodeType .Element)
{
if (reader.Name == "item" )
{
reader.MoveToAttribute( "id" );
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter .
*簡単にするため、メソッドではチェックを省略しました。
デスクトップの結果
以下はテスト結果です。 各テストを実行するために、時間を個別に測定してから平均しました。 テーブル内のミリ秒単位の時間。
| 1 | 10 | 100 | 1,000 | 10,000 | 100,000 | |
| XmlDocument | 0.59ミリ秒 | 0.5ミリ秒 | 0.67ミリ秒 | 2.49ミリ秒 | 21.73ミリ秒 | 398.91ミリ秒 |
| Xmlreader | 0.51ミリ秒 | 0.47ミリ秒 | 0.55ミリ秒 | 1.31ミリ秒 | 8.62ミリ秒 | 79.65ミリ秒 |
| Linq to XML | 0.57ミリ秒 | 0.59ミリ秒 | 0.64ミリ秒 | 2.09ミリ秒 | 15.6ミリ秒 | 192.66ミリ秒 |
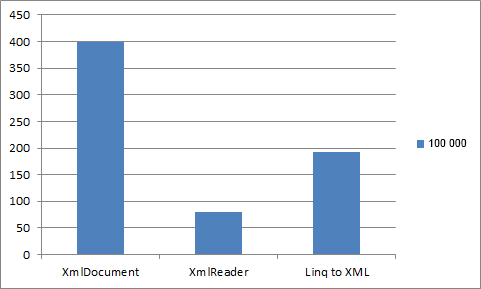
表からわかるように、XmlReaderは大きなxmlファイルを読み取るときに、Linq To XMLのパフォーマンスが2.42倍、XmlDocument が5倍以上も優れています。
Windows Phoneでのテスト
今が電話でテストを行うときです。 古いバージョンの.Net FrameworkがWindows Phoneにインストールされているため、XmlDocument.Loadを使用するメソッドが機能せず、XmlReaderのコードをわずかに書き換える必要があることに注意してください。
private static void XmlReaderReader( string filename)
{
using ( var reader = XmlReader.Create(filename)) {
while (reader.Read()) {
if (reader.NodeType == XmlNodeType .Element) {
if (reader.Name == "item" ) {
reader.MoveToAttribute( "id" );
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter .
Windows Phoneの結果
予想通り、XmlReaderは電話でより高速であることが判明しました。 ただし、デスクトップコンピューターとは異なり、大きなファイルでのパフォーマンスの違いは異なります。 XmlReader電話では、LINQ to XMLより1.91倍、デスクトップでは2.42倍高速です。
| 1 | 10 | 100 | 1,000 | 10,000 | 100,000 | |
| Xmlreader | 1.67ミリ秒 | 1.74ミリ秒 | 3.19ミリ秒 | 19.5ミリ秒 | 173.84ミリ秒 | 1736.18ミリ秒 |
| Linq to XML | 1.73ミリ秒 | 2.21ミリ秒 | 4.75ミリ秒 | 31.39ミリ秒 | 314.39ミリ秒 | 3315.13ミリ秒 |
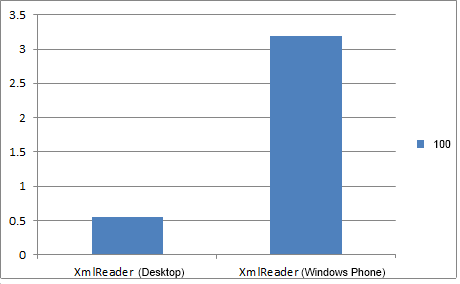
デスクトップとWindows Phoneのファイルから100個の要素を読み取る速度の違い。
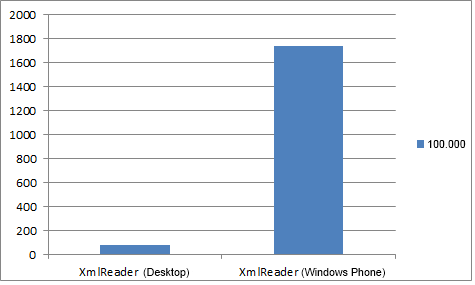
デスクトップとWindows Phoneのファイルから100,000アイテムを読み取る速度の違い。
ご覧のとおり、データの量に応じて、電話とデスクトップコンピューターでデータを読み取る速度は非線形に変化します。 なぜそうなのかを知るのは興味深い。
おわりに
説明したように、xmlからデータを読み取る最も生産的な方法は、プラットフォームに関係なくXmlReaderを使用することです。 しかし、その使用の不便さは、データをフェッチするためのかなり複雑な方法です-ポインターがどの要素にあるかをチェックするたびに。
パフォーマンスが基礎とならない場合、そして最も重要なことは、コードメンテナンスの明快さと単純さである場合、LINQ to XMLが最適です。 また、パフォーマンスが低いため、作業プロジェクトでXmlDocument.Loadを使用しないようにしてください。
PS この記事が私にこのすべてを書くように促したことに言及する価値があります。
更新:提案で、 alex_rusはXPathを使用せずにXmlDocumentのテストを行いました。 結果は良くなりましたが、それでもこの方法は最も遅いままでした。
表3。XPathを使用した場合と使用しない場合のXmlDocumentのパフォーマンスの比較。
| 1 | 10 | 100 | 1,000 | 10,000 | 100,000 | |
| XmlDocument(c XPath) | 0.59ミリ秒 | 0.5ミリ秒 | 0.67ミリ秒 | 2.49ミリ秒 | 21.73ミリ秒 | 398.91ミリ秒 |
| XmlDocument(XPathなし) | 0.56ミリ秒 | 0.5ミリ秒 | 0.65ミリ秒 | 2.24ミリ秒 | 19.47ミリ秒 | 362.75ミリ秒 |

表(および図)からわかるように、生産性はわずか10%増加しました。 この値ははるかに高くなるという提案がありましたが。
実際、XPathを使用しないXmlDocumentのコードは次のとおりです。 知識のある人がエラーのある場所を示し、その結果、処理速度が「時々」ではなく、10%だけ増加することを願っています。
private static void XmlDocumentReader2( string filename)
{
var doc = new XmlDocument ();
doc.Load(filename);
XmlElement root = doc.DocumentElement;
foreach (XmlElement el in root.ChildNodes)
{
if (el.Name != "item" ) continue ;
string id = el.Attributes[ "id" ].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .