
ABBYY FineReaderの次の各バージョンは、ますます直感的になっています。 特に、最新バージョンには、マウスを数回クリックするだけでアクションの標準シーケンスを実行できるビルトインスクリプトのシステムが含まれています。 そのため、ほとんどのユーザーがプログラムを使用して作業できるようにしています。 それにも関わらず、FineReaderには、表面にない多くの機能がありますが、上級ユーザーには役立ちます。 この投稿では、これらの機能のいくつかについて説明します。
ABBYY FineReader 10 Professional Editionの言語作成機能から始めましょう。 なぜ誰のために必要なのですか? 基本的には、記事、非文字、略語、数字など、多くの特定の構造を含むテキストの認識に携わっている人向けです。 一見そのようなケースはまれなようですが、ユーザーからよく似た質問に遭遇します。 たとえば、FineReaderフォーラムで興味深いケースが説明されました。ユーザーはポーカーブックを認識する必要があり、もちろんスーツシンボルがありました。 スーツの正しい表示で問題を解決するために、プログラムで新しい言語を作成することをお勧めします。 この手順により、そのようなドキュメントでの作業が容易になり、処理時間が大幅に短縮されます。 作成プロセス自体はそれほど時間がかからず、特定の知識も必要ありません。ここでは注意が必要です。 理解しやすくするために、これがどのように行われるかを示します。
新しい言語のパラメータを設定するメインダイアログは、[ ツール] -> [ 言語エディタ ]メニューから[ 新規... ]ボタンをクリックして呼び出します。 言語は既存の言語の1つに基づいて作成されるため、新しい言語のプロパティを編集する前に、基本となる言語を選択してください。 認識できるテキストがロシア語である場合は、ベーステキストとして選択する必要があります。 [ 言語のプロパティ]ウィンドウを開きます。
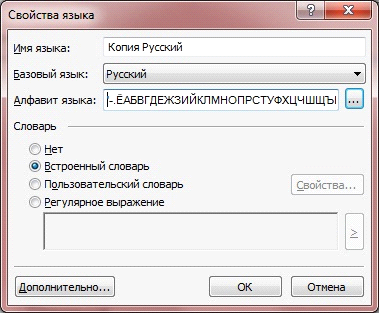 」
」
アルファベットの作成からこのプロセスを開始する必要があると推測するのは簡単です。 編集ボタンを押すと、独自のアルファベットを作成するための幅広い可能性を備えたダイアログが表示されます。ここでは、馴染みのあるキリル文字から特別な数学的および装飾的なものまで、60以上のセットから任意のシンボルを追加できます。 必要な文字を見つけてアルファベットに追加し、編集ウィンドウを閉じます。
文字をアルファベットに追加する機能に加えて、逆の手順があります-不要な文字を削除します。 たとえば、リリースが60〜70年の本を認識した場合、認識言語から&#@などの文字を削除することは理にかなっています。 そのため、あいまいなタイプの文字を認識するときに、プログラムが不要なオプションを排除するのに役立ちます。
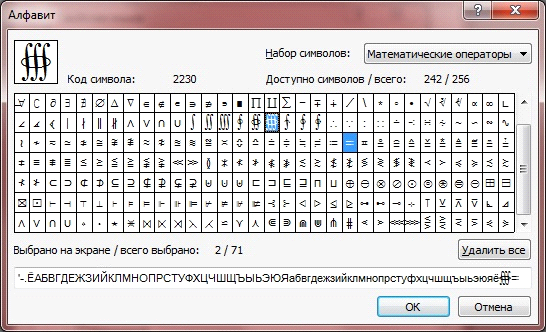
アルファベットの作業が完了したら、システムが認識および確認するときに使用する辞書を選択し、追加のプロパティ(たとえば、単語の先頭と末尾に出現する可能性がある文字など)を指定する必要があります。 FineReaderはテキストを認識する準備ができました。
新しい言語を作成したとき、おそらく「 言語エディター 」ダイアログで使用可能な2番目のオプション-「新しい言語グループの作成」に気づいたでしょう。 テキストがいくつかの非伝統的な言語で同時にコンパイルされているドキュメントを同時に認識しなければならない人に役立ちます。 たとえば、突然、アイマラ語、コンゴ語、ズールー語の言語で書かれた科学論文を認識する必要がありました...
プログラムには事前に定義された言語グループもあることをすぐに思い出させてください。 これらは、2つまたは3つの一般的な言語、たとえばロシア語と英語、または英語、ドイツ語とフランス語などで書かれた文書を認識するために使用されます。 そのようなドキュメントの場合、毎回新しいグループを作成する必要はありません。 そして、中国語の単純化された化学式と単純な化学式の組み合わせ、または英語と以前に自分で作成した化学式の組み合わせが突然必要になった場合、ここにいます。 「言語の新しいグループを作成する」オプションをチェックして、提供されたリストから必要な言語を選択して追加してください。 新しく作成されたグループの元の名前を思いつくことを忘れないでください-次に使用できます。
次の機会-「トレーニングでの認識」-装飾フォントで印刷されたテキストを認識する必要がある場合に便利です。 そのような場合、使用可能な文字からアルファベットを作成することは物理的に不可能ですが、テキストで使用される独自の文字の標準を作成し、それを使用して装飾フォントを認識できます。 多数の複雑な数式を含むテキストを認識し、大量の低品質のテキストを認識する場合にも、この機能を使用すると便利です。
それでも標準を作成することにした場合は、[ 認識 ]タブの[ ツール ]-> [ オプション ]メニューに移動します。 ここで、 トレーニンググループで、[ トレーニングで認識する ]チェックボックスをオンにし、[ 標準 ]ボタンをクリックして、新しい参照を作成するためのダイアログを表示する必要があります。 新しい標準の名前を入力し、開いているダイアログをすべて閉じて、認識プロセスを開始します。 なじみのないシンボルが見つかるとすぐに、このシンボルの画像を含む「 手動学習リファレンス」ダイアログが開きます。
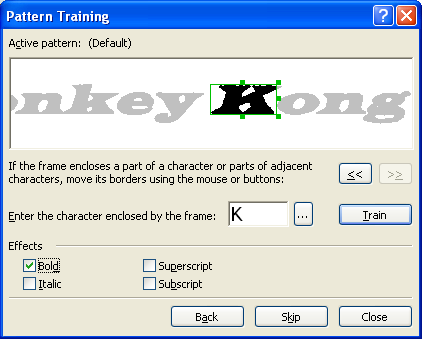
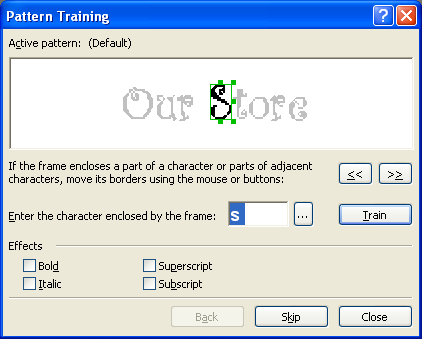
認識の結果として、FineReaderが教えたなじみのない文字の値を正確に取得できます。 このような簡単な方法で、FineReaderトレーニングが行われます。 ちなみに、作成した標準は保存できます-その後、必要に応じて編集したり、何度も使用したりできます。
本日、2つのFineReaderの機能についてお伝えしましたが、これらはまだ知られていない可能性があり、便利な場合があります。 これらおよびその他の興味深いFineReader関数はヘルプに記載されているため、時々参照することをお勧めします。
アリサ・ラフマノワ、
テキスト認識製品部