多くの人は、このアドバイスの実際的な側面に興味を持っているかもしれません。実際には、ソートされたベクトルは連想コンテナよりも速くなることがあります。 私もこの問題に興味があり、小さなテストを行い、すべてが適切に収まるようにいくつかのグラフを描くことにしました。
ちょっとした理論、初心者向け(どのベクターとマップを読む必要がないかを知っている人)。 STLのマップは、キーと値のペアを保存するための連想コンテナです。 データはソートされた形式で格納されますが、C ++標準では実装が指定されていませんが、ほとんどの場合、マップは赤黒ツリーとして実装され、各要素は2つの子へのポインタを格納します。 STLのベクターは、そこに格納されているデータが断片化されないことを保証する要素のコンテナーにすぎません。 その中の効果的な検索は、ソートおよびさらにバイナリ検索によって整理できます。 最初の場合と同様に、検索の複雑さはO(ln(n))です。 速度の違いは、2番目の場合のキャッシュの改善により異なります(データはローカルに配置され、ストレージに必要なメモリは少なくなります)。
挿入速度と検索速度を比較するために、コンテナでのランダム値の記録(gettimeofdayを使用)と一定時間のコンテナでのランダム値の検索(コンテナでのランダム値(ランダム(3))の記録)の2種類の測定を行うテストプログラムが作成されました( 10秒)。 したがって、データをコンテナに挿入するのにかかる時間と、一定の時間間隔でコンテナ内の検索数が測定されます。
ツールキット:
ハードウェア:スワップファイルなしのデュアルプロセッサ(Intel Xeon E5420)サーバー。
ソフトウェア:カーネル2.6.28、gcc 4.3.3を備えたUbuntuサーバー。
キーを使用したプロジェクトのコンパイル:-O3 -felide-constructors -fno-exceptions -fno-rtti -funroll-loops -ffast-math -fomit-frame-pointer -march = core2
各テストは数回実行され(N = 10)、特定のパラメーターの最小値、最大値、平均値が記録されました。 テスト中、取得した値の差は最小限に抑えられました(サーバーの負荷を軽減し、CPUアフィニティをインストールします)。
アイテムをコンテナに挿入するときに取得されるデータ
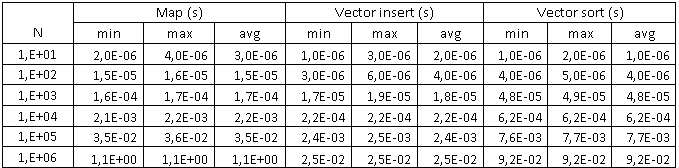
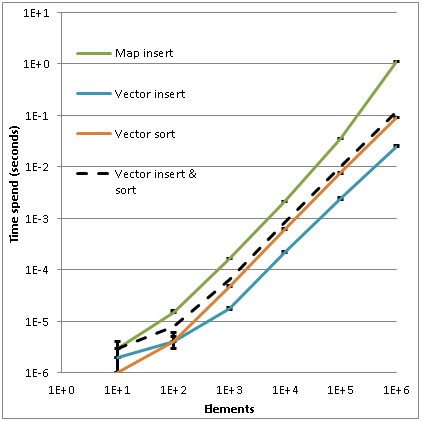
最初のグラフは、要素の数に応じたコンテナの挿入時間とソート時間の依存性を示しています。 両方のスケールは対数であるため、明確にするために、ベクトルの挿入時間とソート時間の合計を示す別の曲線が作成されました。これは破線で示されています。 水平の黒い線は、各実験のエラー-最大値と最小値を示しています。 ご覧のとおり、100万件のレコードの場合、ベクターの挿入と並べ替えにかかる時間は、マップ(1.1秒)の約10分の1(0.11秒)です。
コンテナ内のアイテムを検索するときに取得されるデータ
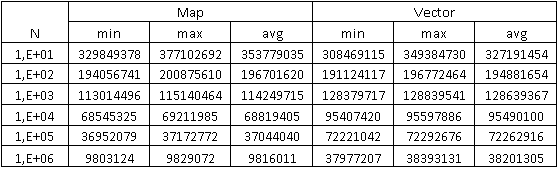
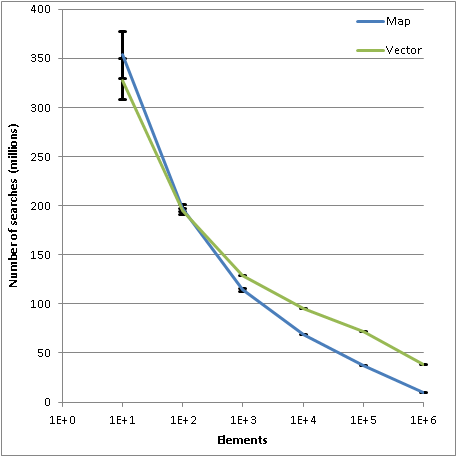
2番目のグラフは、単位時間(10秒)あたりの検索数のコンテナ内の要素数への依存性を示しています。 上記で予想したように、ベクターの検索速度が速く、100万件のレコードでベクターの検索数がマップの約3.9倍であることがわかります。
これらのテストから、ベクターのパフォーマンスはマップよりも大幅に(3.9倍)高いことがわかります。一方、ベクターの単一の充填とそのソートもマップよりも高速(10倍)です。 したがって、ソートされたベクトルは、まれなデータ変更や頻繁な検索の状況で使用する必要があります。たとえば、プログラムの起動中にロードされ、今後ほとんど変更されないデータです。 そしていつものように、時期尚早な最適化は悪であることを忘れてはなりません。