यह वास्तव में क्या है
एक बार, एक दिसंबर की देर शाम, सैट पर हैबर लेख के लिए सामग्री का संग्रह पूरा हो गया था। बहुत अधिक सामग्री थी, और मेरे पास एक विकल्प था: लेख को दो भागों में विभाजित करना या सभी सामग्रियों को एक साथ एक लेख में एकत्र करना। पसंद को भागों ( पहले और दूसरे ) में विभाजित करने के पक्ष में बनाया गया था। मेरे आश्चर्य करने के लिए, दूसरे भाग को पहले की तुलना में काफी कम ध्यान दिया गया - वास्तव में, इसे आधे लोगों द्वारा पढ़ा गया था।
समय बीतता गया, और मैंने नोटिस करना शुरू किया कि यह न केवल मेरे लेखों के साथ हुआ, बल्कि कई हिस्सों में कई अन्य लेखों के साथ भी हुआ। तब मेरा एक सवाल था, क्या यह आम तौर पर सच है कि दूसरे हिस्से को कम ध्यान (विचार, प्लसस, और पसंदीदा) प्राप्त होता है?

(एक हाब्र-लेख के आधार पर बनाया गया कि आंकड़ों की मदद से झूठ कैसे बोला जाए )
लेख संरचना
नतीजतन, निम्नलिखित विचार मेरे पास आया: लेखों के जोड़े इकट्ठा करने के लिए - पहला या दूसरा भाग और देखें कि क्या लेखों के बीच मुख्य मापदंडों में महत्वपूर्ण अंतर है। और यह भी मूल्यांकन करें कि ये पैरामीटर लेखों के लिए कई (दो से अधिक) भागों में कैसे बदलते हैं।
डेटा
पिछले लेख की तरह, विज़ुअलाइज़ेशन के लिए सभी डेटा, कोड और स्क्रिप्ट जीथब पर डाउनलोड के लिए उपलब्ध हैं। आप पिछले लेख से कोड और उदाहरणों का उपयोग करते हुए, सभी प्रयोगों को दोहरा सकते हैं, साथ ही सभी स्रोत डेटा एकत्र और सत्यापित कर सकते हैं । सबसे पहले, प्रयोगों की पारदर्शिता और पुनरावृत्ति सुनिश्चित करने के लिए यह आवश्यक है, साथ ही उन लोगों के लिए कुछ शुरुआती बिंदु प्रदान करना चाहते हैं जो हब्र-डेटा पर अपना शोध करना चाहते हैं।
कई हिस्सों में लेख डेटा एकत्र करना सबसे आसान काम से दूर है, लेकिन हम कुछ सरल विचारों का उपयोग करके पर्याप्त लेख एकत्र कर सकते हैं। चलो पिछले लेख से एक habra- लेख के साथ all.csv डेटासेट पर विचार करें

हेबर को पढ़ने में शानदार अनुभव ने मुझे यह संकेत दिया कि शीर्षक (टैबलेट में शीर्षक) के लिए कई भागों के बारे में जानकारी क्या होनी चाहिए। यदि हम कीवर्ड भाग की उपस्थिति के लिए सभी सुर्खियों से गुजरते हैं, तो हम उम्मीदवारों के अच्छे सेट को एक साथ रख सकते हैं। लेखों के प्रारंभिक फ़िल्टरिंग के लिए एक साधारण फ़िल्टर- थ्रू स्क्रिप्ट में प्रभावशाली, लेकिन लेखकों द्वारा वर्गीकृत उम्मीदवार लेखों की एक विशाल सूची नहीं है। उम्मीदवारों का विश्लेषण करने के बाद, दो डेटासेट श्रृंखला1। एससीवी और सीरीज़ 2। एससीवी का गठन किया गया, जिसमें क्रमशः पहले और दूसरे भाग शामिल हैं:

प्रत्येक डेटासेट में 180 प्रविष्टियाँ हैं।
भागों की तुलना करें
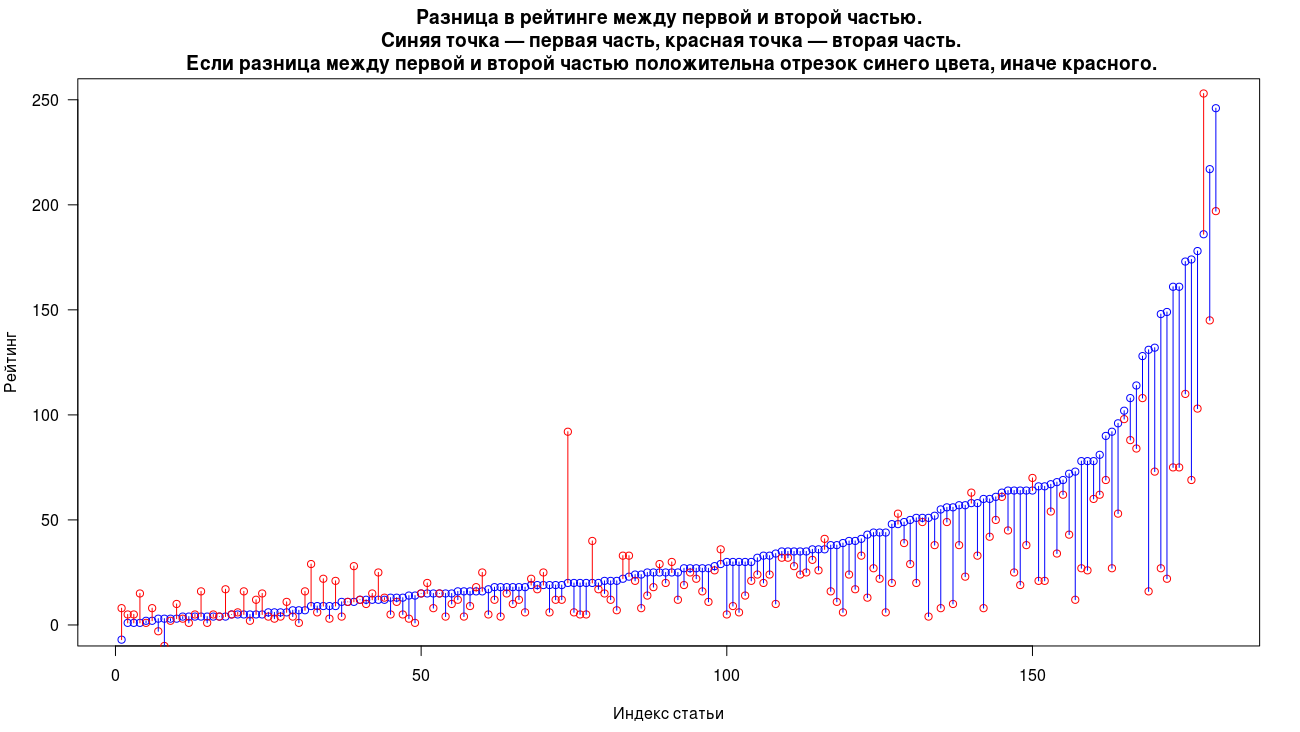
निम्नलिखित संकेतकों के लिए पहले और दूसरे भागों के बीच अंतर पर विचार करें: विचार, रेटिंग और पसंदीदा। नीचे दिए गए प्रत्येक ग्राफ में, एक नीले बिंदु का अर्थ है लेख का पहला भाग, और एक लाल बिंदु का दूसरा भाग है। एक ही लेख के दो भाग एक ही x-निर्देशांक पर प्रदर्शित होते हैं। यदि पहले और दूसरे भाग के बीच विचारों, रेटिंग या पसंदीदा के माप में अंतर सकारात्मक है, तो उनके बीच का खंड नीला है, और यदि यह नकारात्मक है, तो लाल। दृष्टिगत रूप से, जितनी अधिक नीली रेखाएँ हम देखते हैं, उतनी बार मापित मापदंडों के अनुसार, पहला भाग बेहतर होता है। पहले लेख के पैरामीटर को बढ़ाकर ग्राफ पर लेखों को क्रमबद्ध किया जाता है।
पहले ग्राफ पर हम दूसरे भाग के पहले भाग की स्पष्ट झलक देखते हैं, केवल 10% मामलों में दूसरा भाग पहले की तुलना में बेहतर है। लेकिन इनमें से अधिकांश मामलों में विचारों में एक नगण्य अंतर दिखाई देता है, केवल दो मामलों में सभी रिकॉर्डों के बीच हम पहले भाग के दूसरे भाग की एक महत्वपूर्ण प्रबलता देखते हैं। विचारों की औसत संख्या पहले भागों के लिए 20k और दूसरे के लिए 10k है।

सामान्य तौर पर, हम पसंदीदा में रिकॉर्ड के लिए एक समान तस्वीर देखते हैं, केवल 14% मामलों में दूसरा भाग पसंदीदा में अधिक रिकॉर्ड एकत्र करता है, केवल एक मामले में एक महत्वपूर्ण प्रबलता है। पसंदीदा का मध्य भाग पहले भाग के लिए 137 और दूसरे के लिए 82 है।
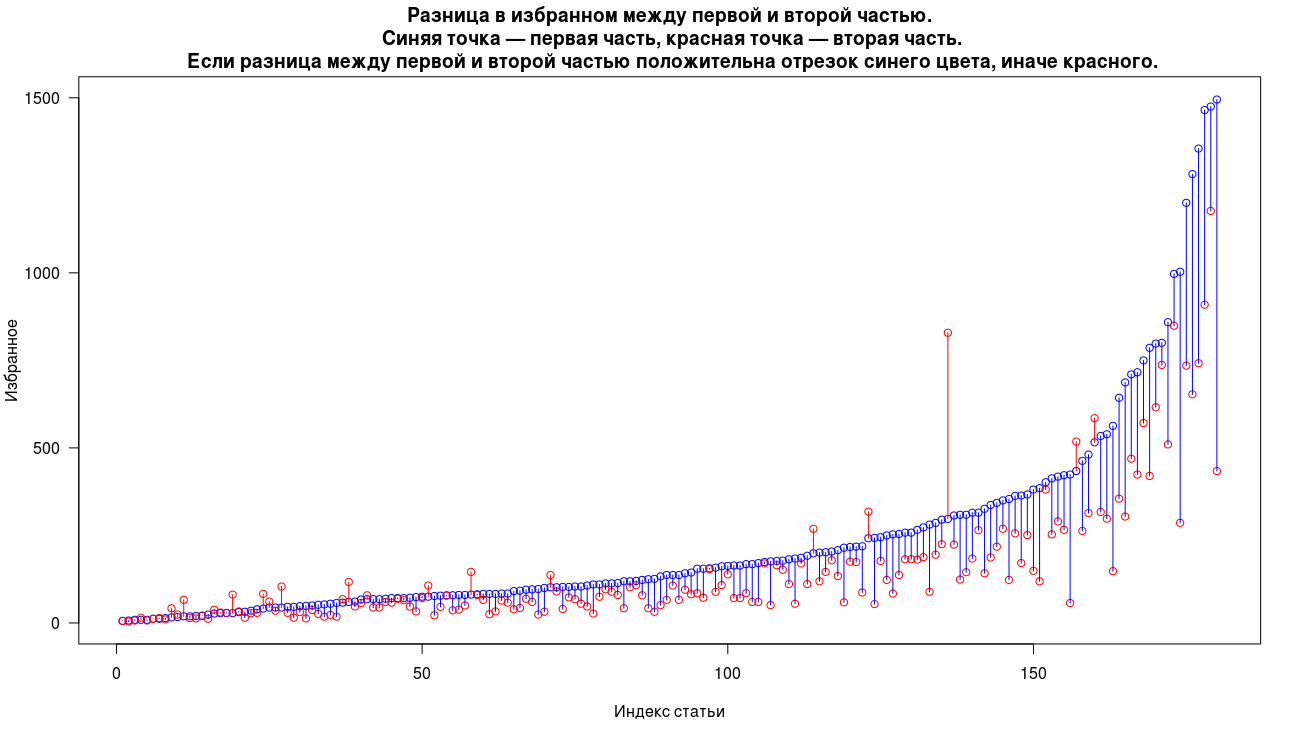
रेटिंग के मामले में, 22% मामलों में दूसरा भाग पहले अधिक बार हावी होता है। महत्वपूर्ण पूर्वाभास, जैसा कि विचारों के मामले में होता है, केवल दो मामलों में उत्पन्न होता है। पहले भाग के लिए मेडियन रेटिंग दूसरे के लिए 25 और 17।
(ग्राफ अंतर का उपयोग कर प्राप्त किया। स्क्रिप्ट)
अगर किसी को दिलचस्पी है, तो पहले भाग के दूसरे भाग की एक महत्वपूर्ण प्रधानता इन लेखों में यहाँ दी गई है:
जैसा कि मैंने Pacman लिखा है, और इसके बारे में क्या आया। भाग 1
जैसा कि मैंने Pacman लिखा है, और इसके बारे में क्या आया। भाग २
और लेख में प्रदर्शन का सबसे बड़ा अंतर:
भाग 1. Unboxing VisuMax - विज़न सुधार के लिए फेमटो लेजर
भाग 2. ऑप्टिक तंत्रिका के माध्यम से कितने मेगाबिट्स / एस पास किए जा सकते हैं और रेटिना का संकल्प क्या है? सिद्धांत की बिट
लेखों की श्रृंखला
लेखों की लंबी श्रृंखलाओं पर विचार करना और भी दिलचस्प है। उम्मीदवारों की कुल संख्या से, 5 या अधिक भागों के लेखों की श्रृंखला का चयन किया गया था - वे series_long.csv डेटासेट में पाए जा सकते हैं।
डेटा में निम्न प्रारूप है:

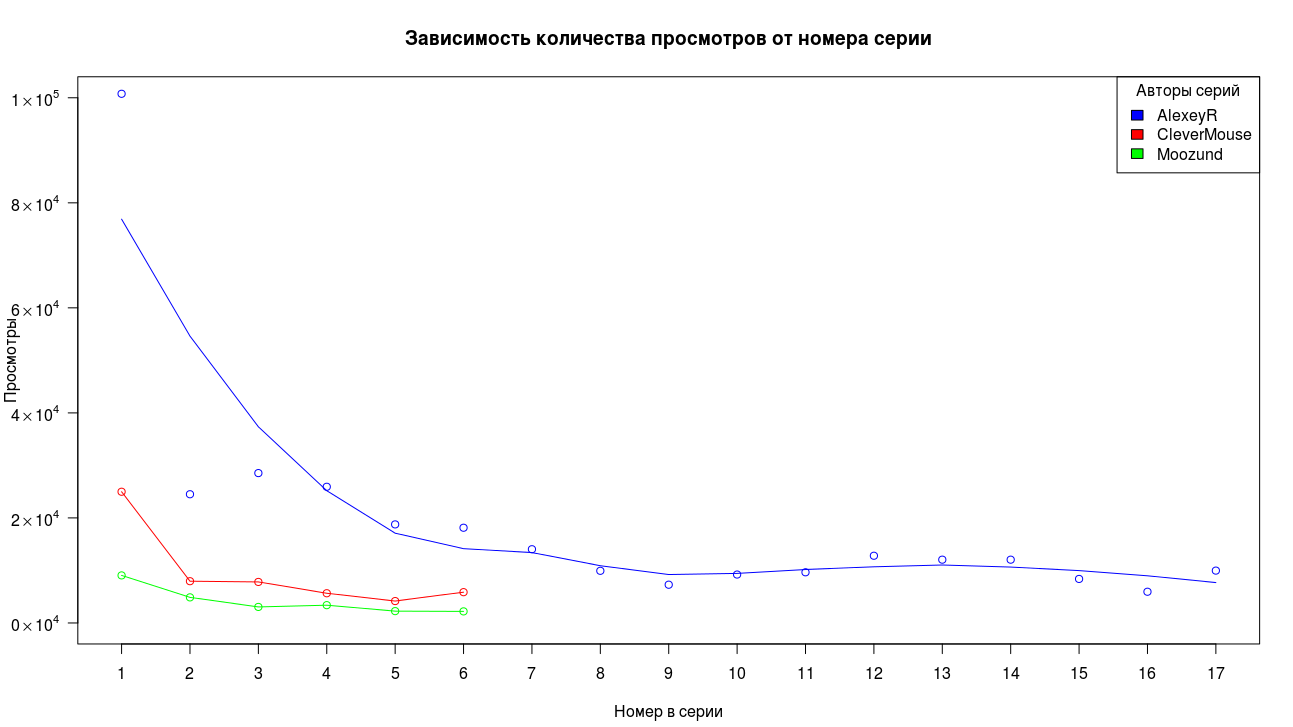
एकत्र किए गए डेटा एक बहुत ही सीमित नमूना आकार का प्रतिनिधित्व करते हैं, इसलिए असंदिग्ध निष्कर्ष निकालना मुश्किल है, लेकिन हम कम से कम परिवर्तनों की सामान्य प्रकृति का मूल्यांकन कर सकते हैं। हम एक उदाहरण के रूप में देते हैं और एकत्र अवधि के लिए लेखों की तीन सबसे लंबी श्रृंखलाओं को प्रेरित करते हैं।
सबसे पहले, हम देखते हैं कि पहले भाग ने अन्य भागों की तुलना में काफी अधिक विचार प्राप्त किए। दूसरे और तीसरे भाग के लिए, ड्रॉप में दो के क्रम का एक कारक होता है, फिर ड्रॉप धीमा हो जाता है और दृश्य स्थिर हो जाते हैं।
कुल मिलाकर, हम पसंदीदा में प्रविष्टियों के लिए एक समान तस्वीर देखते हैं, पहले बिंदु का उच्च मूल्य, एक तेज गिरावट और पूंछ का स्थिरीकरण।
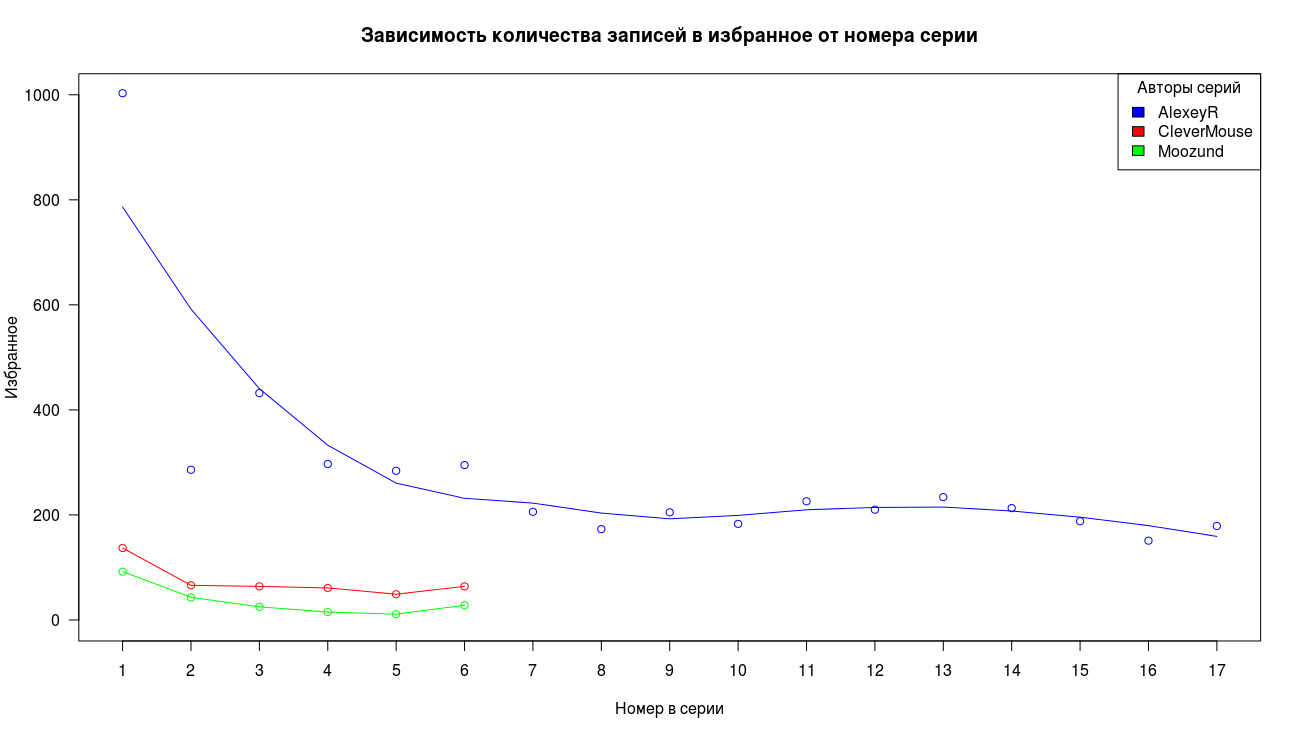
रेटिंग के साथ स्थिति ऊपर चर्चा की गई दो रेखांकन से भिन्न होती है, लेकिन सामान्य तौर पर तस्वीर का सामान्य दृश्य नीली श्रृंखला में कम प्रारंभिक परिणाम के अपवाद के साथ रहता है।
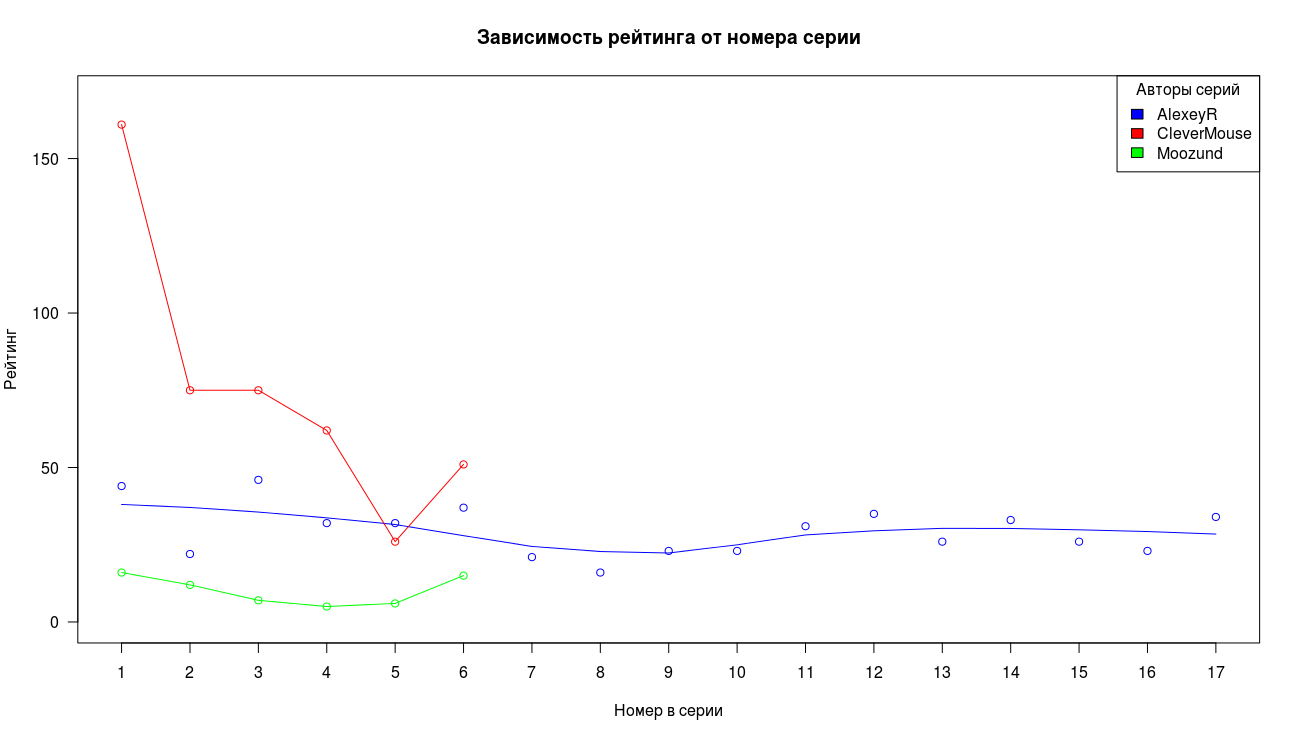
(स्क्रिप्ट का उपयोग कर प्राप्त long_plot.R )
क्या परिणाम इतना अप्रत्याशित है? वास्तव में नहीं। यह लगभग वही है जो शुरुआत में अपेक्षित था - जैसा कि जिपफ के क्लासिक वितरण ने पिछले लेख में लिखा था ( एक दिलचस्प और कम शुष्क भाषा में लिखा गया था)। यह अक्सर पाया जाता है और विभिन्न श्रृंखलाओं के विचारों की संख्या की गिनती करते समय इसे देखना आश्चर्यजनक नहीं है, उदाहरण के लिए, व्याख्यान नोट्स:

( स्टैनफोर्ड प्रोग्रामिंग मेथोडोलॉजी कोर्स के यूट्यूब चैनल से लिया गया डेटा)
हम एक समान चित्र देखते हैं, जब पहले बिंदु पर पैरामीटर के उच्च मूल्य पर, एक तेज गिरावट और पूंछ का "स्थिरीकरण" होता है। हब पर लेखों के बीच विचारों की निर्भरता और कई संसाधनों में अन्य संसाधनों पर सामग्री के विचारों की समानता को नोट करना मुश्किल नहीं है।
निष्कर्ष
यह अनुभवजन्य अवलोकन हमें कई दिलचस्प सवालों को उठाता है: क्या यह संभव है कि निम्नलिखित भागों में "रुचि" में गिरावट विभाजन के बहुत ढांचे में निहित है? उदाहरण के लिए, लेख n देखने के लिए, आपको n-1 लेख देखना होगा, जो पढ़ने के समय को काफी बढ़ाता है और दर्शकों को कम करता है। क्या हब पर लेखों की कोई विशिष्टता एक भूमिका निभाती है, या क्या अन्य संसाधनों पर सभी समान लेखों के साथ ऐसा होता है?
बेशक, किसी लेख को कई भागों में विभाजित करना है या नहीं, यह तय करने के लिए विशेष रूप से समान अनुभवजन्य टिप्पणियों का पालन करना असंभव है, लेकिन यह अवलोकन आपको वर्तमान संकेतकों के आधार पर, निम्न भागों के लिए कुछ अपेक्षा मानक (मुख्य मापदंडों में) निर्धारित करने की अनुमति देता है।
आगे पढ़ रहे हैं
यदि डेटा विश्लेषण का विषय दिलचस्प लगा, तो अध्ययन के लिए उपयोगी सामग्री
- Udacity
- कैलटेक - डेटा से सीखना
- कौरसेरा - डाटा साइंस ट्रैक
- यदि आप सेंट पीटर्सबर्ग में रहते हैं, तो आप DMLabs में पाठ्यक्रम ले सकते हैं
- यदि आप मास्को में रहते हैं, तो आपने शायद पहले ही SHAD के बारे में सुना होगा