
The history of machine learning began in the middle of the last century. At that time, this technology was more an area for scientific research and experiments, and powerful computers gave an impetus to the practical application of ML.
Today, machine learning is an undeniable trend in the IT market. More and more companies from various industries are creating Data science divisions in order to use machine learning to find new opportunities in the accumulated data for growth and improving business efficiency. However, while these initiatives do not give the proper return. According to statistics, 8 out of 10 confirmed cases do not go into commercial operation.
Most likely, most of you have heard the joke "the most effective way to make machine learning more productive is PowerPoint slides." Unfortunately, this is not a joke. Often, the whole process looks like this: a business transfers data and a business case that have been downloaded from business systems. Data Scientists are developing a machine learning model in the Jupiter Notebook, a screenshot of the graphs is placed on a PowerPoint slide, and sent to the business customer. Is it possible to use the resulting slide in making management decisions? Most likely not, since the forecast data quickly become outdated, and the situation in the business during this time can seriously change.
Trying to overcome all obstacles and put machine learning on the flow, most companies invest in the infrastructure for collecting, storing and processing large amounts of data - Data Lake. Of course, this is a necessary step. But what does this change from a business perspective? Is it possible to make decisions based on machine learning? No, because there is a gap between Data Lake and business. Obviously, why 86% of the companies surveyed believe that next-generation business applications should be equipped with machine learning.
We at SAP decided to write a series of articles on how to overcome existing difficulties with the new SAP Data Intelligence platform and put such a powerful tool as machine learning at the service of business. And, if you are interested in this topic, read on :)
First, I’ll tell you about the first and very important stage in the development of any business case “Data Search and Preparation”. In subsequent articles, we will consider the stages “Development and training of models”, “Integration with SAP and non-SAP on-premise and cloud data sources in detail”, “Creating services for using models”, “Transferring business cases to productive”, “Monitoring and the operation of business cases ”and much more.
Development of a business case based on machine learning. Search and preparation of data.
Let's look at the process of creating a business case (Figure 1).
Initially, an idea is usually formulated by a business. Often, he does it willingly, as he has a definite goal of digitalizing functions within the digital transformation of the entire enterprise. For collecting, evaluating and prioritizing ideas, you can use, for example, SAP Innovation Management.
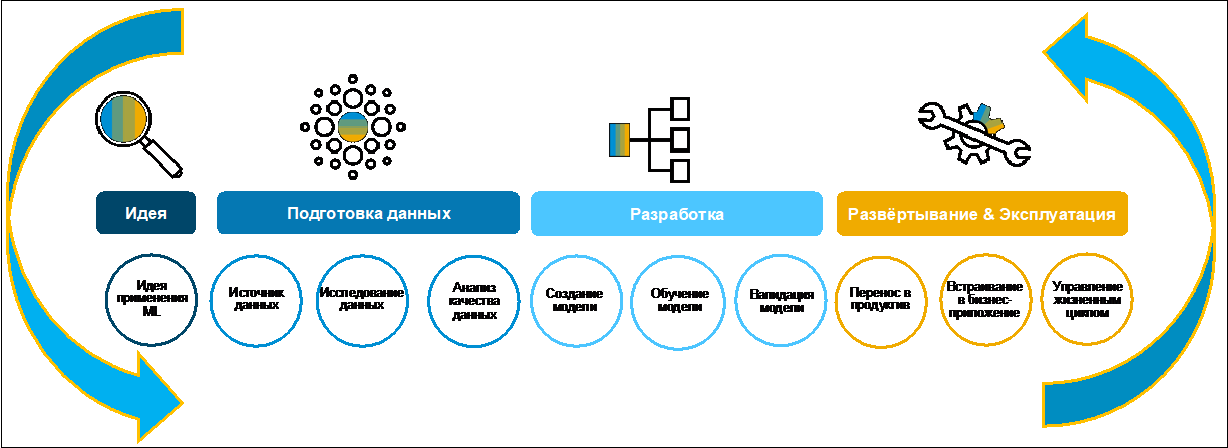
Picture 1.
At the first stage of data search and preparation, it is necessary to understand whether they exist at all for the development of a business case, where they are stored, in what formats and what quality they are. The modern typical landscape includes many heterogeneous systems. Data can be duplicated in different applications. Finding the right information can take a lot of time. For this purpose, in SAP Data intelligence, this task has been significantly simplified using the Metadata Catalog. Let's look at what it is and how to use it.
Metadata catalog
To use the metadata catalog, you must connect the source system to Data Intelligence. Data sources for Data Intelligence can be on-premise systems SAP ERP, BW, Marketing ... and non-SAP MES, Oracle, MS SQL, DB2, Hadoop and many others, as well as cloud services Amazon, Azzure, Google SCP. To connect to data sources, you need information about the location of the systems and technical users created in these systems specifically for integration with SAP Data Intelligence. Figure 2 shows an example of a customized data landscape in SAP Data Intelligence.

Figure 2
Once configured in the SAP Data Intelligence Metadata Catalog, it is possible to see information that is stored on connected systems. Figure 3 shows the list of files that are located in the DAT263 folder in Hadoop connected to SAP Data Intelligence.

Figure 3
If you find the data that is necessary to implement a business case, let's add data objects to the Catalog using the publish function. I will use the autos_history.csv file, which contains used car sales statistics. In Figure 4, you see how you can publish a data object and its metadata to the Catalog for quick access in the future.

Figure 4
You can customize the directory structure and hierarchy levels to suit your business case requirements. For example, in my Habr_demo folder, all metadata about the objects that I need for this article will be collected.
The generated Metadata Catalog is a quick access to business case data. I will conduct profiling and analysis of their quality on the objects of my folder in the SAP Data Intelligence Metadata Catalog. The initial screen of the metadata catalog is shown in Fig. 5.
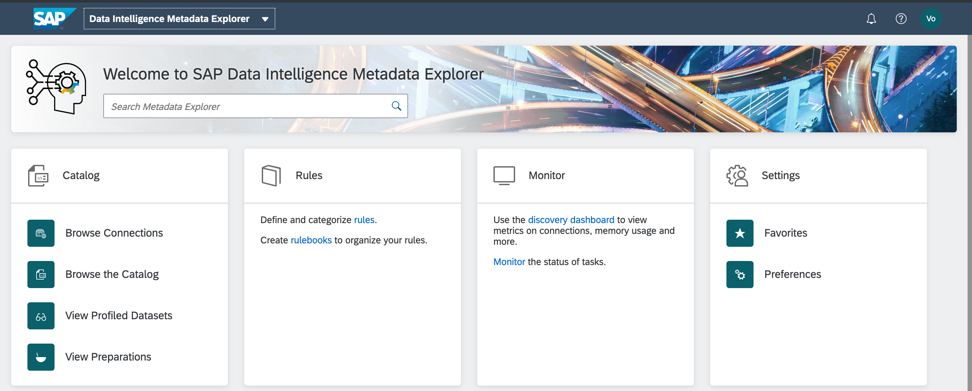
Figure 5
And here is the same data object that I published in the Habr_demo folder (Fig. 6)
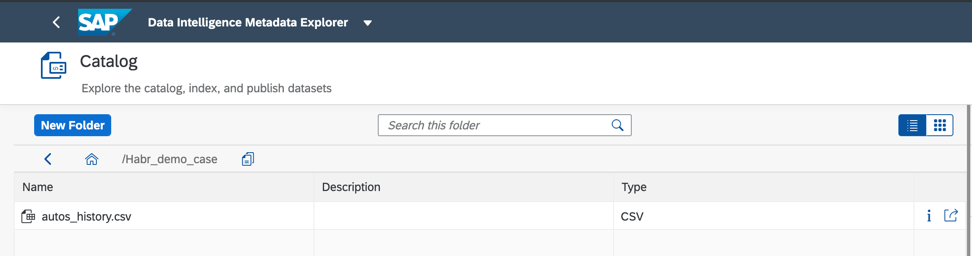
Figure 6
Additionally, to improve and speed up the search, we can assign tags or labels in the catalog of data objects, as shown in Fig. 7.
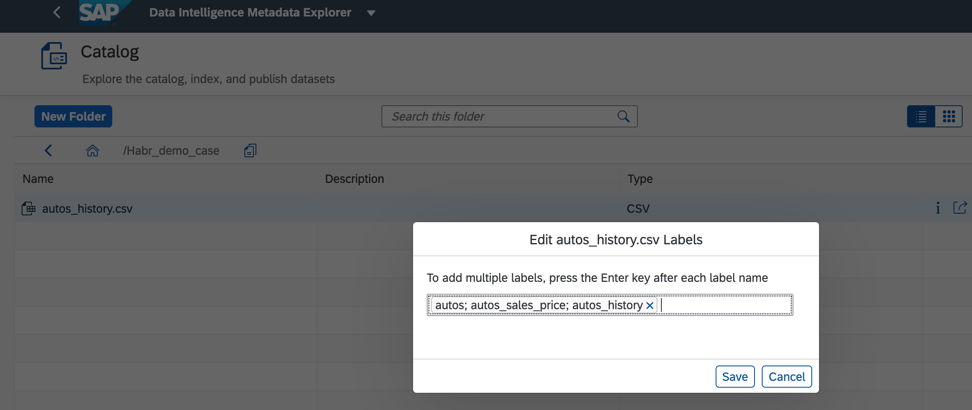
Figure 7
The metadata catalog allows you to search for objects by their names, fields, as well as labels. A single data object may have multiple labels. This is convenient if several developers work with it, everyone can assign a label to their business case, and quickly find everything you need from it. Also, tags can highlight personal and confidential data, access to which should be strictly limited.
In the considered data set, a search by label and by field name gives a quick result (Fig. 8). Agree, it is very convenient!
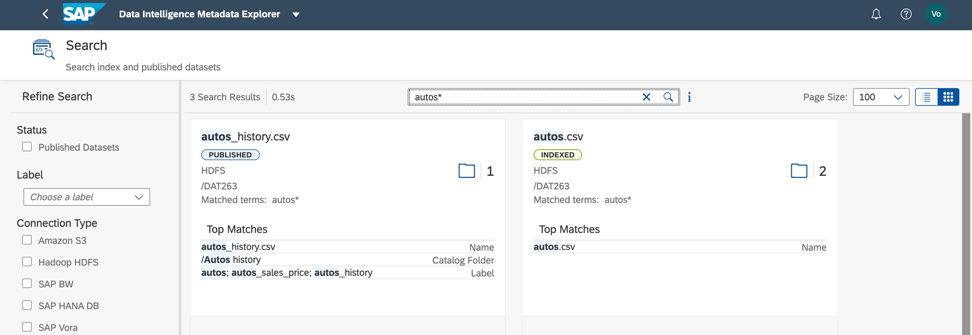
Figure 8
Next we need to understand how our file is filled. To do this, we can profile the data. We also start the process from the metadata catalog and the context menu for data objects (Fig. 9).

Figure 9
During profiling, the metadata catalog will read the contents of the file, analyze its structure and filling. The result can be found in Fact Sheet (Fig. 10).
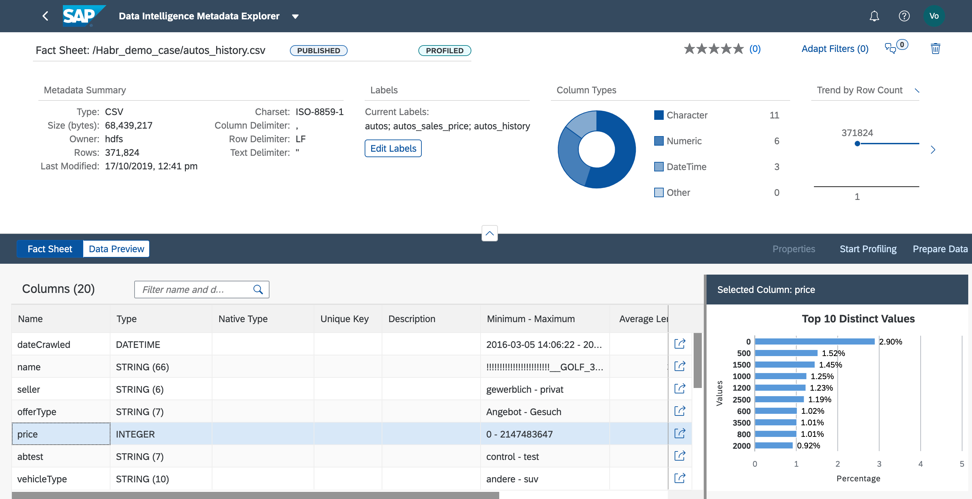
Figure 10
In Fact Sheet we see the file structure and information on filling in the fields.
1. In the selected file, as a result of profiling, we revealed: the seller field has one value I in all lines. This means that we can remove this field from the data set so as not to use machine learning when building the model, since it will not affect the forecast result (Fig. 11).

Figure 11.
2. Analyzing the price column, we understand that almost 3% of the data we have contains zero price. In order to use this file in our business case, we must fill in the price with either the actual values or the average for this product, or we must delete the lines with zero price from the file (Fig. 12).
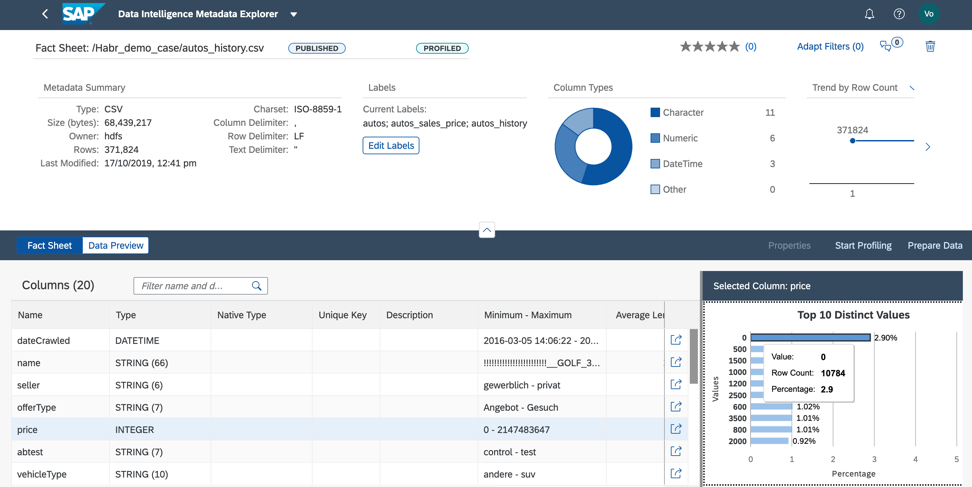
Figure 12.
We can do data preprocessing in two ways: in the Metadata Catalog or directly in the Jupiter Notebook. The choice of tool depends on who is responsible for the preprocessing of data for the business case. If an analyst, then I recommend using the visual data preparation interface, which is available in the Metadata Catalog. If a data scientist is involved in the preparation of the data, then definitely the choice should be in favor of the Jupiter Notebook, which is also integrated into Data Intelligence.
3. The value of the model field is well distributed, which will allow us to qualitatively train the model, as in Figure 13.
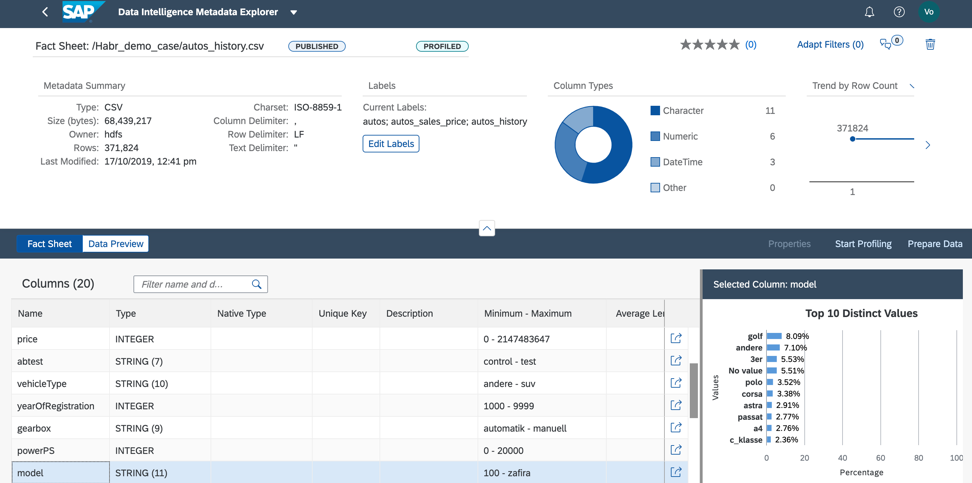
Figure 13.
Now we understand what data objects are required to implement a business case, what data objects are filled with, what preprocessing we must do to use this data for implementation, training and testing of the model. But before you begin preprocessing, you need to check the quality of the data. To do this, business rules are available in the Metadata Catalog. I note right away that at the moment the functionality of business rules has a number of serious limitations. Therefore, I recommend more or less complicated data preprocessing in the Jupiter Notebook, which is integrated into SAP Data Intelligence.
So, let's go back to our data set and verify compliance with the minimum and maximum thresholds in the price field, so we can roughly estimate whether the data have anomalies or incorrect values. As you already understood, business rules are also configured in the Metadata Catalog, as in Fig. 14a, c. The association of rules and data is configured in the rulebook (Rulebook). This allows you to use the same rules to validate different data.
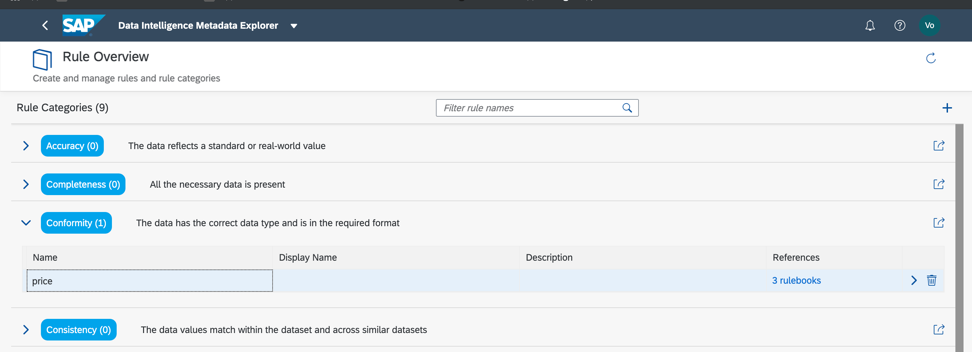
Figure 14 a.
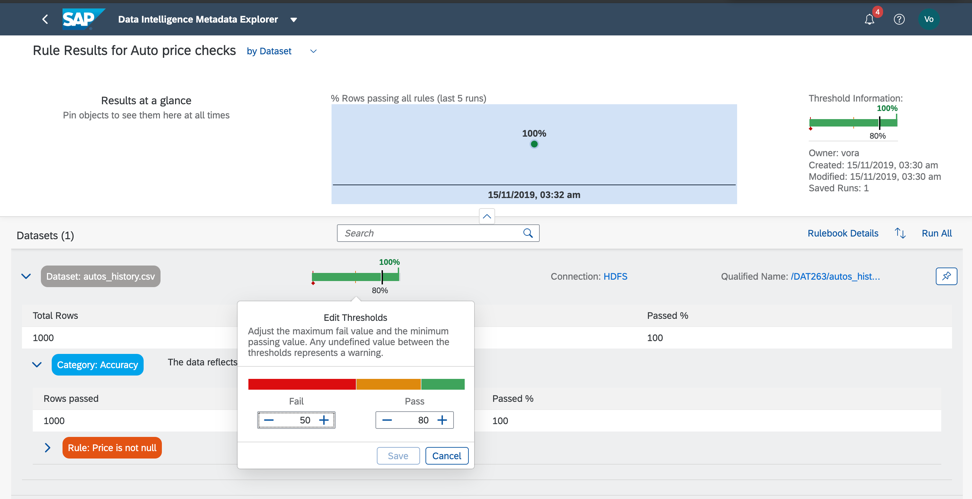
Figure 14 c.
So, as we see, our data is 100% correct.
But this does not always happen. Data can be considered correct if 75% of the records meet the conditions specified in the rules.
It is possible to improve the quality of data, and above all, this is done in accounting systems. To do this, companies organize a data management process. Another possible reason is incorrectly defined data quality criteria.
Summarizing, I want to say about the advantages and disadvantages of the Metadata Catalog.
In my opinion, it has 3 main advantages:
- Simplify data access.
- Speeding up data retrieval.
- Convenient and intuitive interface, which is intended not only for advanced in IT or Data Science specialists, but also for the business involved in the implementation and further support of the business case.
And, of course, about the flaws. They are obvious. Currently, the functionality of the Metadata Catalog in SAP Data Intelligence is at a basic level. It may be sufficient to start using, but the functionality does not exactly cover all the requirements for a data management solution.
And this is a consequence of the novelty and complexity of SAP Data Intelligence. SAP invests a lot of resources to improve this solution. And this inspires confidence that in the near future the Metadata Catalog will turn into a powerful tool for data management. There will be an opportunity to create complex business rules without programming. It will also be possible to integrate the SAP Information Steward and the SAP Data Hub for the purpose of fully functional coverage of the topic of data management.
In the next article, we will talk about the “Development and training of a model in SAP Data Intelligence” phase. All the most interesting ahead!
Posted by Elena Ganchenko, SAP CIS Expert