Immediately a small disclaimer: we tested the product in terms of its use in a public service. Perhaps some functions, interesting and important for private use, were left overs.

This is ActiveScale P100 in April 2019 before installation in the OST data center.
Now our S3 runs on Cloudian HyperStore 7.1.5. This version provides 98% compatibility with Amazon APIs. The current solution has everything necessary for us as a service provider and our customers, so we looked for no less in the alternatives.
This time, Western Digital ActiveScale software and hardware solution fell into our hands. The vendor positions it as a solution for organizing an S3 cluster.
This is how it looks:

ActiveScale P100 installed in one of the halls of the OST data center.
The top three units are control nodes. The following six units are nodes for storing data. Each of the six nodes contains 12 disks of 10 TB each. Total 720 Tb of "raw" capacity. The complex also includes 2 network devices. For each node - 2 links of 10G. In total, this solution takes 11 units in the rack.
We ran ActiveScale through load tests: with a script, we generated a different number of files of different sizes, tried to upload them in single-threaded and multi-threaded modes, and recorded the execution time of commands for uploading and deleting files. This test was artificial: it was carried out from a computer with an SSD-drive, a large amount of memory and a processor with a frequency of 3.2 GHz, with a limited channel width of 100 Mb / s. Nevertheless, we have the results of a similar test for the current solution, and the results obtained were more than within our expectations.
| Test
| Object Size
| Number of objects
| Number of threads
| average speed
| Loading time
| Removal Time *
|
| one
| 10 Kb
| 100,000
| one
| 104 kb / s
| 2 h 40 m
| 6 m 58 s
|
| 2
| 10 Kb
| 100,000
| twenty
| 11 MB / s
| 35 m 4 s
| 11 m 38 s
|
| 3
| 1 Mb
| 100,000
| one
| 5 MB / s
| 5 h 55 m
| 7 m 16 s
|
| 4
| 1 Mb
| 100,000
| twenty
| 11 MB / s
| 2 h 31 min
| 7 m 26 s
|
| 5
| 10 GB
| one
| one
| 10 MB / s
| 16 m 5 s
| 3 s
|
| 6
| 10 GB
| one
| twenty
| 10 MB / s
| 16 m 2 s
| 3 s
|
* When deleting an object is only marked for deletion. The removal itself occurs once a day. When the cluster is almost full, this can complicate capacity management, since there is no up-to-date information about the resources used.
Amazon S3 compatibility was tested in standard ways. Here is one of the tests I used.
At the time of testing, we had the most basic documentation, so we dealt with the device of this "black box" independently - through the admin web interface, API and physical access.
What was found inside
Admin interface On the main page, summary information on cluster sizes and working metrics, statistics on objects, users, buckets, storage policies.
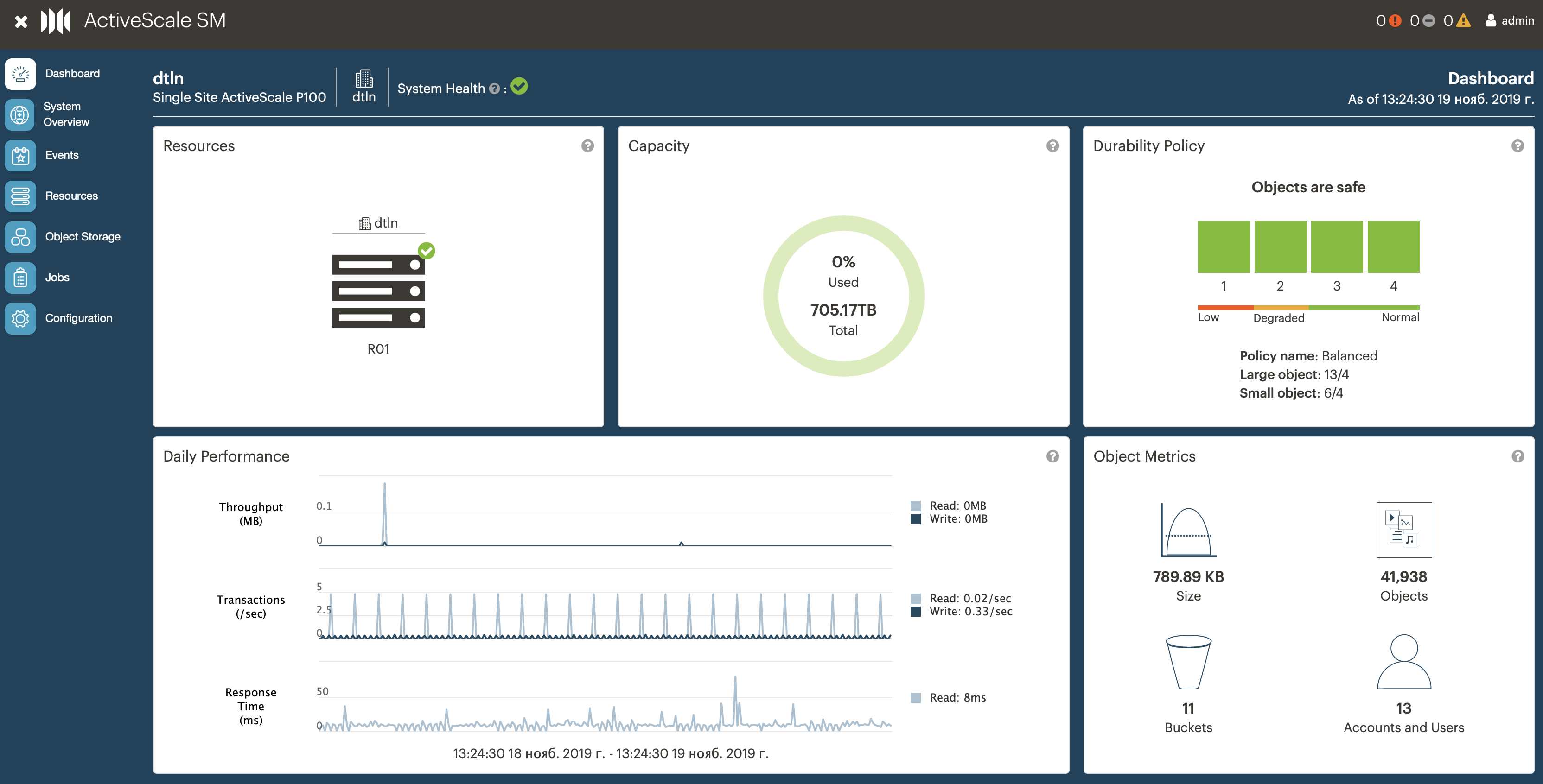
User interface. In the S3 service, it is needed so that the administrator on the client side can add / remove users, generate access keys for them, quote users, etc. The P100 does not have it, but after our feedback, the vendor plans to implement it.
User / role management. To organize a public service, we need the ability to create users with different access rights. P100 has significant limitations in this regard:
- You can create only one system user, that is, a cluster administrator. More - only through integration with Active Directory.
- Users cannot be grouped and assigned an administrator. Actually, this makes it impossible for us to provide a public service.
- the user cannot be permanently deleted, so if the new user is with the same login, you will have to be creative.
- setting quotas for users (volume, number of transactions, etc.) is possible only through the CLI.
Billing. The P100 is out of the box, and this is the biggest drawback for us as a service provider. We have a commercial product, and we need to somehow bill customers. P100 has statistics logs that can be removed every hour through the admin panel. Theoretically, you can parse them, pull out the necessary data and make a calculation on them. But these logs are stored only 30 days. What to do in situations where in the month of 31 days or the client asks to double-check the account for the previous months is not clear.
Setting your own rules for storing objects. The P100 has already come to us with the following settings: files smaller than the chunk (20 Kb) are stored in erasure code (EC) 6 + 2 mode. Files larger than chunk are stored in EC 13 + 4 mode. The P100 itself determines the file size and selects the appropriate mode.
On the one hand, the P100 has more options. On the other hand, all settings by storage rules for the replication factor and erasure code are possible only at the stage of cluster deployment. Later, during operation, it is no longer possible to add new data storage rules or modify existing ones. When expanding the cluster, this must be done so that the efficiency and reliability of storage is optimal.
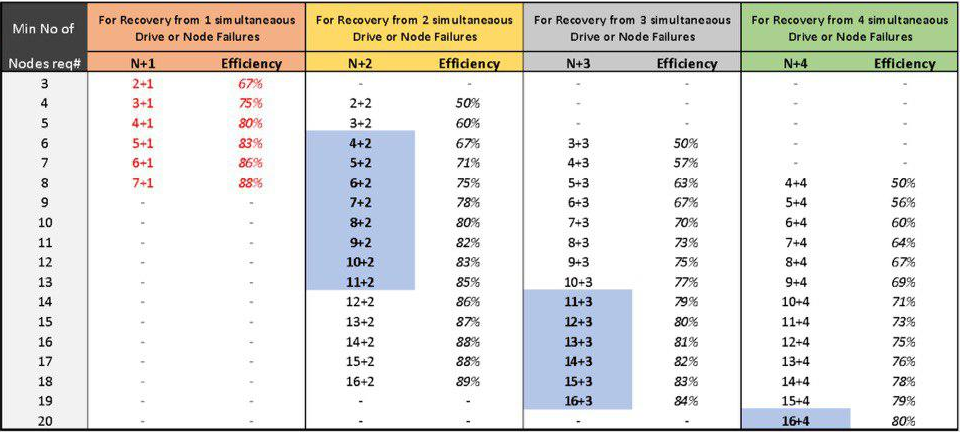
Erasure Code storage performance table.
Native CLI \ AdminAPI. To manage the cluster, the P100 has a CLI, but it is written and tested only for Ubuntu (we use Red Hat). It does not give significant advantages over interaction through curl requests (put, get, post), but there are some features for managing the cluster.
Support for the basic AWS S3 API and AWS CLI. This is just an indicator of compatibility with the Amazon API. Simply put, is it possible to use commands for Amazon S3 in this solution. According to experience, on average, this indicator varies somewhere in the range of 50–70%.
P100 got 58% according to the test results. It was not possible to do compatibility tests on assigning access rights to individual objects, since in the P100 solution you can assign general access only to a bucket, and not to a separate object. Also there is no IAM (Identity and Access Management). As a result, compatibility is closer to 50%.

From the test results.
OS management. According to the specification, ActiveScale OS 5.x appears. According to the logs and folders accessible through the web interface, I found out that it is most likely based on a Debian distribution. During testing, it was not possible to find ways for self-managing updates, how to install critical security updates, your monitoring agents, and so on. Definitely need to contact P100 technical support with the departure of a specially trained person.
The number of bucket per user. In such services, the user can usually create up to 100 buckets, a kind of “folder” for storing files. In the general case, this is enough, but practice shows that there are not many buckets. In the P100, 100 bucket is the maximum. In our current solution, the user can create 1000 buckets.
Setting access rights to bucket and objects. In P100, you can give access to a specific bucket, but not to a specific object. The latter is often used by users because it allows you to set limits on the number of downloads and the time when it can be downloaded.
Cluster / user / bucket statistics. We need this information in order to track cluster occupancy and not miss the moment when we get to the ceiling by resources.
In the interface, you can see almost real-time statistics on users and buckets (information is updated once an hour).
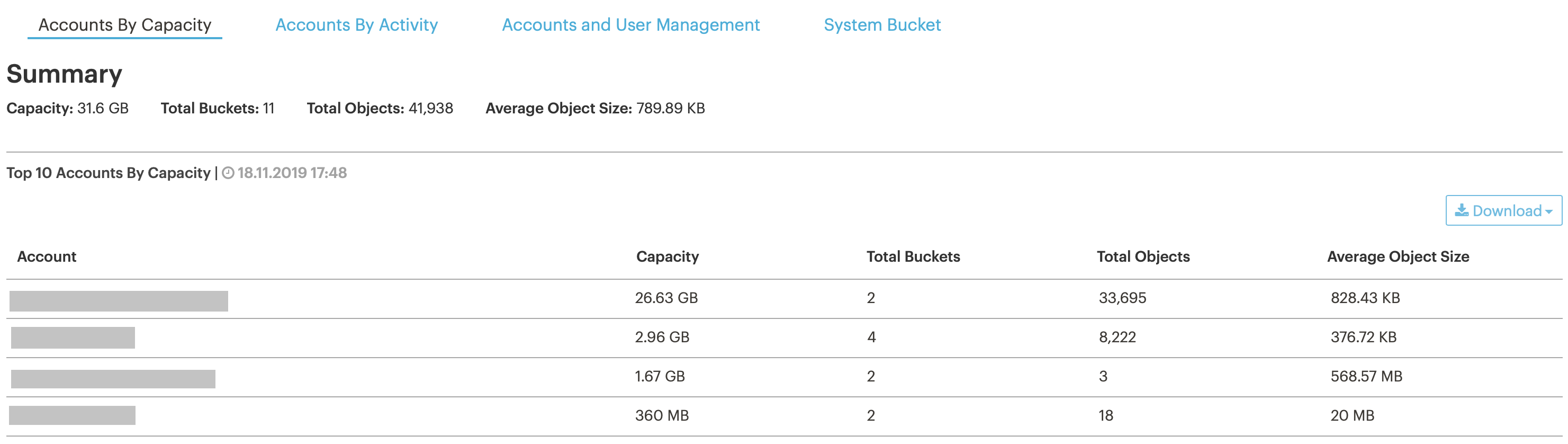
It can be downloaded through a special system bucket, but in the downloaded form instead of email or user names there will be a UUID, so you need to somehow compare what kind of user is hiding behind specific UUIDs. This is not a problem if there are 10 users, but if more?
Self-diagnosis. The P100 can interrogate via SNMP the entire iron part of the cluster and display it on a dashboard. For example, you can see the fullness and temperature of disks, memory usage, etc.
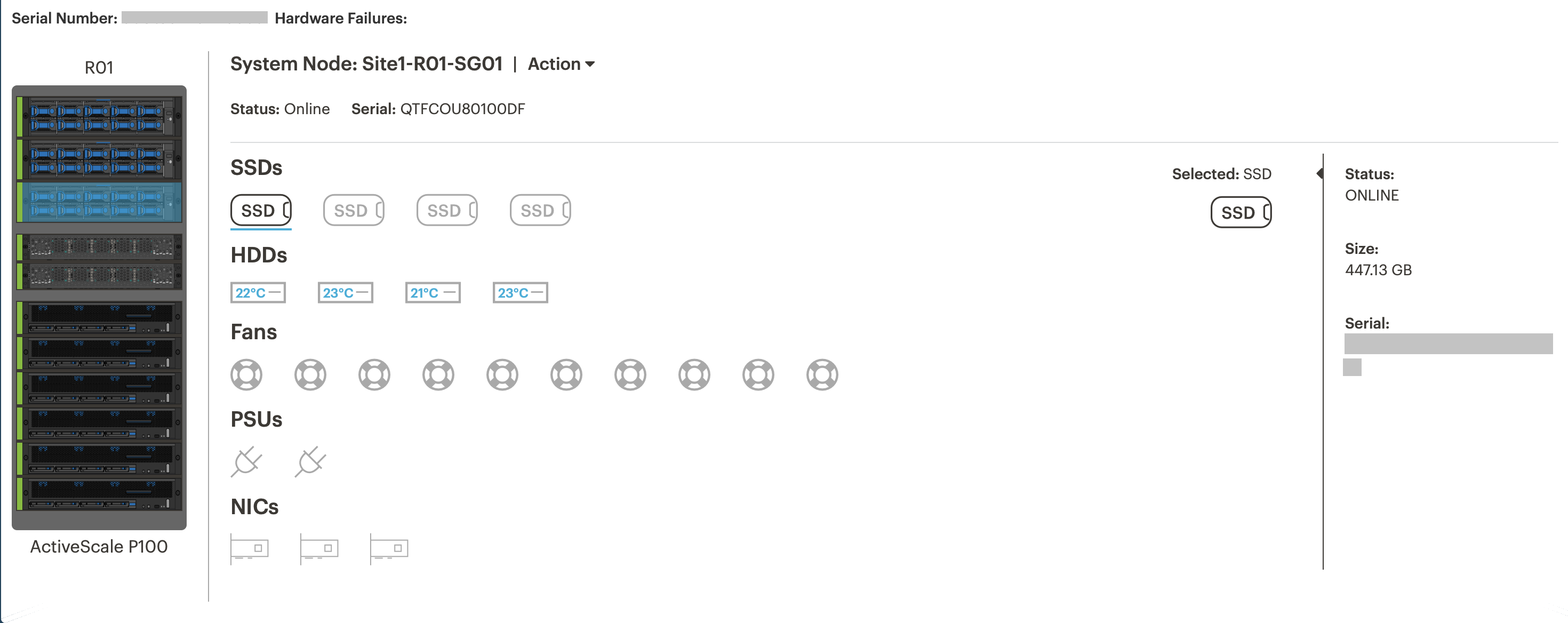
Information about the state of the system node.
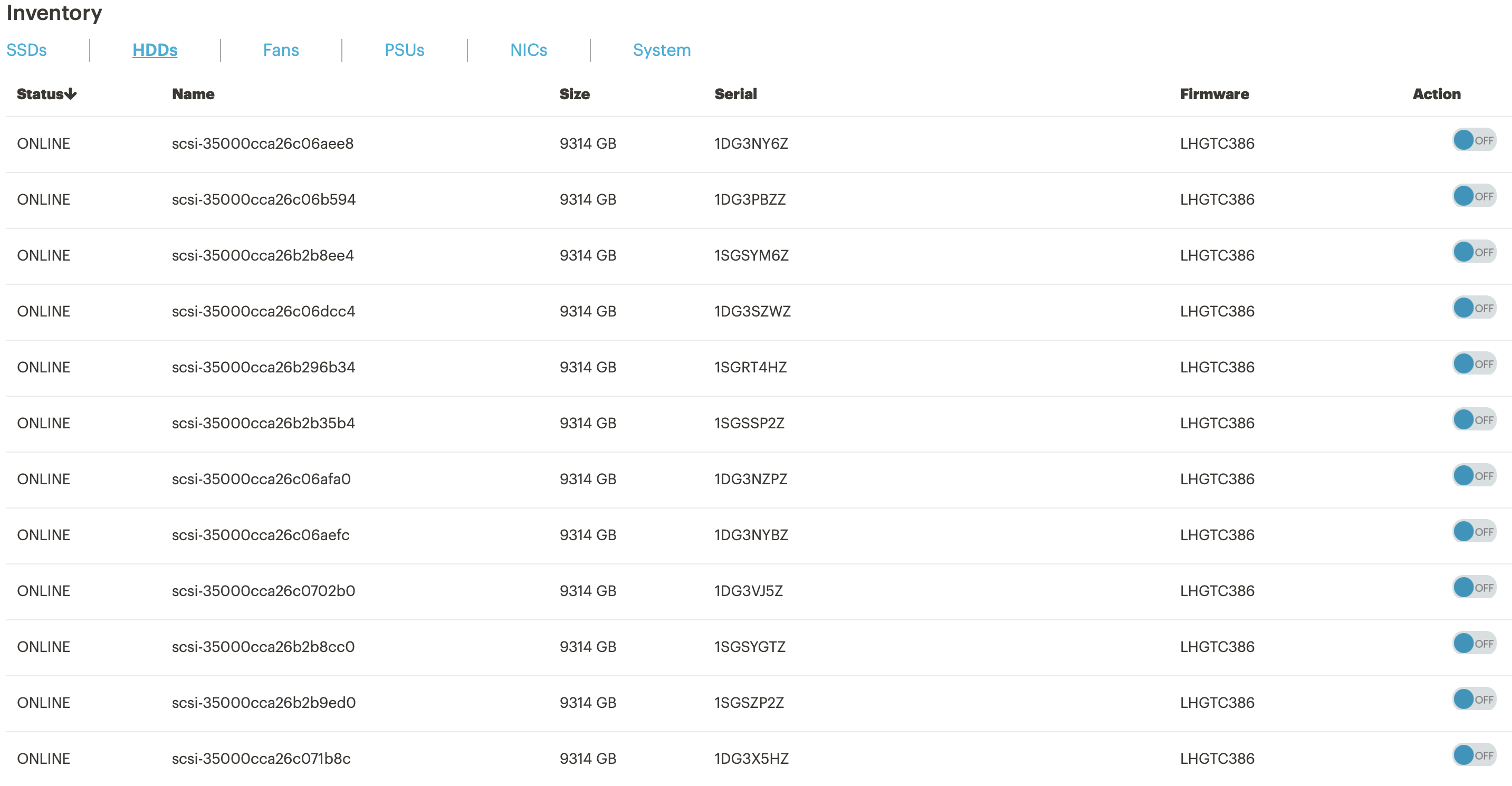
Information about the status of the drives. When a drive fails, you can turn on the backlight to quickly find and replace.
Parameters for loading the CPU and memory in the cluster.
Logging user actions. It is not there, which means understanding situations “who deleted the file and deleted” will not be easy.
Support SSE / SSE-C. P100 supports encryption, but with limitations: you need to request a separate license key, and this is extra money.
Load balancer. It is built-in, presumably worth HAProxy. You need to configure it to a minimum: just specify the incoming and outgoing IP addresses.
Automation of input / output processes of nodes or disks on nodes. It helps when a node breaks in a cluster and needs to be decommissioned. Now for such situations we have a ready-made solution. I did not find such a mechanism in the P100, you can only disable a separate node through the admin web interface. Most likely, you will have to invite the engineer from the vendor.
S3 Gate Appliance. This software solution allows you to deploy ftp / nfs / samba-gate on the client side and drop the files that should be in S3 there. A convenient thing if the end user does not know how to use S3. Unfortunately, the P100 does not have this on board.
Working application ports. In the P100, only the standard ports for S3 are available - 80, 443.
User documentation. There is only API documentation.
Administrative documentation. Provided by the vendor upon request.
Not tested, but declared by the vendor
Multiple endpoints. We arrived with a ready installation, where only one endpoint per cluster was already configured. Change failed.
Geo-reservation. This option makes it possible to replicate data at three sites and switch customers to backup sites. We had only one cluster, so it was not possible to test.
Integration with AD. Declared, but we do not use AD in relation to S3, so we did not test.
conclusions
In general, the WD ActiveScale P100 left a positive impression: it works “out of the box”, quickly and at the same time it is very acceptable. Nevertheless, this is a private solution that cannot yet be used to build a public S3 service. Here is the main thing that we did not have enough:
- there is no way to create user groups and set an administrator for them;
- no graphical user interface;
- no billing;
- inclusion of additional functions only through an appeal to the vendor;
- the inability to keep different storage policies and assign them to different user groups within the same cluster, depending on current tasks.
According to the test results, the vendor accepted all the wishes. Perhaps in the near future one of them will be realized.