
Designing streaming analytics and streaming data processing systems has its own nuances, its own problems, and its own technological stack. We talked about this in the next open lesson , which took place on the eve of the launch of the Data Engineer course.
At the webinar discussed:
- when streaming processing is needed;
- what elements are in SPOD, what tools can we use to implement these elements;
- how to build your own clickstream analysis system.
Lecturer - Egor Mateshuk , Senior Data Engineer at MaximaTelecom.
When is streaming needed? Stream vs Batch
First of all, we need to figure out when we need streaming, and when batch processing. Let us explain the strengths and weaknesses of these approaches.
So, the disadvantages of batch processing:
- data is delivered with a delay. Since we have a certain period of calculations, then for this period we always lag behind real time. And the more iteration, the more we lag behind. Thus, we get a time delay, which in some cases is critical;
- peak load on iron is created. If we calculate a lot in batch mode, at the end of the period (day, week, month) we have a peak load, because you need to calculate a lot of things. What does this lead to? First, we begin to rest against limits, which, as you know, are not infinite. As a result, the system periodically runs to the limit, which often ends in failures. Secondly, since all these jobs start at the same time, they compete and are calculated quite slowly, that is, you can’t count on a quick result.
But batch processing has its advantages:
- high efficiency. We will not go deeper, since efficiency is associated with compression, with frameworks, and with the use of column formats, etc. The fact is that batch processing, if you take the number of processed records per unit time, will be more efficient;
- ease of development and support. You can process any part of the data by testing and recounting as necessary.
Advantages of streaming data processing (streaming):
- result in real time. We do not wait for the end of any periods: as soon as the data (even a very small amount) comes to us, we can immediately process it and pass it on. That is, the result, by definition, tends to real time;
- uniform load on iron. It is clear that there are daily cycles, etc., however, the load is still distributed throughout the day and it turns out more uniform and predictable.
The main disadvantage of streaming processing:
- complexity of development and support. First, testing, managing, and retrieving data is a bit harder when compared to batch. The second difficulty (in fact, this is the most basic problem) is associated with rollbacks. If jobs didn’t work, and there was a failure, it is very difficult to capture exactly the moment where everything broke. And solving the problem will require you more effort and resources than batch processing.
So, if you are thinking about whether you need streams , answer the following questions for yourself:
- Do you really need real-time?
- Are there many streaming sources?
- Is losing one record critical?
Let's look at two examples :
Example 1. Stock analytics for retail:
- display of goods does not change in real time;
- data is most often delivered in batch mode;
- loss of information is critical.
In this example, it is better to use batch.
Example 2. Analytics for a web portal:
- analytics speed determines the response time to a problem;
- data comes in real time;
- Losses of a small amount of user activity information are acceptable.
Imagine that analytics reflects how visitors to a web portal feel using your product. For example, you rolled out a new release and you need to understand within 10-30 minutes whether everything is in order, if any custom features have broken. Let's say the text from the “Order” button is gone - analytics will allow you to quickly respond to a sharp drop in the number of orders, and you will immediately understand that you need to roll back.
Thus, in the second example, it is better to use streams.
SPOD elements
Data processing engineers capture, move, deliver, convert and store this very data (yes, data storage is also an active process!).
Therefore, to build a streaming data processing system (SPOD), we will need the following elements:
- data loader (means of delivering data to the storage);
- data exchange bus (not always needed, but there is no way to stream it, because you need a system through which you will exchange data in real time);
- data storage (as without it);
- ETL engine (necessary to do various filtering, sorting and other operations);
- BI (to display results);
- orchestrator (links the whole process together, organizing multi-stage data processing).
In our case, we will consider the simplest situation and focus only on the first three elements.
Data Stream Processing Tools
We have several “candidates” for the role of data loader :
- Apache flume
- Apache nifi
- Streamset
Apache flume
The first one we'll talk about is Apache Flume , a tool for transporting data between different sources and repositories.

Pros:
- there is almost everywhere
- long used
- flexible and extensible enough
Minuses:
- inconvenient configuration
- difficult to monitor
As for its configuration, it looks something like this:

Above, we create one simple channel that sits on the port, takes data from there and simply logs it. In principle, to describe one process, this is still normal, but when you have dozens of such processes, the configuration file turns into hell. Someone adds some visual configurators, but why bother if there are tools that make it out of the box? For example, the same NiFi and StreamSets.
Apache nifi
In fact, it performs the same role as Flume, but with a visual interface, which is a big plus, especially when there are a lot of processes.
A couple of facts about NiFi
- originally developed at the NSA;
- Hortonworks is now supported and developed;
- part of HDF from Hortonworks;
- has a special version of MiNiFi for collecting data from devices.
The system looks something like this:
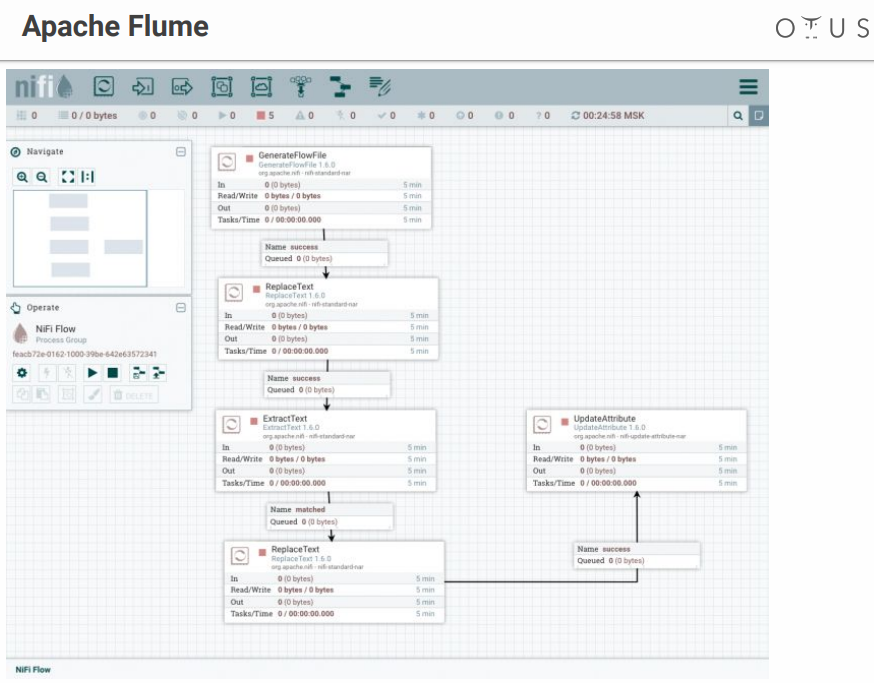
We have a field for creativity and stages of data processing that we throw there. There are many connectors to all possible systems, etc.
Streamset
It is also a data flow control system with a visual interface. It was developed by people from Cloudera, it is easily installed as Parcel on CDH, it has a special version of SDC Edge for collecting data from devices.
Consists of two components:
- SDC - a system that performs direct data processing (free);
- StreamSets Control Hub - a control center for several SDC with additional features for the development of paylines (paid).
It looks something like this:

Unpleasant moment - StreamSets has both free and paid parts.
Data bus
Now let's figure out where we will upload this data. Applicants:
- Apache kafka
- Rabbitmq
- NATS
Apache Kafka is the best option, but if you have RabbitMQ or NATS in your company, and you need to add a little bit of analytics, then deploying Kafka from scratch will not be very profitable.
In all other cases, Kafka is a great choice. In fact, it is a message broker with horizontal scaling and huge bandwidth. It is perfectly integrated into the entire ecosystem of tools for working with data and can withstand heavy loads. It has a universal interface and is the circulatory system of our data processing.
Inside, Kafka is divided into Topic - a certain separate data stream from messages with the same scheme or, at least, with the same purpose.
To discuss the next nuance, you need to remember that data sources may vary slightly. The data format is very important:

The Apache Avro data serialization format deserves special mention. The system uses JSON to determine the data structure (schema) that is serialized into a compact binary format . Therefore, we save a huge amount of data, and serialization / deserialization is cheaper.
Everything seems to be fine, but the presence of separate files with circuits poses a problem, since we need to exchange files between different systems. It would seem simple, but when you work in different departments, the guys on the other end can change something and calm down, and everything will break down for you.
In order not to transfer all these files to flash drives, floppy disks and rock paintings, there is a special service - Schema registry. This is a service for synchronizing avro-schemes between services that write and read from Kafka.

In terms of Kafka, the producer is the one who writes, the consumer is the one who consumes (reads) the data.
Data store
Applicants (in fact, there are many more options, but take only a few):
- HDFS + Hive
- Kudu + Impala
- Clickhouse
Before choosing a repository, remember what idempotency is . Wikipedia says that idempotency (Latin idem - the same + potens - capable) - the property of an object or operation when applying the operation to the object again, gives the same result as the first. In our case, the process of streaming processing should be built so that when re-filling the source data, the result remains correct.
How to achieve this in streaming systems:
- identify a unique id (can be composite)
- use this id to deduplicate data
HDFS + Hive storage does not provide idempotency for streaming recording “out of the box”, so we have:
- Kudu + Impala
- Clickhouse
Kudu is a repository suitable for analytic queries, but with a Primary Key for deduplication. Impala is the SQL interface to this repository (and several others).
As for ClickHouse, this is an analytical database from Yandex. Its main purpose is analytics on a table filled with a large stream of raw data. Of the advantages - there is a ReplacingMergeTree engine for key deduplication (deduplication is designed to save space and may leave duplicates in some cases, you need to take into account the nuances ).
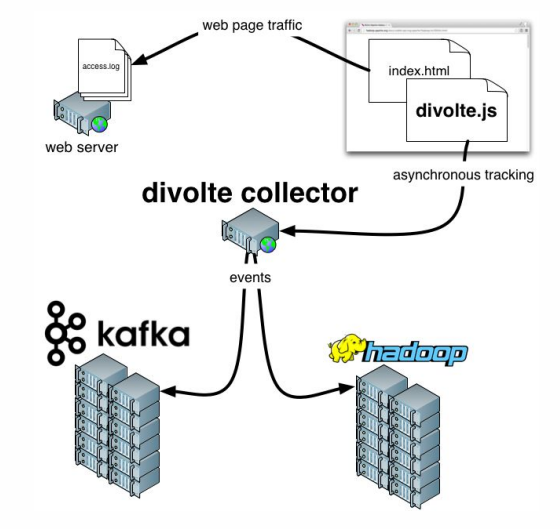
It remains to add a few words about Divolte . If you remember, we talked about the fact that some data needs to be captured. If you need to quickly and easily organize analytics for any portal, then Divolte is an excellent service for capturing user events on a web page via JavaScript.
Practical example
What are we trying to do? Let's try to build a pipeline to collect Clickstream data in real time. Clickstream is a virtual footprint that a user leaves while on your site. We will capture data using Divolte, and write it to Kafka.

To work, you need Docker, plus you will need to clone the following repository . Everything that happens will be launched in containers. To consistently run multiple containers at once, docker-compose.yml will be used. In addition, there is a Dockerfile compiling our StreamSets with certain dependencies.
There are also three folders:
- clickhouse data will be written to clickhouse-data
- exactly the same daddy ( sdc-data ) we will have for StreamSets, where the system can store configurations
- the third folder ( examples ) includes a request file and a pipe configuration file for StreamSets

To start, enter the following command:
docker-compose up
And we enjoy how slowly but surely containers start. After starting, we can go to the address http: // localhost: 18630 / and immediately touch Divolte:

So, we have Divolte, which has already received some events and recorded them in Kafka. Let's try to calculate them using StreamSets: http: // localhost: 18630 / (password / username - admin / admin).

In order not to suffer, it is better to import Pipeline , naming it, for example, clickstream_pipeline . And from the examples folder we import clickstream.json . If everything is ok, we will see the following picture :

So, we created a connection to Kafka, registered which Kafka we need, registered which topic interests us, then selected the fields that interest us, then put a drain in Kafka, registering which Kafka and which topic. The differences are that in one case, the Data format is Avro, and in the second it is just JSON.
Go ahead. We can, for example, make a preview that captures certain records in real time from Kafka. Then we write everything down.
After launching, we’ll see that a stream of events flies to Kafka, and this happens in real time:

Now you can make a repository for this data in ClickHouse. To work with ClickHouse, you can use a simple native client by running the following command:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Please note that this line indicates the network to which you want to connect. And depending on how you name the folder with the repository, your network name may differ. In general, the command will be as follows:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
The list of networks can be viewed with the command:
docker network ls
Well, there is nothing left:
1. First, “sign” our ClickHouse to Kafka , “explaining to him” what format the data we need there:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2. Now create a real table where we will put the final data:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3. And then we will provide a link between these two tables :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
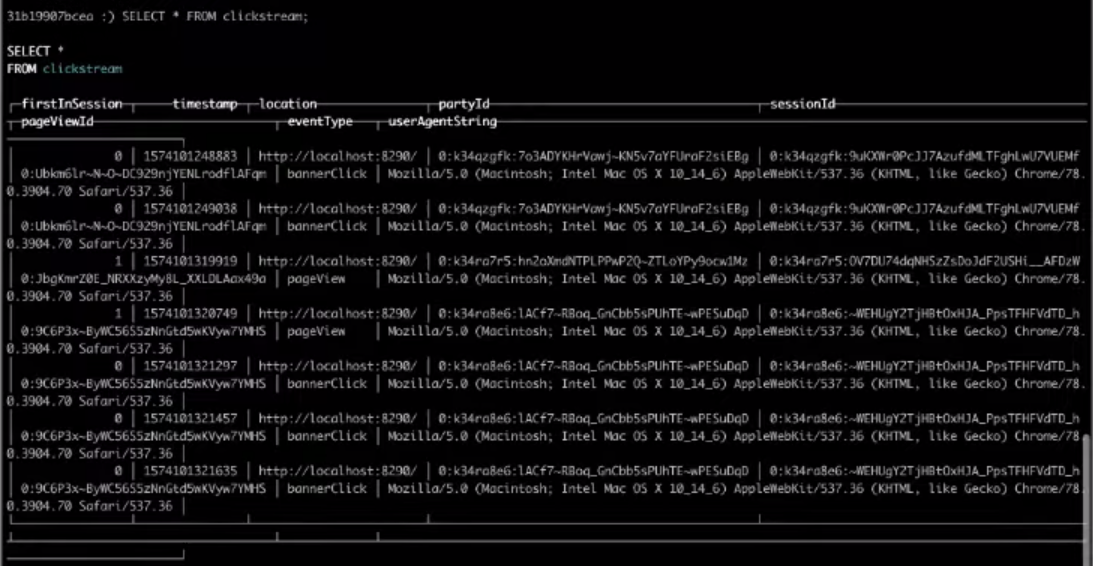
4. And now we will select the necessary fields :
SELECT * FROM clickstream;
As a result, the choice from the target table will give us the result we need.
That's all, it was the simplest Clickstream that you can build. If you want to complete the above steps yourself, watch the entire video .