
Based on my performances at Highload ++ and DataFest Minsk 2019
For many, mail today is an integral part of online life. With its help, we conduct business correspondence, store all kinds of important information related to finances, hotel reservations, checkout and much more. In mid-2018, we formulated a mail development product strategy. What should be modern mail?
Mail must be smart , that is, help users navigate the increasing amount of information: filter, structure and provide it in the most convenient way. It should be useful , allowing directly in the mailbox to solve various problems, for example, pay fines (a function that I, unfortunately, use). And at the same time, of course, mail should provide information protection by cutting off spam and protecting against hacks, that is, be safe .
These areas determine a number of key tasks, many of which can be effectively solved using machine learning. Here are examples of existing features developed as part of the strategy - one for each direction.
- Smart Reply . There is a smart answer function in the mail. The neural network analyzes the text of the letter, understands its meaning and purpose, and as a result offers the three most suitable answer options: positive, negative and neutral. This helps to significantly save time when answering letters, and also often respond non-standard and fun for yourself.
- Grouping of letters related to orders in online stores. We often make purchases on the Internet, and, as a rule, stores can send several letters for each order. For example, from AliExpress, the largest service, there are a lot of letters for one order, and we figured that in the terminal case their number can reach 29. Therefore, using the Named Entity Recognition model, we select the order number and other information from the text and group all letters in one thread. We also show the basic information about the order in a separate box, which makes it easier to work with this type of letters.
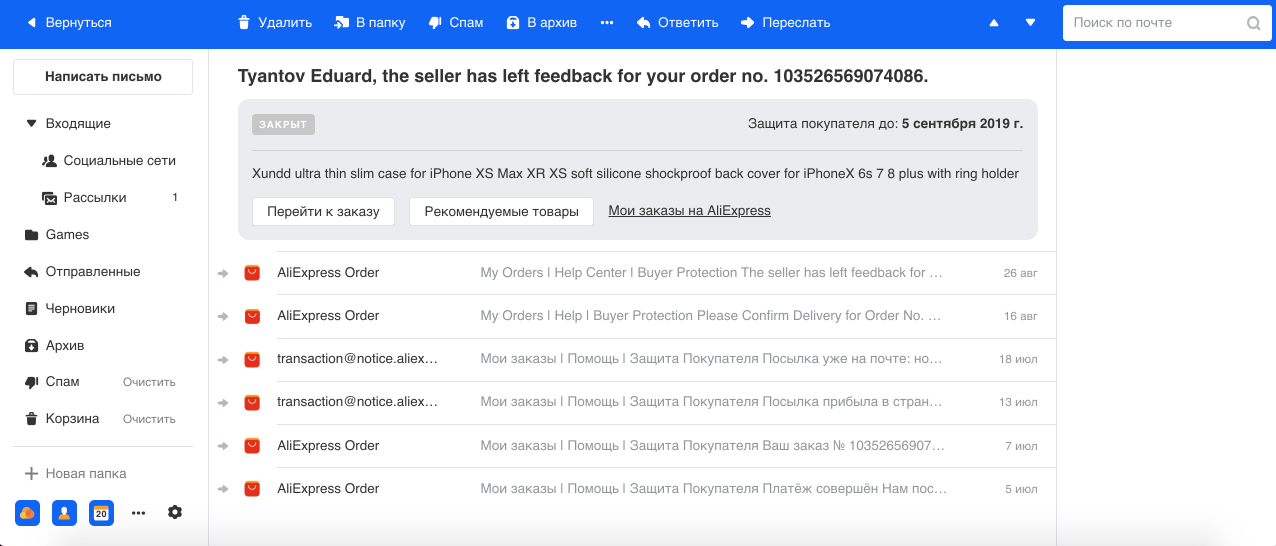
- Antiphishing . Phishing is a particularly dangerous fraudulent type of emails with the help of which attackers try to gain financial information (including user’s bank cards) and logins. Such letters mimic the real ones sent out by the service, including visually. Therefore, with the help of Computer Vision, we recognize the logos and style of letters of large companies (for example, Mail.ru, Sberbank, Alpha) and take this into account, along with text and other signs in our spam and phishing classifiers.
Machine learning
A little about machine learning in mail in general. Mail is a highly loaded system: on our servers, an average of 1.5 billion letters per day passes to 30 million DAU users. Serve all the necessary functions and features of about 30 machine learning systems.
Each letter goes through a whole classification conveyor. First we cut off spam and leave good emails. Users often do not notice the operation of anti-spam, because 95-99% of spam does not even get into the corresponding folder. Spam recognition is a very important part of our system, and the most difficult, since in the anti-spam sphere there is a constant adaptation between defense and attack systems, which provides a continuous engineering challenge for our team.
Next, we separate letters from people and robots. Letters from people are most important, so for them we provide features like Smart Reply. Letters from robots are divided into two parts: transactional - these are important letters from services, for example, confirmation of purchases or hotel reservations, finances, and information - these are business advertising, discounts.
We believe that transactional letters are equal in value to personal correspondence. They should be at hand, because often it is necessary to quickly find information about the order or booking a ticket, and we spend time searching for these letters. Therefore, for convenience, we automatically divide them into six main categories: travel, bookings, finances, tickets, registrations, and finally, fines.
Newsletters are the largest and probably less important group that does not require instant reaction, since nothing significant will change in the user's life if he does not read such a letter. In our new interface, we collapse them into two threads: social networks and newsletters, thus visually clearing the mailbox and leaving only important letters in sight.

Exploitation
A large number of systems causes many difficulties in operation. After all, models degrade over time, like any software: signs break down, machines fail, a code rolls around. In addition, data is constantly changing: new ones are added, the pattern of user behavior is transformed, etc., therefore, the model without proper support will work worse and worse over time.
We must not forget that the deeper machine learning penetrates the lives of users, the greater the impact they have on the ecosystem, and, as a result, the more financial losses or profits the market players can get. Therefore, in an increasing number of areas, players are adapting to the work of ML-algorithms (classic examples are advertising, search and the antispam already mentioned).
Also, machine learning tasks have a feature: any, albeit insignificant, change in the system can give rise to a lot of work with the model: working with data, retraining, deployment, which can drag on for weeks or months. Therefore, the faster the environment in which your models operate, the more effort their support requires. A team can create many systems and enjoy it, and then spend almost all the resources on their support, without the ability to do something new. We once encountered such a situation once in an anti-spam team. And they made the obvious conclusion that maintenance should be automated.
Automation
What can be automated? In fact, almost everything. I have identified four areas that define the infrastructure of machine learning:
- data collection;
- continuing education;
- deployment;
- testing & monitoring.
If the environment is unstable and constantly changing, then the entire infrastructure around the model is much more important than the model itself. It may be the good old linear classifier, but if you correctly apply the signs and establish good feedback from users, it will work much better than State-Of-The-Art-models with all the bells and whistles.
Feedback loop
This cycle combines data collection, further training and deployment - in fact, the entire cycle of updating the model. Why is it important? Look at the registration schedule in the mail:

The machine learning developer has introduced an antibot model that prevents bots from registering in the mail. The graph drops to a value where only real users remain. Everything is great! But four hours pass, the botvods tighten up their scripts, and everything returns to square one. In this implementation, the developer spent a month adding features and a training model, but the spammer was able to adapt in four hours.
In order not to be so painfully painful and do not have to redo everything later, we must initially think about how the feedback loop will look and what we will do if the environment changes. Let's start by collecting data - this is the fuel for our algorithms.
Data collection
It is clear that modern neural networks, the more data, the better, and they, in fact, generate users of the product. Users can help us by marking up the data, but you should not abuse it, because at some point users will be tired of completing your models and they will switch to another product.
One of the most common mistakes (here I make a reference on Andrew Ng) is that the orientation to the metrics on the test dataset is too strong, and not to the feedback from the user, which is actually the main measure of the quality of work, as we create a product for the user. If the user does not understand or dislike the work of the model, then everything is perishable.
Therefore, the user should always be able to vote, should give him a tool for feedback. If we think that a letter related to finance has arrived in the box, we need to mark it “finance”, and draw a button that the user can click on and say that it’s not finance.
Feedback quality
Let's talk about the quality of user feedback. Firstly, you and the user can put different meanings in one concept. For example, you and product managers believe that “finance” is letters from the bank, and the user believes that the letter from my grandmother about retirement also refers to finances. Secondly, there are users who thoughtlessly love to press buttons without any logic. Third, the user may be deeply mistaken in their conclusions. A vivid example from our practice is the introduction of the Nigerian spam classifier, a very funny type of spam, when the user is asked to collect several million dollars from a suddenly found distant relative in Africa. After introducing this classifier, we checked the “No spam” clicks on these letters, and it turned out that 80% of them are juicy Nigerian spam, which suggests that users can be extremely trusting.
And let's not forget that not only people can poke buttons, but also all sorts of bots that pretend to be a browser. So raw feedback is not good for learning. What can be done with this information?
We use two approaches:
- Feedback from related ML . For example, we have an online antibot system, which, as I mentioned, makes a quick decision based on a limited number of signs. And there is a second, slow system that works ex post. She has more data about the user, about his behavior, etc. As a result, the most balanced decision is made, respectively, it has higher accuracy and completeness. You can direct the difference in the work of these systems in the first as data for training. Thus, a simpler system will always try to get closer to a more complex performance.
- Classification of clicks . You can simply classify each user click, evaluate its validity and usability. We do this in the anti-spam mail, using the user's attributes, his history, sender attributes, the text itself and the result of the classifiers. As a result, we get an automatic system that validates user feedback. And since it is necessary to train it much less frequently, its work can become the main one for all other systems. Precision is the main priority in this model, because training a model on inaccurate data is fraught with consequences.
While we are cleaning data and retraining our ML-systems, we should not forget about users, because for us thousands, millions of errors on the graph are statistics, and for a user, every bug is a tragedy. In addition to the fact that the user needs to somehow live with your mistake in the product, he, after feedback, expects the exclusion of a similar situation in the future. Therefore, you should always give users not only the opportunity to vote, but also correct the behavior of ML-systems, creating, for example, personal heuristics for each click of feedback, in the case of mail it may be possible to filter such letters by sender and header for this user.
You also need to crutch the model on the basis of some reports or calls to support in semi-automatic or manual mode, so that other users also do not suffer from similar problems.
Heuristics for Learning
There are two problems with these heuristics and crutches. The first is that the ever-growing number of crutches is difficult to maintain, not to mention their quality and long-distance performance. The second problem is that the error may not be frequency, and a few clicks to retrain the model will not be enough. It would seem that these two unrelated effects can be substantially leveled if the following approach is applied.
- Create a temporary crutch.
- We direct the data from it to the model; it is regularly retrieved, including the data received. Here, of course, it is important that the heuristic has high accuracy so as not to reduce the quality of the data in the training set.
- Then we hang up the monitoring on the operation of the crutch, and if after some time the crutch does not work anymore and is completely covered by the model, then you can safely remove it. Now this problem is unlikely to recur.
So the army of crutches is very useful. The main thing is that their service is urgent, not permanent.
Further education
Retraining is the process of adding new data obtained as a result of feedback from users or other systems, and training the existing model on them. There can be several problems with retraining:
- A model may simply not support further education, and learn only from scratch.
- Nowhere in the book of nature does it say that continuing education will certainly improve the quality of work in production. Often it happens just the opposite, that is, only deterioration is possible.
- Changes can be unpredictable. This is a rather subtle point that we have identified for ourselves. Even if the new model in the A / B test shows similar results compared to the current one, this does not mean at all that it will work identically. Their work may differ in any one percent, which may bring new errors or return already corrected old ones. Both we and users already know how to live with current errors, and when a large number of new errors occur, the user may also not understand what is happening, because he expects predictable behavior.
Therefore, the most important thing in retraining is guaranteed to improve the model, or at least not to worsen it.
The first thing that comes to mind when we talk about continuing education is the Active Learning approach. What does this mean? For example, the classifier determines whether the letter relates to finances, and around its border of decision-making, we add a selection of marked-up examples. This works well, for example, in advertising, where there is a lot of feedback and you can train the model online. And if there is little feedback, then we get a strongly biased sample relative to the production of the data distribution, on the basis of which it is impossible to evaluate the behavior of the model during operation.
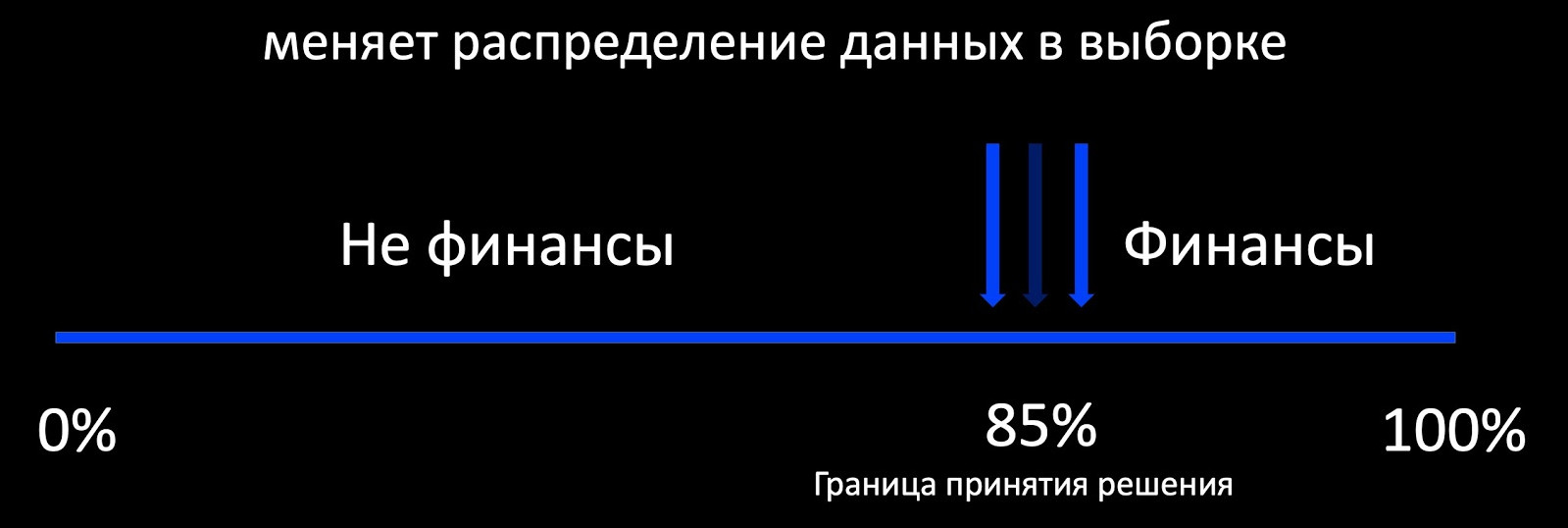
In fact, our goal is to preserve old patterns, already known models, and acquire new ones. Continuity is important here. The model, which we often rolled out with great difficulty, already works, so we can focus on its performance.
In the mail, different models are used: trees, linear, neural networks. For each we make our own retraining algorithm. In the process of retraining, we get not only new data, but often new features that we will take into account in all the algorithms below.
Linear models
Let's say we have a logistic regression. We compose a loss model from the following components:
- LogLoss on new data;
- we regularize the weights of new signs (we don’t touch the old ones);
- we learn from old data in order to preserve old patterns;
- and, perhaps, the most important: we attach Harmonic Regularization, which guarantees a slight change in weights relative to the old model at the norm.
Since each Loss component has coefficients, we can choose the optimal values for our task for cross-validation or based on product requirements.

The trees
Let's move on to decision trees. We filmed the following tree retraining algorithm:
- A forest of 100-300 trees works on the prod, which was trained on the old data set.
- At the end, we delete M = 5 pieces and add 2M = 10 new ones, trained on the entire data set, but with high weight from the new data, which naturally guarantees an incremental change in the model.
Obviously, over time, the number of trees increases significantly, and they must be periodically reduced in order to fit into the timings. To do this, we use the now ubiquitous Knowledge Distillation (KD). Briefly about the principle of its work.
- We have the current “complex” model. We start it on the training data set and get the probability distribution of the classes at the output.
- Next, we teach the student model (the model with fewer trees in this case) to repeat the results of the model using the class distribution as the target variable.
- It is important to note here that we do not use data set markup in any way, and therefore we can use arbitrary data. Of course, we use a sample of data from the battle stream as a training sample for the student model. Thus, the training set allows us to ensure the accuracy of the model, and a sample of the flow guarantees a similar performance on the production distribution, compensating for the offset of the training sample.
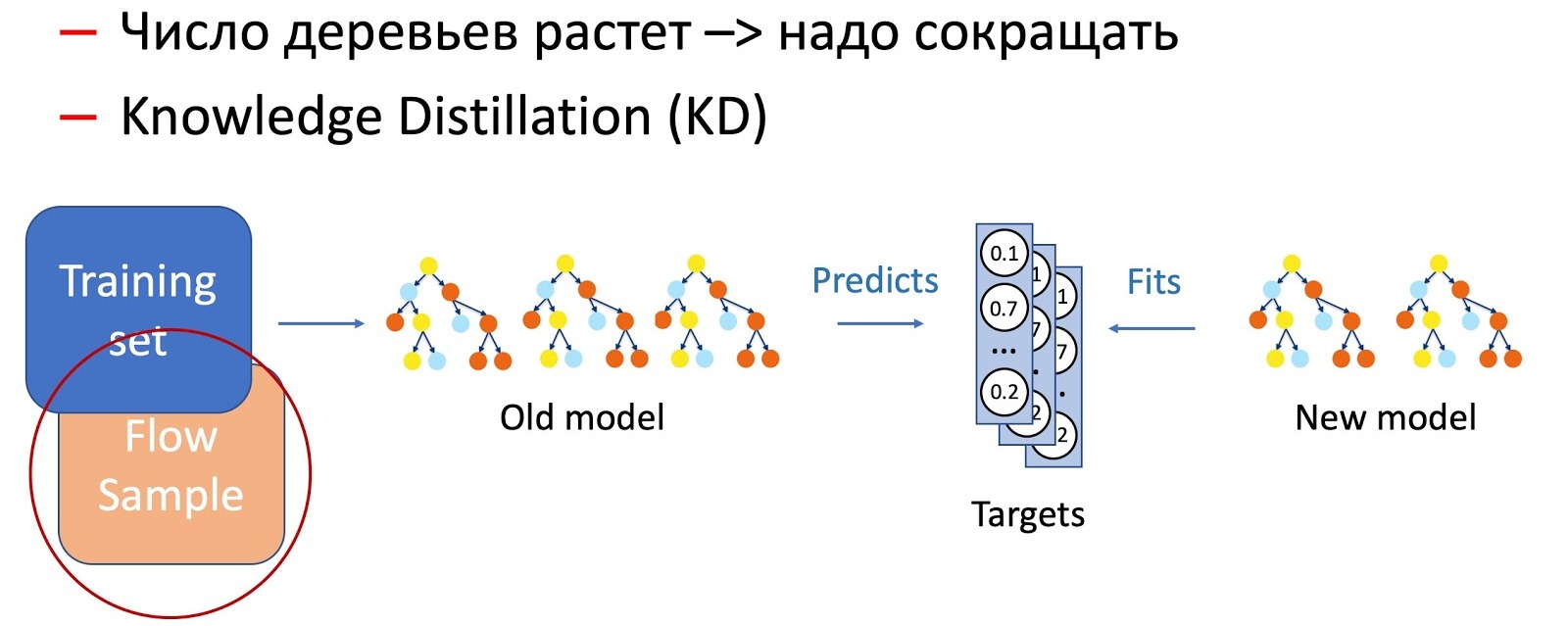
The combination of these two techniques (adding trees and periodically reducing their number using Knowledge Distillation) ensures the introduction of new patterns and complete continuity.
With the help of KD, we also carry out the distinction of operations with characteristics of a model, for example, removal of characteristics and work on passes. In our case, we have a number of important statistical features (by senders, text hashes, URLs, etc.), which are stored in a database that has the property to refuse. Of course, the model is not ready for such a development of events, since there are no failure situations in the training set. In such cases, we combine KD and augmentation techniques: when training for a part of the data, we delete or zero out the necessary signs, and we take the labels (outputs of the current model) as the initial ones, the student model teaches us to repeat this distribution.
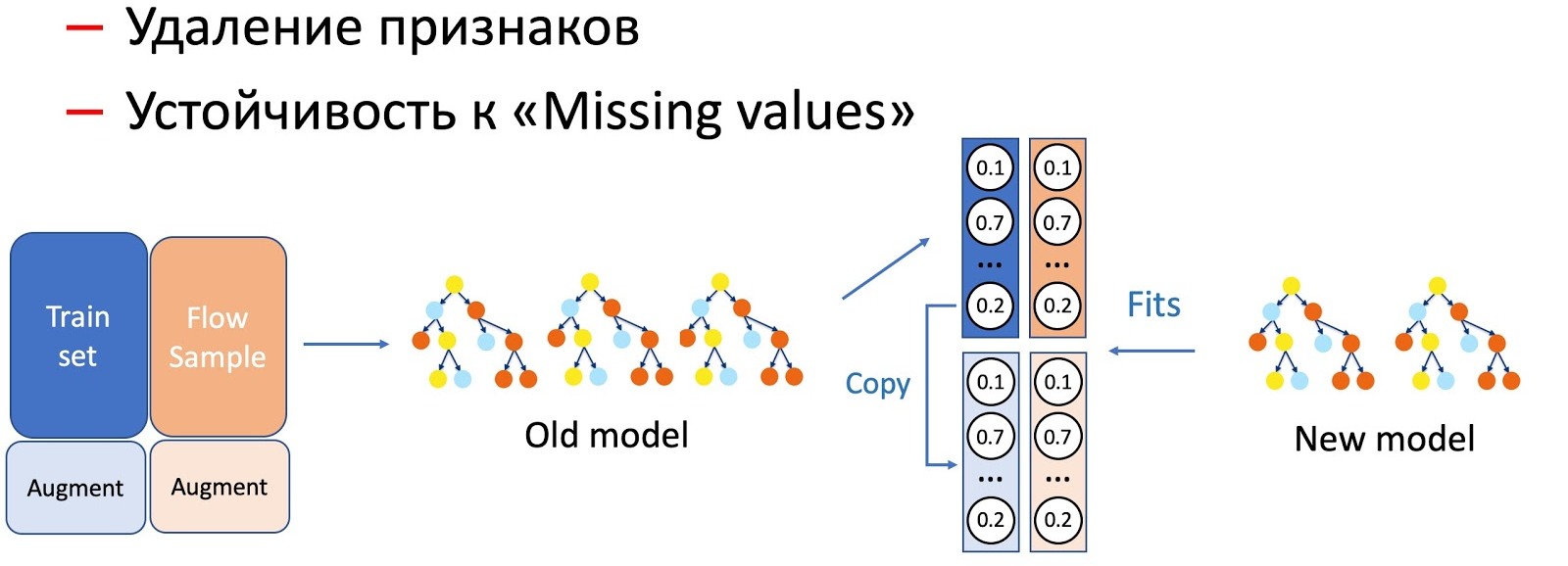
We noticed that the more serious manipulation of the models occurs, the greater the percentage of sample flow required.
To remove features, the simplest operation, only a small part of the flow is required, since only a couple of features change, and the current model studied on the same set - the difference is minimal. To simplify the model (reducing the number of trees by several times), 50 to 50 is already required. And omissions of important statistical features that seriously affect the performance of the model require even more flow to even out the work of the new model, which is resistant to omissions, on all types of letters.
Fasttext
Let's move on to FastText. Let me remind you that the representation (Embedding) of a word consists of the sum of embedding of the word itself and all of its alphabetic N-grams, usually trigrams. Since trigrams can be quite a lot, Bucket Hashing is used, that is, converting the entire space to a certain fixed hashmap. As a result, the weight matrix is obtained by the dimension of the inner layer by the number of words + bucket.
During further education, new signs appear: words and trigrams. In the standard after-training from Facebook, nothing significant happens. Only old weights with cross-entropy on new data are retrained. Thus, new features are not used, of course, this approach has all the above disadvantages associated with the unpredictability of the model on production. Therefore, we slightly modified FastText. We add all new weights (words and trigrams), finish the entire matrix with cross-entropy and add harmonic regularization by analogy with the linear model, which guarantees an insignificant change in old weights.

CNN
With convolution networks, it’s a bit more complicated. If the last layers are completed in CNN, then, of course, harmonic regularization can be applied and continuity guaranteed. But in the event that additional training of the entire network is required, then such regularization can no longer be hung on all layers. However, there is the option of teaching complementary embeddings through Triplet Loss ( original article ).
Triplet loss
Using the antiphishing problem as an example, let’s take a look at Triplet Loss. We take our logo, as well as positive and negative examples of logos of other companies. We minimize the distance between the first and maximize the distance between the second, we do this with a small gap to ensure greater compactness of the classes.

If we retrain the network, then our metric space is completely changing, and it becomes completely incompatible with the previous one. This is a serious problem in vectors. To get around this problem, we will mix old embeddings during training.
We have added new data to the training set and are training the second version of the model from scratch. At the second stage, we retrain our network (Finetuning): first the last layer is retrained, and then the whole network is thawed. In the process of compiling triplets, only part of the embeddings is calculated using the trained model, the rest - using the old one. Thus, in the process of retraining, we ensure the compatibility of the metric spaces v1 and v2. A peculiar variant of harmonic regularization.

Whole architecture
If we consider the entire system as an example of anti-spam, then the models are not isolated, but embedded in each other. We take pictures, text and other signs, using CNN and Fast Text we get embeddings. Then, on top of embeddings, classifiers are used, which give out scores for various classes (types of letters, spam, the presence of a logo). The scoria and signs already fall into the forest of trees for a final decision. Separate classifiers in this scheme make it possible to better interpret the results of the system and more accurately retrain the components in case of problems than to provide all the data raw to the decision trees.

As a result, we guarantee continuity at every level. At the lower level in CNN and Fast Text we use harmonic regularization, for classifiers in the middle we also use harmonic regularization and speed calibration for compatibility of probability distribution. Well, tree boosting is trained incrementally or with the help of Knowledge Distillation.
In general, support for such an embedded machine learning system is usually a pain, since any component at the lower level leads to an upgrade of the entire system above. But since in our setup each component changes slightly and is compatible with the previous one, the whole system can be updated piece by piece without the need to retrain the entire structure, which allows you to maintain it without a serious overhead.
Deploy
We examined the data collection and further training of different types of models, so we are moving on to their deployment in the production environment.
A / B testing
As I said earlier, in the process of collecting data, as a rule, we get a biased sample from which it is impossible to evaluate the production performance of the model. Therefore, when deploying, the model must be compared with the previous version in order to understand how things really go, that is, conduct A / B tests. In fact, the process of rolling out and analyzing charts is rather routine and lends itself to automation. We are rolling out our models gradually by 5%, by 30%, by 50% and by 100% of users, while collecting all available metrics according to the responses of the model and user feedback. In the case of some serious outliers, we automatically roll back the model, and for other cases, having collected a sufficient number of user clicks, we decide to increase the percentage. As a result, we bring the new model up to 50% of users completely automatically, and people will be able to roll out the entire audience, although this step can be automated.
However, the A / B test process offers room for optimization. The fact is that any A / B test is quite long (in our case, it takes from 6 to 24 hours depending on the amount of feedback), which makes it quite expensive and with limited resources. In addition, a sufficiently high percentage of the flow for the test is required to essentially speed up the total time of the A / B test (it can take a very long time to collect a statistically significant sample for evaluating metrics at a small percentage), which makes the number of A / B slots extremely limited. Obviously, we need to test only the most promising models, of which we get a lot in the process of retraining.
To solve this problem, we trained a separate classifier that predicts the success of the A / B test. To do this, we take decision making statistics, Precision, Recall, and other metrics on the training set, on the delayed one, and on the sample from the stream as signs. We also compare the model with the current one in production, with heuristics, and take into account the Complexity of the model. Using all these signs, the classifier trained on the history of tests will scout the candidate models, in our case it’s a forest of trees, and decides which one to put into the A / B test.

At the time of implementation, this approach allowed several times to increase the number of successful A / B tests.
Testing & Monitoring
Oddly enough, testing and monitoring do not harm our health; rather, on the contrary, they improve and relieve unnecessary stress. Testing helps prevent crashes, while monitoring can detect them in time to reduce impact on users.
It is important to understand that sooner or later your system will always be wrong - this is due to the development cycle of any software. At the beginning of system development, there are always a lot of bugs until everything settles down and the main stage of innovations is completed. But over time, entropy takes its toll, and errors again appear - due to the degradation of the components around and data changes, which I spoke about at the beginning.
Here I would like to note that any machine learning system must be considered in terms of its profit throughout the entire life cycle. The graph below shows an example of how the system works to catch a rare type of spam (on the graph, the line is near zero). Once, due to an incorrectly cached sign, she went crazy. As luck would have it, there was no monitoring for abnormal operation, as a result, the system began to save letters to the spam folder on the border of decision-making in large numbers. Despite correcting the consequences, the system has already made a mistake so many times that it will not pay for itself in five years. And this is a complete failure in terms of the life cycle of the model.

Therefore, such a simple thing as monitoring can become a key in the life of the model. In addition to standard and obvious metrics, we consider the distribution of responses and model scores, as well as the distribution of the values of key attributes. Using the KL divergence, we can compare the current distribution with the historical one or the values on the A / B test with the rest of the flow, which allows us to notice anomalies in the model and roll back the changes in time.
In most cases, we launch our first versions of systems using simple heuristics or models that we will use as monitoring in the future. For example, we monitor the NER-model in comparison with the regulars for specific online stores, and if the classifier coverage is squandered in comparison with them, then we understand the reasons. Another useful application of heuristics!
Summary
Let's walk through the key thoughts of the article once again.
- Fibdek . We always think about the user: how he will live with our mistakes, how he will be able to report them. Do not forget that users are not a source of pure feedback for training models, and it must be cleaned with the help of auxiliary ML-systems. If there is no way to collect a signal from the user, then we are looking for alternative feedback sources, for example, related systems.
- Retraining . The main thing here is continuity, so we rely on the current production model. We train new models so that they do not differ much from the previous one due to harmonic regularization and similar tricks.
- Deploy . . , .
, , ML-, , .