
Introduction
I / O reactor (single-threaded event loop ) is a pattern for writing highly loaded software, used in many popular solutions:
In this article, we will consider the ins and outs of the I / O reactor and the principle of its operation, write an implementation for less than 200 lines of code and force a simple HTTP server to process over 40 million requests / min.
Foreword
- The article was written with the aim of helping to understand the functioning of the I / O reactor, and therefore realize the risks when using it.
- To master the article, knowledge of the basics of the C language and a little experience in developing network applications are required.
- All code is written in C strictly according to ( carefully: long PDF ) the C11 standard for Linux and is available on GitHub .
Why is this needed?
With the growing popularity of the Internet, web servers needed to process a large number of connections at the same time, and therefore two approaches were tried: blocking I / O on a large number of OS threads and non-blocking I / O in combination with an event notification system, also called "system selector "( epoll / kqueue / IOCP / etc).
The first approach was to create a new OS thread for each incoming connection. Its disadvantage is poor scalability: the operating system will have to make many context transitions and system calls . They are expensive operations and can lead to a lack of free RAM with an impressive number of connections.
The modified version allocates a fixed number of threads (thread pool), thereby not allowing the system to crash execution, but at the same time introduces a new problem: if at the given moment the thread pool is blocked by long read operations, then other sockets that are already able to receive data will not be able to do this.
The second approach uses an event notification system (system selector), which the OS provides. This article discusses the most common type of system selector based on alerts (events, notifications) about readiness for I / O operations, rather than alerts about their completion . A simplified example of its use can be represented by the following flowchart:

The difference between these approaches is as follows:
- Blocking I / O operations suspend the user stream until the OS properly defragments the incoming IP packets into the byte stream ( TCP , receiving data) or free up enough space in the internal write buffers for subsequent sending via NIC (sending data).
- After a while, the system selector notifies the program that the OS has already defragmented IP packets (TCP, receiving data) or that enough space in the internal recording buffers is already available (sending data).
To summarize, reserving the OS thread for each I / O is a waste of computing power, because in reality, the threads are not busy with useful work (the term "software interruption" has its roots in it ). The system selector solves this problem by allowing the user program to consume CPU resources much more economically.
Reactor I / O Model
An I / O reactor acts as a layer between the system selector and user code. The principle of its operation is described by the following flowchart:
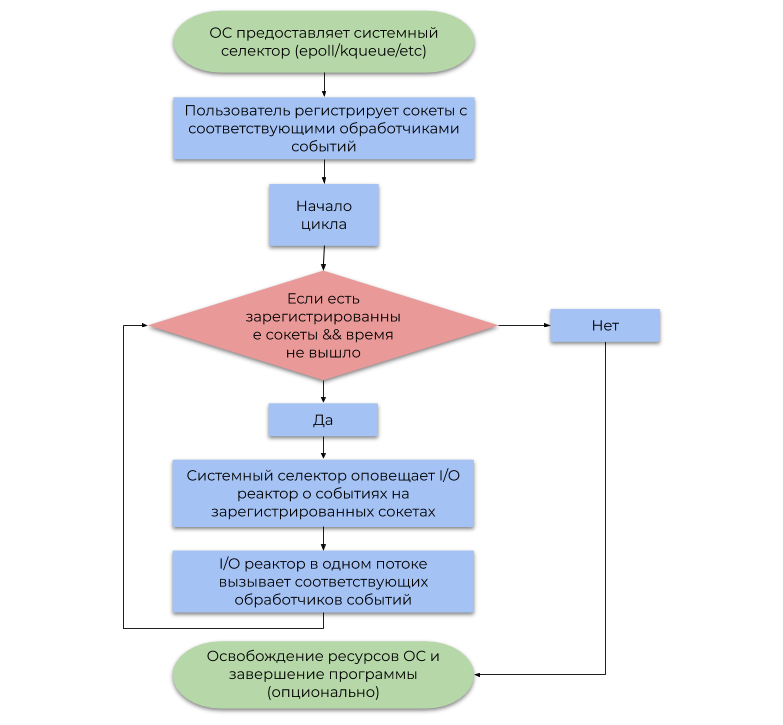
- Let me remind you that an event is a notification that a certain socket is able to perform a non-blocking I / O operation.
- An event handler is a function called by the I / O reactor when an event is received, which then performs a non-blocking I / O operation.
It is important to note that the I / O reactor is by definition single-threaded, but nothing prevents using the concept in a multi-threaded environment with respect to 1 stream: 1 reactor, thereby utilizing all CPU cores.
Implementation
We put the public interface in the reactor.h
file, and the implementation in reactor.c
. reactor.h
will consist of the following declarations:
typedef struct reactor Reactor; /* * , I/O * . */ typedef void (*Callback)(void *arg, int fd, uint32_t events); /* * `NULL` , -`NULL` `Reactor` * . */ Reactor *reactor_new(void); /* * , * I/O . * * -1 , 0 . */ int reactor_destroy(Reactor *reactor); int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_deregister(const Reactor *reactor, int fd); int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); /* * - `timeout`. * * * / . */ int reactor_run(const Reactor *reactor, time_t timeout);
The I / O structure of the reactor consists of an epoll selector file descriptor and a GHashTable
hash table , which each socket maps to CallbackData
(a structure from an event handler and a user argument for it).
struct reactor { int epoll_fd; GHashTable *table; // (int, CallbackData) }; typedef struct { Callback callback; void *arg; } CallbackData;
Please note that we have used the ability to handle an incomplete type by pointer. In reactor.h
we declare the structure of the reactor
, and in reactor.c
define it, thereby preventing the user from explicitly changing its fields. This is one of the patterns of data hiding that fits organically into the semantics of C.
The reactor_register
, reactor_deregister
and reactor_reregister
update the list of sockets of interest and the corresponding event handlers in the system selector and in the hash table.
#define REACTOR_CTL(reactor, op, fd, interest) \ if (epoll_ctl(reactor->epoll_fd, op, fd, \ &(struct epoll_event){.events = interest, \ .data = {.fd = fd}}) == -1) { \ perror("epoll_ctl"); \ return -1; \ } int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; } int reactor_deregister(const Reactor *reactor, int fd) { REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0) g_hash_table_remove(reactor->table, &fd); return 0; } int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; }
After the I / O reactor intercepted the event with the fd
descriptor, it calls the corresponding event handler, into which it passes fd
, the bit mask of the generated events, and the user pointer to void
.
int reactor_run(const Reactor *reactor, time_t timeout) { int result; struct epoll_event *events; if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL) abort(); time_t start = time(NULL); while (true) { time_t passed = time(NULL) - start; int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) { // case -1: perror("epoll_wait"); result = -1; goto cleanup; // case 0: result = 0; goto cleanup; // default: // for (int i = 0; i < nfds; i++) { int fd = events[i].data.fd; CallbackData *callback = g_hash_table_lookup(reactor->table, &fd); callback->callback(callback->arg, fd, events[i].events); } } } cleanup: free(events); return result; }
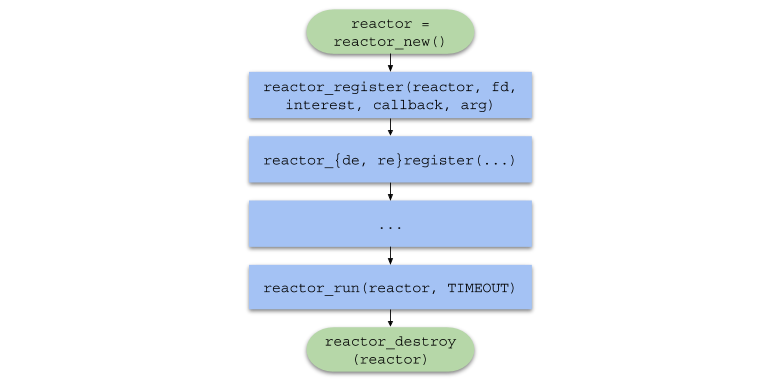
To summarize, the chain of function calls in user code will take the following form:
Single threaded server
In order to test the I / O reactor under high load, we will write a simple HTTP web server to respond to any request with an image.
HTTP is an application-level protocol primarily used for server interaction with a browser.
HTTP can easily be used on top of the TCP transport protocol, sending and receiving messages of the format defined by the specification .
Request format
<> <URI> < HTTP>CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
-
CRLF
is a sequence of two characters:\r
and\n
, separating the first line of query, headers and data. -
<>
is one ofCONNECT
,DELETE
,GET
,HEAD
,OPTIONS
,PATCH
,POST
,PUT
,TRACE
. The browser will send aGET
command to our server, meaning "Send me the contents of the file." -
<URI>
is the unified resource identifier . For example, if URI =/index.html
, then the client requests the main page of the site. -
< HTTP>
is the HTTP protocol version in theHTTP/XY
format. The most commonly used version to date isHTTP/1.1
. -
< N>
is a key-value pair in the format<>: <>
, sent to the server for further analysis. -
<>
- data required by the server to complete the operation. Often it is just JSON or any other format.
Response format
< HTTP> < > < >CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
-
< >
is a number representing the result of an operation. Our server will always return status 200 (successful operation). -
< >
- string representation of the status code. For status code 200, this isOK
. -
< N>
- a header of the same format as in the request. We will return theContent-Length
(file size) andContent-Type: text/html
(return type) headers. -
<>
- data requested by the user. In our case, this is the path to the image in HTML .
The http_server.c
(single-threaded server) file includes the common.h
file, which contains the following function prototypes:
/* * , , * . */ static void on_accept(void *arg, int fd, uint32_t events); /* * , , * HTTP . */ static void on_send(void *arg, int fd, uint32_t events); /* * , , * HTTP . */ static void on_recv(void *arg, int fd, uint32_t events); /* * . */ static void set_nonblocking(int fd); /* * stderr * `EXIT_FAILURE`. */ static noreturn void fail(const char *format, ...); /* * , * TCP . */ static int new_server(bool reuse_port);
The function macro SAFE_CALL()
also described and the fail()
function is defined. The macro compares the value of the expression with the error, and if the condition is fulfilled, it calls the fail()
function:
#define SAFE_CALL(call, error) \ do { \ if ((call) == error) { \ fail("%s", #call); \ } \ } while (false)
The fail()
function prints the passed arguments to the terminal (like printf()
) and terminates the program with the EXIT_FAILURE
code:
static noreturn void fail(const char *format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fprintf(stderr, ": %s\n", strerror(errno)); exit(EXIT_FAILURE); }
The new_server()
function returns the file descriptor of the "server" socket created by the system calls socket()
, bind()
and listen()
and capable of accepting incoming connections in non-blocking mode.
static int new_server(bool reuse_port) { int fd; SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)), -1); if (reuse_port) { SAFE_CALL( setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)), -1); } struct sockaddr_in addr = {.sin_family = AF_INET, .sin_port = htons(SERVER_PORT), .sin_addr = {.s_addr = inet_addr(SERVER_IPV4)}, .sin_zero = {0}}; SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1); SAFE_CALL(listen(fd, SERVER_BACKLOG), -1); return fd; }
- Note that the socket is initially created in non-blocking mode using the
SOCK_NONBLOCK
flag, so that in theon_accept()
function (read more), theaccept()
system call does not stop the execution of the stream. - If
reuse_port
istrue
, then this function will configure the socket with theSO_REUSEPORT
option usingsetsockopt()
to use the same port in a multi-threaded environment (see the section "Multi-threaded server").
The on_accept()
event handler is called after the OS generates an EPOLLIN
event, in this case meaning that a new connection can be accepted. on_accept()
accepts the new connection, switches it to non-blocking mode and registers with the on_recv()
event handler in the I / O reactor.
static void on_accept(void *arg, int fd, uint32_t events) { int incoming_conn; SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1); set_nonblocking(incoming_conn); SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv, request_buffer_new()), -1); }
The on_recv()
event handler is called after the OS generates an EPOLLIN
event, in this case meaning that the connection registered by on_accept()
is ready to accept data.
on_recv()
reads the data from the connection until the full HTTP request has been received, then it registers the on_send()
handler to send the HTTP response. If the client disconnects, the socket deregisters and closes with close()
.
static void on_recv(void *arg, int fd, uint32_t events) { RequestBuffer *buffer = arg; // , recv 0 ssize_t nread; while ((nread = recv(fd, buffer->data + buffer->size, REQUEST_BUFFER_CAPACITY - buffer->size, 0)) > 0) buffer->size += nread; // if (nread == 0) { SAFE_CALL(reactor_deregister(reactor, fd), -1); SAFE_CALL(close(fd), -1); request_buffer_destroy(buffer); return; } // read , , // if (errno != EAGAIN && errno != EWOULDBLOCK) { request_buffer_destroy(buffer); fail("read"); } // HTTP . // if (request_buffer_is_complete(buffer)) { request_buffer_clear(buffer); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLOUT, on_send, buffer), -1); } }
The on_send()
event handler is called after the OS generates an EPOLLOUT
event, which means that the connection registered by on_recv()
is ready to send data. This function sends an HTTP response containing HTML with the image to the client, and then changes the event handler to on_recv()
again.
static void on_send(void *arg, int fd, uint32_t events) { const char *content = "<img " "src=\"https://habrastorage.org/webt/oh/wl/23/" "ohwl23va3b-dioerobq_mbx4xaw.jpeg\">"; char response[1024]; sprintf(response, "HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: " "text/html" DOUBLE_CRLF "%s", strlen(content), content); SAFE_CALL(send(fd, response, strlen(response), 0), -1); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1); }
And finally, in the file http_server.c
, in the main()
function, we create an I / O reactor using reactor_new()
, create a server socket and register it, start the reactor using reactor_run()
exactly one minute, and then release the resources and exit from the program.
#include "reactor.h" static Reactor *reactor; #include "common.h" int main(void) { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL( reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); }
Check that everything works as expected. We compile ( chmod a+x compile.sh && ./compile.sh
in the root of the project) and start the self-written server, open http://127.0.0.1:18470 in the browser and observe what was expected:
Performance measurement
$ screenfetch MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic MMd /++ -sNMd: Uptime: 2h 34m MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217 ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20 NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080 NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10 NMm dMM -MMm `MMM dMM. dMM WM: Muffin NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y) NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3] hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y -NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9 -dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C] `/dMNmy+/:-------------:/yMMM GPU: NV136 ./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB \.MMMMMMMMMMMMMMMMMMM
We measure the performance of a single-threaded server. Let's open two terminals: in one we run ./http_server
, in the other - wrk . After a minute, the following statistics will be displayed in the second terminal:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 493.52us 76.70us 17.31ms 89.57% Req/Sec 24.37k 1.81k 29.34k 68.13% 11657769 requests in 1.00m, 1.60GB read Requests/sec: 193974.70 Transfer/sec: 27.19MB
Our single-threaded server was able to process over 11 million requests per minute, originating from 100 connections. Not a bad result, but can it be improved?
Multithreaded server
As mentioned above, an I / O reactor can be created in separate streams, thereby utilizing all the CPU cores. Let's apply this approach in practice:
#include "reactor.h" static Reactor *reactor; #pragma omp threadprivate(reactor) #include "common.h" int main(void) { #pragma omp parallel { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); } }
Now each thread owns its own reactor:
static Reactor *reactor; #pragma omp threadprivate(reactor)
Note that the argument to new_server()
is true
. This means that we are setting the server socket to the SO_REUSEPORT
option to use it in a multi-threaded environment. You can read more here .
Second run
Now we’ll measure the performance of a multithreaded server:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 1.14ms 2.53ms 40.73ms 89.98% Req/Sec 79.98k 18.07k 154.64k 78.65% 38208400 requests in 1.00m, 5.23GB read Requests/sec: 635876.41 Transfer/sec: 89.14MB
The number of processed requests in 1 minute increased by ~ 3.28 times! But up to the round number, only ~ two million was not enough, let's try to fix it.
First, look at the statistics generated by perf :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded Performance counter stats for './http_server_multithreaded': 242446,314933 task-clock (msec) # 4,000 CPUs utilized 1 813 074 context-switches # 0,007 M/sec 4 689 cpu-migrations # 0,019 K/sec 254 page-faults # 0,001 K/sec 895 324 830 170 cycles # 3,693 GHz 621 378 066 808 instructions # 0,69 insn per cycle 119 926 709 370 branches # 494,653 M/sec 3 227 095 669 branch-misses # 2,69% of all branches 808 664 cache-misses 60,604330670 seconds time elapsed
Using CPU affinity , compiling with -march=native
, PGO , increasing the number of hits in the cache , increasing MAX_EVENTS
and using EPOLLET
did not give a significant increase in performance. But what happens if you increase the number of simultaneous connections?
Statistics for 352 simultaneous connections:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 352 connections Thread Stats Avg Stdev Max +/- Stdev Latency 2.12ms 3.79ms 68.23ms 87.49% Req/Sec 83.78k 12.69k 169.81k 83.59% 40006142 requests in 1.00m, 5.48GB read Requests/sec: 665789.26 Transfer/sec: 93.34MB
The desired result was obtained, and with it an interesting graph showing the dependence of the number of processed requests in 1 minute on the number of connections:
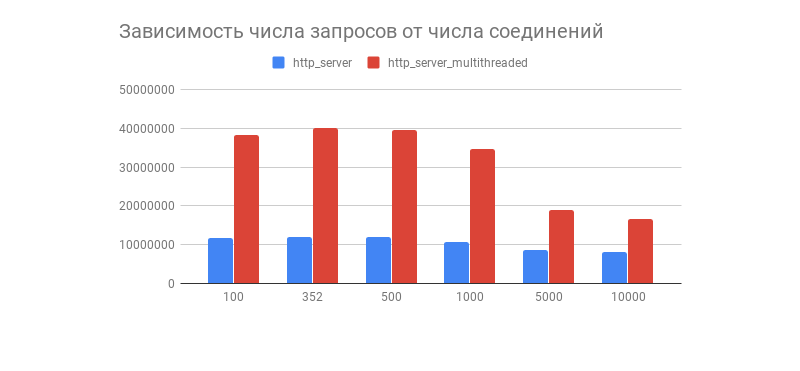
We see that after a couple of hundreds of connections the number of processed requests from both servers drops sharply (in a multi-threaded version this is more noticeable). Is this related to the Linux TCP / IP stack implementation? Feel free to write your assumptions about such graph behavior and optimizations of multithreaded and single-threaded options in the comments.
As noted in the comments, this performance test does not show the behavior of the I / O reactor on real loads, because almost always the server interacts with the database, displays logs, uses cryptography with TLS , etc., as a result of which the load becomes heterogeneous (dynamic). Tests along with third-party components will be conducted in an article about the I / O proactor.
Disadvantages of I / O Reactor
You need to understand that the I / O reactor is not without drawbacks, namely:
- Using an I / O reactor in a multi-threaded environment is somewhat more difficult, because you have to manually manage the flows.
- Practice shows that in most cases the load is heterogeneous, which can lead to the fact that one thread will be put down while the other is loaded with work.
- If one event handler blocks the stream, the system selector itself will also be blocked, which can lead to hard-to-catch bugs.
These problems are solved by the I / O proctor , often having a scheduler that evenly distributes the load to the thread pool, and also has a more convenient API. It will be discussed later in my other article.
Conclusion
On this, our journey from theory straight to the exhaust profiler came to an end.
Do not dwell on this, because there are many other equally interesting approaches to writing network software with different levels of convenience and speed. Interesting, in my opinion, links are given below.
See you soon!
Interesting projects
What else to read?
- https://linux.die.net/man/7/socket
- https://stackoverflow.com/questions/1050222/what-is-the-difference-between-concurrency-and-parallelism
- http://www.kegel.com/c10k.html
- https://kernel.dk/io_uring.pdf
- https://aturon.github.io/blog/2016/09/07/futures-design/
- https://tokio.rs/blog/2019-10-scheduler/
- https://www.artima.com/articles/io_design_patterns.html
- https://habr.com/en/post/183832/