You will also learn how we implement new functionality on a bunch of servers right away. And how to test complex services directly in production, without giving users any inconvenience. In general, how the search for the Market works, so that everyone would be fine.
A little about us: what problem do we solve
When you enter text, look for products by parameters or compare prices in different stores, all requests arrive at the search service. Search is the largest service in the Market.
We process all search queries: from the sites market.yandex.ru, beru.ru, the Supercheck service, Yandex.Advisor, and mobile applications. We also include offers of goods in search results on yandex.ru.
By search service, I mean not only the search itself, but also a database with all the offers on the Market. The scale is this: more than a billion search queries are processed per day. And everything should work quickly, without interruptions and always produce the desired result.
What is what: Market architecture
Briefly describe the current architecture of the Market. Conventionally, it can be described by the scheme below:
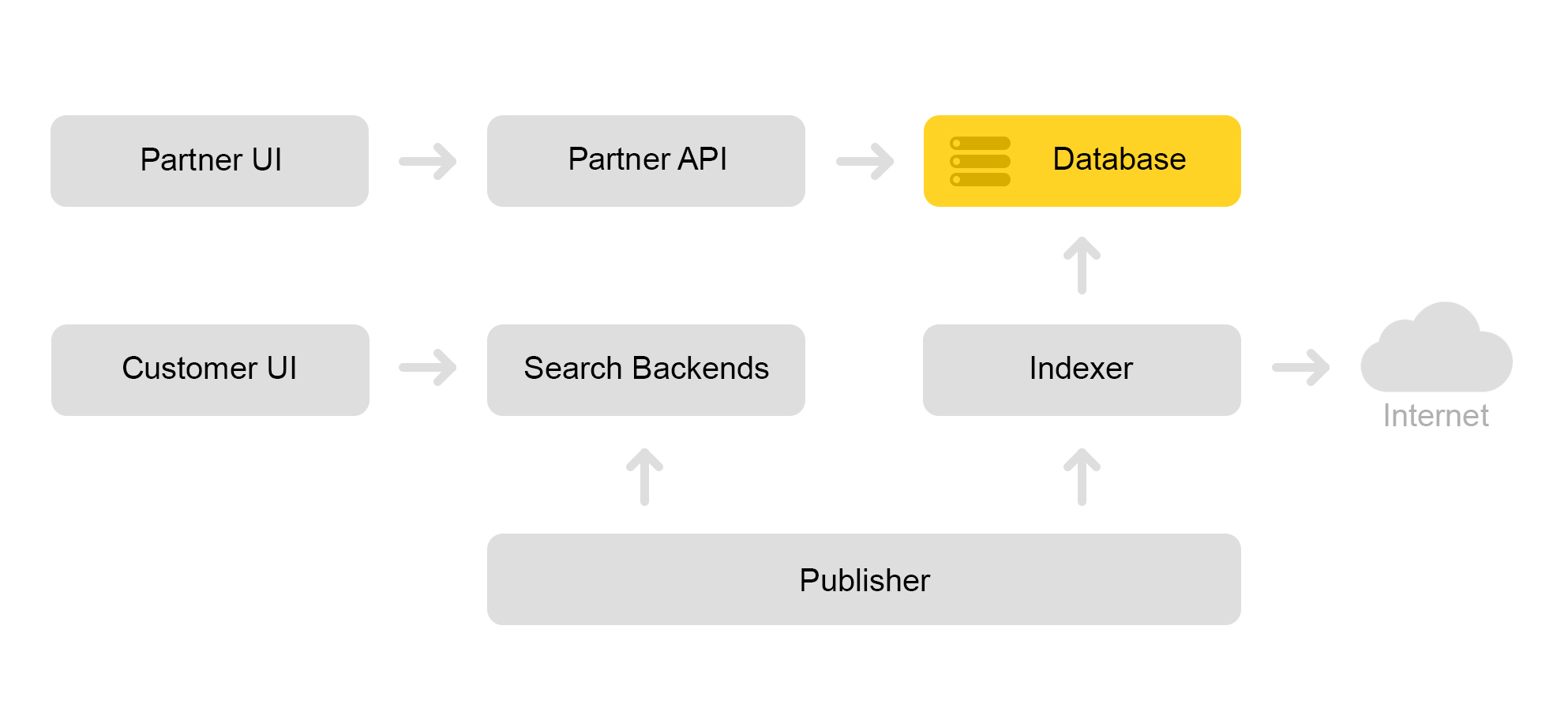
Let's say a partner store comes to us. He says I want to sell a toy: this evil cat with a squeaker. And an evil cat without a tweeter. And just a cat. Then the store needs to prepare offers on which the Market searches. The store forms a special xml with offers and reports the path to this xml through the affiliate interface. Then the indexer periodically downloads this xml, checks for errors and stores all the information in a huge database.
There are a lot of saved xml. A search index is created from this database. The index is stored in internal format. After creating the index, the Layouts service uploads it to the search engines.
As a result, an evil cat with a squeaker appears in the database, and a cat index appears on the server.
I’ll talk about how we look for a cat in the part about the search architecture.
Market Search Architecture
We live in the world of microservices: each incoming request to market.yandex.ru causes a lot of subqueries, and dozens of services participate in their processing. The diagram shows only a few:
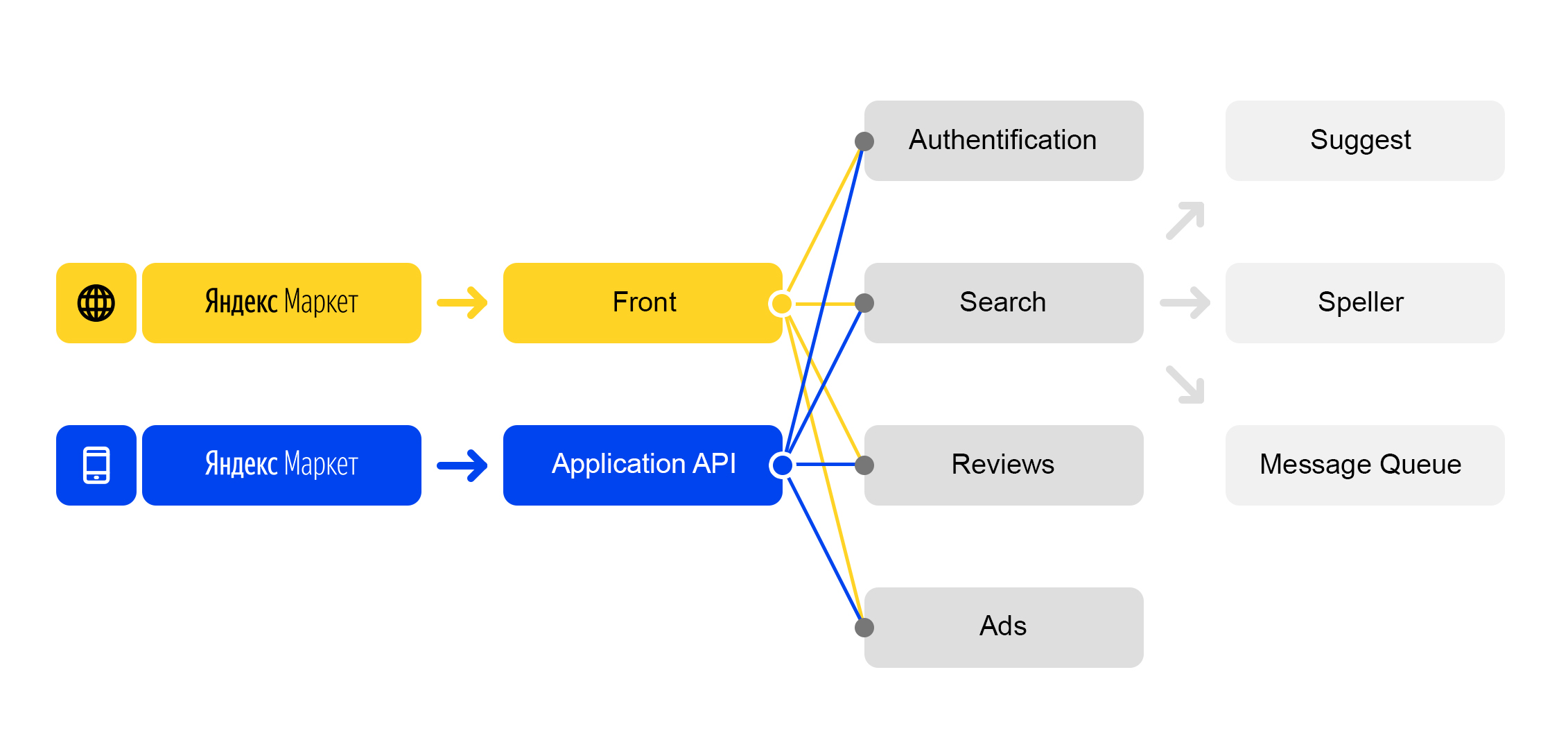
Simplified request processing scheme
Each service has a wonderful thing - its own balancer with a unique name:
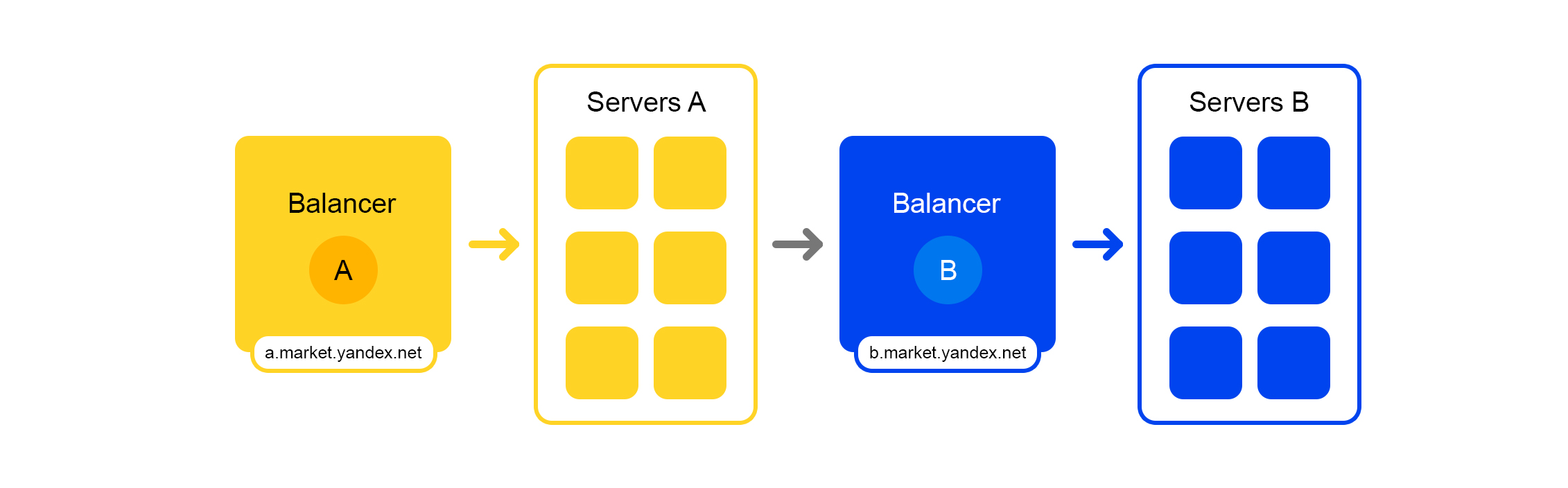
The balancer gives us great flexibility in managing the service: for example, you can turn off the servers, which is often required for updates. The balancer sees that the server is unavailable and automatically redirects requests to other servers or data centers. When you add or remove a server, the load is automatically redistributed between the servers.
The unique name of the balancer does not depend on the data center. When service A makes a request to B, then by default, balancer B redirects the request to the current data center. If the service is unavailable or absent in the current data center, the request is redirected to other data centers.
A single FQDN for all data centers allows service A to generally disengage from locations. His request to service B will always be processed. An exception is the case when the service is in all data centers.
But not everything is so rosy with this balancer: we have an additional intermediate component. The balancer may work unstably, and this problem is solved by redundant servers. There is also an additional delay between services A and B. But in practice, it is less than 1 ms and for most services this is not critical.
Fighting the unexpected: balancing and resilient search services
Imagine that a collapse happened: you need to find a cat with a squeaker, but the server crashes. Or 100 servers. How to get out? Will we really leave the user without a cat?
The situation is terrible, but we are ready for it. I'll tell you in order.
Search infrastructure is located in several data centers:
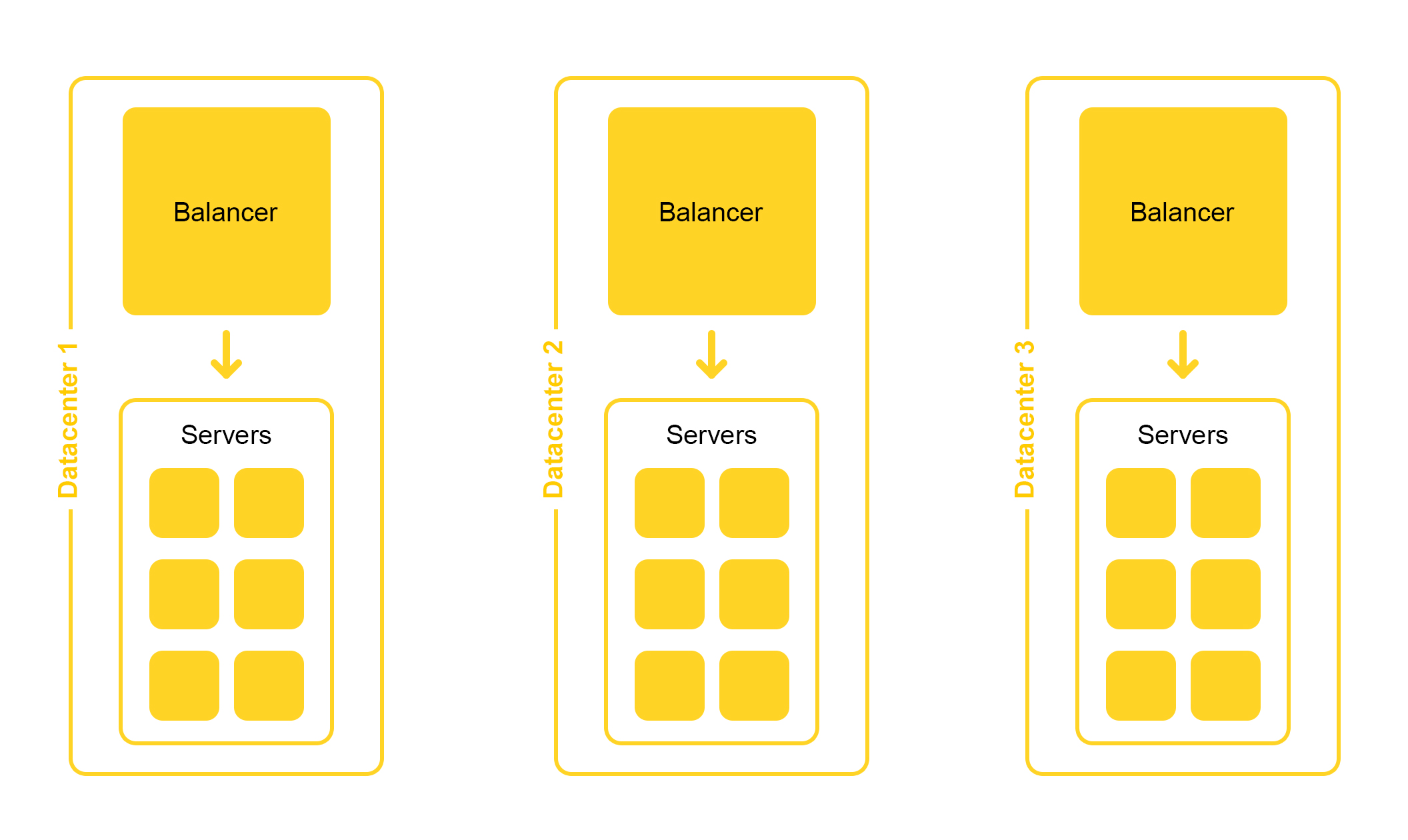
When designing, we lay the possibility of disabling one data center. Life is full of surprises - for example, an excavator can cut an underground cable (yes, it was like that). The capacities in the remaining data centers should be sufficient to withstand the peak load.
Consider a single data center. In each data center the same scheme of balancers:
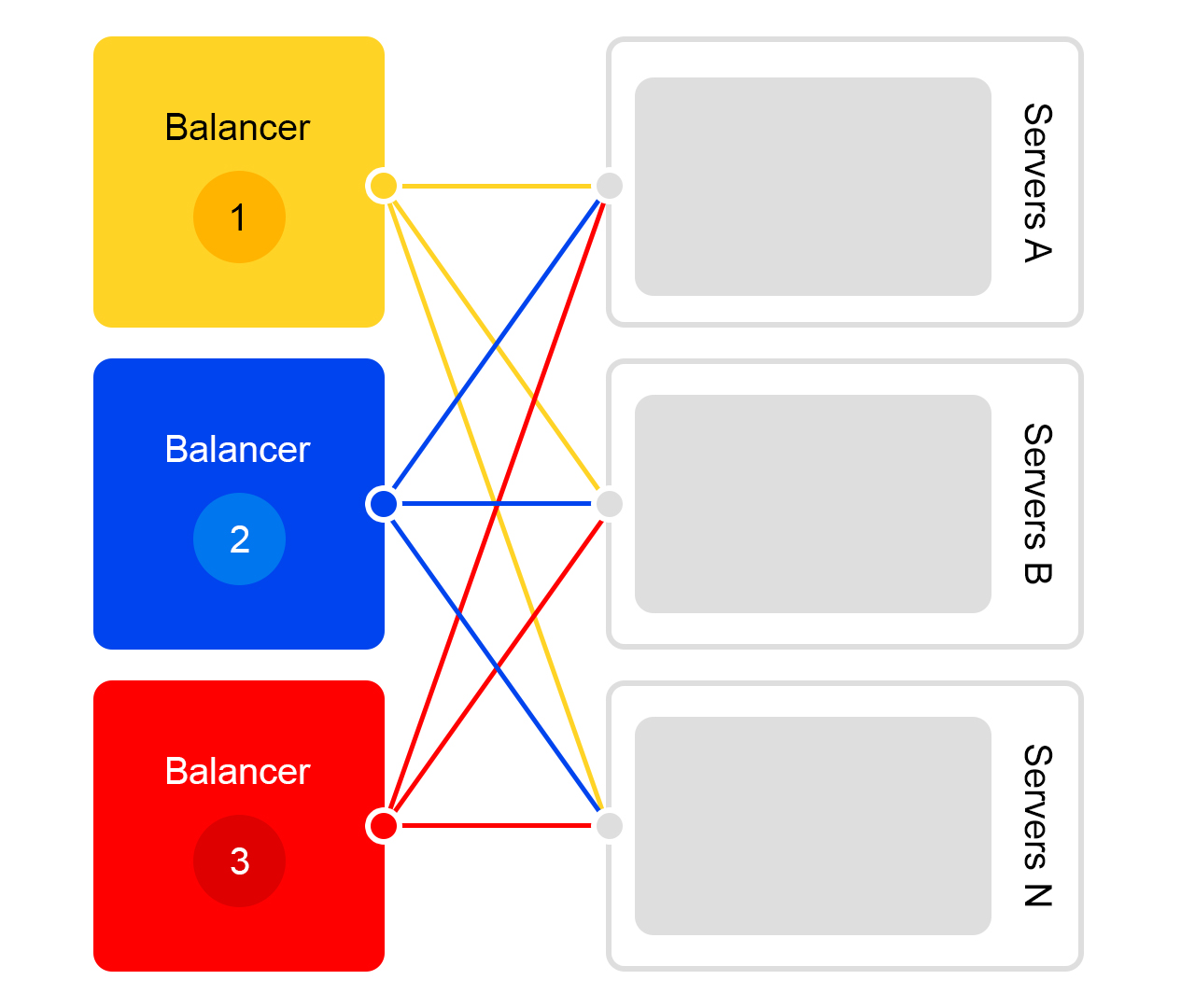
One balancer is at least three physical servers. Such redundancy is made for reliability. Balancers work at HAProx.
We selected HAProx because of its high performance, small resource requirements and wide functionality. Inside each server our search software works.
The probability of failure of one server is small. But if you have many servers, the likelihood that at least one falls will increase.
This is what happens in reality: servers are crashing. Therefore, you must constantly monitor the status of all servers. If the server stops responding, then it is automatically disconnected from the traffic. To do this, HAProxy has a built-in health check. It goes to all servers with HTTP request “/ ping” once a second.
Another feature of HAProxy: agent-check allows you to load all servers evenly. To do this, HAProxy connects to all servers, and they return their weight depending on the current load from 1 to 100. The weight is calculated based on the number of requests in the processing queue and the load on the processor.
Now about finding a cat. Inquiries of the form / search? Text = angry + cat arrive to search . For the search to be fast, the entire cat index must be placed in RAM. Even reading from an SSD is not fast enough.
Once upon a time, the offer base was small, and there was enough RAM for one server for it. As the proposal database grew, everything ceased to fit in this RAM, and the data was divided into two parts: shard 1 and shard 2.

But it always happens: any solution, even a good one, gives rise to other problems.
The balancer still went to any server. But on the machine where the request came, there was only half the index. The rest was on other servers. Therefore, the server had to go to some neighboring machine. After receiving data from both servers, the results were combined and reorganized.
Since the balancer distributes requests evenly, all servers were engaged in re-arranging, and not only giving data.
The problem occurred if the neighboring server was unavailable. The solution was to specify several servers with different priorities as the "neighboring" server. First, the request was sent to the servers in the current rack. If no response was received, the request was sent to all servers in this data center. And last but not least, the request went to other data centers.
As the number of proposals increased, the data was divided into four parts. But this was not the limit.
Now a configuration of eight shards is used. In addition, to further save memory, the index was divided into the search part (by which the search takes place) and the snippet part (which is not involved in the search).
One server contains information on only one shard. Therefore, to perform a search on the full index, you need to search on eight servers containing different shards.
Servers are grouped in clusters. Each cluster contains eight search engines and one snippet.
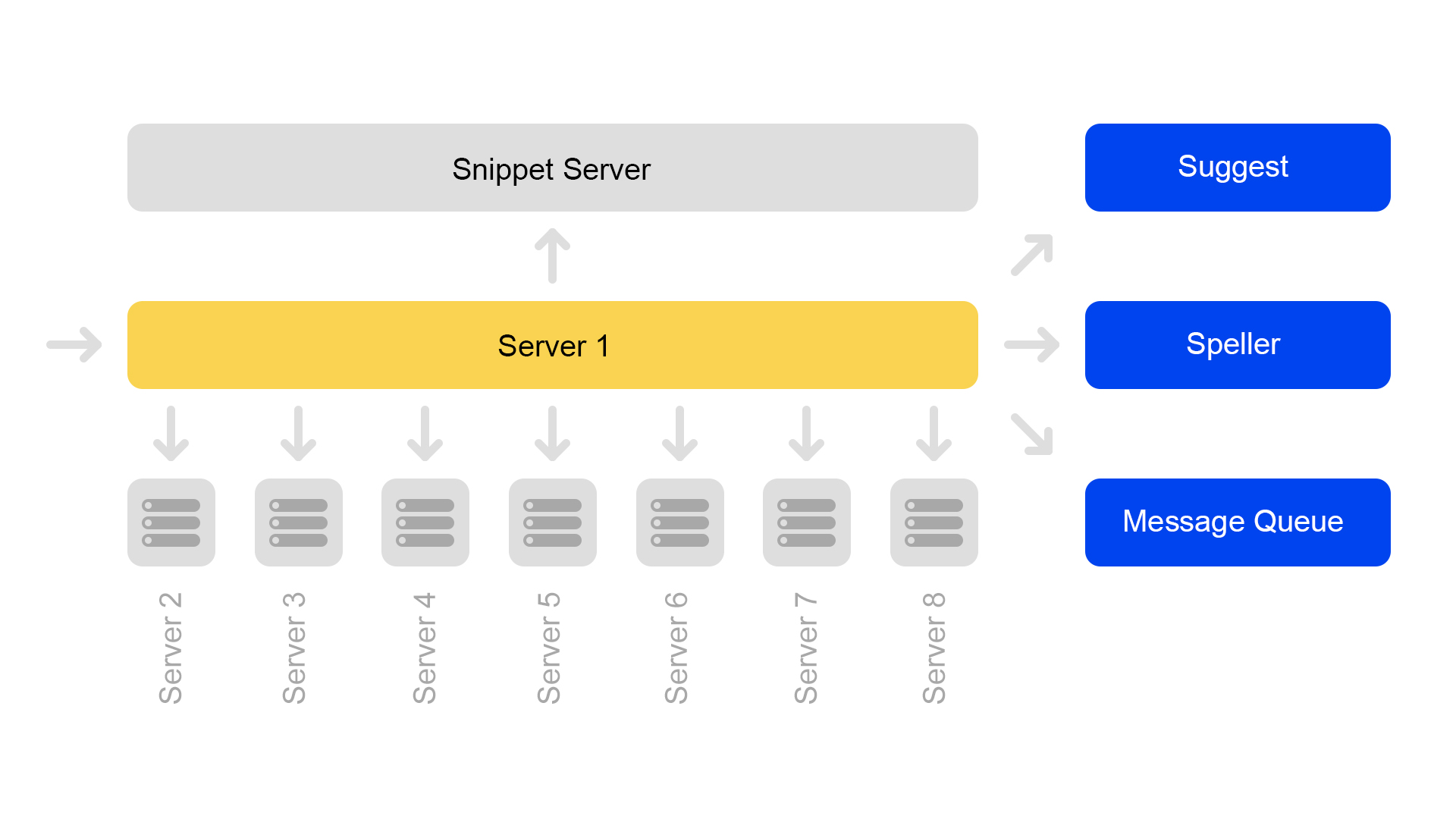
The key-value database with static data runs on the snippet server. They are needed for issuing documents, for example, a description of a cat with a squeaker. The data is specially taken out on a separate server so as not to load the memory of search engines.
Since document IDs are unique only within the framework of one index, a situation could arise that there are no documents in the snippets. Well or that on one ID there will be other content. Therefore, in order for the search to work and the search to occur, a need has emerged for the consistency of the entire cluster. I’ll talk about how we monitor consistency a bit below.
The search itself is organized as follows: a search query can come to any of eight servers. Suppose he came to server 1. This server processes all the arguments and understands what and how to look for. Depending on the incoming request, the server may make additional requests to external services for the necessary information. One request can be followed by up to ten requests to external services.
After collecting the necessary information, a search begins on the database of offers. To do this, subqueries are made for all eight servers in the cluster.
After receiving the answers, the results are combined. In the end, to generate the issue, you may need a few more subqueries to the snippet server.
Search queries within the cluster are: / shard1? Text = angry + cat . In addition, subqueries of the form: / status are constantly made between all servers within the cluster once a second.
The / status request detects a situation when the server is not available.
It also controls that on all servers the search engine version and index version are the same, otherwise there will be inconsistent data inside the cluster.
Despite the fact that one snippet server processes requests from eight search engines, its processor is very lightly loaded. Therefore, now we transfer snippet data to a separate service.
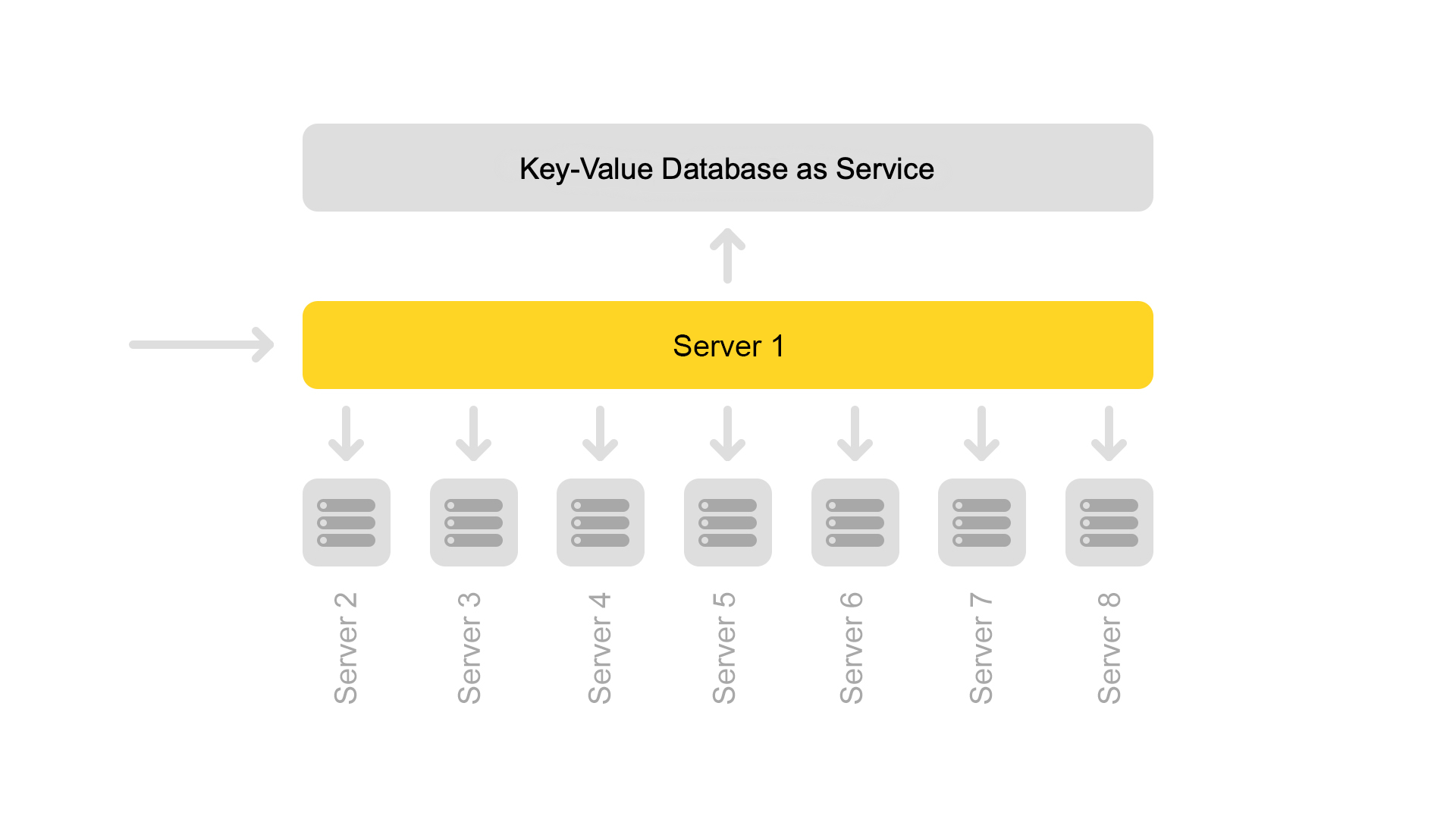
To transfer data, we introduced universal keys for documents. Now the situation is impossible when the content from another document is returned for one key.
But the transition to another architecture is not yet complete. Now we want to get rid of the dedicated snippet server. And then generally move away from the cluster structure. This will allow us to continue to scale easily. An added bonus is significant iron savings.
And now to the scary stories with a happy ending. Consider several cases of server unavailability.
Terrible happened: one server is unavailable
Let's say one server is unavailable. Then the other servers in the cluster may continue to respond, but the search results will be incomplete.
Through a status check, neighboring servers understand that one is unavailable. Therefore, to maintain completeness, all the servers in the cluster respond to the / ping request to the balancer that they are also unavailable. It turns out that all the servers in the cluster died (which is not so). This is the main drawback of our cluster scheme - so we want to get away from it.
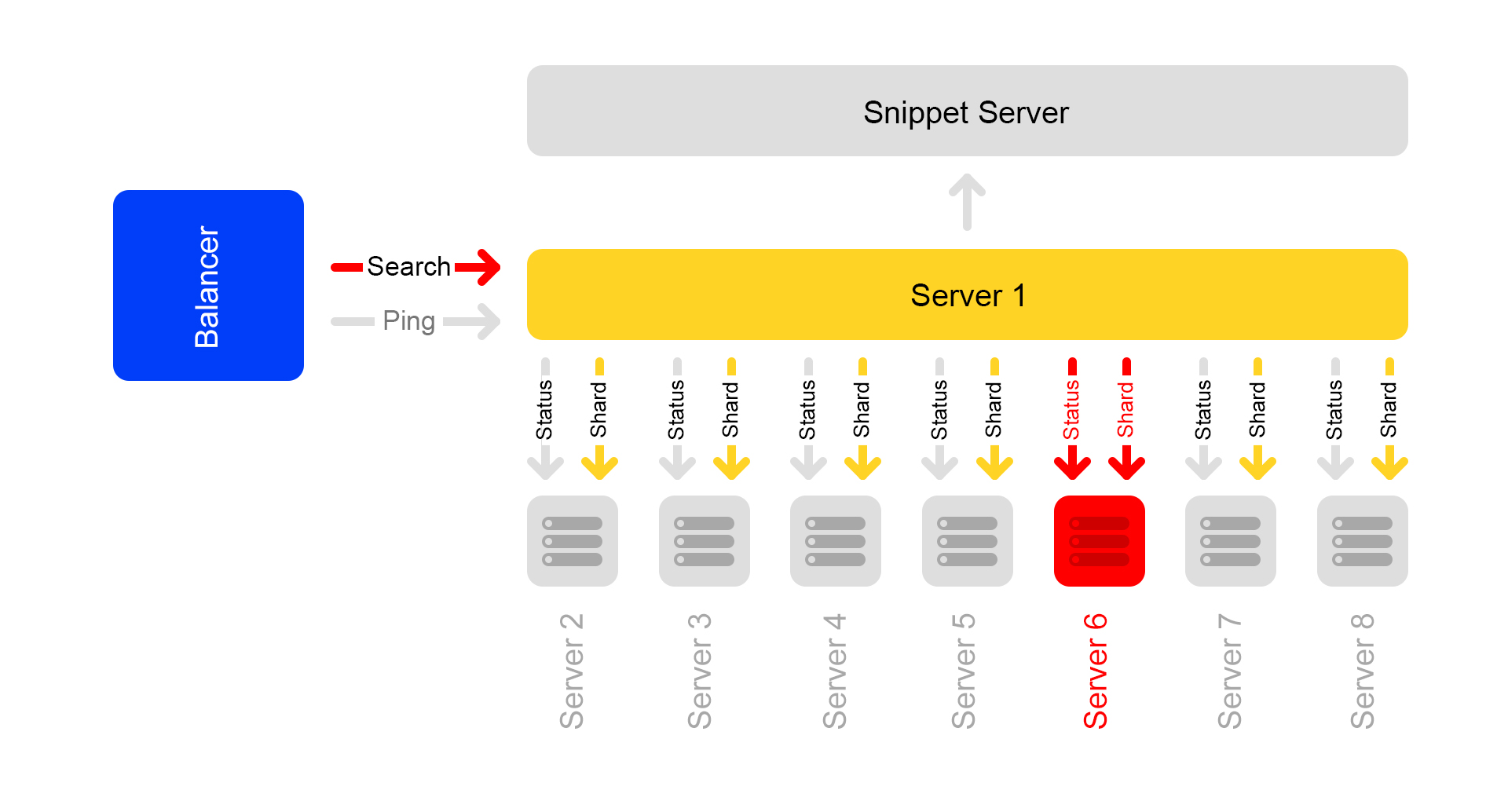
Requests that ended with an error, the balancer asks again on other servers.
Also, the balancer stops sending user traffic to dead servers, but continues to check their status.
When the server becomes available, it begins to respond to / ping . As soon as normal responses to pings from dead servers begin to arrive, balancers begin to send user traffic there. The cluster is restored, cheers.
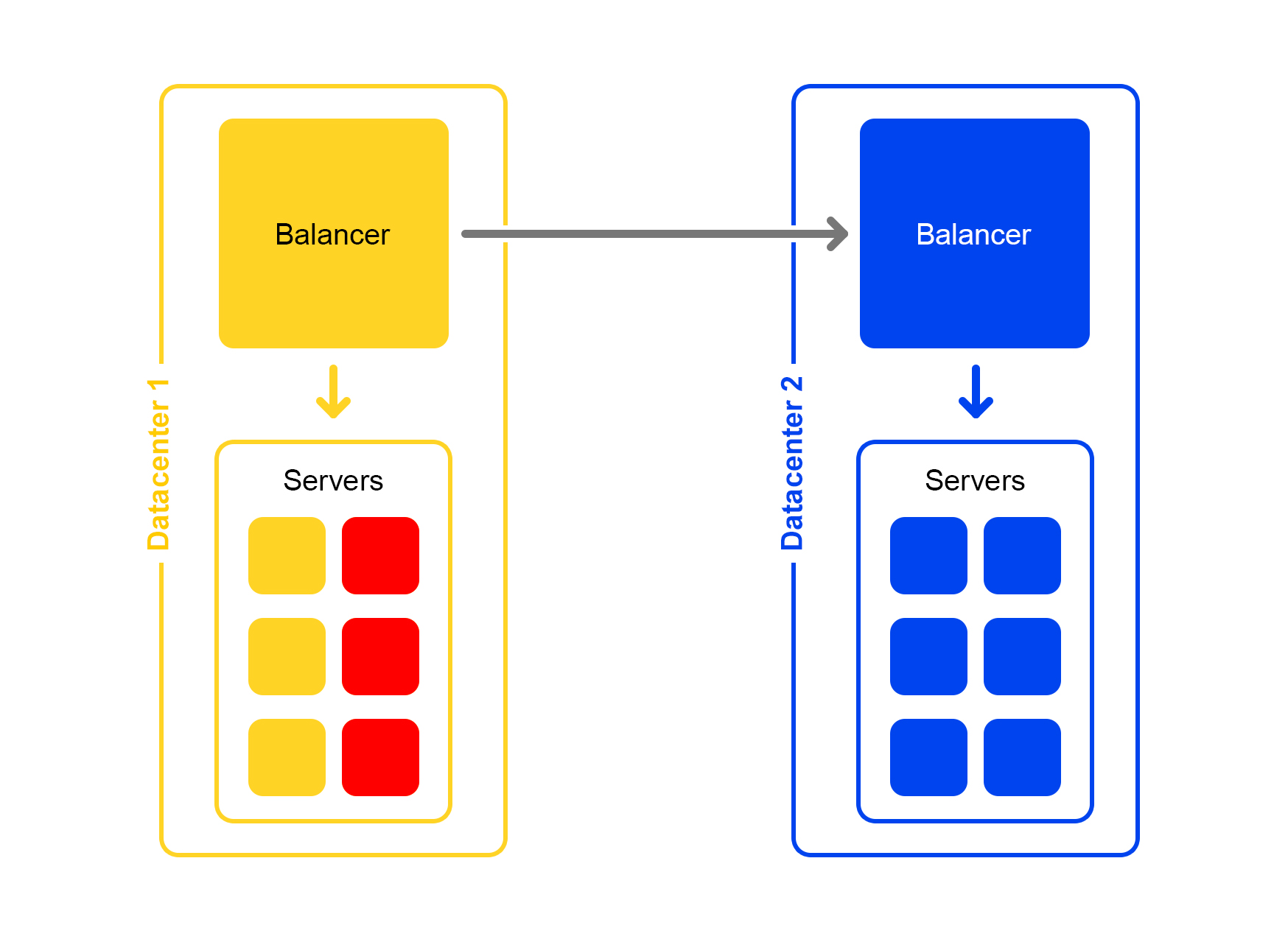
Even worse: many servers unavailable
A significant part of the servers in the data center is cut down. What to do, where to run? The balancer comes to the rescue again. Each balancer constantly keeps in memory the current number of live servers. He always considers the maximum amount of traffic that the current data center can handle.
When many servers in the data center fall, the balancer understands that this data center cannot process all the traffic.
Then the excess traffic starts randomly distributed to other data centers. Everything works, everyone is happy.
How we do it: release releases
Now about how we publish the changes made to the service. Here we went along the path of simplifying processes: rolling out a new release is almost completely automated.
When a certain number of changes is accumulated in the project, a new release is automatically created and its assembly is launched.
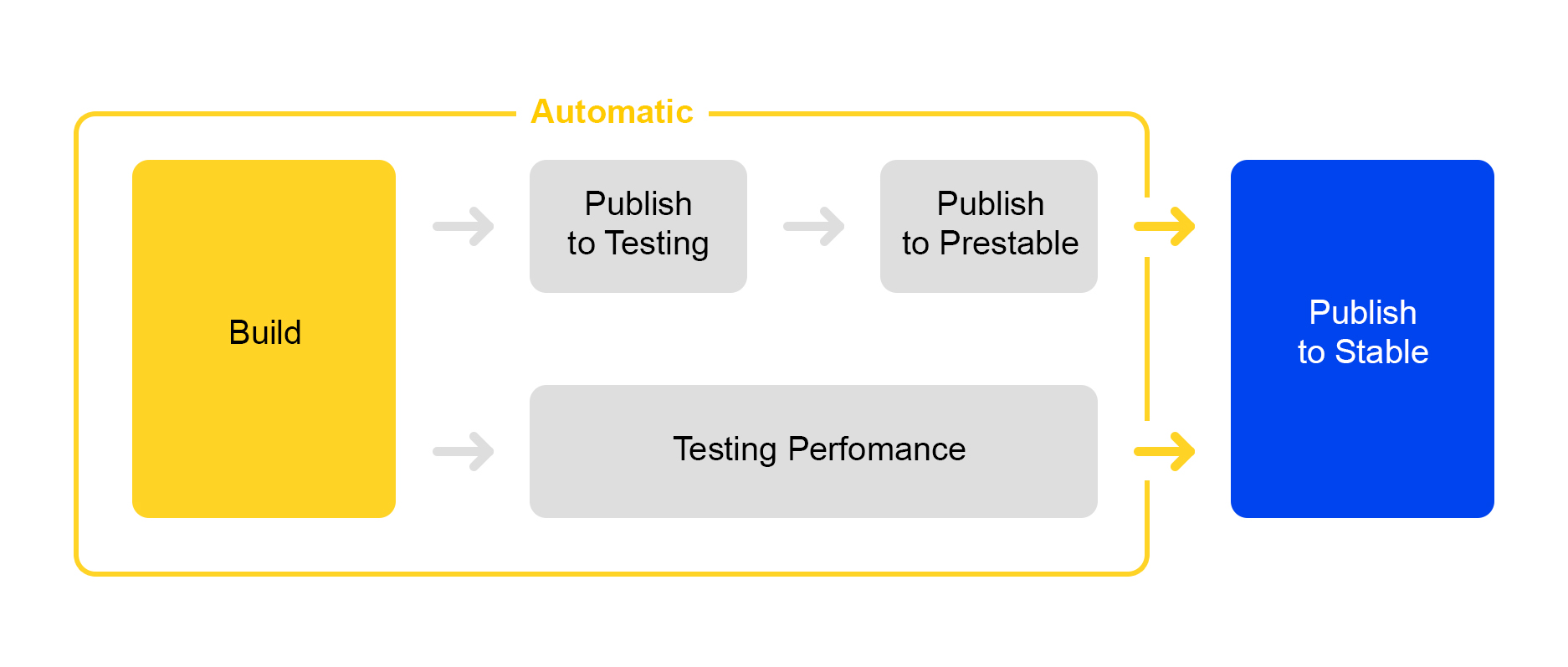
Then the service is rolled out to testing, where stability is checked.
At the same time, automatic performance testing is launched. He is engaged in a special service. I will not talk about him now - his description is worthy of a separate article.
If the publication in testing is successful, the publication of the release in prestable automatically starts. Prestable is a special cluster where normal user traffic is directed. If it returns an error, the balancer does a reboot in production.
In prestable, response times are measured and compared to the previous release in production. If everything is fine, then the person connects: checks the graphs and the results of load testing and then starts rolling out to production.
All the best for the user: A / B testing
It is not always obvious whether changes in the service will bring real benefits. To measure the usefulness of change, people came up with A / B testing. I’ll tell you a little how this works in Yandex.Market search.
It all starts with the addition of a new CGI parameter that includes new functionality. Let our parameter be: market_new_functionality = 1 . Then, in the code, enable this functionality with the flag:
If (cgi.experiments.market_new_functionality) { // enable new functionality }
New functionality rolls out in production.
There is a dedicated service for automating A / B testing, which is described in detail here . An experiment is created in the service. The share of traffic is set, for example, 15%. Interest is set not for requests, but for users. The time of the experiment, for example, a week, is also indicated.
Several experiments can be started at the same time. In the settings, you can specify whether intersection with other experiments is possible.
As a result, the service automatically adds the argument market_new_functionality = 1 to 15% of users. He also automatically calculates the selected metrics. After the experiment, analysts look at the results and draw conclusions. Based on the findings, a decision is made to roll out in production or finalize.
Market's nimble hand: production testing
It often happens that you need to check the operation of new functionality in production, but there is no certainty how it will behave in “combat” conditions under heavy load.
There is a solution: flags in CGI parameters can be used not only for A / B testing, but also to test new functionality.
We made a tool that allows you to instantly change the configuration on thousands of servers without exposing the service to risks. It is called "Stop Crane." The original idea was to quickly turn off some functionality without layout. Then the tool expanded and became more complex.
The scheme of the service is presented below:
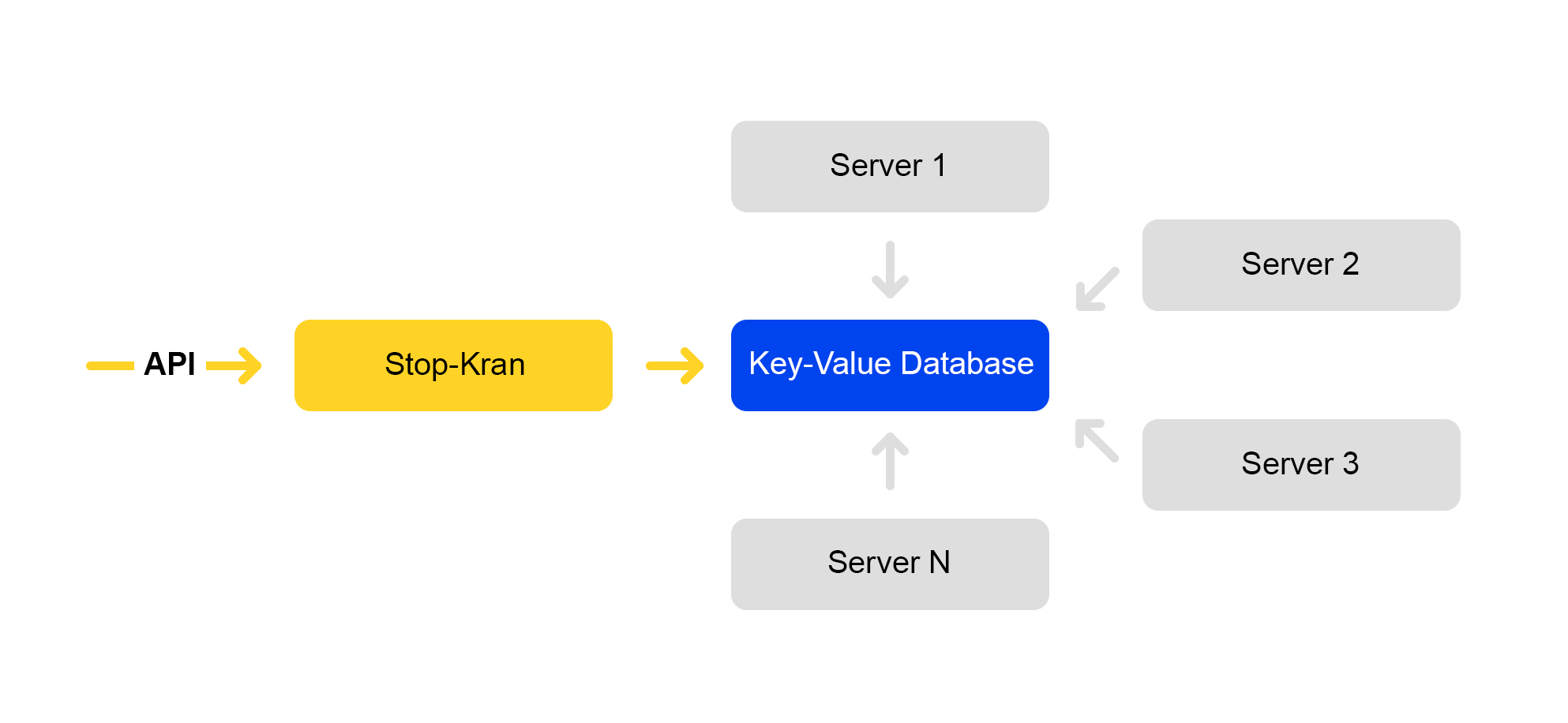
The API sets flag values. The management service stores these values in a database. All servers go to the database once every ten seconds, pump out the values of the flags and apply these values to each request.
In Stop Crane, you can set two kinds of values:
1) Conditional expressions. Apply when one of the values is executed. For example:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
The value “3” will be applied when the request is processed in DC1 location. And the value is “4” when the request is processed on the second cluster for the site beru.ru.
2) Unconditional values. They are used by default if none of the conditions is met. For example:
value, value!
If the value ends with an exclamation point, it is given a higher priority.
The parser of the CGI parameters parses the URL. It then applies the values from the stop tap.
Values with the following priorities apply:
- Higher priority from stop tap (exclamation mark).
- The value from the query.
- The default value is from the stop tap.
- The default value in the code.
There are a lot of flags that are indicated in conditional values - they are enough for all the scenarios known to us:
- Data center.
- Environment: production, testing, shadow.
- Venue: market, beru.
- Cluster number.
With this tool, you can enable new functionality on a group of servers (for example, only in one data center) and test the functionality of this functionality without any particular risk to the entire service. Even if you seriously made a mistake somewhere, everything started to fall and the whole data center went down, balancers will redirect requests to other data center. End users will not notice anything.
If you notice a problem, you can immediately return the previous value of the flag, and the changes will be rolled back.
This service has its drawbacks: the developers love it very much and often try to push all the changes into the Stop Crane. We are trying to combat misuse.
The Stop Crane approach works well when you already have a stable code, ready to be rolled out in production. At the same time, you still have doubts, and you want to check the code in "combat" conditions.
However, the stopcock is not suitable for testing during development. For developers, there is a separate cluster called the “shadow cluster”.
Covert Testing: Shadow Cluster
Requests from one of the clusters are duplicated to the shadow cluster. But the balancer completely ignores the responses of this cluster. The scheme of his work is presented below.
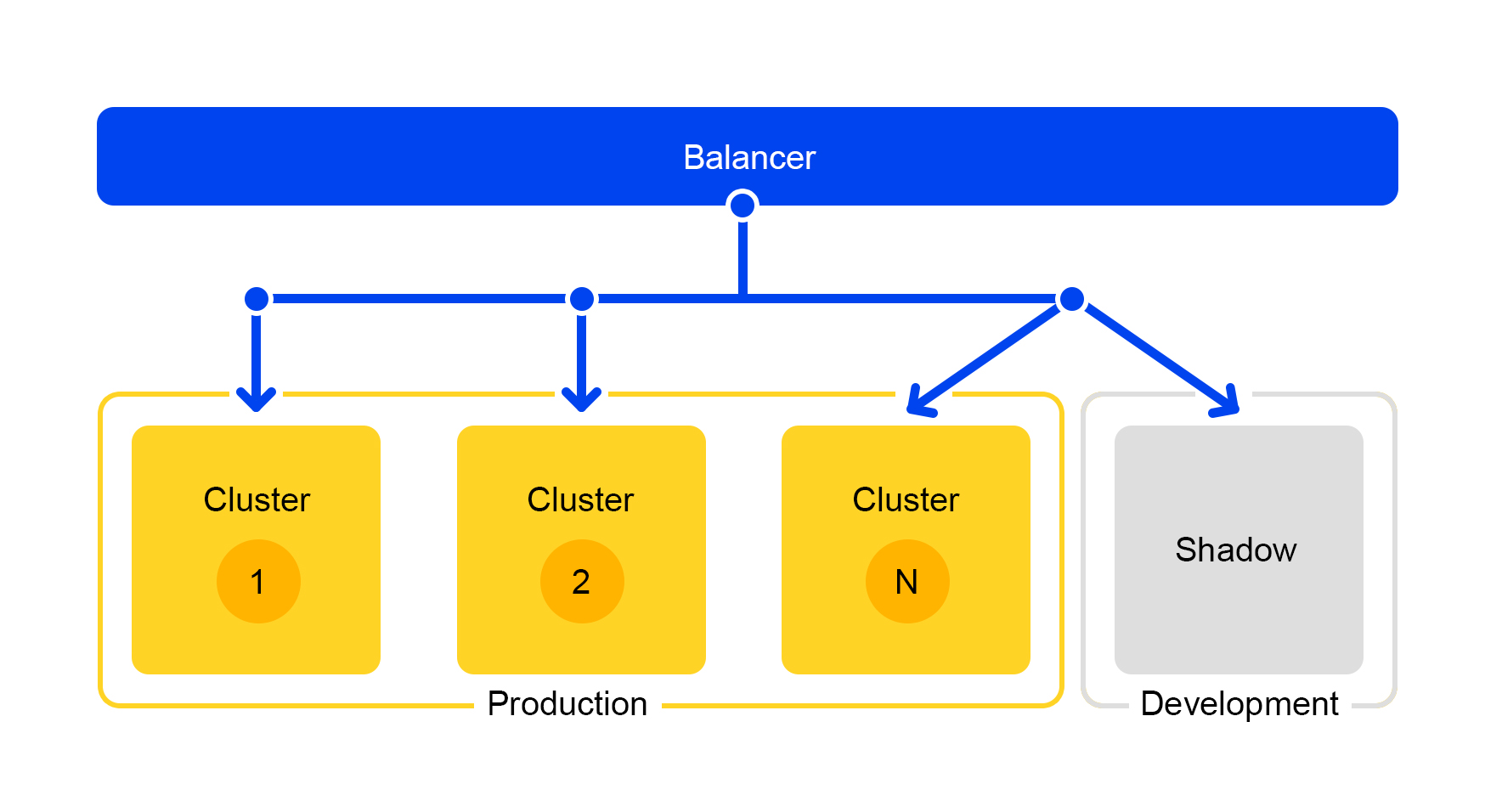
We get a test cluster that is in real “combat” conditions. Normal user traffic flies there. The hardware in both clusters is the same, so you can compare performance and errors.
And since the balancer completely ignores the answers, the end users will not see the responses from the shadow cluster. Therefore, it is not scary to make a mistake.
conclusions
So, how did we build the Market search?
So that everything goes smoothly, we separate the functionality into separate services. So you can scale only those components that we need and make the components simpler. It is easy to give a separate component to another team and share responsibilities for working on it. And significant savings in iron with this approach is an obvious plus.
The shadow cluster also helps us: you can develop services, test them in the process and at the same time not bother the user.
Well and check in production, of course. Need to change the configuration on a thousand servers? Easy, use a stop crane. So you can immediately roll out a ready-made complex solution and roll back to a stable version if problems arise.
I hope I was able to show how we make the Market fast and stable with an ever-growing base of offers. How to solve server problems, deal with a huge number of requests, improve service flexibility and do this without interrupting work processes.