
As the saying goes, if you are not ashamed of your old code, then you do not grow up as a programmer - and I agree with this opinion. I started programming for entertainment more than 40 years ago, and 30 years ago professionally, so I got a lot of mistakes. As a professor of computer science, I teach my students how to learn from mistakes - theirs, mine, strangers. I think it's time to talk about my mistakes so as not to lose modesty. I hope someone will find it useful.
Third place - Microsoft C compiler
My school teacher believed that Romeo and Juliet should not be considered a tragedy, because the heroes did not have tragic guilt - they just behaved stupidly, as teenagers should. Then I did not agree with him, but now I see in his opinion a rational kernel - especially in connection with programming.
By the time I finished the second year of MIT, I was young and inexperienced, both in life and in programming. In the summer, I did my internship at Microsoft, in the team of the C compiler. At first I was engaged in a routine such as profiling support, and then I was entrusted with the work on the most fun (as I thought) part of the compiler - backend optimization. In particular, I had to improve the x86 code for branching statements.
Determined to write the best machine code for every possible case, I rushed into the pool with my head. If the density of distribution of values was high, I entered them in the transition table . If they had a common divisor, I used it to make the table denser (but only if the division could be done using a bit shift ). When all the values were powers of two, I performed another optimization. If the set of values did not satisfy my conditions, I split it into several optimizable cases and used the already optimized code.
It was a nightmare. After many years, they told me that the programmer who inherited my code hated me.

Lesson learned
As David Patterson and John Hennessy write in the book Computer Architecture and Computer Systems Design, one of the main principles of architecture and development is that in general, everything works as quickly as possible.
Accelerating common cases will increase productivity more efficiently than optimizing rare cases. Ironically, common cases are often simpler than rare. This logical advice implies that you know which case to consider common - and this is only possible through careful testing and measurement.
In my defense, I can say that I tried to figure out what the branch operators looked like in practice (for example, how many branches existed and how the constants were distributed), but in 1988 this information was not available. However, I should not have added special cases whenever the current compiler could not generate the optimal code for the artificial example that I came up with.
I needed to call an experienced developer and with him to think what were the common cases, and deal specifically with them. I would write less code, but that’s even good. As Stack Overflow founder Jeff Atwood wrote, the programmer’s worst enemy is the programmer:
I know that you have the best of intentions, as we all have. We create programs and love to write code. So we are arranged. We think that any problem can be solved with tape, a homemade crutch and a pinch of code. No matter how painful it is for coders to admit this, the best code is that code that does not exist. Each new line needs debugging and support, it needs to be understood. When adding new code, you should do it with reluctance and disgust, because all other options have been exhausted. Many programmers write too much code, making it our enemy.
If I wrote simpler code that covered common cases, then it would be much easier to update if necessary. I left a mess that no one wanted to mess with.

Second place: social media advertising
When I worked at Google on social media advertising (remember Myspace?), I wrote in C ++ something like this:
for (int i = 0; i < user->interests->length(); i++) { for (int j = 0; j < user->interests(i)->keywords.length(); j++) { keywords->add(user->interests(i)->keywords(i)) { } }
Programmers may immediately see the error: the last argument should be j, not i. Unit testing did not reveal an error, nor did my reviewer notice it. A launch was made, and one night my code went to the server and crashed all the computers in the data center.
Nothing terrible happened. None of them broke, because before the global launch, the code was tested within the same data center. Unless the SRE engineers quit playing billiards for a while and made a small rollback. The next morning I received an email with a crash dump, fixed the code and added unit tests that would reveal an error. Since I followed the protocol - otherwise my code would simply not have run - there were no other problems.

Lesson learned
Many are convinced that such a major mistake is necessarily the culprit of the dismissal, but this is not so: firstly, all programmers are wrong, and secondly, they rarely make one mistake twice.
In fact, I have a familiar programmer - a brilliant engineer, who was fired for one single mistake. After that, he was hired by Google (and soon promoted) - he honestly talked about the mistake made in the interview, and she was not considered fatal.
Here's what Thomas Watson, the legendary head of IBM, has to say:
A government order worth about a million dollars was announced. IBM Corporation - or rather, personally Thomas Watson Sr. - really wanted to get it. Unfortunately, the sales representative could not do this, and IBM lost the tender. The next day, this officer came to Mr. Watson’s office and put an envelope on his desk. Mr. Watson did not even look into him - he was waiting for an employee and knew that this was a letter of resignation.
Watson asked what went wrong.
The sales representative described in detail the progress of the tender. He called the mistakes that could have been avoided. Finally, he said: “Mr. Watson, thank you for letting me explain. I know how much we needed this order. I know how important he was, ”and was about to leave.
Watson went up to him at the door, looked into his eyes and returned the envelope with the words: “How can I let you go? I just invested a million dollars in your education.
I have a T-shirt that says: “If you really learn from mistakes, then I’m already a master.” In fact, in terms of errors, I am a Doctor of Science.
First Place: App Inventor API
Really terrible mistakes affect a huge number of users, become public, are long fixed and made by those who could not allow them. My biggest mistake satisfies all these criteria.
The worse the better
I read Richard Gabriel 's essay about this approach in the nineties as a graduate student, and I like it so much that I ask it to my students. If you do not remember it well, refresh your memory, it is small. In this essay, the desire to “do it right” and the approach “the worse the better” are contrasted in many ways, including simplicity.
As it should: the design should be easy to implement and interface. Simplicity of the interface is more important than simplicity of implementation.
The worse, the better: the design should be simple in implementation and interface. Simplicity of implementation is more important than simplicity of the interface.
Forget about it for a moment. Unfortunately, I forgot about it for many years.
App inventor
While working at Google, I was part of the App Inventor team, an online development environment with drag and drop support for beginner Android developers. It was 2009, and we were in a hurry to release the alpha version in time, so that in the summer we could hold master classes for teachers who could use the learning environment in the fall. I volunteered to implement sprites, nostalgic for how I once wrote games on TI-99/4. For those who are not in the know: a sprite is a two-dimensional graphic object that can move and interact with other program elements. Examples of sprites are spaceships, asteroids, balls and rackets.
We implemented the object-oriented App Inventor in Java, so there is just a bunch of objects. Since balls and sprites behave very similarly, I created an abstract sprite-class with properties (fields) X, Y, Speed (speed) and Heading (direction). They had the same methods for detecting collisions, bouncing off the screen border, etc.
The main difference between the ball and the sprite is exactly what is drawn - a filled circle or raster. Since I first implemented sprites, it was logical to specify the x- and y-coordinates of the upper left corner of the place where the image was located.

When the sprites started working, I decided that you could implement ball objects with very little code. The only problem was that I went the simplest way (from the point of view of the implementer), indicating the x- and y-coordinates of the upper left corner of the contour surrounding the ball.
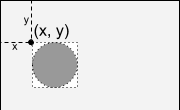
In fact, it was necessary to indicate the x- and y-coordinates of the center of the circle, as any mathematics textbook and any other source mentioning circles teach.
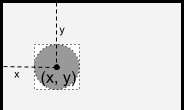
Unlike my past mistakes, not only my colleagues, but also millions of App Inventor users suffered from this. Many of them were children or completely new to programming. They had to perform many unnecessary actions when working on each application in which the ball was present. If I remember the rest of my mistakes with a laugh, then this one throws me into a sweat today.
I finally patched this error only recently, ten years later. “Patched”, but not “fixed”, because as Joshua Bloch says, the APIs are eternal. Unable to make changes that would affect existing programs, we added the OriginAtCenter property with false in old programs and true in all future ones. Users can ask a legitimate question to whom it occurred to anyone to locate a reference point somewhere other than the center. To whom? One programmer who was too lazy to create a normal API ten years ago.
Lessons learned
When working on an API (which almost every programmer sometimes has to do), you should follow the best tips outlined in Joshua Bloch’s video “ How to create a good API and why it is so important ” or in this short list :
- The API can be of great benefit to you, as well as great harm . A good API creates loyal customers. Bad becomes your eternal nightmare.
- Public APIs, like diamonds, are eternal . Try your best: there is no other chance to do everything as it should.
- Schedules for the API should be short - one page with class and method signatures and descriptions that take no more than a line. This will allow you to easily restructure the API, if the first time it comes out not perfect.
- Describe use cases before you implement the API and even work on its specification. This way you avoid the implementation and specification of a fully non-functional API.
If I wrote at least a small synopsis with an artificial script, most likely I would have identified a mistake and corrected it. If not, then one of my colleagues would definitely do it. Any decision that has far-reaching consequences must be considered for at least a day (this applies not only to programming).
The title of Richard Gabriel’s essay, “The Worse, the Better,” indicates the advantage that comes first to the market — even with an imperfect product — while someone else has been pursuing the ideal for ages. Thinking about the sprite code, I understand that I didn’t even have to write more code to do everything as it should. Like it or not, I was grossly mistaken.
Conclusion
Programmers make mistakes every day - whether it's writing code with bugs or reluctance to try something that will increase their skill and productivity. Of course, you can be a programmer and not allowing such serious mistakes as I did. But to become a good programmer without realizing your mistakes and not learning from them is impossible.
I constantly meet students who think that they make too many mistakes and therefore are not designed for programming. I know how common the imposter syndrome is in IT. I hope you learn the lessons I have listed - but remember the main one: each of us makes mistakes - shameful, funny, scary. I will be surprised and upset if in the future I don’t have enough material to continue the article.