
A bit of history: HTTP / 1.1
In 1997, HTTP version 1.1 text exchange protocol gained its RFC. At that time, the protocol was used by browsers for several years, and the new standard lasted another fifteen. The protocol worked only on a request-response basis and was intended primarily for transmitting textual information.
HTTP was designed to work on top of the TCP protocol, which guarantees reliable delivery of packets to the destination. TCP is based on establishing and maintaining a reliable connection between endpoints and segmenting traffic. Segments have their own sequence number and checksum. If suddenly one of the segments does not come or comes with the wrong checksum, the transmission will stop until the lost segment is restored.
In HTTP / 1.0, the TCP connection was closed after each request. It was extremely wasteful since Establishing a TCP connection (3-Way-Handshake) is not a quick process. HTTP / 1.1 introduced the keep-alive mechanism, which allows you to reuse a single connection for multiple requests. However, since it can easily become a bottleneck, multiple TCP / IP connections to the same host are allowed in different HTTP / 1.1 implementations. For example, in Chrome and in recent versions of Firefox, up to six connections are allowed.

Encryption was also supposed to be left to other protocols, and for this, the TLS protocol was used over TCP, which reliably protected data, but further increased the time required to establish a connection. As a result, the handshake process began to look like this:
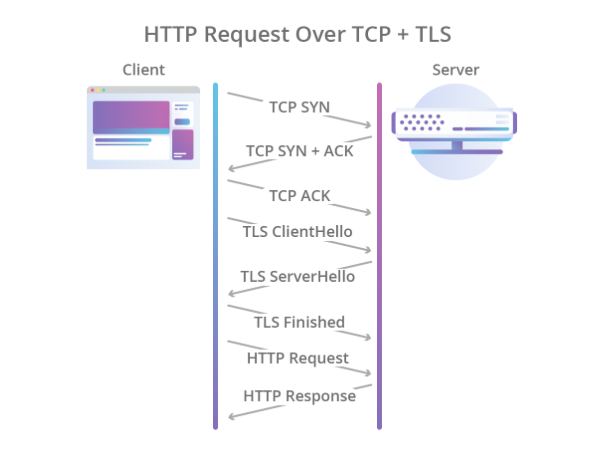
Cloudflare illustration
Thus, HTTP / 1.1 had a number of problems:
- Slow connection setup.
- One TCP connection is used for one request, which means that the rest of the requests must either find another connection, or wait until the current request releases it.
- Only the pull model is supported. There is nothing in the standard about server-push.
- Headings are transmitted in text.
If server-push is somehow implemented using the WebSocket protocol, then the rest of the problems had to be dealt with more radically.
A bit of modernity: HTTP / 2
In 2012, work on the SPDY protocol (pronounced "speed") began in the bowels of Google. The protocol was designed to solve the basic problems of HTTP / 1.1 and at the same time had to maintain backward compatibility. In 2015, the IETF working group introduced the HTTP / 2 specification based on the SPDY protocol. Here are the differences in HTTP / 2:
- Binary serialization.
- Multiplexing multiple HTTP requests into a single TCP connection.
- Server-push out of the box (without WebSocket).
The protocol was a big step forward. It greatly outperforms the first version and does not require the creation of several TCP connections: all requests to one host are multiplexed into one. That is, in one connection there are several so-called streams, each of which has its own ID. The bonus is a boxed server-push.
However, multiplication leads to another cornerstone problem. Imagine that we asynchronously execute 5 requests to one server. When using HTTP / 2, all these requests will be executed within the same TCP connection, which means that if one of the segments of any request is lost or arrives incorrectly, the transmission of all requests and responses will stop until the lost segment is restored. Obviously, the worse the connection quality, the slower HTTP / 2 works. According to Daniel Stenberg , in a situation where lost packets make up 2% of all, HTTP / 1.1 in a browser performs better than HTTP / 2 due to the fact that it opens 6 connections, and not one.
This problem is called “head-of-line blocking” and, unfortunately, it is not possible to solve it using TCP.
Illustration of Daniel Steinberg
As a result, the developers of the HTTP / 2 standard did a great job and did almost everything that could be done at the application level of the OSI model. It's time to go down to the transport level and invent a new transport protocol.
We need a new protocol: UDP vs TCP
It quickly became clear that to introduce a completely new transport layer protocol is an unsolvable task in today's realities. The fact is that the glands or middle-boxes (routers, firewalls, NAT-servers ...) know about the transport level, and to teach them something new is an extremely difficult task. In addition, support for transport protocols is wired into the kernel of operating systems, and kernels also change not so very willingly.
And here it would be possible to give up and say "We, of course, will invent a new HTTP / 3 with preference and courtesans, but it will be implemented in 10-15 years (after about this time most of the pieces of iron will be replaced)", but there is one more not the most obvious option: use the UDP protocol. Yes, yes, that same protocol, according to which we threw files on a LAN at the end of the nineties and the beginning of zero. Almost all of today's pieces of iron know how to work with it.
What are the advantages of UDP over TCP? First of all, we don’t have a transport level session that iron knows about. This allows us to determine the session on endpoints ourselves and to resolve conflicts that arise there. That is, we are not limited to one or several sessions (as in TCP), but we can create them as much as we need. Secondly, data transmission over UDP is faster than over TCP. Thus, in theory, we can break through today's speed ceiling achieved in HTTP / 2.
However, UDP does not guarantee reliable data transmission. In fact, we simply send packets, hoping that they will be received at the other end. Have not received? Well, no luck ... This was enough to transmit video for adults, but for more serious things you need reliability, which means you have to wind something else on top of UDP.
As in the case of HTTP / 2, work on creating a new protocol began at Google in 2012, that is, at about the same time as the start of work on SPDY. In 2013, Jim Roskind introduced the QUIC protocol (Quick UDP Internet Connections) to the general public, and already in 2015 Internet Draft was introduced to standardize the IETF. Already at that time, the protocol developed by Roskind on Google was very different from the standard one, so the Google version was called gQUIC.
What is QUIC
Firstly, as already mentioned, this is a wrapper over UDP. QUIC-connection rises on top of UDP, in which, by analogy with HTTP / 2, several streams may exist. These streams exist only on endpoints and are served independently. If the packet loss occurred in one stream, it will not affect the others in any way.
Illustration of Daniel Steinberg
Secondly, encryption is now implemented not at a separate level, but included in the protocol. This allows you to establish a connection and exchange public keys in a single handshake, and also allows you to use the tricky 0-RTT handshake mechanism and generally avoid delays in shaking hands. In addition, individual data packets can now be encrypted. This allows not to wait for the completion of data reception from the stream, but to decrypt the received packets independently. This mode of operation was not possible at all in TCP, because TLS and TCP worked independently of each other, and TLS could not know what pieces TCP data would chop into. And therefore, I could not prepare my segments so that they fit into the TCP segments one to one and could be decrypted independently. All these improvements allow QUIC to lower latency compared to TCP.

Thirdly, the concept of light streams allows you to untie the connection from the client's IP address. This is important, for example, when a client switches from one Wi-Fi access point to another, changing his IP. In this case, when using TCP, a lengthy process occurs during which existing TCP connections fall off in timeout and new connections are created from the new IP. In the case of QUIC, the client simply continues to send packets from the new IP with the old stream ID to the server. Because Stream ID is now unique and not reused, the server understands that the client has changed IP, sends the lost packets and continues communication to the new address.
Fourth, QUIC is implemented at the application level, not the operating system. This, on the one hand, allows faster changes to the protocol, as To get an update, just update the library, rather than wait for a new version of the OS. On the other hand, this leads to a strong increase in processor consumption.
And finally, the headlines. Header compression just refers to points that differ in QUIC and gQUIC. I see no reason to devote a lot of time to this, I can only say that in the version submitted for standardization, header compression was made as similar as possible to header compression in HTTP / 2. More details can be read here .
How much faster is it?
It's a difficult question. The fact is that while we do not have a standard, there is nothing special to measure. Perhaps the only statistics we have available - Statistics Google, which uses gQUIC in 2013 and in 2016 reported to the IETF , that about 90% of traffic coming to their servers from the Chrome browser, is now using QUIC. In the same presentation, they report that through gQUIC, pages load about 5% faster, and streaming video has 30% less freezes compared to TCP.
In 2017, a group of researchers led by Arash Molavi Kakhki published a large work on the study of gQUIC performance compared to TCP.
The study revealed several gQUIC weaknesses, such as instability to network packet mixing, unfairness in channel capacity and slower transfer of small (up to 10 kb) objects. The latter, however, can be compensated for using the 0-RTT. In all other cases investigated, gQUIC showed an increase in speed compared to TCP. It’s hard to talk about specific numbers. It is better to read the study itself or a short post .
Here it must be said that this data is specifically about gQUIC, and they are irrelevant for the standard being developed. What will happen for QUIC: so far, the mystery lies behind seven seals, but there is hope that the weaknesses identified by gQUIC will be taken into account and corrected.
A little future: what about HTTP / 3?
And here everything is crystal clear: the API will not change in any way. Everything will remain exactly the same as it was in HTTP / 2. Well, if the API remains the same, the transition to HTTP / 3 will have to be decided using the latest version of the library supporting transport via QUIC on the backend. True, for a long time you still have to keep fallback to older versions of HTTP, because the Internet is now not ready for a full switch to UDP.
Who is already supporting
Here is a list of existing QUIC implementations. Despite the lack of a standard, the list is not bad.
No browser currently supports QUIC in the release. Recently there was information that Chrome included HTTP / 3 support, but so far only in Canary.
Of the backends, HTTP / 3 only supports Caddy and Cloudflare , but so far experimentally. NGINX announced in late spring 2019 that they had begun work on HTTP / 3 support, but had not yet completed it.
What are the problems
We live in the real world, where not a single big technology can go to the masses without meeting resistance, and QUIC is no exception.
Most importantly, you need to somehow explain to the browser that “https: //” is no longer a fact that leads to the 443rd TCP port. There may not be TCP at all. To do this, use the Alt-Svc header. It allows the browser to be informed that this website is also accessible on such and such protocol at such and such address. In theory, this should work like a clock, but in practice, we come across the fact that UDP can be, for example, disabled on a firewall in order to avoid DDoS attacks.
But even if UDP is not prohibited, the client may be behind a NAT router that is configured to hold a TCP session by IP address, as we use UDP, in which there is no hardware session, NAT will not hold the connection, and the QUIC session will always be terminated .
All these problems are connected with the fact that UDP was not previously used for the transfer of Internet content, and the hardware manufacturers could not have foreseen that this would ever happen. In the same way, admins still do not really understand how to properly configure their networks for QUIC. This situation will slowly change, and, in any case, such changes will take less time than the introduction of a new transport layer protocol.
In addition, as already described, QUIC greatly increases processor utilization. Daniel Stenberg rated growth on the processor up to three times.
When HTTP / 3 Comes
They want to adopt the standard by May 2020, but given that the documents scheduled for July 2019 remain unfinished, we can say that the date is most likely pushed back.
Well, Google has been using its implementation of gQUIC since 2013. If you look at the HTTP request that is sent to the Google search engine, you can see this:

conclusions
QUIC now looks like a rather crude, but very promising technology. Considering that over the past 20 years, all optimizations of the transport layer protocols have mainly concerned TCP, QUIC, which in most cases wins in performance, now looks extremely good.
However, there are still unsolved problems that must be addressed in the next few years. The process may be delayed due to the fact that hardware is involved, which no one likes to update, but nevertheless, all problems look quite solvable, and sooner or later we will all have HTTP / 3.
The future is not far off!