
In this article I will tell you how I tried to participate in the development of some major open source project, I hated myself, and then automated the routine and learned to enjoy life. Details - under the cut.
Why is this even necessary?
Typically, developers want to participate in the open source community for several reasons. Here are some (and probably not all) of them:
- in gratitude for the opportunity to use this and other programs for free
- gaining new experience
- to pump your resume
I was always primarily attracted by the opportunity to learn something new, to absorb the best practices in software development, but everything else is no less pleasant appendage in this process.
OK, I'm in, where do I start?
The first thing to do is find a task to work on. You are a real lucky one, if you needed to modify some library for your work needs - start a task, discuss with the owners and start implementation! Otherwise, you can refer to the list of open tasks on the project page and pick up something for yourself. Finding the right one is no less important than its implementation, and here it is not so simple. Even if you are an experienced engineer, it may be useful to start with simpler tasks, familiarize yourself with the code base, accepted development processes, and only then take on a bigger feature.
How to find tasks for beginners?
Some time ago, github began to show suitable tasks for beginners.
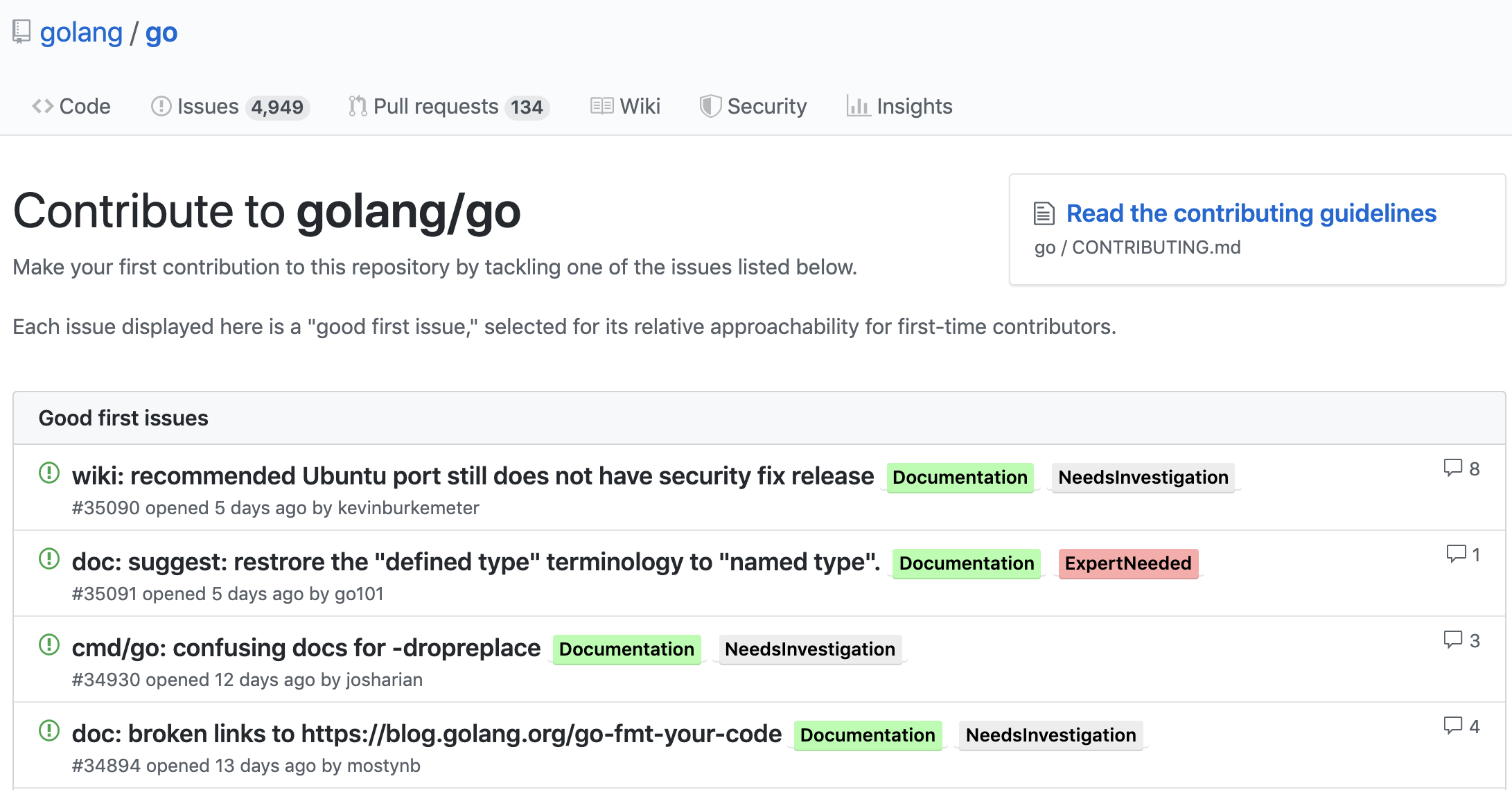
Having settled on these "tools", my usual day began to look like this - I opened the list of projects that I wanted to work on (to keep them handy, I marked them all with little stars), went to the above section or searched through the desired tags through the search, simultaneously searching those that are used in this particular project. Needless to say, going around 40-60 repositories cost a huge heap of strength and quickly bored me. In the process, I became irritable, lost my patience and abandoned this thing. On one of these days, I realized that I could automate the search process and proceeded to compile a TOR.
Requirements
- The task must be open
- The task is not assigned to anyone
- The task should be labeled with simplicity and openness to the community.
- Task should not be too old
After that, I began to analyze different repositories for the labels used. It turned out that there is a huge bunch of different labels, some of which are unique to specific repositories / organizations. Case-sensitive, I compiled a list of ~ 60 tags
Solution Development
As a tool, I decided to use Kotlin, which was already familiar to me, and implemented the following algorithm: go through all the repositories marked with an asterisk, get all the tasks that fit the requirements, sort by the date of change, discard too old ones and display them. The resulting list is divided by timestamps - for today, for yesterday, for the past week, for the month and everything else - thanks to this it has become much more convenient to use the program on a regular basis. I decided that at the first stage the application will be a console utility, so the output goes just to stdout.
I wrapped the result in a docker image, expecting that a person is more likely to have docker installed than JRE. The utility does not store any state, so each launch will execute the entire algorithm, and the spent container can be safely removed from the system.
Here's how the program works:

Request Limit
Accessing the third-party API is a classic example of an io-intensive task, so it was naturally decided to start loading data into several streams. Through trial and error, I met the limitations of the Github API. Firstly, with a large number of threads, the anti-abuse check on the Github side was triggered and I had to stop at 10 threads by default, with the possibility of configuration via input arguments.
Secondly, there is a limit on the number of requests - they can be made no more than 5000 per hour. With this restriction, everything is much more complicated, since when passing multiple tags to a search query, Github puts a logical 'And' between them and, given the number of tags in the list, it will find nothing with almost 100% probability. Faced with a big waste of calls to the API, I began to make an additional request for all the tags that are in the project, take the intersection with my list and piece by piece request tasks only for these tags. By adding 1 request to each repository, I got rid of 50-55 extra requests (the more tags the program supports, the more extra requests) for tasks on tags that do not exist for the repository.
However, for some users this optimization may not be enough. According to a superficial assessment, the current solution allows you to bypass 1000 repositories (there is also a strict restriction in the code), expecting that on average there are 4 simple labels in each repository. No one has encountered such a restriction so far, but the idea of a solution is in the backlog. Everything is simple here - storing the state, caching responses, in especially difficult cases, slowly bypass in the background.
How to find repositories?
If you aren’t such an active Github user yet, or if you don’t use the stars functionality, here are some tips for finding suitable repositories:
- Walk through the technologies that you use on your projects, maybe some of them are presented on Github
- Use the section of popular trends
- Use the awesome-lists repository for topics of interest to you.
Launch
To start, you will need:
- have docker installed on the computer
- write API token, you can do it on the corresponding Github settings page
- start the container by passing its access token through the parameters
docker pull igorperikov/mighty-watcher:latest docker run -e TOKEN={} --rm igorperikov/mighty-watcher:latest
Other settings (filter by language, level of parallelism, blacklist of repositories) can be found on the project page. Link to the project .
If you are missing some tags in the project - create a PR or write me in a personal, I will add.