- Adding to the file names information about the version of the data contained in them (usually in the form of a hash of the data in the files).
- Setting HTTP headers
Cache-Control: max-age
andExpires
, which control the caching time of materials (which eliminates the re-validation of the relevant materials for visitors returning to the resource).

All the tools for building projects that I know support adding to the hash file names their contents. This is done using a simple configuration rule (like what is shown below):
filename: '[name]-[contenthash].js'
Such widespread support for this technology has led to the fact that this practice has become extremely common.
Web project performance experts also recommend using code separation techniques. These techniques allow breaking JavaScript code into separate bundles. Such bundles can be downloaded by the browser in parallel, or even only when they become necessary, at the request of the browser.
One of the many advantages of code separation, in particular, related to the best caching techniques, is that the changes made to a separate file with the source code do not lead to invalidation of the cache of the entire bundle. In other words, if a security update was released for the npm package created by the developer “X”, and the contents of
node_modules
fragmented by developers, then only the fragment containing the packages created by “X” will have to be changed.
The problem here is that if all this is combined, then this rarely leads to an increase in the efficiency of long-term data caching.
In practice, changes to one of the source code files almost always result in invalidation of more than one output file of the package assembly system. And this is precisely due to the fact that hashes have been added to the file names that reflect the versions of the contents of these files.
File Name Versioning Issue
Imagine that you have created and deployed a website. You have used code splitting, as a result, most of the JavaScript code for your site is loaded on request.
In the next dependency diagram, you can see the code base entry point - the root fragment of
main
, as well as three dependency fragments loaded asynchronously -
dep1
,
dep2
and
dep3
. There is also a
vendor
fragment that contains all the site dependencies from
node_modules
. All file names, in accordance with caching guidelines, include hashes of the contents of these files.
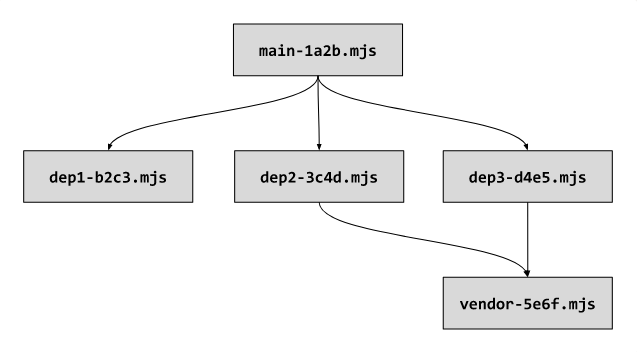
Typical JavaScript module dependency tree
Since
dep2
and
dep3
import modules from the
vendor
fragment, then at the top of their code generated by the project
dep3
, we will most likely find import commands that look something like this:
import {...} from '/vendor-5e6f.mjs';
Now let's think about what will happen if the contents of the
vendor
fragment change.
If this happens, the hash in the name of the corresponding file will also change. And since the link to the name of this file is in the import commands for
dep2
and
dep3
, then it will be necessary for these import commands to change:
-import {...} from '/vendor-5e6f.mjs'; +import {...} from '/vendor-d4a1.mjs';
However, since these import commands are part of the contents of the
dep2
and
dep3
, changing them means that the hash of the contents of the
dep2
and
dep3
files
dep2
also
dep3
. And that means that the names of these files will also change.
But this does not end there. Since the
main
fragment imports
dep2
and
dep3
, and their file names have changed, the import commands in
main
will also change:
-import {...} from '/dep2-3c4d.mjs'; +import {...} from '/dep2-2be5.mjs'; -import {...} from '/dep3-d4e5.mjs'; +import {...} from '/dep3-3c6f.mjs';
And finally, since the contents of the
main
file have changed, the name of this file will also have to change.
This is how the dependency diagram will now look.
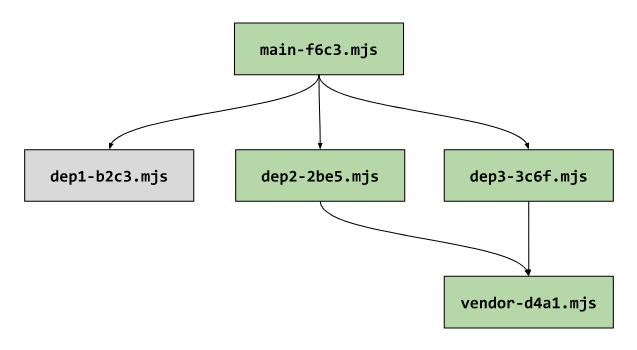
Modules in the dependency tree affected by a single change in the code of one of the leaf nodes of the tree
This example shows how a small code change made in just one file led to invalidation of the cache of 80% of the bundle fragments.
Although it is true that not all changes lead to such sad consequences (for example, invalidating the leaf node cache leads to invalidating the cache of all nodes down to the root, but invalidating the root cache does not cause cascading invalidation reaching the leaf catch), in an ideal world we would not have to deal with any unnecessary cache invalidations.
This leads us to the following question: "Is it possible to get the benefits of immutable resources and long-term caching, while not suffering from cascading cache invalidations?"
Problem Solving Approaches
The problem with the hashes of the contents of the files in the file names, from a technical point of view, is not that the hashes are in the names. It lies in the fact that these hashes appear inside other files. As a result, the cache of these files is disabled when changing the hashes in the names of the files on which they depend.
The solution to this problem is to use the language of the above example to make it possible to import the
vendor
fragment by the
dep2
and
dep3
without specifying the version information of the
vendor
fragment file. In doing so, you must ensure that the downloaded
vendor
version is correct, taking into account the current versions of
dep2
and
dep3
.
As it turned out, there are several ways to achieve this goal:
- Import cards.
- Service Workers.
- Native scripts for loading resources.
Consider these mechanisms.
Approach # 1: Import Cards
Import maps are the simplest solution to the problem of cascading cache invalidation. In addition, this mechanism is easiest to implement. But, unfortunately, it is only supported in Chrome (this feature, moreover, must be explicitly enabled ).
Despite this, I want to start with the story about import cards, because I am sure that this decision will become the most common in the future. In addition, the description of working with import cards will help explain the features of other approaches to solving our problem.
Using import cards to prevent cascading cache invalidation consists of three steps.
▍Step 1
You need to configure the bundler so that when building the project it does not include hashes of the contents of files in their names.
If you assemble a project whose modules are shown in the diagram from the previous example, without including hashes of their contents in the file names, the files in the project output directory will look like this:
dep1.mjs dep2.mjs dep3.mjs main.mjs vendor.mjs
Import commands in the corresponding modules will also not include hashes:
import {...} from '/vendor.mjs';
▍Step 2
You need to use a tool like rev-hash and use it to generate a copy of each file with a hash added to its name indicating the version of its contents.
After this part of the work is done, the contents of the output directory should look something like the one shown below (note that there are now two options for each file):
dep1-b2c3.mjs", dep1.mjs dep2-3c4d.mjs", dep2.mjs dep3-d4e5.mjs", dep3.mjs main-1a2b.mjs", main.mjs vendor-5e6f.mjs", vendor.mjs
▍Step 3
You need to create a JSON object that stores information about the correspondence of each file in whose name there is no hash to each file in the name of which there is a hash. This object needs to be added to HTML templates.
This JSON object is an import map. Here's what it might look like:
<script type="importmap"> { "imports": { "/main.mjs": "/main-1a2b.mjs", "/dep1.mjs": "/dep1-b2c3.mjs", "/dep2.mjs": "/dep2-3c4d.mjs", "/dep3.mjs": "/dep3-d4e5.mjs", "/vendor.mjs": "/vendor-5e6f.mjs", } } </script>
After that, whenever the browser sees the import command of the file located at the address corresponding to one of the keys of the import map, the browser imports the file that matches the key value.
If you use this import map as an example, you can find out that the import command that references the
/vendor.mjs
file will actually query and load the
/vendor-5e6f.mjs
file:
// `/vendor.mjs`, `/vendor-5e6f.mjs`. import {...} from '/vendor.mjs';
This means that the source code of the modules can quite easily refer to the file names of modules that do not contain hashes, and the browser will always download files whose names contain information about versions of their contents. And, since there are no hashes in the source code of the modules (they are present only in the import map), changes to these hashes will not lead to invalidation of modules other than those whose contents have really changed.
Perhaps you are now wondering why I created a copy of each file instead of just renaming the files. This is necessary to support browsers that cannot work with import maps. In the previous example, such browsers will only see the
/vendor.mjs
file and simply download this file, doing as they usually do, encountering similar constructs. As a result, it turns out that both files must exist on the server.
If you want to see import cards in action, here is a set of examples that demonstrate all the ways to solve the problem of cascading cache invalidation shown in this article. Also, take a look at the project build configuration , in case you are interested in learning how I generated the import map and version hashes for each file.
To be continued…
Dear readers! Are you aware of cascading cache invalidation?

