Last week we talked in our blog about changes that would allow enemies (biters) not to run into each other, but this was not the only update related to biters. Coincidentally, this week’s updates included what we worked on over the previous few weeks - updating the search system for enemies.
Search for a way
When a unit wants to move somewhere, it first needs to understand how to get there. In the simplest case, you can move straight to the goal, but sometimes obstacles arise on the way - rocks, trees, enemy nests (spawners), player units. To pave the way, we need to tell the pathfinder function the current and final position, and pathfinder will return to us (perhaps after many measures) a path that is simply a set of waypoints that the unit must move to get to destination
To accomplish its work, pathfinder uses an algorithm called A * (pronounced "A star"). A simple example of finding a path using A * is shown in the video: biter wants to find a path around rocks. The path finding function begins to explore the map around the biter (the study is shown by white dots). At first she tries to go straight to the goal, but as soon as she reaches the cliffs, she “spills” in both directions, trying to find a position from which again it will be possible to move to the goal.
The algorithm in this video is slowed down so you can better see how it works.
Each point in the animation represents a node . Each node remembers the distance from the start of the search and an estimate of the distance from this node to the target (this estimate is calculated by the heuristic function ). It is thanks to the heuristic function that A * works - it directs the algorithm in the right direction.
In the simplest case, this function is simply calculating the distance in a straight line from the node to the target position - this is the approach we used in Factorio from the very beginning of development, and thanks to it, the algorithm initially moves in a straight line. However, this is not the only option - if the heuristic function knew about some of the obstacles, it could direct the algorithm around it, which would speed up the search, because it would not have to examine the extra nodes. Obviously, the smarter the heuristic, the more difficult it is to implement.
A simple heuristic straight-line distance estimation function is good for finding paths over relatively short distances. It suited us in previous versions of Factorio - almost always biters moved over long distances only because they were angry by pollution, and this did not happen very often. However, we now have artillery. Artillery can easily shoot at huge numbers of biters on the other side of a large lake (and "agrify" them), after which they try to pave the way around the lake. The video below shows how the simple A * algorithm we used earlier tries to get around the lake.
This video shows the speed of the algorithm in reality; he is not slowed down.
Block reduction
Finding a path is a long history task, and there are many techniques for improving it. Some of these techniques belong to the category of hierarchical path search : in this case, the map is simplified at first, the path is located on this simplified map, which is then used to find the real path. I repeat, there are several specific implementations of such a technique, but all of them require simplification of the search space.
How can you simplify the world of Factorio? Our maps are randomly generated and constantly changing: placing and deleting entities (for example, collectors, walls or turrets) - this is probably the most basic mechanics of the whole game. We do not want to recount the entire simplified map every time we add or remove an entity. At the same time, if we simplify the map anew every time we need to find a way, then we can easily lose all the gain in performance.
One of the people with access to the source code of the game (Allaizn) came up with an idea. which I implemented as a result. Now this idea seems obvious.
The game is based on blocks of 32x32 tiles. The simplification process replaces each block with one or more abstract nodes . Since our goal is to improve the search for a path around the lakes, we can ignore all entities and consider only tiles: you can’t move on water, on land you can. We separate each block into separate components . A component is a tile area in which a unit can get from one tile inside a component to any other tile of the same component. In the image below, the block is divided into two separate components, red and green. Each of these components will become one abstract node - in fact, the entire block is reduced to two “points”.

The most important thought of Allaizn was that we do not need to store a component for each tile of the map - just remember the components of the tiles around the perimeter of each block, because we are only interested in what other components are connected to (in neighboring blocks) of each component, and this depends only on the tiles that are on the very border of the block.
Hierarchical Path Search
So, we figured out how to simplify the map, but how to use this to find paths? As I said, there are many hierarchical path searching techniques. The simplest idea is to find the path using abstract nodes from the beginning to the goal, that is, the path will be a list of the components of the blocks that you need to visit. Then we use the series of good old searches A * to specifically figure out how to move from one component of the block to another.
The problem here is that we have too simplified the map: what if it is impossible to move from one block to another, because some entities (for example, rocks) block the path? When reducing blocks, we ignore all entities, therefore we only know that the tiles between the blocks are somehow connected, but we know absolutely nothing about whether it is possible to move from one to another.
The solution is to use simplification simply as a “recommendation” for a real search. In particular, we will use it to create a smart version of the heuristic search function.
As a result, we got the following scheme: we have two pathfinder: the base pathfinder , which finds the real path, and the abstract pathfinder , which provides the heuristic function to the base pathfinder. Each time the base pathfinder creates a new base node, it calls an abstract pathfinder to get an estimate of the distance to the target. The abstract pathfinder acts in the opposite order - it starts with the search target and paves the way to the beginning, moving from one component of the block to another. When an abstract search finds the block and component in which a new base node is created, it uses the distance from the beginning of the abstract search (which, as I said, is the goal position of the entire search) to calculate an estimate of the distance from the new base node to the general target.
However, the execution of the entire pathfinder for each individual node will be far from fast, even if the abstract pathfinder moves from one block to another. Therefore, instead, we use a scheme called “Reverse Resumable A *”. “Reverse” means that it, as I said above, is carried out from goal to beginning. “Renewable” means that after finding a block that is interesting to the base pathfinder, we save all its nodes in memory. The next time the base pathfinder creates a new node and needs a distance estimate, we just look at the abstract nodes saved from the previous search. At the same time, there is a high probability that the required abstract node will still be in memory (in the end, one abstract node covers most of the block, and often the entire block).
Even if the base pathfinder creates a node located in a block that is not covered by any of the abstract nodes, we do not need to perform the entire abstract search again. A convenient feature of the A * algorithm is that even after it “finishes work” and finds a path, it continues execution, exploring the nodes around the nodes already studied. And this is exactly what we do if we need a distance estimate for a base node located in a block not yet covered by abstract search: we resume the abstract search from nodes stored in memory until it expands to the node we need.
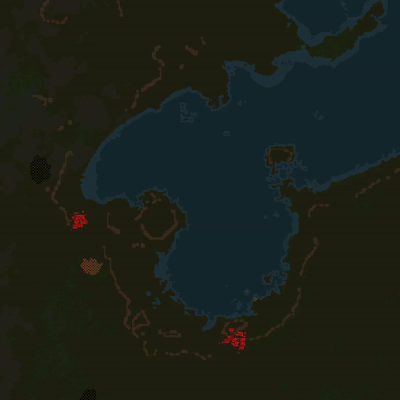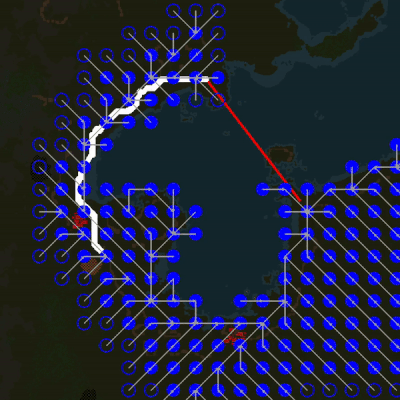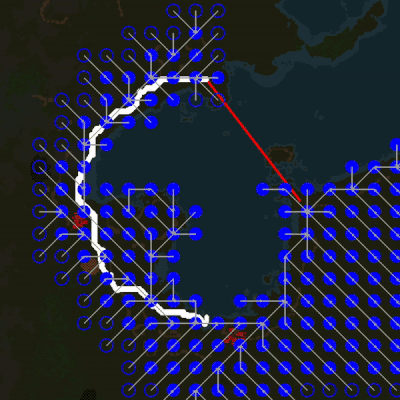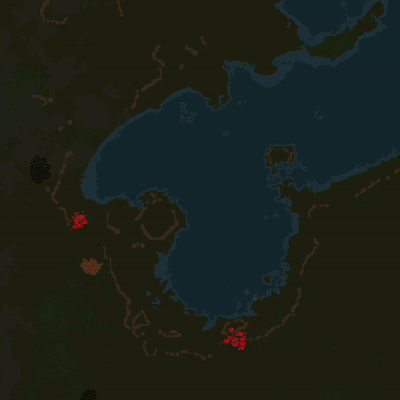
The video below shows a new pathfinding system in action. Blue circles are abstract nodes; white dots - basic search. The pathfinder in the video is much slower than the game to show how it works. At normal speed, the entire search takes only a few ticks. Note that the basic search, which still uses the old algorithm that we always used, simply magically “knows” how to move around the lake.
Since the abstract pathfinder is used only for obtaining a heuristic estimate of the distance, the basic search can quite easily depart from the path proposed by the abstract search. This means that even though the block reduction scheme ignores all entities, the basic pathfinder can bypass them almost without problems. Due to the ignoring of entities in the process of simplifying the map, we do not need to repeat it again each time an entity is added or deleted, it is sufficient to cover only those tiles that have been changed (for example, as in the case with a garbage landfill), which is much less common than the placement of entities.
In addition, this means that we essentially use the same pathfinder that has been used for years, only the heuristic function has been updated. That is, this change will not affect many other systems, and will only affect the search speed.