Processing 40 TB of code from 10 million projects on a dedicated server with Go for $ 100
The Sloc Cloc and Code (scc) command line tool that I wrote , which is now finalized and supported by many great people, counts lines of code, comments, and estimates the complexity of files inside a directory. A good selection is needed here. The tool counts branching operators in code. But what is complexity? For example, the statement “This file has difficulty 10” is not very useful without context. To solve this problem, I ran
on all sources on the Internet. This will also allow you to find some extreme cases that I did not consider in the tool itself. Powerful brute force test.
But if I'm going to run the test on all the sources in the world, it will require a lot of computing resources, which is also an interesting experience. Therefore, I decided to write everything down - and this article appeared.
In short, I downloaded and processed a lot of sources.
Naked figures:
Let's just mention one detail. There are not 10 million projects, as indicated in the high-profile title. I missed 15,000, so I rounded it. I apologize for this.
It took about five weeks to download everything, go through scc and save all the data. Then a little more than 49 hours to process 1 TB JSON and get the results below.
Also note that I could be mistaken in some calculations. I will promptly inform you if any error is detected, and provide a dataset.
Since launching searchcode.com, I have already accumulated a collection of more than 7,000,000 projects on git, mercurial, subversion and so on. So why not process them? Working with git is usually the easiest solution, so this time I ignored mercurial and subversion and exported a complete list of git projects. It turns out I actually tracked 12 million git repositories, and I probably need to refresh the main page to reflect this.
So now I have 12 million git repositories to download and process.
When you run scc, you can select the output in JSON with saving the file to disk:
The results are as follows (for a single file):
For a larger example, see the results for the redis project: redis.json . All the results below are obtained from such a result without any additional data.
It should be borne in mind that scc usually classifies languages based on the extension (unless the extension is common, for example, Verilog and Coq). Thus, if you save an HTML file with the java extension, it will be considered a java file. This is usually not a problem, because why do this? But, of course, on a large scale, the problem becomes noticeable. I discovered this later when some files were disguised as a different extension.
Some time ago, I wrote code for generating scc-based github tags . Since the process needed to cache the results, I changed it a bit to cache them in JSON format on AWS S3.
With the code for labels in AWS on lambda, I took an exported list of projects, wrote about 15 python lines to clear the format to match my lambda, and made a request to it. Using python multiprocessing, I parallelized requests to 32 processes so that the endpoint responds quickly enough.
Everything worked brilliantly. However, the problem was, firstly, in cost, and secondly, lambda has an 30-second timeout for API Gateway / ALB, so it cannot process large repositories fast enough. I knew that this was not the most economical solution, but I thought that the price would be about $ 100, which I would put up with. After processing a million repositories, I checked - and the cost was about $ 60. Since I was not happy with the prospect of a final AWS account of $ 700, I decided to reconsider my decision. Keep in mind that this was basically the storage and CPU that were used to collect all this information. Any processing and export of data significantly increased the price.
Since I was already on AWS, a quick solution would be to dump the URLs as messages in SQS and pull them out using EC2 or Fargate instances for processing. Then scale like crazy. But despite the everyday experience with AWS, I have always believed in the principles of Taco Bell programming . In addition, there were only 12 million repositories, so I decided to implement a simpler (cheaper) solution.
Starting the calculation locally was not possible due to the terrible internet in Australia. However, my searchcode.com works by using the dedicated servers from Hetzner rather carefully. These are fairly powerful i7 Quad Core 32 GB RAM machines, often with 2 TB of storage space (usually not used). They usually have a good supply of computing power. For example, the front-end server most of the time calculates the square root of zero. So why not start processing there?
This is not really Taco Bell programming, as I used the bash and gnu tools. I wrote a simple program on Go to run 32 go-routines that read data from a channel, generate git and scc subprocesses before writing the output to JSON in S3. I actually wrote the solution first in Python, but the need to install pip dependencies on my clean server seemed like a bad idea, and the system crashed in strange ways that I didn't want to debug.
Running all this on the server produced the following metrics in htop, and several running git / scc processes (scc does not appear in this screenshot) assumed that everything was working as expected, which was confirmed by the results in S3.

I recently read these articles , so I had the idea to borrow the format of these posts in relation to the presentation of information. True, I also wanted to add jQuery DataTables to large tables to sort and search / filter the results. Thus, in the original article, you can click on the headings to sort and use the search field to filter.
The size of the data to be processed raised another question. How to process 10 million JSON files, occupying a little more than 1 TB of disk space in the S3 bucket?
The first thought was AWS Athena. But since it would cost something like $ 2.50 per query for such a dataset, I quickly started looking for an alternative. However, if you save the data there and rarely process it, this may be the cheapest solution.
I posted a question in corporate chat (why solve problems alone).
One idea was to dump data into a large SQL database. However, this means processing the data in the database, and then executing queries on it several times. Plus, the data structure means multiple tables, which means foreign keys and indexes to provide a certain level of performance. This seems wasteful because we could just process the data as we read it from disk - in one pass. I was also worried about creating such a large database. With data only, it will be more than 1 TB in size before adding indexes.
Seeing how I created JSON in a simple way, I thought, why not handle the results in the same way? Of course, there is one problem. Pulling 1 TB of data from S3 will cost a lot. If the program crashes, it will be annoying. To reduce costs, I wanted to pull out all the files locally and save them for further processing. Good advice: it’s better not to store many small files in one directory . This sucks for runtime performance, and file systems don't like that.
My answer to this was another simple Go program to pull files from S3 and then save them in a tar file. Then I could process this file again and again. The process itself runs a very ugly Go program to process the tar file so that I can re-run the queries without having to pull data from S3 again and again. I didn’t bother with go-routines here for two reasons. Firstly, I didn’t want to load the server as much as possible, so I limited myself to one core for the CPU to work hard (the other was mostly locked on the processor to read the tar file). Secondly, I wanted to guarantee thread safety.
When this was done, a set of questions was needed to answer. I again used the collective mind and connected my colleagues while I came up with my own ideas. The result of this merging of minds is presented below.
You can find all the code that I used to process JSON, including the code for local processing, and the ugly Python script that I used to prepare something useful for this article: please do not comment on it, I know that the code is ugly , and it is written for a one-time task, since I’m unlikely to ever look at it again.
If you want to see the code that I wrote for general use, look at the scc sources .
I spent about $ 60 on computing while trying to work with lambda. I have not looked at the cost of storing S3 yet, but it should be close to $ 25, depending on the size of the data. However, this does not include transmission costs, which I did not watch either. Please note that I cleaned the bucket when I finished with it, so this is not a fixed cost.
But after a while I still abandoned AWS. So what is the real cost if I wanted to do it again?
All software is free and free. So there’s nothing to worry about.
In my case, the cost would be zero, since I used the “free” computing power left from searchcode.com. However, not everyone has such free resources. Therefore, let's assume that the other person wants to repeat this and must raise the server.
This can be done for € 73 using the cheapest new dedicated server from Hetzner , including the cost of installing a new server. If you wait and delve into the section with auctions , you can find much cheaper servers without installation fees. At the time of writing, I found a car that is perfect for this project, for € 25.21 a month without installation fees.
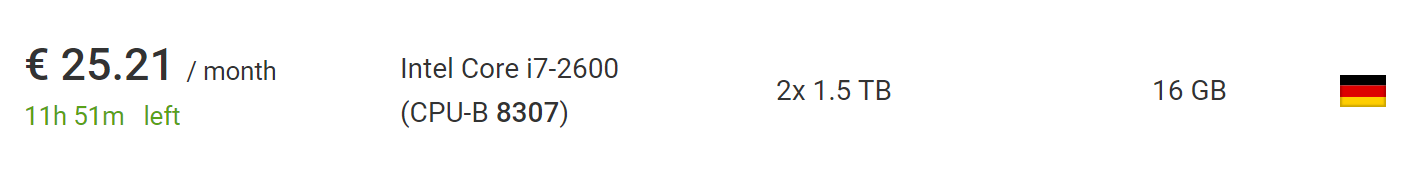
What's even better, outside the European Union, VAT will be removed from this price, so safely take another 10%.
Therefore, if you lift such a service from scratch on my software, it will ultimately cost up to $ 100, but rather up to $ 50, if you are a little patient or successful. This assumes that you have been using the server for less than two months, which is enough for downloading and processing. There is also enough time to get a list of 10 million repositories.
If I used zipped tar (which is actually not that difficult), I could process 10 times more repositories on the same machine, and the resulting file will still remain small enough to fit on the same HDD. Although the process can take several months, because the download will take longer.
To go far beyond the 100 million repositories, however, some kind of sharding is required. Nevertheless, it is safe to say that you will repeat the process on my scale or much larger, on the same equipment without much effort or code changes.
Here's how many projects came from each of three sources: github, bitbucket, and gitlab. Please note that this is before excluding empty repositories, therefore, the amount exceeds the number of repositories that are actually processed and taken into account in the following tables.
I apologize to the GitHub / Bitbucket / GitLab staff if you read this. If my script caused any problems (although I doubt it), I have a drink of your choice when meeting me.
Let's move on to the real issues. Let's start with a simple one. How many files are in the average repository? Most projects only have a couple of files or more? After looping through the repositories, we get the following schedule:

Here, the X axis shows buckets with the number of files, and the Y axis shows the number of projects with so many files. Limit the horizontal axis to a thousand files, because then the graph is too close to the axis.
It seems like most repositories have less than 200 files.
But what about visualization up to the 95th percentile, which will show the real picture? It turns out that in the vast majority (95%) of projects - less than 1000 files. While 90% of projects have less than 300 files and 85% have less than 200.

If you want to build a chart yourself and do it better than me, here is a link to the raw data in JSON .
For example, if a Java file is identified, then we increase the number of Java in the projects by one, and we do nothing for the second file. This gives a quick idea of which languages are most commonly used. Unsurprisingly, the most common languages include markdown, .gitignore, and plaintext.
Markdown is the most frequently used language; it is seen in more than 6 million projects, which is about 2⁄3 of the total. This makes sense, since almost all projects include README.md which is displayed in HTML for repository pages.
Addition to the previous table, but averaged by the number of files for each language in the repository. That is, how many Java files exist on average for all projects where there is Java?
I believe it’s still interesting to see which languages have the largest files on average? Using arithmetic mean generates abnormally high numbers due to projects like sqlite.c, which is included in many repositories, combining many files into one, but no one ever works on this one large file (I hope!)
Therefore, I calculated the average of the median. However, languages with absurdly high values, such as Bosque and JavaScript, still remained.
So I thought, why not make a knight's move? At the suggestion of Darrell (a Kablamo resident and an excellent data scientist), I made one small change and changed the arithmetic mean, dropping files over 5,000 lines to remove anomalies.
What is the average file complexity for each language?
In fact, complexity ratings cannot be directly correlated between languages. Excerpt from readme itself
:
Thus, languages cannot be compared with each other here, although this can be done between similar languages such as Java and C, for example.
This is a more valuable metric for individual files in the same language. Thus, you can answer the question “Is this file I'm working with easier or more complicated than the average?”
I must mention that I will be glad to suggest how to improve this metric in scc . For a commit, it is usually enough to add just a few keywords to the languages.json file, so any programmer can help.
What is the average number of comments in files in each language?
Perhaps the question can be rephrased: the developers in which language write the most comments, suggesting a misunderstanding of the reader.
What file names are most common in all codebases, ignoring the extension and case?
If you asked me earlier, I would say: README, main, index, license. The results pretty well reflect my assumptions. Although there is a lot of interesting things. I have no idea why so many projects contain a file called
or
.
The most common makefile surprised me a bit, but then I remembered that it was used in many new JavaScript projects. Another interesting thing to note: it seems that jQuery is still on the horse, and the reports of his death are greatly exaggerated, and he is in fourth place on the list.
Please note that due to memory limitations, I made this process a little less accurate. After every 100 projects, I checked the map and deleted the names of files that occurred less than 10 times from the list. They could return to the next test, and if they met more than 10 times, they remained on the list. Perhaps some results have some error if some common name rarely appeared in the first batch of repositories before becoming common. In short, these are not absolute numbers, but should be close enough to them.
I could use the prefix tree to “squeeze” the space and get the absolute numbers, but I didn’t want to write it, so I slightly abused the map to save enough memory and get the result. However, it will be quite interesting to try the prefix tree later.
It is very interesting. How many repositories have at least some explicit license file? Please note that the absence of a license file here does not mean that the project does not have it, since it can exist in the README file or can be indicated through SPDX comment tags in lines. It simply means that
it could not find the explicit license file using its own criteria. Currently, such files are considered to be “license”, “license”, “copying”, “copying3”, “unlicense”, “unlicence”, “license-mit”, “license-mit” or “copyright” files.
Unfortunately, the vast majority of repositories do not have a license. I would say that there are many reasons why any software needs a license, but someone else said it for me.

Some may not know this, but there may be several .gitignore files in a git project. With this in mind, how many projects use multiple .gitignore files? But at the same time, how many have not a single one?
I found a rather interesting project with 25,794 .gitignore files in the repository. The next result was 2547. I have no idea what is going on there. I glanced briefly: it seems that they are used to check directories, but I can’t confirm this.
Returning to the data, here is a graph of repositories with up to 20 .gitignore files, which covers 99% of all projects.

As expected, most projects have 0 or 1 .gitignore files. This is confirmed by a massive tenfold drop in the number of projects with 2 files. What surprised me was how many projects have more than one .gitignore file. The long tail in this case is especially long.
I was curious why some projects have thousands of such files. One of the main troublemakers is the fork https://github.com/PhantomX/slackbuilds : each of them has about 2547 .gitignore files. The following are other repositories with more than a thousand .gitignore files.
This section is not an exact science, but belongs to the class of problems of natural language processing. Searching for abusive or abusive terms in a specific list of files will never be effective. If you search with a simple search, you will find many ordinary files like
and so on. So I took a list of curses and then checked if any files in each project start with one of these values followed by a dot. This means that the file named
will be taken into account, but
not. However, he will miss many varied options, such as
other equally crude names.
My list contains some words on leetspeak, such as
and
, to catch some of the interesting cases. Full list here.
Although this is not entirely accurate, as already mentioned, it is incredibly interesting to look at the result. Let's start with the list of languages in which the most curses. You should probably correlate the result with the total amount of code in each language. So here are the leaders.
Interesting!My first thought was: “Oh, these naughty C developers!” But despite the large number of such files, they write so much code that the percentage of curses is lost in the total. However, it’s pretty clear that Dart developers have a few words in their arsenal! If you know one of the Dart programmers, you can shake his hand.
I also want to know what are the most commonly used curses. Let's look at a common dirty collective mind. Some of the best that I found were normal names (if you squint), but most of the rest will certainly surprise colleagues and some comments in the pool requests.
Note that some of the more offensive words on the list did have matching file names, which I find pretty shocking. Fortunately, they are not very common and are not included in the list above, which is limited to files with the number of more than 100. I hope that these files exist only for testing allow / deny lists and the like.
As expected, plaintext, SQL, XML, JSON, and CSV occupy the top positions: they usually contain metadata, database dumps, and the like.
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
Once again, these values are not directly comparable to each other, but it’s interesting to see what is considered the most difficult in every language.
Some of these files are absolute monsters. For example, consider the most complex C ++ file I found: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp : it's 28.3 megabytes of compiler hell (and, fortunately, it seems to be generated automatically).
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
It sounds good in theory, but in fact ... something minified or without line breaks distorts the results, making them meaningless. Therefore, I do not publish the results of the calculations. However, I created a ticket in
to support the minification detection in order to remove it from the calculation results.
You can probably draw some conclusions based on the available data, but I want all users to benefit from this feature
.
I have no idea what valuable information you can learn from this, but it's interesting to see.
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
Under the "pure" in the types of projects are purely in one language. Of course, this is not very interesting in itself, so let's look at them in context. As it turned out, the vast majority of projects have less than 25 languages, and most have less than ten.
The peak in the graph below is in four languages.
Of course, in clean projects there can be only one programming language, but there is support for other formats, such as markdown, json, yml, css, .gitignore, which are taken into account
. It is probably reasonable to assume that any project with less than five languages is “clean” (for some level of cleanliness), and this is just over half of the total dataset. Of course, your definition of cleanliness may differ from mine, so you can focus on any number that you like.
What surprises me is a strange surge around 34-35 languages. I have no reasonable explanation of where it came from, and this is probably worthy of a separate investigation.

Ah, the modern world of TypeScript. But for TypeScript projects, how many are purely in this language?
I must admit, I'm a little surprised by this number. Although I understand that mixing JavaScript with TypeScript is quite common, I would have thought there would be more projects in the newfangled language. But it is possible that a more recent set of repositories will dramatically increase their number.
I have the feeling that some TypeScript developers feel sick at the very thought of it. If this helps them, I can assume that most of these projects are programs like
with examples of all languages for testing purposes.
Given that you can either upload all the files you need into one directory or create a directory system, what is the typical path length and number of directories?
To do this, count the number of slashes in the path for each file and average. I did not know what to expect here, except that Java might be at the top of the list, since there are usually long file paths.
There was once a “discussion” at Slack - using .yaml or .yml. Many were killed there on both sides.
Debate may finally (?) End. Although I suspect that some will still prefer to die in a dispute.
What register is used for file names? Since there is still an extension, we can expect, mainly, a mixed case.
Which, of course, is not very interesting, because usually file extensions are lowercase. What if ignore extensions?
Not what I expected. Again, mostly mixed, but I would have thought that the bottom would be more popular.
Another idea that colleagues came up with when looking at some old Java code. I thought, why not add a check for any Java code where Factory, FactoryFactory or FactoryFactoryFactory appears in the title. The idea is to estimate the number of such factories.
So, just over 2% of the Java code turned out to be a factory or factoryfactory. Fortunately, no factoryfactoryfactory was found. Perhaps this joke will finally die, although I’m sure that at least one serious third-level recursive multifactory still works somewhere in some kind of Java 5 monolith, and it makes more money every day than I have seen in my entire career. .
The idea of .ignore files was developed by burntsushi and ggreer in a discussion on Hacker News . Perhaps this is one of the best examples of "competing" open source tools that work together with good results and are completed in record time. It has become the de facto standard for adding code that tools will ignore.
also fulfills the .ignore rule, but also knows how to count them. Let's see how well the idea has spread.
I like to do some analysis for the future. It would be nice to scan things like AWS AKIA keys and the like. I would also like to expand the coverage of Bitbucket and Gitlab projects with analysis for each, to see if there may hang out development teams from different areas.
If I ever repeat the project, I would like to overcome the following shortcomings and take into account the following ideas.
Well, I can take some of this information and use it in my searchcode.com search engine and program
. At least some useful data points. Initially, the project was conceived in many ways for the sake of this. It is also very useful to compare your project with others. It was also an interesting way to spend a few days solving some interesting problems. And a good reliability check for
.
In addition, I am currently working on a tool that helps leading developers or managers analyze code, search for specific languages, large files, flaws, etc. ... with the assumption that you need to analyze several repositories. You enter some kind of code, and the tool says how maintainable it is and what skills are needed to maintain it. This is useful when deciding whether to buy some kind of code base, to service it, or to get an idea about your own product that the development team gives out. Theoretically, this should help teams scale through shared resources. Something like AWS Macie, but for code - something like this I'm working on. I myself need this for everyday work, and I suspect that others may find application for such an instrument, at least that is the theory.
Perhaps it would be worth putting here some form of registration for those interested ...
If someone wants to make their own analysis and make corrections, here is a link to the processed files (20 MB). If someone wants to post raw files in the public domain, let me know. This is 83 GB tar.gz, and inside is just over 1 TB. Content consists of just over 9 million JSON files of various sizes.
UPD. Several good souls suggested placing the file, the places are indicated below:
By hosting this tar.gz file, thanks to CNCF for the server for xet7 from the Wekan project .
scc
on all sources on the Internet. This will also allow you to find some extreme cases that I did not consider in the tool itself. Powerful brute force test.
But if I'm going to run the test on all the sources in the world, it will require a lot of computing resources, which is also an interesting experience. Therefore, I decided to write everything down - and this article appeared.
In short, I downloaded and processed a lot of sources.
Naked figures:
- 9,985,051 total repositories
- 9,100,083 repositories with at least one file
- 884 968 empty repositories (without files)
- 3,500,000,000 files in all repositories
- Processed 40 736 530 379 778 bytes (40 TB)
- 1,086,723,618,560 rows identified
- 816,822,273,469 lines with code recognized
- 124 382 152 510 blank lines
- 145 519 192 581 lines of comments
- Total complexity according to scc rules: 71 884 867 919
- 2 new bugs found in scc
Let's just mention one detail. There are not 10 million projects, as indicated in the high-profile title. I missed 15,000, so I rounded it. I apologize for this.
It took about five weeks to download everything, go through scc and save all the data. Then a little more than 49 hours to process 1 TB JSON and get the results below.
Also note that I could be mistaken in some calculations. I will promptly inform you if any error is detected, and provide a dataset.
Table of contents
- Methodology
- Presentation and calculation of results
- Cost
- Data sources
- How many files are in the repository?
- What is the language breakdown?
- How many files are in the repository by language?
- How many lines of code in a typical language file?
- Average file complexity in each language?
- Average number of comments for files in each language?
- What are the most common file names?
- How many repositories are missing a license?
- Which languages have the most comments?
- How many projects use multiple .gitignore files?
- What language is more obscene language?
- The largest files by the number of lines in each language
- What is the most complex file in every language?
- The most complicated file regarding the number of lines?
- What is the most commented file in each language?
- How many “clean” projects
- Projects with TypeScript but not JavaScript
- Does anyone use CoffeeScript and TypeScript?
- What is the typical path length in each language
- YAML or YML?
- Upper, lower, or mixed case?
- Factories in Java
- .Ignore files
- Ideas for the future
- Why is this all?
- Unprocessed / processed files
Methodology
Since launching searchcode.com, I have already accumulated a collection of more than 7,000,000 projects on git, mercurial, subversion and so on. So why not process them? Working with git is usually the easiest solution, so this time I ignored mercurial and subversion and exported a complete list of git projects. It turns out I actually tracked 12 million git repositories, and I probably need to refresh the main page to reflect this.
So now I have 12 million git repositories to download and process.
When you run scc, you can select the output in JSON with saving the file to disk:
scc --format json --output myfile.json main.go
The results are as follows (for a single file):
[ { "Blank": 115, "Bytes": 0, "Code": 423, "Comment": 30, "Complexity": 40, "Count": 1, "Files": [ { "Binary": false, "Blank": 115, "Bytes": 20396, "Callback": null, "Code": 423, "Comment": 30, "Complexity": 40, "Content": null, "Extension": "go", "Filename": "main.go", "Hash": null, "Language": "Go", "Lines": 568, "Location": "main.go", "PossibleLanguages": [ "Go" ], "WeightedComplexity": 0 } ], "Lines": 568, "Name": "Go", "WeightedComplexity": 0 } ]
For a larger example, see the results for the redis project: redis.json . All the results below are obtained from such a result without any additional data.
It should be borne in mind that scc usually classifies languages based on the extension (unless the extension is common, for example, Verilog and Coq). Thus, if you save an HTML file with the java extension, it will be considered a java file. This is usually not a problem, because why do this? But, of course, on a large scale, the problem becomes noticeable. I discovered this later when some files were disguised as a different extension.
Some time ago, I wrote code for generating scc-based github tags . Since the process needed to cache the results, I changed it a bit to cache them in JSON format on AWS S3.
With the code for labels in AWS on lambda, I took an exported list of projects, wrote about 15 python lines to clear the format to match my lambda, and made a request to it. Using python multiprocessing, I parallelized requests to 32 processes so that the endpoint responds quickly enough.
Everything worked brilliantly. However, the problem was, firstly, in cost, and secondly, lambda has an 30-second timeout for API Gateway / ALB, so it cannot process large repositories fast enough. I knew that this was not the most economical solution, but I thought that the price would be about $ 100, which I would put up with. After processing a million repositories, I checked - and the cost was about $ 60. Since I was not happy with the prospect of a final AWS account of $ 700, I decided to reconsider my decision. Keep in mind that this was basically the storage and CPU that were used to collect all this information. Any processing and export of data significantly increased the price.
Since I was already on AWS, a quick solution would be to dump the URLs as messages in SQS and pull them out using EC2 or Fargate instances for processing. Then scale like crazy. But despite the everyday experience with AWS, I have always believed in the principles of Taco Bell programming . In addition, there were only 12 million repositories, so I decided to implement a simpler (cheaper) solution.
Starting the calculation locally was not possible due to the terrible internet in Australia. However, my searchcode.com works by using the dedicated servers from Hetzner rather carefully. These are fairly powerful i7 Quad Core 32 GB RAM machines, often with 2 TB of storage space (usually not used). They usually have a good supply of computing power. For example, the front-end server most of the time calculates the square root of zero. So why not start processing there?
This is not really Taco Bell programming, as I used the bash and gnu tools. I wrote a simple program on Go to run 32 go-routines that read data from a channel, generate git and scc subprocesses before writing the output to JSON in S3. I actually wrote the solution first in Python, but the need to install pip dependencies on my clean server seemed like a bad idea, and the system crashed in strange ways that I didn't want to debug.
Running all this on the server produced the following metrics in htop, and several running git / scc processes (scc does not appear in this screenshot) assumed that everything was working as expected, which was confirmed by the results in S3.
Presentation and calculation of results
I recently read these articles , so I had the idea to borrow the format of these posts in relation to the presentation of information. True, I also wanted to add jQuery DataTables to large tables to sort and search / filter the results. Thus, in the original article, you can click on the headings to sort and use the search field to filter.
The size of the data to be processed raised another question. How to process 10 million JSON files, occupying a little more than 1 TB of disk space in the S3 bucket?
The first thought was AWS Athena. But since it would cost something like $ 2.50 per query for such a dataset, I quickly started looking for an alternative. However, if you save the data there and rarely process it, this may be the cheapest solution.
I posted a question in corporate chat (why solve problems alone).
One idea was to dump data into a large SQL database. However, this means processing the data in the database, and then executing queries on it several times. Plus, the data structure means multiple tables, which means foreign keys and indexes to provide a certain level of performance. This seems wasteful because we could just process the data as we read it from disk - in one pass. I was also worried about creating such a large database. With data only, it will be more than 1 TB in size before adding indexes.
Seeing how I created JSON in a simple way, I thought, why not handle the results in the same way? Of course, there is one problem. Pulling 1 TB of data from S3 will cost a lot. If the program crashes, it will be annoying. To reduce costs, I wanted to pull out all the files locally and save them for further processing. Good advice: it’s better not to store many small files in one directory . This sucks for runtime performance, and file systems don't like that.
My answer to this was another simple Go program to pull files from S3 and then save them in a tar file. Then I could process this file again and again. The process itself runs a very ugly Go program to process the tar file so that I can re-run the queries without having to pull data from S3 again and again. I didn’t bother with go-routines here for two reasons. Firstly, I didn’t want to load the server as much as possible, so I limited myself to one core for the CPU to work hard (the other was mostly locked on the processor to read the tar file). Secondly, I wanted to guarantee thread safety.
When this was done, a set of questions was needed to answer. I again used the collective mind and connected my colleagues while I came up with my own ideas. The result of this merging of minds is presented below.
You can find all the code that I used to process JSON, including the code for local processing, and the ugly Python script that I used to prepare something useful for this article: please do not comment on it, I know that the code is ugly , and it is written for a one-time task, since I’m unlikely to ever look at it again.
If you want to see the code that I wrote for general use, look at the scc sources .
Cost
I spent about $ 60 on computing while trying to work with lambda. I have not looked at the cost of storing S3 yet, but it should be close to $ 25, depending on the size of the data. However, this does not include transmission costs, which I did not watch either. Please note that I cleaned the bucket when I finished with it, so this is not a fixed cost.
But after a while I still abandoned AWS. So what is the real cost if I wanted to do it again?
All software is free and free. So there’s nothing to worry about.
In my case, the cost would be zero, since I used the “free” computing power left from searchcode.com. However, not everyone has such free resources. Therefore, let's assume that the other person wants to repeat this and must raise the server.
This can be done for € 73 using the cheapest new dedicated server from Hetzner , including the cost of installing a new server. If you wait and delve into the section with auctions , you can find much cheaper servers without installation fees. At the time of writing, I found a car that is perfect for this project, for € 25.21 a month without installation fees.
What's even better, outside the European Union, VAT will be removed from this price, so safely take another 10%.
Therefore, if you lift such a service from scratch on my software, it will ultimately cost up to $ 100, but rather up to $ 50, if you are a little patient or successful. This assumes that you have been using the server for less than two months, which is enough for downloading and processing. There is also enough time to get a list of 10 million repositories.
If I used zipped tar (which is actually not that difficult), I could process 10 times more repositories on the same machine, and the resulting file will still remain small enough to fit on the same HDD. Although the process can take several months, because the download will take longer.
To go far beyond the 100 million repositories, however, some kind of sharding is required. Nevertheless, it is safe to say that you will repeat the process on my scale or much larger, on the same equipment without much effort or code changes.
Data sources
Here's how many projects came from each of three sources: github, bitbucket, and gitlab. Please note that this is before excluding empty repositories, therefore, the amount exceeds the number of repositories that are actually processed and taken into account in the following tables.
| Source | amount |
|---|---|
| github | 9 680 111 |
| bitbucket | 248 217 |
| gitlab | 56 722 |
I apologize to the GitHub / Bitbucket / GitLab staff if you read this. If my script caused any problems (although I doubt it), I have a drink of your choice when meeting me.
How many files are in the repository?
Let's move on to the real issues. Let's start with a simple one. How many files are in the average repository? Most projects only have a couple of files or more? After looping through the repositories, we get the following schedule:
Here, the X axis shows buckets with the number of files, and the Y axis shows the number of projects with so many files. Limit the horizontal axis to a thousand files, because then the graph is too close to the axis.
It seems like most repositories have less than 200 files.
But what about visualization up to the 95th percentile, which will show the real picture? It turns out that in the vast majority (95%) of projects - less than 1000 files. While 90% of projects have less than 300 files and 85% have less than 200.
If you want to build a chart yourself and do it better than me, here is a link to the raw data in JSON .
What is the language breakdown?
For example, if a Java file is identified, then we increase the number of Java in the projects by one, and we do nothing for the second file. This gives a quick idea of which languages are most commonly used. Unsurprisingly, the most common languages include markdown, .gitignore, and plaintext.
Markdown is the most frequently used language; it is seen in more than 6 million projects, which is about 2⁄3 of the total. This makes sense, since almost all projects include README.md which is displayed in HTML for repository pages.
Full list
| Language | Number of projects |
|---|---|
| Markdown | 6 041 849 |
| gitignore | 5,471,254 |
| Plain text | 3,553,325 |
| Javascript | 3 408 921 |
| HTML | 3 397 596 |
| CSS | 3 037 754 |
| License | 2 597 330 |
| XML | 2 218 846 |
| Json | 1 903 569 |
| Yaml | 1 860 523 |
| Python | 1 424 505 |
| Shell | 1 395 199 |
| Ruby | 1,386,599 |
| Java | 1 319 091 |
| C header | 1,259,519 |
| Makefile | 1 215 586 |
| Rakefile | 1 006 022 |
| Php | 992 617 |
| Properties file | 909 631 |
| Svg | 804,946 |
| C | 791 773 |
| C ++ | 715 269 |
| Batch | 645,442 |
| Sass | 535 341 |
| Autoconf | 505 347 |
| Objective c | 503 932 |
| CoffeeScript | 435 133 |
| SQL | 413,739 |
| Perl | 390,775 |
| C # | 380 841 |
| ReStructuredText | 356 922 |
| Msbuild | 354,212 |
| LESS | 281 286 |
| Csv | 275,143 |
| C ++ Header | 199,245 |
| CMake | 173,482 |
| Patch | 169,078 |
| Assembly | 165,587 |
| XML Schema | 148 511 |
| m4 | 147 204 |
| JavaServer Pages | 142,605 |
| Vim script | 134 156 |
| Scala | 132 454 |
| Objective C ++ | 127 797 |
| Gradle | 126,899 |
| Module definition | 120 181 |
| Bazel | 114 842 |
| R | 113 770 |
| ASP.NET | 111 431 |
| Go template | 111 263 |
| Document Type Definition | 109,710 |
| Gherkin specification | 107 187 |
| Smarty template | 106 668 |
| Jade | 105 903 |
| Happy | 105 631 |
| Emacs lisp | 105 620 |
| Prolog | 102 792 |
| Go | 99 093 |
| Lua | 98 232 |
| Bash | 95 931 |
| D | 94,400 |
| ActionScript | 93,066 |
| Tex | 84 841 |
| Powershell | 80 347 |
| Awk | 79 870 |
| Groovy | 75 796 |
| Lex | 75 335 |
| nuspec | 72,478 |
| sed | 70 454 |
| Puppet | 67 732 |
| Org | 67 703 |
| Clojure | 67 145 |
| Xaml | 65 135 |
| TypeScript | 62 556 |
| Systemd | 58 197 |
| Haskell | 58 162 |
| Xcode Config | 57 173 |
| Boo | 55 318 |
| LaTeX | 55 093 |
| Zsh | 55 044 |
| Stylus | 54 412 |
| Razor | 54 102 |
| Handlebars | 51 893 |
| Erlang | 49,475 |
| Hex | 46,442 |
| Protocol buffers | 45 254 |
| Mustache | 44,633 |
| ASP | 43 114 |
| Extensible Stylesheet Language Transformations | 42,664 |
| Twig template | 42,273 |
| Processing | 41,277 |
| Dockerfile | 39,664 |
| Swig | 37 539 |
| LD Script | 36 307 |
| FORTRAN Legacy | 35,889 |
| Scons | 35,373 |
| Scheme | 34 982 |
| Alex | 34 221 |
| TCL | 33,766 |
| Android Interface Definition Language | 33,000 |
| Ruby HTML | 32 645 |
| Device tree | 31 918 |
| Expect | 30,249 |
| Cabal | 30 109 |
| Unreal script | 29 113 |
| Pascal | 28,439 |
| GLSL | 28,417 |
| Intel hex | 27 504 |
| Alloy | 27 142 |
| Freemarker template | 26,456 |
| IDL | 26,079 |
| Visual basic for applications | 26,061 |
| Macromedia eXtensible Markup Language | 24,949 |
| F # | 24,373 |
| Cython | 23,858 |
| Jupyter | 23,577 |
| Forth | 22 108 |
| Visual basic | 21 909 |
| Lisp | 21,242 |
| OCaml | 20,216 |
| Rust | 19,286 |
| Fish | 18,079 |
| Monkey c | 17 753 |
| Ada | 17 253 |
| SAS | 17 031 |
| Dart | 16,447 |
| TypeScript Typings | 16,263 |
| Systemverilog | 15 541 |
| Thrift | 15 390 |
| C shell | 14,904 |
| Fragment shader file | 14,572 |
| Vertex Shader File | 14 312 |
| QML | 13,709 |
| Coldfusion | 13,441 |
| Elixir | 12 716 |
| Haxe | 12 404 |
| Jinja | 12,274 |
| Jsx | 12 194 |
| Specman e | 12 071 |
| FORTRAN Modern | 11,460 |
| PKGBUILD | 11 398 |
| ignore | 11,287 |
| Mako | 10 846 |
| Tol | 10 444 |
| SKILL | 10 048 |
| Asciidoc | 9 868 |
| Swift | 9 679 |
| Buildstream | 9 198 |
| ColdFusion CFScript | 8 614 |
| Stata | 8 296 |
| Creole | 8 030 |
| Basic | 7 751 |
| V | 7 560 |
| Vhdl | 7,368 |
| Julia | 7 070 |
| ClojureScript | 7 018 |
| Closure template | 6,269 |
| AutoHotKey | 5 938 |
| Wolfram | 5,764 |
| Docker ignore | 5 555 |
| Korn shell | 5 541 |
| Arvo | 5,364 |
| Coq | 5,068 |
| SRecode Template | 5 019 |
| Game maker language | 4 557 |
| Nix | 4,216 |
| Vala | 4 110 |
| COBOL | 3 946 |
| Varnish configuration | 3,882 |
| Kotlin | 3,683 |
| Bitbake | 3 645 |
| Gdscript | 3 189 |
| Standard ML (SML) | 3,143 |
| Jenkins buildfile | 2 822 |
| Xtend | 2 791 |
| Abap | 2 381 |
| Modula3 | 2,376 |
| Nim | 2,273 |
| Verilog | 2013 |
| Elm | 1 849 |
| Brainfuck | 1 794 |
| Ur / web | 1,741 |
| Opalang | 1,367 |
| GN | 1,342 |
| Taskpaper | 1,330 |
| Ceylon | 1,265 |
| Crystal | 1,259 |
| Agda | 1,182 |
| Vue | 1,139 |
| LOLCODE | 1 101 |
| Hamlet | 1,071 |
| Robot framework | 1,062 |
| MUMPS | 940 |
| Emacs dev env | 937 |
| Cargo lock | 905 |
| Flow9 | 839 |
| Idris | 804 |
| Julius | 765 |
| Oz | 764 |
| Q # | 695 |
| Lucius | 627 |
| Meson | 617 |
| F * | 614 |
| ATS | 492 |
| PSL Assertion | 483 |
| Bitbucket pipeline | 418 |
| Purescript | 370 |
| Report Definition Language | 313 |
| Isabelle | 296 |
| Jai | 286 |
| MQL4 | 271 |
| Ur / Web Project | 261 |
| Alchemist | 250 |
| Cassius | 213 |
| Softbridge basic | 207 |
| MQL Header | 167 |
| Jsonl | 146 |
| Lean | 104 |
| Spice netlist | one hundred |
| Madlang | 97 |
| Luna | 91 |
| Pony | 86 |
| MQL5 | 46 |
| Wren | 33 |
| Just | thirty |
| QCL | 27 |
| Zig | 21 |
| SPDX | twenty |
| Futhark | 16 |
| Dhall | fifteen |
| Fidl | fourteen |
| Bosque | fourteen |
| Janet | 13 |
| Game maker project | 6 |
| Polly | 6 |
| Verilog Args File | 2 |
How many files are in the repository by language?
Addition to the previous table, but averaged by the number of files for each language in the repository. That is, how many Java files exist on average for all projects where there is Java?
Full list
| Language | Average number of files |
|---|---|
| Abap | 1,0008927583699165 |
| ASP | 1.6565139917314107 |
| ASP.NET | 346.88867258489296 |
| ATS | 7.888545610390882 |
| Awk | 5,098807478952136 |
| ActionScript | 15.682562363539644 |
| Ada | 7.265376817272021 |
| Agda | 1,2669381110755398 |
| Alchemist | 7.437307493090622 |
| Alex | 20.152479318023637 |
| Alloy | 1,0000000894069672 |
| Android Interface Definition Language | 3.1133707938643074 |
| Arvo | 9.872687772928423 |
| Asciidoc | 14,645389421879814 |
| Assembly | 1049.6270518312476 |
| AutoHotKey | 1,5361384288472488 |
| Autoconf | 33,99728695464163 |
| Bash | 3.7384110335355545 |
| Basic | 5,103623499110781 |
| Batch | 3.943513588378872 |
| Bazel | 1.0013122734382187 |
| Bitbake | 1,0878349272366024 |
| Bitbucket pipeline | one |
| Boo | 5,321822367969364 |
| Bosque | 1.28173828125 |
| Brainfuck | 1,3141119785974242 |
| Buildstream | 1,4704635441667189 |
| C | 15610,17972307699 |
| C header | 14103,33936083782 |
| C shell | 3.1231084093649315 |
| C # | 45.804460355773394 |
| C ++ | 30,416980313492328 |
| C ++ Header | 8.313450764990089 |
| CMake | 37.2566873554469 |
| COBOL | 3,129408853490878 |
| CSS | 5.332398714337156 |
| Csv | 8.370432089241898 |
| Cabal | 1.0078125149013983 |
| Cargo lock | 1.0026407549221519 |
| Cassius | 4.657169356495984 |
| Ceylon | 7,397692655679642 |
| Clojure | 8,702303821528872 |
| ClojureScript | 5.384518778099244 |
| Closure template | 1,0210028022356945 |
| CoffeeScript | 45.40906609668401 |
| Coldfusion | 13.611857060674573 |
| ColdFusion CFScript | 40,42554202020521 |
| Coq | 10,903652047164622 |
| Creole | 1.000122070313864 |
| Crystal | 3.8729367926098117 |
| Cython | 1.9811811237515262 |
| D | 529,2562750397005 |
| Dart | 1.5259554297822313 |
| Device tree | 586,4119588123021 |
| Dhall | 5.072265625 |
| Docker ignore | 1.0058596283197403 |
| Dockerfile | 1.7570825852789156 |
| Document Type Definition | 2.2977520758534693 |
| Elixir | 8,916658446524252 |
| Elm | 1,6702759813968946 |
| Emacs dev env | 15,720268315288969 |
| Emacs lisp | 11.378847912292201 |
| Erlang | 3.4764894379621607 |
| Expect | 2.8863991651091614 |
| Extensible Stylesheet Language Transformations | 1.2042068607534995 |
| F # | 1.2856606249320954 |
| F * | 32,784058919015 |
| FIDL | 1,8441162109375 |
| FORTRAN Legacy | 11,37801716560221 |
| FORTRAN Modern | 27,408192558594685 |
| Fish | 1,1282354207617833 |
| Flow9 | 5,218046229973186 |
| Forth | 10,64736177807574 |
| Fragment Shader File | 3,648087980622546 |
| Freemarker Template | 8,397226930409037 |
| Futhark | 4,671875 |
| GDScript | 3,6984173692608313 |
| GLSL | 1,6749061330076334 |
| GN | 1,0193083210608163 |
| Game Maker Language | 3,6370866431049604 |
| Game Maker Project | 1,625 |
| Gherkin Specification | 60,430588516231666 |
| Go | 115,23482489228113 |
| Go Template | 28,011342078505013 |
| Gradle | 5,628880473160033 |
| Groovy | 6,697367294187844 |
| HEX | 22,477003537989486 |
| HTML | 4,822243456786672 |
| Hamlet | 50,297887645777536 |
| Handlebars | 36,60120978679127 |
| Happy | 5,820573911044464 |
| Haskell | 8,730027121836951 |
| Haxe | 20,00590981880653 |
| IDL | 79,38510300176867 |
| Idris | 1,524684997890027 |
| Intel HEX | 113,25178379632708 |
| Isabelle | 1,8903018088753136 |
| JAI | 1,4865150753259275 |
| JSON | 6,507823973898348 |
| JSONL | 1,003931049286678 |
| JSX | 4,6359645801363465 |
| Jade | 5,353279289700571 |
| Janet | 1,0390625 |
| Java | 118,86142228014006 |
| Javascript | 140,56079100796154 |
| JavaServer Pages | 2,390251418283771 |
| Jenkins Buildfile | 1,0000000000582077 |
| Jinja | 4,574843152310338 |
| Julia | 6,672268339671913 |
| Julius | 2,2510109380818903 |
| Jupyter | 13,480476117239338 |
| Just | 1,736882857978344 |
| Korn Shell | 1,5100887455636172 |
| Kotlin | 3,9004723322169363 |
| LD Script | 16,59996086864524 |
| LESS | 39,6484785300563 |
| Lex | 5,892075421476933 |
| LOLCODE | 1,0381496530137617 |
| LaTeX | 5,336103768010524 |
| Lean | 1,6653789470747329 |
| License | 5,593879701111845 |
| Lisp | 33,15947937896521 |
| Lua | 24,796117625764612 |
| Lucius | 6,5742989471450155 |
| Luna | 4,437807061133055 |
| MQL Header | 13,515527575704464 |
| MQL4 | 6,400151428436254 |
| MQL5 | 46,489316522221515 |
| MSBuild | 4,8321384193507875 |
| MUMPS | 8,187699062741014 |
| Macromedia eXtensible Markup Language | 2,1945287114300807 |
| Madlang | 3,7857666909751373 |
| Makefile | 1518,1769808494607 |
| Mako | 3,410234685769436 |
| Markdown | 45,687500000234245 |
| Meson | 32,45071679724949 |
| Modula3 | 1,1610784588847318 |
| Module-Definition | 4,9327688042002595 |
| Monkey C | 3,035163164383345 |
| Mustache | 19,052714578803542 |
| Nim | 1,202213335585401 |
| Nix | 2,7291879559930488 |
| OCaml | 3,7135029841909697 |
| Objective C | 4,9795510788040005 |
| Objective C++ | 2,2285232767506264 |
| Opalang | 1,9975597794742732 |
| Org | 5,258117805392903 |
| Oz | 22,250069644336204 |
| Php | 199,17870638869982 |
| PKGBUILD | 7,50632295051949 |
| PSL Assertion | 3,0736406530442473 |
| Pascal | 90,55238627885495 |
| Patch | 25,331829692384225 |
| Perl | 27,46770444081142 |
| Plain text | 1119,2375825397799 |
| Polly | one |
| Pony | 3,173291031071342 |
| Powershell | 6,629884642978543 |
| Processing | 9,139907354078636 |
| Prolog | 1,816763080890156 |
| Properties File | 2,1801967863634255 |
| Protocol Buffers | 2,0456253005879304 |
| Puppet | 43,424491631161054 |
| PureScript | 4,063801504037935 |
| Python | 22,473917606983292 |
| Q# | 5,712939431518483 |
| QCL | 7,590678825974464 |
| QML | 1,255201818986247 |
| R | 2,3781868952970115 |
| Rakefile | 14,856192677576413 |
| Razor | 62,79058974450959 |
| ReStructuredText | 11,63852408056825 |
| Report Definition Language | 23,065085061465403 |
| Robot Framework | 2,6260137148703535 |
| Ruby | 554,0134362337432 |
| Ruby HTML | 24,091116656979562 |
| Rust | 2,3002003813895207 |
| SAS | 1,0032075758254648 |
| SKILL | 1,9229039972029645 |
| SPDX | 2,457843780517578 |
| SQL | 2,293643752864969 |
| SRecode Template | 20,688193360975845 |
| Svg | 4,616972531365432 |
| Sass | 42,92418345584642 |
| Scala | 1,5957851387966393 |
| Scheme | 10,480490204644848 |
| Scons | 2,1977062552968114 |
| Shell | 41,88552208947577 |
| Smarty Template | 6,90615223295527 |
| Softbridge Basic | 22,218602385698304 |
| Specman e | 2,719783829645327 |
| Spice Netlist | 2,454830619852739 |
| Standard ML (SML) | 3,7598713626650295 |
| Stata | 2,832579915520368 |
| Stylus | 7,903926412469745 |
| Swift | 54,175594149331914 |
| Swig | 2,3953681161240747 |
| SystemVerilog | 7,120705494624247 |
| Systemd | 80,83254275520476 |
| TCL | 46,9378307136513 |
| TOML | 1,0316491217260413 |
| TaskPaper | 1,0005036006351133 |
| TeX | 8,690789447558961 |
| Thrift | 1,620168483240211 |
| Twig Template | 18,33051814392764 |
| TypeScript | 1,2610517452930048 |
| TypeScript Typings | 2,3638072576034137 |
| Unreal Script | 2,9971615019965148 |
| Ur/Web | 3,420488425604595 |
| Ur/Web Project | 1,8752869585517504 |
| V | 1,8780624768245784 |
| VHDL | 5,764059992075602 |
| Vala | 42,22072166146626 |
| Varnish Configuration | 1,9899734258599446 |
| Verilog | 1,443359777332832 |
| Verilog Args File | 25.5 |
| Vertex Shader File | 2,4700152399875077 |
| Vim Script | 3,2196359799822662 |
| Visual basic | 119,8397831247842 |
| Visual Basic for Applications | 2,5806381264096503 |
| Vue | 249,0557418123258 |
| Wolfram | 1,462178856761796 |
| Wren | 227,4526259500999 |
| XAML | 2,6149608174399264 |
| XCode Config | 6,979387911493798 |
| XML | 146,10128153519918 |
| XML Schema | 6,832042266604565 |
| Xtend | 2,87054940757827 |
| YAML | 6,170148717655746 |
| Zig | 1,071681022644043 |
| Zsh | 2,6295064863912088 |
| gitignore | 6,878908416722053 |
| ignore | 1,0210649380633772 |
| m4 | 57,5969985568356 |
| nuspec | 3,245791111381787 |
| sed | 1,3985770380241234 |
How many lines of code in a typical language file?
I believe it’s still interesting to see which languages have the largest files on average? Using arithmetic mean generates abnormally high numbers due to projects like sqlite.c, which is included in many repositories, combining many files into one, but no one ever works on this one large file (I hope!)
Therefore, I calculated the average of the median. However, languages with absurdly high values, such as Bosque and JavaScript, still remained.
So I thought, why not make a knight's move? At the suggestion of Darrell (a Kablamo resident and an excellent data scientist), I made one small change and changed the arithmetic mean, dropping files over 5,000 lines to remove anomalies.
Full list
| Language | < 5000 | |
|---|---|---|
| ABAP | 139 | 36 |
| ASP | 513 | 170 |
| ASP.NET | 315 | 148 |
| ATS | 945 | 1 411 |
| AWK | 431 | 774 |
| ActionScript | 950 | 2 676 |
| Ada | 1,179 | 13 |
| Agda | 466 | 89 |
| Alchemist | 1,040 | 1 463 |
| Alex | 479 | 204 |
| Alloy | 72 | 66 |
| Android Interface Definition Language | 119 | 190 |
| Arvo | 257 | 1 508 |
| AsciiDoc | 519 | 1 724 |
| Assembly | 993 | 225 |
| AutoHotKey | 360 | 23 |
| Autoconf | 495 | 144 |
| BASH | 425 | 26 |
| Basic | 476 | 847 |
| Batch | 178 | 208 |
| Bazel | 226 | twenty |
| Bitbake | 436 | 10 |
| Bitbucket Pipeline | 19 | 13 |
| Boo | 898 | 924 |
| Bosque | 58 | 199 238 |
| Brainfuck | 141 | 177 |
| BuildStream | 1 955 | 2 384 |
| C | 1 052 | 5 774 |
| C Header | 869 | 126 460 |
| C Shell | 128 | 77 |
| C # | 1 215 | 1,138 |
| C ++ | 1 166 | 232 |
| C++ Header | 838 | 125 |
| CMake | 750 | fifteen |
| COBOL | 422 | 24 |
| CSS | 729 | 103 |
| Csv | 411 | 12 |
| Cabal | 116 | 13 |
| Cargo Lock | 814 | 686 |
| Cassius | 124 | 634 |
| Ceylon | 207 | fifteen |
| Clojure | 521 | 19 |
| ClojureScript | 504 | 195 |
| Closure Template | 343 | 75 |
| CoffeeScript | 342 | 168 |
| ColdFusion | 686 | 5 |
| ColdFusion CFScript | 1 231 | 1 829 |
| Coq | 560 | 29 250 |
| Creole | 85 | twenty |
| Crystal | 973 | 119 |
| Cython | 853 | 1 738 |
| D | 397 | 10 |
| Dart | 583 | 500 |
| Device Tree | 739 | 44 002 |
| Dhall | 124 | 99 |
| Docker ignore | 10 | 2 |
| Dockerfile | 76 | 17 |
| Document Type Definition | 522 | 1 202 |
| Elixir | 402 | 192 |
| Elm | 438 | 121 |
| Emacs Dev Env | 646 | 755 |
| Emacs Lisp | 653 | fifteen |
| Erlang | 930 | 203 |
| Expect | 419 | 195 |
| Extensible Stylesheet Language Transformations | 442 | 600 |
| F# | 384 | 64 |
| F* | 335 | 65 |
| FIDL | 655 | 1 502 |
| FORTRAN Legacy | 277 | 1 925 |
| FORTRAN Modern | 636 | 244 |
| Fish | 168 | 74 |
| Flow9 | 368 | 32 |
| Forth | 256 | 62 |
| Fragment Shader File | 309 | eleven |
| Freemarker Template | 522 | twenty |
| Futhark | 175 | 257 |
| GDScript | 401 | one |
| GLSL | 380 | 29th |
| GN | 950 | 8 866 |
| Game Maker Language | 710 | 516 |
| Game Maker Project | 1 290 | 374 |
| Gherkin Specification | 516 | 2 386 |
| Go | 780 | 558 |
| Go Template | 411 | 25 342 |
| Gradle | 228 | 22 |
| Groovy | 734 | 13 |
| HEX | 1 002 | 17 208 |
| HTML | 556 | 1 814 |
| Hamlet | 220 | 70 |
| Handlebars | 506 | 3 162 |
| Happy | 1 617 | 0 |
| Haskell | 656 | 17 |
| Haxe | 865 | 9 607 |
| IDL | 386 | 210 |
| Idris | 285 | 42 |
| Intel HEX | 1 256 | 106 650 |
| Isabelle | 792 | 1 736 |
| JAI | 268 | 41 |
| JSON | 289 | 39 |
| JSONL | 43 | 2 |
| JSX | 393 | 24 |
| Jade | 299 | 192 |
| Janet | 508 | 32 |
| Java | 1,165 | 697 |
| Javascript | 894 | 73 979 |
| JavaServer Pages | 644 | 924 |
| Jenkins Buildfile | 79 | 6 |
| Jinja | 465 | 3 914 |
| Julia | 539 | 1 031 |
| Julius | 113 | 12 |
| Jupyter | 1 361 | 688 |
| Just | 62 | 72 |
| Korn Shell | 427 | 776 |
| Kotlin | 554 | 169 |
| LD Script | 521 | 439 |
| LESS | 1 086 | 17 |
| Lex | 1 014 | 214 |
| LOLCODE | 129 | four |
| LaTeX | 895 | 7 482 |
| Lean | 181 | 9 |
| License | 266 | twenty |
| Lisp | 746 | 1 201 |
| Lua | 820 | 559 |
| Lucius | 284 | 445 |
| Luna | 85 | 48 |
| MQL Header | 793 | 10 337 |
| MQL4 | 799 | 3 168 |
| MQL5 | 384 | 631 |
| MSBuild | 558 | 160 |
| MUMPS | 924 | 98 191 |
| Macromedia eXtensible Markup Language | 500 | twenty |
| Madlang | 368 | 340 |
| Makefile | 309 | twenty |
| Mako | 269 | 243 |
| Markdown | 206 | 10 |
| Meson | 546 | 205 |
| Modula3 | 162 | 17 |
| Module-Definition | 489 | 7 |
| Monkey C | 140 | 28 |
| Mustache | 298 | 8 083 |
| Nim | 352 | 3 |
| Nix | 240 | 78 |
| OCaml | 718 | 68 |
| Objective C | 1 111 | 17 103 |
| Objective C++ | 903 | 244 |
| Opalang | 151 | 29th |
| Org | 523 | 24 |
| Oz | 360 | 7 132 |
| Php | 964 | 14 660 |
| PKGBUILD | 131 | 19 |
| PSL Assertion | 149 | 108 |
| Pascal | 1 044 | 497 |
| Patch | 676 | 12 |
| Perl | 762 | eleven |
| Plain text | 352 | 841 |
| Polly | 12 | 26 |
| Pony | 338 | 42 488 |
| Powershell | 652 | 199 |
| Processing | 800 | 903 |
| Prolog | 282 | 6 |
| Properties File | 184 | eighteen |
| Protocol Buffers | 576 | 8 080 |
| Puppet | 499 | 660 |
| PureScript | 598 | 363 |
| Python | 879 | 258 |
| Q# | 475 | 5 417 |
| QCL | 548 | 3 |
| QML | 815 | 6 067 |
| R | 566 | twenty |
| Rakefile | 122 | 7 |
| Razor | 713 | 1 842 |
| ReStructuredText | 735 | 5 049 |
| Report Definition Language | 1,389 | 34 337 |
| Robot Framework | 292 | 115 |
| Ruby | 739 | 4 942 |
| Ruby HTML | 326 | 192 |
| Rust | 1 007 | four |
| SAS | 233 | 65 |
| SKILL | 526 | 123 |
| SPDX | 1 242 | 379 |
| SQL | 466 | 143 |
| SRecode Template | 796 | 534 |
| Svg | 796 | 1 538 |
| Sass | 682 | 14 653 |
| Scala | 612 | 661 |
| Scheme | 566 | 6 |
| Scons | 545 | 6 042 |
| Shell | 304 | four |
| Smarty Template | 392 | fifteen |
| Softbridge Basic | 2 067 | 3 |
| Specman e | 127 | 0 |
| Spice Netlist | 906 | 1 465 |
| Standard ML (SML) | 478 | 75 |
| Stata | 200 | 12 |
| Stylus | 505 | 214 |
| Swift | 683 | 663 |
| Swig | 1 031 | 4 540 |
| SystemVerilog | 563 | 830 |
| Systemd | 127 | 26 |
| TCL | 774 | 42 396 |
| TOML | one hundred | 17 |
| TaskPaper | 37 | 7 |
| TeX | 804 | 905 |
| Thrift | 545 | 329 |
| Twig Template | 713 | 9 907 |
| TypeScript | 461 | 10 |
| TypeScript Typings | 1 465 | 236 866 |
| Unreal Script | 795 | 927 |
| Ur/Web | 429 | 848 |
| Ur/Web Project | 33 | 26 |
| V | 704 | 5 711 |
| VHDL | 952 | 1 452 |
| Vala | 603 | 2 |
| Varnish Configuration | 203 | 77 |
| Verilog | 198 | 2 |
| Verilog Args File | 456 | 481 |
| Vertex Shader File | 168 | 74 |
| Vim Script | 555 | 25 |
| Visual basic | 738 | 1 050 |
| Visual Basic for Applications | 979 | 936 |
| Vue | 732 | 242 |
| Wolfram | 940 | 973 |
| Wren | 358 | 279 258 |
| XAML | 703 | 24 |
| XCode Config | 200 | eleven |
| XML | 605 | 1,033 |
| XML Schema | 1 008 | 248 |
| Xtend | 710 | 120 |
| YAML | 165 | 47 327 |
| Zig | 188 | 724 |
| Zsh | 300 | 9 |
| gitignore | 33 | 3 |
| ignore | 6 | 2 |
| m4 | 959 | 807 |
| nuspec | 187 | 193 |
| sed | 82 | 33 |
Average file complexity in each language?
What is the average file complexity for each language?
In fact, complexity ratings cannot be directly correlated between languages. Excerpt from readme itself
scc
:
The complexity score is just a number that can only be matched between files in the same language. It should not be used to compare languages directly. The reason is that it is calculated by looking for branch and loop operators for each file.
Thus, languages cannot be compared with each other here, although this can be done between similar languages such as Java and C, for example.
This is a more valuable metric for individual files in the same language. Thus, you can answer the question “Is this file I'm working with easier or more complicated than the average?”
I must mention that I will be glad to suggest how to improve this metric in scc . For a commit, it is usually enough to add just a few keywords to the languages.json file, so any programmer can help.
Full list
| Language | |
|---|---|
| ABAP | 11,180740488380376 |
| ASP | 11,536947250366211 |
| ASP.NET | 2,149275320643484 |
| ATS | 0,7621728432717677 |
| AWK | 0 |
| ActionScript | 22,088579905848178 |
| Ada | 13,69141626294931 |
| Agda | 0,19536590785719454 |
| Alchemist | 0,3423442907696928 |
| Alex | 0 |
| Alloy | 6,9999997997656465 |
| Android Interface Definition Language | 0 |
| Arvo | 0 |
| AsciiDoc | 0 |
| Assembly | 1,5605608227976997 |
| AutoHotKey | 423,87785756399626 |
| Autoconf | 1,5524294972419739 |
| BASH | 7,500000094871363 |
| Basic | 1,0001350622574257 |
| Batch | 1,4136352496767306 |
| Bazel | 6,523681727119303 |
| Bitbake | 0,00391388021490391 |
| Bitbucket Pipeline | 0 |
| Boo | 65,67764583729533 |
| Bosque | 236,79837036132812 |
| Brainfuck | 27,5516445041791 |
| BuildStream | 0 |
| C | 220,17236548200242 |
| C Header | 0,027589923237434522 |
| C Shell | 1,4911166269191476 |
| C # | 1,0994400597744005 |
| C ++ | 215,23628287682845 |
| C++ Header | 2,2893104921677154 |
| CMake | 0,887660006199008 |
| COBOL | 0,018726348891789816 |
| CSS | 6,317460331175305E-176 |
| Csv | 0 |
| Cabal | 3,6547924155738194 |
| Cargo Lock | 0 |
| Cassius | 0 |
| Ceylon | 21,664400369259404 |
| Clojure | 0,00009155273437716484 |
| ClojureScript | 0,5347588658332859 |
| Closure Template | 0,503426091716392 |
| CoffeeScript | 0,02021490140137264 |
| ColdFusion | 6,851776515250336 |
| ColdFusion CFScript | 22,287403080299764 |
| Coq | 3,3282556015266307 |
| Creole | 0 |
| Crystal | 1,6065794006138856 |
| Cython | 42,87412906489837 |
| D | 0 |
| Dart | 2,1264450684815657 |
| Device Tree | 0 |
| Dhall | 0 |
| Docker ignore | 0 |
| Dockerfile | 6,158891172385556 |
| Document Type Definition | 0 |
| Elixir | 0,5000612735793482 |
| Elm | 5,237952479502043 |
| Emacs Dev Env | 1,2701271416728307E-61 |
| Emacs Lisp | 0,19531250990197657 |
| Erlang | 0,08028322620528387 |
| Expect | 0,329944610851471 |
| Extensible Stylesheet Language Transformations | 0 |
| F# | 0,32300702900710193 |
| F* | 9,403954876643223E-38 |
| FIDL | 0,12695312593132269 |
| FORTRAN Legacy | 0,8337643985574195 |
| FORTRAN Modern | 7,5833590276411185 |
| Fish | 1,3386242155247368 |
| Flow9 | 34.5 |
| Forth | 2,4664166555765066 |
| Fragment Shader File | 0,0003388836600090293 |
| Freemarker Template | 10,511094652522283 |
| Futhark | 0,8057891242233386 |
| GDScript | 10,750000000022537 |
| GLSL | 0,6383056697891334 |
| GN | 22,400601854287807 |
| Game Maker Language | 4,709514207365569 |
| Game Maker Project | 0 |
| Gherkin Specification | 0,4085178437480328 |
| Go | 50,06279203974034 |
| Go Template | 2,3866690339840662E-153 |
| Gradle | 0 |
| Groovy | 3,2506868488244898 |
| HEX | 0 |
| HTML | 0 |
| Hamlet | 0,25053861103978114 |
| Handlebars | 1,6943764911351036E-21 |
| Happy | 0 |
| Haskell | 28,470107150053625 |
| Haxe | 66,52873523714804 |
| IDL | 7,450580598712868E-9 |
| Idris | 17,77642903881352 |
| Intel HEX | 0 |
| Isabelle | 0,0014658546850726184 |
| JAI | 7,749968137734008 |
| JSON | 0 |
| JSONL | 0 |
| JSX | 0,3910405338329044 |
| Jade | 0,6881713929215119 |
| Janet | 0 |
| Java | 297,22908150612085 |
| Javascript | 1,861130583340945 |
| JavaServer Pages | 7,24235416213196 |
| Jenkins Buildfile | 0 |
| Jinja | 0,6118526458846931 |
| Julia | 5,779676990326951 |
| Julius | 3,7432448068125277 |
| Jupyter | 0 |
| Just | 1,625490248219907 |
| Korn Shell | 11,085027896435056 |
| Kotlin | 5,467347841779503 |
| LD Script | 6,538079182471746E-26 |
| LESS | 0 |
| Lex | 0 |
| LOLCODE | 5,980839657708373 |
| LaTeX | 0 |
| Lean | 0,0019872561135834133 |
| License | 0 |
| Lisp | 4,033602018074421 |
| Lua | 44,70686769972825 |
| Lucius | 0 |
| Luna | 0 |
| MQL Header | 82,8036524637758 |
| MQL4 | 2,9989408299408566 |
| MQL5 | 32,84198718928553 |
| MSBuild | 2,9802322387695312E-8 |
| MUMPS | 5,767955578948634E-17 |
| Macromedia eXtensible Markup Language | 0 |
| Madlang | 8.25 |
| Makefile | 3,9272747722381812E-90 |
| Mako | 0,007624773579836673 |
| Markdown | 0 |
| Meson | 0,3975182396400463 |
| Modula3 | 0,7517121883916386 |
| Module-Definition | 0,25000000023283153 |
| Monkey C | 9,838715311259486 |
| Mustache | 0,00004191328599945435 |
| Nim | 0,04812580073302998 |
| Nix | 25,500204694250044 |
| OCaml | 16,92218069843716 |
| Objective C | 65,08967337175548 |
| Objective C++ | 10,886891531550603 |
| Opalang | 1,3724696160763994E-8 |
| Org | 28,947825231747235 |
| Oz | 6,260657086070324 |
| Php | 2,8314653639690874 |
| PKGBUILD | 0 |
| PSL Assertion | 0,5009768009185791 |
| Pascal | four |
| Patch | 0 |
| Perl | 48,16959255514553 |
| Plain text | 0 |
| Polly | 0 |
| Pony | 4,91082763671875 |
| Powershell | 0,43151378893449877 |
| Processing | 9,691001653621564 |
| Prolog | 0,5029296875147224 |
| Properties File | 0 |
| Protocol Buffers | 0,07128906529847256 |
| Puppet | 0,16606500436341776 |
| PureScript | 1,3008141816356456 |
| Python | 11,510142201304832 |
| Q# | 5,222080192729404 |
| QCL | 13,195626304795667 |
| QML | 0,3208023407643109 |
| R | 0,40128818821921775 |
| Rakefile | 2,75786388297917 |
| Razor | 0,5298294073055322 |
| ReStructuredText | 0 |
| Report Definition Language | 0 |
| Robot Framework | 0 |
| Ruby | 7,8611656283491795 |
| Ruby HTML | 1,3175727506823756 |
| Rust | 8,62646485221385 |
| SAS | 0,5223999023437882 |
| SKILL | 0,4404907226562501 |
| SPDX | 0 |
| SQL | 0,00001537799835205078 |
| SRecode Template | 0,18119949102401853 |
| Svg | 1,7686873200833423E-74 |
| Sass | 7,002974651049148E-113 |
| Scala | 17,522343645163424 |
| Scheme | 0,00003147125255509322 |
| Scons | 25,56868253610655 |
| Shell | 6,409446969197895 |
| Smarty Template | 53,06143077491294 |
| Softbridge Basic | 7.5 |
| Specman e | 0,0639350358484781 |
| Spice Netlist | 1,3684555315672042E-48 |
| Standard ML (SML) | 24,686901116754818 |
| Stata | 1,5115316917094068 |
| Stylus | 0,3750006556512421 |
| Swift | 0,5793484510104517 |
| Swig | 0 |
| SystemVerilog | 0,250593163372906 |
| Systemd | 0 |
| TCL | 96,5072605676113 |
| TOML | 0,0048828125000002776 |
| TaskPaper | 0 |
| TeX | 54,0588040258797 |
| Thrift | 0 |
| Twig Template | 2,668124511961211 |
| TypeScript | 9,191392608918255 |
| TypeScript Typings | 6,1642456222327375 |
| Unreal Script | 2,7333421227943004 |
| Ur/Web | 16,51621568240534 |
| Ur/Web Project | 0 |
| V | 22,50230618938804 |
| VHDL | 18,05495198571289 |
| Vala | 147,2761703068509 |
| Varnish Configuration | 0 |
| Verilog | 5,582400367711671 |
| Verilog Args File | 0 |
| Vertex Shader File | 0,0010757446297590262 |
| Vim Script | 2,4234658314493798 |
| Visual basic | 0,0004882812500167852 |
| Visual Basic for Applications | 4,761343429454877 |
| Vue | 0,7529517744621779 |
| Wolfram | 0,0059204399585724215 |
| Wren | 0,08593750013097715 |
| XAML | 6,984919309616089E-10 |
| XCode Config | 0 |
| XML | 0 |
| XML Schema | 0 |
| Xtend | 2,8245844719990547 |
| YAML | 0 |
| Zig | 1,0158334437942358 |
| Zsh | 1,81697392626756 |
| gitignore | 0 |
| ignore | 0 |
| m4 | 0 |
| nuspec | 0 |
| sed | 22,91158285739948 |
Average number of comments for files in each language?
What is the average number of comments in files in each language?
Perhaps the question can be rephrased: the developers in which language write the most comments, suggesting a misunderstanding of the reader.
Full list
| Language | Comments |
|---|---|
| ABAP | 56,3020026683825 |
| ASP | 24,67145299911499 |
| ASP.NET | 9,140447860406259E-11 |
| ATS | 41,89465025163305 |
| AWK | 11,290069486393975 |
| ActionScript | 31,3568633027012 |
| Ada | 61,269572412982384 |
| Agda | 2,4337660860304755 |
| Alchemist | 2,232399710231226E-103 |
| Alex | 0 |
| Alloy | 0,000002207234501959681 |
| Android Interface Definition Language | 26,984662160277367 |
| Arvo | 0 |
| AsciiDoc | 0 |
| Assembly | 2,263919769706678E-72 |
| AutoHotKey | 15,833985920534857 |
| Autoconf | 0,47779749499136687 |
| BASH | 34,15625059662068 |
| Basic | 1,4219117348874069 |
| Batch | 1,0430908205926455 |
| Bazel | 71,21859817579139 |
| Bitbake | 0,002480246487177871 |
| Bitbucket Pipeline | 0,567799577547725 |
| Boo | 5,03128187009327 |
| Bosque | 0,125244140625 |
| Brainfuck | 0 |
| BuildStream | 12,84734197699206 |
| C | 256,2839210573451 |
| C Header | 184,88885430308878 |
| C Shell | 5,8409870392823375 |
| C # | 30,96563720101839 |
| C ++ | 44,61584829131642 |
| C++ Header | 27,578790410119197 |
| CMake | 1,7564333047949374 |
| COBOL | 0,7503204345703562 |
| CSS | 4,998773531463529 |
| Csv | 0 |
| Cabal | 4,899812531420634 |
| Cargo Lock | 0,0703125 |
| Cassius | 0,07177734654413487 |
| Ceylon | 3,6406326349824667 |
| Clojure | 0,0987220821845421 |
| ClojureScript | 0,6025725119252456 |
| Closure Template | 17,078124673988057 |
| CoffeeScript | 1,6345682790069884 |
| ColdFusion | 33,745563628665096 |
| ColdFusion CFScript | 13,566947396771592 |
| Coq | 20,3222774725393 |
| Creole | 0 |
| Crystal | 6,0308081267588145 |
| Cython | 21,0593019957583 |
| D | 0 |
| Dart | 4,634361584097128 |
| Device Tree | 33,64898256434121 |
| Dhall | 1,0053101042303751 |
| Docker ignore | 8,003553375601768E-11 |
| Dockerfile | 4,526245545632278 |
| Document Type Definition | 0 |
| Elixir | 8,0581139370409 |
| Elm | 24,73191350743249 |
| Emacs Dev Env | 2,74822998046875 |
| Emacs Lisp | 12,168370702306452 |
| Erlang | 16,670030919109056 |
| Expect | 3,606161126133445 |
| Extensible Stylesheet Language Transformations | 0 |
| F# | 0,5029605040200058 |
| F* | 5,33528354690743E-27 |
| FIDL | 343,0418392068642 |
| FORTRAN Legacy | 8,121405267242158 |
| FORTRAN Modern | 171,32042583820953 |
| Fish | 7,979248739519377 |
| Flow9 | 0,5049991616979244 |
| Forth | 0,7578125 |
| Fragment Shader File | 0,2373057885016209 |
| Freemarker Template | 62,250244379050855 |
| Futhark | 0,014113984877253714 |
| GDScript | 31,14457228694065 |
| GLSL | 0,2182627061047912 |
| GN | 17,443267241931284 |
| Game Maker Language | 3,9815753922640824 |
| Game Maker Project | 0 |
| Gherkin Specification | 0,0032959059321794604 |
| Go | 6,464829990599041 |
| Go Template | 4,460169822267483E-251 |
| Gradle | 0,5374194774415457 |
| Groovy | 32,32068506016523 |
| HEX | 0 |
| HTML | 0,16671794164614084 |
| Hamlet | 4,203293477836184E-24 |
| Handlebars | 0,9389737429747177 |
| Happy | 0 |
| Haskell | 20,323476462551376 |
| Haxe | 9,023509566990532 |
| IDL | 1,01534495399968 |
| Idris | 0,36279318680267497 |
| Intel HEX | 0 |
| Isabelle | 4,389802167076498 |
| JAI | 2,220446049250313E-16 |
| JSON | 0 |
| JSONL | 0 |
| JSX | 0,9860839844113964 |
| Jade | 0,25000000000034117 |
| Janet | 9,719207406044006 |
| Java | 330,66188089718935 |
| Javascript | 22,102491285372537 |
| JavaServer Pages | 4,31250095370342 |
| Jenkins Buildfile | 0 |
| Jinja | 2,5412145720173454E-50 |
| Julia | 12,542627036271085 |
| Julius | 0,24612165248208867 |
| Jupyter | 0 |
| Just | 0,3186038732601446 |
| Korn Shell | 40,89005232702741 |
| Kotlin | 0,3259347784770708 |
| LD Script | 3,7613336386434204 |
| LESS | 15,495439701029127 |
| Lex | 55,277186392539086 |
| LOLCODE | 13,578125958700468 |
| LaTeX | 3,316717967334341 |
| Lean | 21,194565176965895 |
| License | 0 |
| Lisp | 88,10676444837796 |
| Lua | 76,67247973843406 |
| Lucius | 0,3894241626790286 |
| Luna | 16,844066019174637 |
| MQL Header | 82,22436339969337 |
| MQL4 | 1,957314499740677 |
| MQL5 | 27,463183855085845 |
| MSBuild | 0,19561428198176206 |
| MUMPS | 5,960464477541773E-8 |
| Macromedia eXtensible Markup Language | 0 |
| Madlang | 6,75 |
| Makefile | 1,2287070602578574 |
| Mako | 1,3997604187154047E-8 |
| Markdown | 0 |
| Meson | 4,594536366188615 |
| Modula3 | 3,4375390004645627 |
| Module-Definition | 7,754887182446689 |
| Monkey C | 0,02734480644075532 |
| Mustache | 0,0000038370490074157715 |
| Nim | 0,8432132130061808 |
| Nix | 165,09375 |
| OCaml | 27,238212826702338 |
| Objective C | 32,250000004480256 |
| Objective C++ | 4,688333711547599 |
| Opalang | 3,2498599900436704 |
| Org | 2,4032862186444435 |
| Oz | 11,531631554476924 |
| Php | 0,37573912739754056 |
| PKGBUILD | 0 |
| PSL Assertion | 4,470348358154297E-7 |
| Pascal | 274,7797153576955 |
| Patch | 0 |
| Perl | 42,73014043490598 |
| Plain text | 0 |
| Polly | 0 |
| Pony | 0,2718505859375 |
| Powershell | 2,0956492198317282 |
| Processing | 11,358358417519032 |
| Prolog | 6,93889390390723E-17 |
| Properties File | 4,297774864451927 |
| Protocol Buffers | 5,013992889700926 |
| Puppet | 1,9962931947466012 |
| PureScript | 6,608705271035433 |
| Python | 15,208443286809963 |
| Q# | 0,4281108849922295 |
| QCL | 13,880147817629737 |
| QML | 16,17036877582475 |
| R | 5,355639399818855 |
| Rakefile | 0,4253943361101697 |
| Razor | 0,2500305203720927 |
| ReStructuredText | 0 |
| Report Definition Language | 1,8589575837924928E-119 |
| Robot Framework | 0 |
| Ruby | 8,696056880656087 |
| Ruby HTML | 0,031281024218515086 |
| Rust | 22,359375028118006 |
| SAS | 0,7712382248290134 |
| SKILL | 0,002197265625 |
| SPDX | 0 |
| SQL | 0,4963180149979617 |
| SRecode Template | 17,64534428715706 |
| Svg | 0,780306812508952 |
| Sass | 1,6041624981030795 |
| Scala | 2,7290137764062656 |
| Scheme | 18,68675828842983 |
| Scons | 9,985132321266597 |
| Shell | 19,757167057040007 |
| Smarty Template | 0,0009841919236350805 |
| Softbridge Basic | 4,76177694441164E-25 |
| Specman e | 0,1925095270881778 |
| Spice Netlist | 5,29710110812646 |
| Standard ML (SML) | 0,20708566564292288 |
| Stata | 0,04904100534194722 |
| Stylus | 4,534405773074049 |
| Swift | 1,8627019961192913E-9 |
| Swig | 11,786422730001505 |
| SystemVerilog | 0,00009708851624323821 |
| Systemd | 0 |
| TCL | 382,839838598133 |
| TOML | 0,37500173695180483 |
| TaskPaper | 0 |
| TeX | 8,266233975096164 |
| Thrift | 50,53134153016524 |
| Twig Template | 0 |
| TypeScript | 8,250029131770134 |
| TypeScript Typings | 37,89904005334354 |
| Unreal Script | 46,13322029508541 |
| Ur/Web | 0,04756343913582129 |
| Ur/Web Project | 6,776263578034403E-21 |
| V | 28,75797889154211 |
| VHDL | 37,47892257625405 |
| Vala | 74,26528331441615 |
| Varnish Configuration | 19,45791923156868 |
| Verilog | 4,165537942430622 |
| Verilog Args File | 0 |
| Vertex Shader File | 1,7979557178975683 |
| Vim Script | 0 |
| Visual basic | 0,26300267116040704 |
| Visual Basic for Applications | 0,3985138943535276 |
| Vue | 5,039982162930666E-52 |
| Wolfram | 70,01674025323683 |
| Wren | 30694,003311276458 |
| XAML | 0,5000169009533838 |
| XCode Config | 13,653495818959595 |
| XML | 3,533205032457776 |
| XML Schema | 0 |
| Xtend | 19,279739396268607 |
| YAML | 1,1074293861154887 |
| Zig | 0,507775428428431 |
| Zsh | 6,769231127673729 |
| gitignore | 1,3347179947709417E-20 |
| ignore | 0,0356445312500015 |
| m4 | 5,4183238737327075 |
| nuspec | 3,640625 |
| sed | 6,423678000929861 |
What are the most common file names?
What file names are most common in all codebases, ignoring the extension and case?
If you asked me earlier, I would say: README, main, index, license. The results pretty well reflect my assumptions. Although there is a lot of interesting things. I have no idea why so many projects contain a file called
15
or
s15
.
The most common makefile surprised me a bit, but then I remembered that it was used in many new JavaScript projects. Another interesting thing to note: it seems that jQuery is still on the horse, and the reports of his death are greatly exaggerated, and he is in fourth place on the list.
Full list
| file-name | count |
|---|---|
| makefile | 59 141 098 |
| index | 33 962 093 |
| readme | 22 964 539 |
| jquery | 20 015 171 |
| main | 12 308 009 |
| package | 10 975 828 |
| license | 10 441 647 |
| __init__ | 10 193 245 |
| strings | 8 414 494 |
| android | 7 915 225 |
| config | 7 391 812 |
| default | 5 563 255 |
| build | 5 510 598 |
| setup | 5 291 751 |
| test | 5 282 106 |
| irq | 4 914 052 |
| fifteen | 4 295 032 |
| country | 4 274 451 |
| pom | 4 054 543 |
| io | 3 642 747 |
| system | 3 629 821 |
| common | 3 629 698 |
| gpio | 3 622 587 |
| core | 3 571 098 |
| module | 3 549 789 |
| init | 3 378 919 |
| dma | 3 301 536 |
| bootstrap | 3 162 859 |
| application | 3 000 210 |
| time | 2 928 715 |
| cmakelists | 2 907 539 |
| plugin | 2 881 206 |
| base | 2 805 340 |
| s15 | 2 733 747 |
| androidmanifest | 2 727 041 |
| cache | 2 695 345 |
| debug | 2 687 902 |
| file | 2 629 406 |
| app | 2 588 208 |
| version | 2 580 288 |
| assemblyinfo | 2 485 708 |
| exception | 2 471 403 |
| project | 2 432 361 |
| util | 2 412 138 |
| user | 2 343 408 |
| clock | 2 283 091 |
| timex | 2 280 225 |
| pci | 2 231 228 |
| style | 2 226 920 |
| styles | 2 212 127 |
Please note that due to memory limitations, I made this process a little less accurate. After every 100 projects, I checked the map and deleted the names of files that occurred less than 10 times from the list. They could return to the next test, and if they met more than 10 times, they remained on the list. Perhaps some results have some error if some common name rarely appeared in the first batch of repositories before becoming common. In short, these are not absolute numbers, but should be close enough to them.
I could use the prefix tree to “squeeze” the space and get the absolute numbers, but I didn’t want to write it, so I slightly abused the map to save enough memory and get the result. However, it will be quite interesting to try the prefix tree later.
How many repositories are missing a license?
It is very interesting. How many repositories have at least some explicit license file? Please note that the absence of a license file here does not mean that the project does not have it, since it can exist in the README file or can be indicated through SPDX comment tags in lines. It simply means that
scc
it could not find the explicit license file using its own criteria. Currently, such files are considered to be “license”, “license”, “copying”, “copying3”, “unlicense”, “unlicence”, “license-mit”, “license-mit” or “copyright” files.
Unfortunately, the vast majority of repositories do not have a license. I would say that there are many reasons why any software needs a license, but someone else said it for me.
| Got a license? | amount |
|---|---|
| no | 6 502 753 |
| there is | 2 597 330 |
How many projects use multiple .gitignore files?
Some may not know this, but there may be several .gitignore files in a git project. With this in mind, how many projects use multiple .gitignore files? But at the same time, how many have not a single one?
I found a rather interesting project with 25,794 .gitignore files in the repository. The next result was 2547. I have no idea what is going on there. I glanced briefly: it seems that they are used to check directories, but I can’t confirm this.
Returning to the data, here is a graph of repositories with up to 20 .gitignore files, which covers 99% of all projects.
As expected, most projects have 0 or 1 .gitignore files. This is confirmed by a massive tenfold drop in the number of projects with 2 files. What surprised me was how many projects have more than one .gitignore file. The long tail in this case is especially long.
I was curious why some projects have thousands of such files. One of the main troublemakers is the fork https://github.com/PhantomX/slackbuilds : each of them has about 2547 .gitignore files. The following are other repositories with more than a thousand .gitignore files.
- 25,794 files: https://github.com/knot-git/rrs_publication_ocr
- 1523 files: https://github.com/brunosimon/hetic
- 1267 files: https://github.com/par4all/par4all
- 1186 : https://github.com/ramonluis1987/code_school
- 1133 : https://github.com/signed/license-maven-plugin
| .gitignore | |
|---|---|
| 0 | 3 628 829 |
| one | 4 576 435 |
| 2 | 387 748 |
| 3 | 136 641 |
| four | 79 808 |
| 5 | 48 336 |
| 6 | 33 686 |
| 7 | 33 408 |
| 8 | 22 571 |
| 9 | 16 453 |
| 10 | 11 198 |
| eleven | 10 070 |
| 12 | 8 194 |
| 13 | 7 701 |
| fourteen | 5 040 |
| fifteen | 4 320 |
| 16 | 5 905 |
| 17 | 4 156 |
| eighteen | 4 542 |
| 19 | 3,828 |
| twenty | 2 706 |
| 21 | 2 449 |
| 22 | 1 975 |
| 23 | 2 255 |
| 24 | 2 060 |
| 25 | 1,768 |
| 26 | 2 886 |
| 27 | 2 648 |
| 28 | 2 690 |
| 29th | 1 949 |
| thirty | 1,677 |
| 31 | 3 348 |
| 32 | 1,176 |
| 33 | 794 |
| 34 | 1,153 |
| 35 | 845 |
| 36 | 488 |
| 37 | 627 |
| 38 | 533 |
| 39 | 502 |
| 40 | 398 |
| 41 | 370 |
| 42 | 355 |
| 43 | 1 002 |
| 44 | 265 |
| 45 | 262 |
| 46 | 295 |
| 47 | 178 |
| 48 | 384 |
| 49 | 270 |
| fifty | 189 |
| 51 | 435 |
| 52 | 202 |
| 53 | 196 |
| 54 | 325 |
| 55 | 253 |
| 56 | 320 |
| 57 | 126 |
| 58 | 329 |
| 59 | 286 |
| 60 | 292 |
| 61 | 152 |
| 62 | 237 |
| 63 | 163 |
| 64 | 149 |
| 65 | 187 |
| 66 | 164 |
| 67 | 92 |
| 68 | 80 |
| 69 | 138 |
| 70 | 102 |
| 71 | 68 |
| 72 | 62 |
| 73 | 178 |
| 74 | 294 |
| 75 | 89 |
| 76 | 118 |
| 77 | 110 |
| 78 | 319 |
| 79 | 843 |
| 80 | 290 |
| 81 | 162 |
| 82 | 127 |
| 83 | 147 |
| 84 | 170 |
| 85 | 275 |
| 86 | 1 290 |
| 87 | 614 |
| 88 | 4 014 |
| 89 | 2 275 |
| 90 | 775 |
| 91 | 3 630 |
| 92 | 362 |
| 93 | 147 |
| 94 | 110 |
| 95 | 71 |
| 96 | 75 |
| 97 | 62 |
| 98 | 228 |
| 99 | 71 |
| one hundred | 174 |
| 101 | 545 |
| 102 | 304 |
| 103 | 212 |
| 104 | 284 |
| 105 | 516 |
| 106 | 236 |
| 107 | 39 |
| 108 | 69 |
| 109 | 131 |
| 110 | 82 |
| 111 | 102 |
| 112 | 465 |
| 113 | 621 |
| 114 | 47 |
| 115 | 59 |
| 116 | 43 |
| 117 | 40 |
| 118 | 43 |
| 119 | 443 |
| 120 | 72 |
| 121 | 42 |
| 122 | 33 |
| 123 | 392 |
| 124 | 66 |
| 125 | 46 |
| 126 | 381 |
| 127 | 19 |
| 128 | 99 |
| 129 | 906 |
| 130 | 52 |
| 131 | 19 |
| 132 | eleven |
| 133 | 99 |
| 134 | 10 |
| 135 | fifteen |
| 136 | 6 |
| 137 | 22 |
| 138 | 44 |
| 139 | 33 |
| 140 | 24 |
| 141 | 33 |
| 142 | 39 |
| 143 | 48 |
| 144 | 80 |
| 145 | twenty |
| 146 | 28 |
| 147 | 19 |
| 148 | 17 |
| 149 | eleven |
| 150 | twenty |
| 151 | 57 |
| 152 | 35 |
| 153 | 24 |
| 154 | 31 |
| 155 | 35 |
| 156 | 55 |
| 157 | 89 |
| 158 | 57 |
| 159 | 88 |
| 160 | eighteen |
| 161 | 47 |
| 162 | 56 |
| 163 | 36 |
| 164 | 63 |
| 165 | 99 |
| 166 | 44 |
| 167 | 64 |
| 168 | 86 |
| 169 | 70 |
| 170 | 111 |
| 171 | 106 |
| 172 | 25 |
| 173 | 39 |
| 174 | fourteen |
| 175 | 25 |
| 176 | 53 |
| 177 | twenty |
| 178 | 56 |
| 179 | eleven |
| 180 | 7 |
| 181 | 40 |
| 182 | 32 |
| 183 | 17 |
| 184 | 68 |
| 185 | 38 |
| 186 | 16 |
| 187 | 3 |
| 188 | four |
| 189 | 2 |
| 190 | 12 |
| 191 | eighteen |
| 192 | 37 |
| 193 | 9 |
| 194 | 10 |
| 195 | eleven |
| 196 | eighteen |
| 197 | 45 |
| 198 | 27 |
| 199 | eleven |
| 200 | 39 |
| 201 | 23 |
| 202 | 37 |
| 203 | 22 |
| 204 | 21 |
| 205 | 7 |
| 206 | 40 |
| 207 | 7 |
| 208 | 8 |
| 209 | 16 |
| 210 | 29th |
| 211 | twenty |
| 212 | 21 |
| 213 | 7 |
| 214 | four |
| 215 | 12 |
| 217 | 21 |
| 218 | 13 |
| 220 | 12 |
| 221 | 2 |
| 222 | fifteen |
| 223 | four |
| 224 | 12 |
| 225 | 9 |
| 226 | one |
| 227 | 8 |
| 228 | 3 |
| 229 | 6 |
| 230 | 8 |
| 231 | 31 |
| 232 | 26 |
| 233 | 6 |
| 234 | 17 |
| 235 | 6 |
| 236 | 23 |
| 237 | one |
| 238 | eleven |
| 239 | 2 |
| 240 | 10 |
| 241 | 7 |
| 242 | eleven |
| 243 | one |
| 244 | fourteen |
| 245 | 21 |
| 246 | 3 |
| 247 | 12 |
| 248 | one |
| 249 | 6 |
| 250 | 10 |
| 251 | 5 |
| 252 | eighteen |
| 253 | 7 |
| 254 | 17 |
| 255 | four |
| 256 | 16 |
| 257 | 8 |
| 258 | 24 |
| 259 | 17 |
| 260 | four |
| 261 | one |
| 262 | 3 |
| 263 | 12 |
| 264 | 3 |
| 265 | 8 |
| 267 | 2 |
| 268 | one |
| 269 | 3 |
| 271 | four |
| 272 | one |
| 273 | one |
| 274 | one |
| 275 | 3 |
| 276 | 6 |
| 279 | 5 |
| 280 | one |
| 281 | one |
| 284 | four |
| 285 | one |
| 286 | one |
| 288 | 2 |
| 289 | one |
| 290 | 5 |
| 291 | four |
| 293 | 7 |
| 294 | four |
| 295 | one |
| 296 | one |
| 297 | one |
| 299 | 70 |
| 300 | 2 |
| 301 | four |
| 302 | one |
| 303 | 7 |
| 305 | one |
| 306 | 2 |
| 307 | 2 |
| 309 | one |
| 310 | 7 |
| 311 | one |
| 313 | fourteen |
| 316 | one |
| 320 | one |
| 321 | 6 |
| 322 | 2 |
| 323 | 3 |
| 324 | four |
| 327 | four |
| 328 | 2 |
| 329 | one |
| 330 | 13 |
| 331 | 5 |
| 332 | eleven |
| 333 | 3 |
| 334 | one |
| 335 | one |
| 336 | eleven |
| 337 | one |
| 338 | twenty |
| 339 | eleven |
| 340 | 2 |
| 341 | 6 |
| 342 | 10 |
| 343 | 37 |
| 344 | 25 |
| 345 | 9 |
| 346 | 32 |
| 347 | four |
| 348 | 9 |
| 349 | 7 |
| 350 | 12 |
| 351 | 2 |
| 352 | 5 |
| 354 | 7 |
| 358 | 32 |
| 359 | 7 |
| 360 | 6 |
| 361 | one |
| 362 | 21 |
| 363 | fourteen |
| 364 | 51 |
| 365 | 17 |
| 367 | eighteen |
| 368 | 9 |
| 370 | 7 |
| 371 | 6 |
| 372 | fifteen |
| 373 | one |
| 374 | 38 |
| 375 | 113 |
| 376 | 57 |
| 377 | 37 |
| 378 | 23 |
| 379 | 87 |
| 380 | 65 |
| 382 | one |
| 386 | 2 |
| 388 | one |
| 391 | 5 |
| 392 | one |
| 394 | one |
| 397 | 3 |
| 401 | one |
| 403 | one |
| 408 | one |
| 409 | 2 |
| 410 | 5 |
| 411 | one |
| 413 | four |
| 415 | one |
| 418 | one |
| 420 | one |
| 427 | 3 |
| 428 | 2 |
| 430 | 2 |
| 433 | 314 |
| 437 | one |
| 450 | 2 |
| 453 | one |
| 468 | one |
| 469 | one |
| 483 | 5 |
| 484 | one |
| 486 | one |
| 488 | 2 |
| 489 | 9 |
| 490 | four |
| 492 | 2 |
| 493 | 106 |
| 494 | 3 |
| 495 | one |
| 496 | 2 |
| 498 | one |
| 512 | one |
| 539 | one |
| 553 | one |
| 560 | 2 |
| 570 | 2 |
| 600 | one |
| 602 | 3 |
| 643 | one |
| 646 | 2 |
| 657 | one |
| 663 | one |
| 670 | one |
| 672 | 2 |
| 729 | 5 |
| 732 | one |
| 739 | one |
| 744 | one |
| 759 | one |
| 778 | one |
| 819 | one |
| 859 | one |
| 956 | one |
| 959 | 2 |
| 964 | 2 |
| 965 | one |
| 973 | one |
| 1 133 | one |
| 1 186 | one |
| 1 267 | 2 |
| 1 523 | one |
| 2,535 | one |
| 2 536 | one |
| 2,537 | 2 |
| 2 539 | one |
| 2 540 | one |
| 2 541 | 5 |
| 2 542 | one |
| 2,545 | one |
| 2 547 | one |
| 25 794 | one |
?
This section is not an exact science, but belongs to the class of problems of natural language processing. Searching for abusive or abusive terms in a specific list of files will never be effective. If you search with a simple search, you will find many ordinary files like
assemble.sh
and so on. So I took a list of curses and then checked if any files in each project start with one of these values followed by a dot. This means that the file named
gangbang.java
will be taken into account, but
assemble.sh
not. However, he will miss many varied options, such as
pu55syg4rgle.java
other equally crude names.
My list contains some words on leetspeak, such as
b00bs
and
b1tch
, to catch some of the interesting cases. Full list here.
Although this is not entirely accurate, as already mentioned, it is incredibly interesting to look at the result. Let's start with the list of languages in which the most curses. You should probably correlate the result with the total amount of code in each language. So here are the leaders.
| Language | Swear File Names | File percentage |
|---|---|---|
| C header | 7660 | 0.00126394567906% |
| Java | 7023 | 0.00258792635479% |
| C | 6897 | 0.00120706524533% |
| Php | 5713 | 0.00283428484703% |
| Javascript | 4306 | 0.00140692338568% |
| HTML | 3560 | 0.00177646776919% |
| Ruby | 3121 | 0.00223136542655% |
| Json | 1598 | 0.00293688627715% |
| C ++ | 1543 | 0.00135977378652% |
| Dart | 1533 | 0.19129310646% |
| Rust | 1504 | 0.038465935524% |
| Go template | 1500 | 0.0792233157387% |
| Svg | 1234 | 0.00771043360379% |
| XML | 1212 | 0,000875741051608% |
| Python | 1092 | 0.00119138129893% |
| JavaServer Pages | 1037 | 0.0215440542669% |
Interesting!My first thought was: “Oh, these naughty C developers!” But despite the large number of such files, they write so much code that the percentage of curses is lost in the total. However, it’s pretty clear that Dart developers have a few words in their arsenal! If you know one of the Dart programmers, you can shake his hand.
I also want to know what are the most commonly used curses. Let's look at a common dirty collective mind. Some of the best that I found were normal names (if you squint), but most of the rest will certainly surprise colleagues and some comments in the pool requests.
| Word | amount |
|---|---|
| ass | 11 358 |
| knob | 10 368 |
| balls | 8001 |
| xxx | 7205 |
| sex | 5021 |
| nob | 3385 |
| pawn | 2919 |
| hell | 2819 |
| crap | 1112 |
| anal | 950 |
| snatch | 885 |
| fuck | 572 |
| poop | 510 |
| cox | 476 |
| shit | 383 |
| lust | 367 |
| butt | 265 |
| bum | 151 |
| bugger | 132 |
| pron | 121 |
| cum | 118 |
| cok | 112 |
| damn | 105 |
Note that some of the more offensive words on the list did have matching file names, which I find pretty shocking. Fortunately, they are not very common and are not included in the list above, which is limited to files with the number of more than 100. I hope that these files exist only for testing allow / deny lists and the like.
The largest files by the number of lines in each language
As expected, plaintext, SQL, XML, JSON, and CSV occupy the top positions: they usually contain metadata, database dumps, and the like.
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
Full list
| Language | File name | |
|---|---|---|
| Plain text | 1366100696temp.txt | 347 671 811 |
| Php | phpfox_error_log_04_04_12_3d4b11f6ee2a89fd5ace87c910cee04b.php | 121 930 973 |
| HTML | yo.html | 54 596 752 |
| Lex | l | 39 743 785 |
| XML | dblp.xml | 39 445 222 |
| Autoconf | 21-t2.in | 33 526 784 |
| Csv | ontology.csv | 31 946 031 |
| Prolog | top500_full.p | 22 428 770 |
| Javascript | mirus.js | 22 023 354 |
| JSON | douglasCountyVoterRegistration.json | 21 104 668 |
| Game Maker Language | lg.gml | 13 302 632 |
| C Header | trk6data.h | 13 025 371 |
| Objective C++ | review-1.mm | 12 788 052 |
| SQL | newdump.sql | 11 595 909 |
| Patch | clook_iosched-team01.patch | 10 982 879 |
| YAML | data.yml | 10 764 489 |
| Svg | large-file.svg | 10 485 763 |
| Sass | large_empty.scss | 10,000,000 |
| Assembly | Js | 8 388 608 |
| LaTeX | tex | 8 316 556 |
| C++ Header | primpoly_impl.hh | 8 129 599 |
| Lisp | simN.lsp | 7 233 972 |
| Perl | aimlCore3.pl | 6 539 759 |
| SAS | output.sas | 5 874 153 |
| C | CathDomainDescriptionFile.v3.5.c | 5 440 052 |
| Lua | giant.lua | 5 055 019 |
| R | disambisearches.R | 4 985 492 |
| MUMPS | ref.mps | 4 709 289 |
| HEX | combine.hex | 4 194 304 |
| Python | mappings.py | 3 064 594 |
| Scheme | atomspace.scm | 3 027 366 |
| C ++ | Int.cpp | 2 900 609 |
| Properties File | nuomi_active_user_ids.properties | 2 747 671 |
| Alex | Dalek.X | 2 459 209 |
| TCL | TCL | 2 362 970 |
| Ruby | smj_12_2004.rb | 2 329 560 |
| Wolfram | hmm.nb | 2 177 422 |
| Brainfuck | BF | 2 097 158 |
| TypeScript | all_6.ts | 1 997 637 |
| Module-Definition | matrix.def | 1 948 817 |
| LESS | less | 1 930 356 |
| Objective C | faster.m | 1 913 966 |
| Org | default.org | 1 875 096 |
| Jupyter | ReHDDM — AllGo sxFits-Copy0.ipynb | 1 780 197 |
| Specman e | twitter.e | 1 768 135 |
| F* | Pan_troglodytes_monomers.fst | 1 739 878 |
| Systemd | video_clean_lower_tokenized.target | 1 685 570 |
| V | ImageMazeChannelValueROM.v | 1 440 068 |
| Markdown | eukaryota.md | 1 432 161 |
| TeX | japanischtest.tex | 1 337 456 |
| Forth | europarl.tok.fr | 1 288 074 |
| Shell | add_commitids_to_src.sh | 1 274 873 |
| SKILL | hijacked.il | 1 187 701 |
| CSS | 7f116c3.css | 1 170 216 |
| C # | Form1.cs | 1 140 480 |
| gitignore | .gitignore | 1 055 167 |
| Boo | 3.out.tex | 1 032 145 |
| Java | Monster.java | 1 000 019 |
| ActionScript | as | 1,000,000 |
| MSBuild | train.props | 989 860 |
| D | D | 883 308 |
| Coq | CompiledDFAs.v | 873 354 |
| Clojure | raw-data.clj | 694 202 |
| Swig | 3DEditor.i | 645 117 |
| Happy | y | 624 673 |
| GLSL | capsid.vert | 593 618 |
| Verilog | pipeline.vg | 578 418 |
| Standard ML (SML) | Ambit3-HRVbutNoHR.sml | 576 071 |
| SystemVerilog | bitcoinminer.v | 561 974 |
| Visual basic | linqStoreProcs.designer.vb | 561 067 |
| Go | info.go | 559 236 |
| Expect | Argonne_hourly_dewpoint.exp | 552 269 |
| Erlang | sdh_analogue_data.erl | 473 924 |
| Makefile | Makefile | 462 433 |
| QML | 2005.qml | 459 113 |
| SPDX | linux-coreos.spdx | 444 743 |
| VHDL | cpuTest.vhd | 442 043 |
| ASP.NET | AllProducts.aspx | 438 423 |
| XML Schema | AdvanceShipNotices.xsd | 436 055 |
| Elixir | gene.train.with.rare.ex | 399 995 |
| Macromedia eXtensible Markup Language | StaticFlex4PerformanceTest20000.mxml | 399 821 |
| Ada | bmm_top.adb | 390 275 |
| TypeScript Typings | dojox.d.ts | 384 171 |
| Pascal | FHIR.R4.Resources.pas | 363 291 |
| COBOL | cpy | 358 745 |
| Basic | excel-vba-streams-#1.bas | 333 707 |
| Visual Basic for Applications | Dispatcher.cls | 332 266 |
| Puppet | main_110.pp | 314 217 |
| FORTRAN Legacy | f | 313 599 |
| OCaml | Pent.ML | 312 749 |
| FORTRAN Modern | slatec.f90 | 298 677 |
| CoffeeScript | dictionary.coffee | 271 378 |
| Nix | hackage-packages.nix | 259 940 |
| Intel HEX | epdc_ED060SCE.fw.ihex | 253 836 |
| Scala | models_camaro.sc | 253 559 |
| Julia | IJulia 0 .jl | 221 058 |
| SRecode Template | espell.srt | 216 243 |
| sed | CSP-2004fe.SED | 214 290 |
| ReStructuredText | S40HO033.rst | 211 403 |
| Bosque | world_dem_5arcmin_geo.bsq | 199 238 |
| Emacs Lisp | ubermacros.el | 195 861 |
| F# | Ag_O1X5.5_O2X0.55.eam.fs | 180 008 |
| GDScript | 72906.gd | 178 628 |
| Gherkin Specification | feature | 175 229 |
| Haskell | Excel.hs | 173 039 |
| Dart | surnames_list.dart | 153 144 |
| Bazel | matplotlib_1.3.1-1_amd64-20140427-1441.build | 149 234 |
| Haxe | elf-x86id.hx | 145 800 |
| IDL | all-idls.idl | 129 435 |
| LD Script | kernel_partitions.lds | 127 187 |
| Monkey C | LFO_BT1-point.mc | 120 881 |
| Modula3 | tpch22.m3 | 120 185 |
| Batch | EZhunter.cmd | 119 341 |
| Rust | data.rs | 114 408 |
| Ur/Web | dict.ur-en.ur | 113 911 |
| Unreal Script | orfs.derep_id97.uc | 110 737 |
| Groovy | groovy | 100 297 |
| Smarty Template | assign.100000.tpl | 100 002 |
| Bitbake | bb | 100,000 |
| BASH | palmer-master-thesis.bash | 96 911 |
| PSL Assertion | test_uno.psl | 96 253 |
| ASP | sat_gbie_01.asp | 95 144 |
| Protocol Buffers | select1.proto | 89 796 |
| Report Definition Language | ACG.rdl | 84 666 |
| Powershell | PresentationFramework.ps1 | 83 861 |
| Jinja | jinja2 | 76 040 |
| AWK | words-large.awk | 69 964 |
| LOLCODE | lol | 67 520 |
| Wren | reuse_constants.wren | 65 550 |
| JSX | AEscript.jsx | 65 108 |
| Rakefile | seed.rake | 63 000 |
| Stata | .31113.do | 60 343 |
| Vim Script | ddk.vim | 60 282 |
| Swift | Google.Protobuf.UnittestEnormousDescriptor.proto.swift | 60 236 |
| Korn Shell | attachment-0002.ksh | 58 298 |
| AsciiDoc | index.adoc | 52 627 |
| Freemarker Template | designed.eml.ftl | 52 160 |
| Cython | CALC.pex.netlist.CALC.pxi | 50 283 |
| m4 | ax.m4 | 47 828 |
| Extensible Stylesheet Language Transformations | green_ccd.xslt | 37,247 |
| License | copyright | 37 205 |
| JavaServer Pages | 1MB.jsp | 36 007 |
| Document Type Definition | bookmap.dtd | 32 815 |
| Fish | Godsay.fish | 31 112 |
| ClojureScript | core.cljs | 31 013 |
| Robot Framework | robot | 30 460 |
| Processing | data.pde | 30 390 |
| Ruby HTML | big_table.rhtml | 29 306 |
| ColdFusion | spreadsheet2009Q1.cfm | 27 974 |
| CMake | ListOfVistARoutines.cmake | 27 550 |
| ATS | test06.dats | 24 350 |
| Nim | windows.nim | 23 949 |
| Vue | Ogre.vue | 22 916 |
| Razor | validationerror.cshtml | 22 832 |
| Spice Netlist | input6.ckt | 22 454 |
| Isabelle | WooLam_cert_auto.thy | 22 312 |
| XAML | SymbolDrawings.xaml | 20 764 |
| Opalang | p4000_g+5.0_m0.0_t00_st_z+0.00_a+0.00_c+0.00_n+0.00_o+0.00_r+0.00_s+0.00.opa | 20 168 |
| TOML | too_large.toml | 20,000 |
| Madlang | evgg.mad | 19 416 |
| Stylus | test.styl | 19 127 |
| Go Template | html-template.tmpl | 19 016 |
| AutoHotKey | glext.ahk | 18 036 |
| ColdFusion CFScript | IntakeHCPCIO.cfc | 17 606 |
| Zsh | _oc.zsh | 17 307 |
| Twig Template | show.html.twig | 16 320 |
| ABAP | ZRIM01F01.abap | 16 029 |
| Elm | 57chevy.elm | 14 968 |
| Kotlin | _Arrays.kt | 14 396 |
| Varnish Configuration | 40_generic_attacks.vcl | 13 367 |
| Mustache | huge.mustache | 13 313 |
| Alloy | output.als | 12 168 |
| Device Tree | tegra132-flounder-emc.dtsi | 11 893 |
| MQL4 | PhD Appsolute System.mq4 | 11 280 |
| Jade | fugue.jade | 10 711 |
| Q# | in_navegador.qs | 10 025 |
| JSONL | train.jsonl | 10,000 |
| Flow9 | graph2.flow | 9902 |
| Vala | mwp.vala | 8765 |
| Handlebars | theme.scss.hbs | 8259 |
| Crystal | CR | 8084 |
| C Shell | plna.csh | 8000 |
| Hamlet | hamlet | 7882 |
| BuildStream | biometrics.bst | 7746 |
| Mako | verificaciones.mako | 7306 |
| Agda | Pifextra.agda | 6483 |
| Thrift | concourse.thrift | 6471 |
| Fragment Shader File | ms812_bseqoslabel_l.fsh | 6269 |
| Cargo Lock | Cargo.lock | 6202 |
| Xtend | UMLSlicerAspect.xtend | 5936 |
| Arvo | test-extra-large.avsc | 5378 |
| Scons | SConstruct | 5272 |
| Closure Template | buckconfig.soy | 5189 |
| GN | BUILD.gn | 4653 |
| Softbridge Basic | owptext.sbl | 4646 |
| PKGBUILD | PKGBUILD | 4636 |
| Oz | StaticAnalysis.oz | 4500 |
| Lucius | bootstrap.lucius | 3992 |
| Ceylon | RedHatTransformer.ceylon | 3907 |
| Creole | MariaDB_Manager_Monitors.creole | 3855 |
| Luna | Base.luna | 3731 |
| Gradle | dependencies.gradle | 3612 |
| MQL Header | IncGUI.mqh | 3544 |
| Cabal | smartword.cabal | 3452 |
| Emacs Dev Env | ede | 3400 |
| Meson | meson.build | 3264 |
| nuspec | Npm.js.nuspec | 2823 |
| Game Maker Project | LudumDare.yyp | 2679 |
| Julius | default-layout.julius | 2454 |
| Idris | ring_reduce.idr | 2434 |
| Alchemist | out.lmf-dos.crn | 2388 |
| MQL5 | DTS1-Build_814.1_B-test~.mq5 | 2210 |
| Android Interface Definition Language | ITelephony.aidl | 2005 |
| Vertex Shader File | sdk_macros.vsh | 1922 |
| Lean | interactive.lean | 1664 |
| Jenkins Buildfile | Jenkinsfile | 1559 |
| FIDL | amb.in.fidl | 1502 |
| Pony | scenery.pony | 1497 |
| PureScript | prelude.purs | 1225 |
| TaskPaper | task-3275.taskpaper | 1196 |
| Dockerfile | Dockerfile | 1187 |
| Janet | Janet | 1158 |
| Futhark | math.fut | 990 |
| Zig | main.zig | 903 |
| XCode Config | Project-Shared.xcconfig | 522 |
| JAI | LCregistryFile.jai | 489 |
| QCL | bwt.qcl | 447 |
| Ur/Web Project | reader.urp | 346 |
| Cassius | default-layout.cassius | 313 |
| Docker ignore | .dockerignore | 311 |
| Dhall | largeExpressionA.dhall | 254 |
| ignore | .ignore | 192 |
| Bitbucket Pipeline | bitbucket-pipelines.yml | 181 |
| Just | Justfile | 95 |
| Verilog Args File | or1200.irunargs | 60 |
| Polly | polly | 26 |
What is the most complex file in every language?
Once again, these values are not directly comparable to each other, but it’s interesting to see what is considered the most difficult in every language.
Some of these files are absolute monsters. For example, consider the most complex C ++ file I found: COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp : it's 28.3 megabytes of compiler hell (and, fortunately, it seems to be generated automatically).
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
Full list
| Language | File name | |
|---|---|---|
| C ++ | COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp | 682 001 |
| Javascript | blocks.js | 582 070 |
| C Header | bigmofoheader.h | 465 589 |
| C | fmFormula.c | 445 545 |
| Objective C | faster.m | 409 792 |
| SQL | dump20120515.sql | 181 146 |
| ASP.NET | results-i386.master | 164 528 |
| Java | ConcourseService.java | 139 020 |
| TCL | 68030_TK.tcl | 136 578 |
| C++ Header | TPG_hardcoded.hh | 129 465 |
| TypeScript Typings | all.d.ts | 127 785 |
| Svg | Class Diagram2.svg | 105 353 |
| Lua | luaFile1000kLines.lua | 102 960 |
| Php | fopen.php | 100,000 |
| Org | 2015-02-25_idfreeze-2.org | 63 326 |
| Ruby | all_search_helpers.rb | 60 375 |
| Scheme | test.ss | 50,000 |
| Stata | .31113.do | 48 600 |
| Elixir | pmid.sgd.crawl.ex | 46 479 |
| Brainfuck | Poll.bf | 41 399 |
| Perl | r1d7.pl | 41 128 |
| Go | segment_words_prod.go | 34 715 |
| Python | lrparsing-sqlite.py | 34 700 |
| Module-Definition | wordnet3_0.def | 32 008 |
| Clojure | raw-data.clj | 29 950 |
| C # | Matrix.Product.Generated.cs | 29 675 |
| D | parser.d | 27 249 |
| FORTRAN Modern | euitm_routines_407c.f90 | 27 161 |
| Puppet | sqlite3.c.pp | 25 753 |
| SystemVerilog | 6s131.sv | 24 300 |
| Autoconf | Makefile.in | 23 183 |
| Specman e | hansards.e | 20 893 |
| Smarty Template | test-include-09.tpl | 20,000 |
| TypeScript | JSONiqParser.ts | 18 162 |
| V | altera_mf.v | 13 584 |
| F* | slayer-3.fst | 13 428 |
| TeX | definitions.tex | 13 342 |
| Swift | Google.Protobuf.UnittestEnormousDescriptor.proto.swift | 13 017 |
| Assembly | all-opcodes.s | 12 800 |
| Bazel | firebird2.5_2.5.2.26540.ds4-10_amd64-20140427-2159.build | 12 149 |
| FORTRAN Legacy | lm67.F | 11 837 |
| R | Rallfun-v36.R | 11 287 |
| ActionScript | AccessorSpray.as | 10 804 |
| Haskell | Tags.hs | 10 444 |
| Prolog | books_save.p | 10 243 |
| Dart | DartParser.dart | 9606 |
| VHDL | unisim_VITAL.vhd | 9590 |
| Batch | test.bat | 9424 |
| Boo | compman.tex | 9280 |
| Coq | NangateOpenCellLibrary.v | 8988 |
| Shell | i3_completion.sh | 8669 |
| Kotlin | 1.kt | 7388 |
| JSX | typescript-parser.jsx | 7123 |
| Makefile | Makefile | 6642 |
| Emacs Lisp | bible.el | 6345 |
| Objective C++ | set.mm | 6285 |
| OCaml | sparcrec.ml | 6285 |
| Expect | condloadstore.stdout.exp | 6144 |
| SAS | import_REDCap.sas | 5783 |
| Julia | pilot-2013-05-14.jl | 5599 |
| Cython | types.pyx | 5278 |
| Modula3 | tpch22.m3 | 5182 |
| Haxe | T1231.hx | 5110 |
| Visual Basic for Applications | Coverage.cls | 5029 |
| Lisp | simN.lsp | 4994 |
| Scala | SpeedTest1MB.sc | 4908 |
| Groovy | ZulTagLib.groovy | 4714 |
| Powershell | PresentationFramework.ps1 | 4108 |
| Ada | bhps-print_full_version.adb | 3961 |
| JavaServer Pages | sink_jq.jsp | 3850 |
| GN | patch-third_party ffmpeg ffmpeg_generated.gni | 3742 |
| Basic | MSA_version116_4q.bas | 3502 |
| Pascal | Python_StdCtrls.pas | 3399 |
| Standard ML (SML) | arm.sml | 3375 |
| Erlang | lipsum.hrl | 3228 |
| ASP | mylib.asp | 3149 |
| CSS | three-viewer.css | 3071 |
| Unreal Script | ScriptedPawn.uc | 2909 |
| CoffeeScript | game.coffee | 2772 |
| AutoHotKey | fishlog5.93.ahk | 2764 |
| MQL4 | PhD Appsolute System.mq4 | 2738 |
| Processing | Final.pde | 2635 |
| Isabelle | StdInst.thy | 2401 |
| Razor | Checklist.cshtml | 2341 |
| Sass | _multi-color-css-stackicons-social.scss | 2325 |
| Vala | valaccodebasemodule.vala | 2100 |
| MSBuild | all.props | 2008 |
| Rust | ffi.rs | 1928 |
| QML | Dots.qml | 1875 |
| F# | test.fsx | 1826 |
| Vim Script | netrw.vim | 1790 |
| Korn Shell | attachment.ksh | 1773 |
| Vue | vue | 1738 |
| sed | SED | 1699 |
| GLSL | comp | 1699 |
| Nix | auth.nix | 1615 |
| Mustache | template.mustache | 1561 |
| Bitbake | my-2010.bb | 1549 |
| Ur/Web | votes.ur | 1515 |
| BASH | pgxc_ctl.bash | 1426 |
| MQL Header | hanoverfunctions.mqh | 1393 |
| Visual basic | LGMDdataDataSet.Designer.vb | 1369 |
| Q# | flfacturac.qs | 1359 |
| C Shell | regtest_hwrf.csh | 1214 |
| MQL5 | DTS1-Build_814.1_B-test~.mq5 | 1186 |
| Xtend | Parser.xtend | 1116 |
| Nim | disas.nim | 1098 |
| CMake | MacroOutOfSourceBuild.cmake | 1069 |
| Protocol Buffers | configure.proto | 997 |
| SKILL | switch.il | 997 |
| COBOL | geekcode.cob | 989 |
| Game Maker Language | hydroEx_River.gml | 982 |
| Gherkin Specification | upload_remixed_program_again_complex.feature | 959 |
| Alloy | battleformulas.als | 948 |
| Bosque | recover.bsq | 924 |
| ColdFusion | jquery.js.cfm | 920 |
| Stylus | buttron.styl | 866 |
| ColdFusion CFScript | apiUtility.cfc | 855 |
| Verilog | exec_matrix.vh | 793 |
| Freemarker Template | DefaultScreenMacros.html.ftl | 771 |
| Crystal | lexer.cr | 753 |
| Forth | e4 | 690 |
| Monkey C | mc | 672 |
| Rakefile | import.rake | 652 |
| Zsh | zshrc | 649 |
| Ruby HTML | ext_report.rhtml | 633 |
| Handlebars | templates.handlebars | 557 |
| SRecode Template | Al3SEbeK61s.srt | 535 |
| Scons | SConstruct | 522 |
| Agda | Square.agda | 491 |
| Ceylon | runtime.ceylon | 467 |
| Julius | default-layout.julius | 436 |
| Wolfram | qmSolidsPs8dContourPlot.nb | 417 |
| Cabal | parconc-examples.cabal | 406 |
| Fragment Shader File | flappybird.fsh | 349 |
| ATS | ats_staexp2_util1.dats | 311 |
| Jinja | php.ini.j2 | 307 |
| Opalang | unicode.opa | 306 |
| Twig Template | product_form.twig | 296 |
| ClojureScript | core.cljs | 271 |
| Hamlet | hamlet | 270 |
| Oz | StaticAnalysis.oz | 267 |
| Elm | Indexer.elm | 267 |
| Meson | meson.build | 248 |
| ABAP | ZRFFORI99.abap | 244 |
| Dockerfile | Dockerfile | 243 |
| Wren | repl.wren | 242 |
| Fish | fisher.fish | 217 |
| Emacs Dev Env | ede | 211 |
| GDScript | tiled_map.gd | 195 |
| IDL | bgfx.idl | 187 |
| Jade | docs.jade | 181 |
| PureScript | List.purs | 180 |
| XAML | Midnight.xaml | 179 |
| Flow9 | TypeMapper.js.flow | 173 |
| Idris | Utils.idr | 166 |
| PSL Assertion | pre_dec.psl | 162 |
| Lean | kernel.lean | 161 |
| MUMPS | link.mps | 161 |
| Vertex Shader File | base.vsh | 152 |
| Go Template | code-generator.tmpl | 148 |
| Mako | pokemon.mako | 137 |
| Closure Template | template.soy | 121 |
| Zig | main.zig | 115 |
| TOML | telex_o.toml | one hundred |
| Softbridge Basic | asm.sbl | 98 |
| QCL | bwt.qcl | 96 |
| Futhark | math.fut | 86 |
| Pony | jstypes.pony | 70 |
| LOLCODE | LOLTracer.lol | 61 |
| Alchemist | alchemist.crn | 55 |
| Madlang | Copying.MAD | 44 |
| LD Script | plugin.lds | 39 |
| Device Tree | dts | 22 |
| FIDL | GlobalCapabilitiesDirectory.fidl | 19 |
| JAI | LICENSE.jai | eighteen |
| Just | Justfile | 7 |
| Android Interface Definition Language | aidl | 3 |
| Ur/Web Project | jointSpace.urp | 2 |
| Spice Netlist | GRI30.CKT | 2 |
The most complicated file regarding the number of lines?
It sounds good in theory, but in fact ... something minified or without line breaks distorts the results, making them meaningless. Therefore, I do not publish the results of the calculations. However, I created a ticket in
scc
to support the minification detection in order to remove it from the calculation results.
You can probably draw some conclusions based on the available data, but I want all users to benefit from this feature
scc
.
What is the most commented file in each language?
I have no idea what valuable information you can learn from this, but it's interesting to see.
Note.Some of the links below may not work due to some extra information when creating files. Most should work, but for some, you might need to slightly modify the URL.
Full list
| Language | File name | |
|---|---|---|
| Prolog | ts-with-score-multiplier.p | 5 603 870 |
| C | testgen.c | 1 705 508 |
| Python | Untitled0.py | 1 663 466 |
| Javascript | 100MB.js | 1 165 656 |
| Svg | p4-s3_I369600.svg | 1 107 955 |
| SQL | test.sql | 858 993 |
| C Header | head.h | 686 587 |
| C ++ | ResidueTopology.cc | 663 024 |
| Autoconf | square_detector_local.in | 625 464 |
| TypeScript | reallyLargeFile.ts | 583 708 |
| Lex | polaris-xp900.l | 457 288 |
| XML | Test1-CDL-soapui-project.xml | 411 321 |
| HTML | todos_centros.html | 366 776 |
| Pascal | FHIR.R4.Resources.pas | 363 289 |
| SystemVerilog | mkToplevelBT64.v | 338 042 |
| Php | lt.php | 295 054 |
| TypeScript Typings | dojox.d.ts | 291 002 |
| Verilog | CVP14_synth.vg | 264 649 |
| Lua | objects.lua | 205 006 |
| V | TestDataset01-functional.v | 201 973 |
| Java | FinalPackage.java | 198 035 |
| C++ Header | test_cliprdr_channel_xfreerdp_full_authorisation.hpp | 196 958 |
| Shell | add_commitids_to_src.sh | 179 223 |
| C # | ItemId.cs | 171 944 |
| FORTRAN Modern | slatec.f90 | 169 817 |
| Assembly | HeavyWeather.asm | 169 645 |
| Module-Definition | top_level.final.def | 139 150 |
| FORTRAN Legacy | dlapack.f | 110 640 |
| VHDL | cpuTest.vhd | 107 882 |
| Groovy | groovy | 98 985 |
| IDL | all-idls.idl | 91 771 |
| Wolfram | K2KL.nb | 90 224 |
| Go | frequencies.go | 89 661 |
| Scheme | s7test.scm | 88 907 |
| D | coral.jar.d | 80 674 |
| Coq | cycloneiv_hssi_atoms.v | 74 936 |
| Specman e | sysobjs.e | 65 146 |
| Puppet | sqlite3.c.pp | 63 656 |
| Wren | many_globals.wren | 61 388 |
| Boo | sun95.tex | 57 018 |
| Ruby | bigfile.rb | 50,000 |
| Objective C | job_sub011.m | 44 788 |
| CSS | screener.css | 43 785 |
| Swig | CIDE.I | 37 235 |
| Fish | Godsay.fish | 31 103 |
| Sass | sm30_kernels.sass | 30 306 |
| CoffeeScript | tmp.coffee | 29 088 |
| Erlang | nci_ft_ricm_dul_SUITE.erl | 28 306 |
| Lisp | km_2-5-33.lisp | 27 579 |
| YAML | ciudades.yml | 27 168 |
| R | PhyloSimSource.R | 26 023 |
| Scala | GeneratedRedeclTests.scala | 24 647 |
| Emacs Lisp | pjb-java.el | 24 375 |
| Haskell | Dipole80.hs | 24 245 |
| ATS | test06.dats | 24 179 |
| m4 | ax.m4 | 22 675 |
| ActionScript | __2E_str95.as | 21 173 |
| Objective C++ | edges-new.mm | 20 789 |
| Visual basic | clsProjections.vb | 20 641 |
| TCL | 68030_TK.tcl | 20 616 |
| Nix | nix | 19 605 |
| Perl | LF_aligner_3.12_with_modules.pl | 18 013 |
| Ada | amf-internals-tables-uml_metamodel-objects.adb | 14 535 |
| Batch | MAS_0.6_en.cmd | 14 402 |
| OCaml | code_new.ml | 13 648 |
| LaTeX | pm3dcolors.tex | 13 092 |
| Properties File | messages_ar_SA.properties | 13 074 |
| MSBuild | ncrypto.csproj | 11 302 |
| ASP.NET | GallerySettings.ascx | 10 969 |
| Powershell | mail_imap.ps1 | 10 798 |
| Standard ML (SML) | TCP1_hostLTSScript.sml | 10 790 |
| Dart | html_dart2js.dart | 10 547 |
| AutoHotKey | studio.ahk | 10 391 |
| Expect | Navigator.exp | 10 063 |
| Julia | PETScRealSingle.jl | 9417 |
| Makefile | Makefile | 9204 |
| Forth | europarl.lowercased.fr | 9107 |
| ColdFusion | js.cfm | 8786 |
| TeX | hyperref.sty | 8591 |
| Opalang | i18n_language.opa | 7860 |
| LESS | _variables.less | 7394 |
| Swift | CodeSystems.swift | 6847 |
| Bazel | gcc-mingw-w64_12_amd64-20140427-2100.build | 6429 |
| Kotlin | _Arrays.kt | 5887 |
| SAS | 202_002_Stream_DQ_DRVT.sas | 5597 |
| Haxe | CachedRowSetImpl.hx | 5438 |
| Rust | lrgrammar.rs | 5150 |
| Monkey C | mc | 5044 |
| Cython | pcl_common_172.pxd | 5030 |
| Nim | disas.nim | 4547 |
| Game Maker Language | gm_spineapi.gml | 4345 |
| ABAP | ZACO19U_SHOP_NEW_1.abap | 4244 |
| XAML | Raumplan.xaml | 4193 |
| Razor | Privacy.cshtml | 4092 |
| Varnish Configuration | 46_slr_et_rfi_attacks.vcl | 3924 |
| Basic | MSA_version116_4q.bas | 3892 |
| Isabelle | Pick.thy | 3690 |
| Protocol Buffers | metrics_constants.proto | 3682 |
| BASH | bashrc | 3606 |
| Clojure | all-playlists-output.clj | 3440 |
| F# | GenericMatrixDoc.fs | 3383 |
| Thrift | NoteStore.thrift | 3377 |
| COBOL | db2ApiDf.cbl | 3319 |
| JavaServer Pages | sink_jq.jsp | 3204 |
| Modula3 | gdb.i3 | 3124 |
| Visual Basic for Applications | HL7xmlBuilder.cls | 2987 |
| Oz | timing.oz | 2946 |
| Closure Template | buckconfig.soy | 2915 |
| Agda | Pifextra.agda | 2892 |
| Stata | R2_2cleaningprocess.do | 2660 |
| ColdFusion CFScript | Intake.cfc | 2578 |
| Luna | Base.luna | 2542 |
| Unreal Script | UIRoot.uc | 2449 |
| CMake | cmake | 2425 |
| Org | lens-wsn.org | 2417 |
| Flow9 | index.js.flow | 2361 |
| MQL Header | IncGUI.mqh | 2352 |
| JSX | ContactSheetII.jsx | 2243 |
| MQL4 | PhD Appsolute System.mq4 | 2061 |
| Ruby HTML | FinalOral-Old.Rhtml | 2061 |
| GDScript | group.gd | 2023 |
| Processing | testcode.pde | 2014 |
| PSL Assertion | 2016-08-16.psl | 2011 |
| ASP | c_system_plugin.asp | 1878 |
| AWK | dic-generator.awk | 1732 |
| Jinja | php.ini.j2 | 1668 |
| Zsh | .zshrc | 1588 |
| Q# | in_navegador.qs | 1568 |
| sed | Makefile.sed | 1554 |
| Stylus | popup.styl | 1550 |
| Bitbake | Doxyfile.bb | 1533 |
| Rakefile | samples.rake | 1509 |
| Gherkin Specification | WorkflowExecution.feature | 1421 |
| Crystal | string.cr | 1412 |
| Android Interface Definition Language | ITelephony.aidl | 1410 |
| Xtend | Properties.xtend | 1363 |
| SKILL | DT_destub.il | 1181 |
| Madlang | .config.mad | 1137 |
| Spice Netlist | APEXLINEAR.ckt | 1114 |
| QML | MainFULL.qml | 1078 |
| GLSL | subPlanetNoise.frag | 1051 |
| Ur/Web | initial.ur | 1018 |
| Alloy | TransactionFeatureFinal.als | 1012 |
| Vala | puzzle-piece.vala | 968 |
| Smarty Template | Ensau.tpl | 965 |
| Mako | jobs.mako | 950 |
| TOML | traefik.toml | 938 |
| gitignore | .gitignore | 880 |
| Elixir | macros.ex | 832 |
| GN | rules.gni | 827 |
| Korn Shell | lx_distro_install.ksh | 807 |
| LD Script | vmlinux.lds | 727 |
| Scons | SConstruct | 716 |
| Handlebars | Consent-Form.handlebars | 714 |
| Device Tree | ddr4-common.dtsi | 695 |
| FIDL | amb.in.fidl | 686 |
| Julius | glMatrix.julius | 686 |
| C Shell | setup_grid.csh | 645 |
| Lean | perm.lean | 642 |
| Idris | Overview.idr | 637 |
| PureScript | Array.purs | 631 |
| Freemarker Template | result_softwares.ftl | 573 |
| ClojureScript | lt-cljs-tutorial.cljs | 518 |
| Fragment Shader File | bulb.fsh | 464 |
| Elm | Attributes.elm | 434 |
| Jade | index.jade | 432 |
| Vue | form.vue | 418 |
| Gradle | build.gradle | 416 |
| Lucius | bootstrap.lucius | 404 |
| Go Template | fast-path.go.tmpl | 400 |
| Meson | meson.build | 306 |
| F* | Crypto.Symmetric.Poly1305.Bignum.Lemmas.Part1.fst | 289 |
| Ceylon | IdeaCeylonParser.ceylon | 286 |
| MQL5 | ZigzagPattern_oldest.mq5 | 282 |
| XCode Config | Project-Shared.xcconfig | 265 |
| Futhark | blackscholes.fut | 257 |
| Pony | scenery.pony | 252 |
| Vertex Shader File | CC3TexturableRigidBones.vsh | 205 |
| Softbridge Basic | greek.sbl | 192 |
| Cabal | deeplearning.cabal | 180 |
| nuspec | Xamarin.Auth.XamarinForms.nuspec | 156 |
| Dockerfile | Dockerfile | 152 |
| Mustache | models_list.mustache | 141 |
| LOLCODE | LOLTracer.lol | 139 |
| BuildStream | astrobib.bst | 120 |
| Janet | Janet | 101 |
| Cassius | xweek.cassius | 94 |
| Docker ignore | .dockerignore | 92 |
| Hamlet | upload.hamlet | 90 |
| QCL | mod.qcl | 88 |
| Dhall | nix.bash.dhall | 86 |
| ignore | .ignore | 60 |
| Just | Justfile | 46 |
| SRecode Template | srecode-test.srt | 35 |
| Bitbucket Pipeline | bitbucket-pipelines.yml | thirty |
| Ur/Web Project | reader.urp | 22 |
| Alchemist | ctrl.crn | 16 |
| Zig | main.zig | 12 |
| MUMPS | mps | eleven |
| Bosque | bosque.bsq | 8 |
| Report Definition Language | example.rdl | four |
| Emacs Dev Env | Project.ede | 3 |
| Cargo Lock | Cargo.lock | 2 |
| JAI | thekla_atlas.jai | one |
How many “clean” projects
Under the "pure" in the types of projects are purely in one language. Of course, this is not very interesting in itself, so let's look at them in context. As it turned out, the vast majority of projects have less than 25 languages, and most have less than ten.
The peak in the graph below is in four languages.
Of course, in clean projects there can be only one programming language, but there is support for other formats, such as markdown, json, yml, css, .gitignore, which are taken into account
scc
. It is probably reasonable to assume that any project with less than five languages is “clean” (for some level of cleanliness), and this is just over half of the total dataset. Of course, your definition of cleanliness may differ from mine, so you can focus on any number that you like.
What surprises me is a strange surge around 34-35 languages. I have no reasonable explanation of where it came from, and this is probably worthy of a separate investigation.
Full list
| one | 886 559 |
| 2 | 951 009 |
| 3 | 989 025 |
| four | 1 070 987 |
| 5 | 1 012 686 |
| 6 | 845 898 |
| 7 | 655 510 |
| 8 | 542 625 |
| 9 | 446 278 |
| 10 | 392 212 |
| eleven | 295 810 |
| 12 | 204 291 |
| 13 | 139 021 |
| fourteen | 110 204 |
| fifteen | 87 143 |
| 16 | 67 602 |
| 17 | 61 936 |
| eighteen | 44 874 |
| 19 | 34 740 |
| twenty | 32 041 |
| 21 | 25 416 |
| 22 | 24 986 |
| 23 | 23 634 |
| 24 | 16 614 |
| 25 | 13 823 |
| 26 | 10 998 |
| 27 | 9 973 |
| 28 | 6 807 |
| 29th | 7 929 |
| thirty | 6 223 |
| 31 | 5 602 |
| 32 | 6 614 |
| 33 | 12 155 |
| 34 | 15 375 |
| 35 | 7329 |
| 36 | 6227 |
| 37 | 4158 |
| 38 | 3744 |
| 39 | 3844 |
| 40 | 1570 |
| 41 | 1041 |
| 42 | 746 |
| 43 | 1037 |
| 44 | 1363 |
| 45 | 934 |
| 46 | 545 |
| 47 | 503 |
| 48 | 439 |
| 49 | 393 |
| fifty | 662 |
| 51 | 436 |
| 52 | 863 |
| 53 | 393 |
| 54 | 684 |
| 55 | 372 |
| 56 | 366 |
| 57 | 842 |
| 58 | 398 |
| 59 | 206 |
| 60 | 208 |
| 61 | 177 |
| 62 | 377 |
| 63 | 450 |
| 64 | 341 |
| 65 | 86 |
| 66 | 78 |
| 67 | 191 |
| 68 | 280 |
| 69 | 61 |
| 70 | 209 |
| 71 | 330 |
| 72 | 171 |
| 73 | 190 |
| 74 | 142 |
| 75 | 102 |
| 76 | 32 |
| 77 | 57 |
| 78 | fifty |
| 79 | 26 |
| 80 | 31 |
| 81 | 63 |
| 82 | 38 |
| 83 | 26 |
| 84 | 72 |
| 85 | 205 |
| 86 | 73 |
| 87 | 67 |
| 88 | 21 |
| 89 | fifteen |
| 90 | 6 |
| 91 | 12 |
| 92 | 10 |
| 93 | 8 |
| 94 | 16 |
| 95 | 24 |
| 96 | 7 |
| 97 | thirty |
| 98 | four |
| 99 | one |
| one hundred | 6 |
| 101 | 7 |
| 102 | 16 |
| 103 | one |
| 104 | 5 |
| 105 | one |
| 106 | 19 |
| 108 | 2 |
| 109 | 2 |
| 110 | one |
| 111 | 3 |
| 112 | one |
| 113 | one |
| 114 | 3 |
| 115 | 5 |
| 116 | 5 |
| 118 | one |
| 120 | 5 |
| 124 | one |
| 125 | one |
| 131 | 2 |
| 132 | one |
| 134 | 2 |
| 136 | one |
| 137 | one |
| 138 | one |
| 142 | one |
| 143 | 2 |
| 144 | one |
| 158 | one |
| 159 | 2 |
Projects with TypeScript but not JavaScript
Ah, the modern world of TypeScript. But for TypeScript projects, how many are purely in this language?
| Clean TypeScript projects |
|---|
| 27,026 projects |
I must admit, I'm a little surprised by this number. Although I understand that mixing JavaScript with TypeScript is quite common, I would have thought there would be more projects in the newfangled language. But it is possible that a more recent set of repositories will dramatically increase their number.
Does anyone use CoffeeScript and TypeScript?
| Using TypeScript and CoffeeScript |
|---|
| 7849 projects |
I have the feeling that some TypeScript developers feel sick at the very thought of it. If this helps them, I can assume that most of these projects are programs like
scc
with examples of all languages for testing purposes.
What is the typical path length in each language
Given that you can either upload all the files you need into one directory or create a directory system, what is the typical path length and number of directories?
To do this, count the number of slashes in the path for each file and average. I did not know what to expect here, except that Java might be at the top of the list, since there are usually long file paths.
Full list
| Language | |
|---|---|
| ABAP | 4,406555175781266 |
| ASP | 6,372800350189209 |
| ASP,NET | 7.25 |
| ATS | 4,000007286696899 |
| AWK | 4,951896171638623 |
| ActionScript | 8,139775436837226 |
| Ada | 4,00042700953189 |
| Agda | 3,9126438455441743 |
| Alchemist | 3,507827758789091 |
| Alex | 5,000001311300139 |
| Alloy | 5,000488222547574 |
| Android Interface Definition Language | 11,0048217363656 |
| Arvo | 5,9999994741776135 |
| AsciiDoc | 3,5 |
| Assembly | 4.75 |
| AutoHotKey | 2,2087400984292067 |
| Autoconf | 5,8725585937792175 |
| BASH | 2,1289059027401294 |
| Basic | 3,003903865814209 |
| Batch | 6,527053831937014 |
| Bazel | 3,18005371087348 |
| Bitbake | 2,015624999069132 |
| Bitbucket Pipeline | 2,063491820823401 |
| Boo | 4,010679721835899 |
| Bosque | 4,98316764831543 |
| Brainfuck | 4,2025654308963425 |
| BuildStream | 3,4058846323741645 |
| C | 4,923767089530871 |
| C Header | 4,8744963703211965 |
| C Shell | 3,027952311891569 |
| C # | 3,9303305113013427 |
| C ++ | 3,765686050057411 |
| C++ Header | 5,0468749664724015 |
| CMake | 4,474763816174707 |
| COBOL | 2,718678008809146 |
| CSS | 3,158353805542812 |
| Csv | 2,0005474090593514 |
| Cabal | 2,0234456174658693 |
| Cargo Lock | 2,602630615232607 |
| Cassius | 3,56445312181134 |
| Ceylon | 4,750730359584461 |
| Clojure | 3,992209411809762 |
| ClojureScript | 4,905477865257108 |
| Closure Template | 6,800760253008946 |
| CoffeeScript | 4,503051759227674 |
| ColdFusion | 6,124976545410084 |
| ColdFusion CFScript | 6,188602089623717 |
| Coq | 4,000243186950684 |
| Creole | 3,124526690922411 |
| Crystal | 3,1243934621916196 |
| Cython | 5,219657994911814 |
| D | 9,291626930357722 |
| Dart | 3,939864161220478 |
| Device Tree | 6,530643464186369 |
| Dhall | 0,12061593477278201 |
| Docker ignore | 2,9984694408020562 |
| Dockerfile | 3,1281526535752064 |
| Document Type Definition | 6,3923129292499254 |
| Elixir | 3,9999989270017977 |
| Elm | 2,968016967181992 |
| Emacs Dev Env | 4,750648772301943 |
| Emacs Lisp | 2,0156250001746203 |
| Erlang | 4,756546300111156 |
| Expect | 5,126907349098477 |
| Extensible Stylesheet Language Transformations | 4,519531239055546 |
| F# | 5,752862453457055 |
| F* | 4,063724638864983 |
| FIDL | 4,484130888886213 |
| FORTRAN Legacy | 6,117128185927898 |
| FORTRAN Modern | 5,742561882347131 |
| Fish | 3,993835387425861 |
| Flow9 | 9,462829245721366 |
| Forth | 4,016601327653859 |
| Fragment Shader File | 3,8598623261805187 |
| Freemarker Template | 11,122007250069213 |
| Futhark | 6,188476562965661 |
| GDScript | 3,2812499999872675 |
| GLSL | 6,6093769371505005 |
| GN | 3,497192621218512 |
| Game Maker Language | 4,968749999941792 |
| Game Maker Project | 3,8828125 |
| Gherkin Specification | 3,999099795268081 |
| Go | 3,9588454874029275 |
| Go Template | four |
| Gradle | 2,655930499769198 |
| Groovy | 11,499969503013528 |
| HEX | 3,98394775342058 |
| HTML | 4,564478578133282 |
| Hamlet | 3,4842224120074867 |
| Handlebars | 4,998766578761208 |
| Happy | 5,699636149570479 |
| Haskell | 2,000140870587468 |
| Haxe | 5,999999999999997 |
| IDL | 6,249999993495294 |
| Idris | 3,515075657458509 |
| Intel HEX | 3,983397483825683 |
| Isabelle | 4,18351352773584 |
| JAI | 7,750007518357038 |
| JSON | 3,9999972562254724 |
| JSONL | 5,751412352804029 |
| JSX | 5,0041952044625715 |
| Jade | 4,744544962807595 |
| Janet | 3,0312496423721313 |
| Java | 11,265740856469563 |
| Javascript | 4,242187985224513 |
| JavaServer Pages | 7,999993488161865 |
| Jenkins Buildfile | 2,000000000087315 |
| Jinja | 6,937498479846909 |
| Julia | 3,9999848530092095 |
| Julius | 3,187606761406953 |
| Jupyter | 2,375 |
| Just | 4,312155187124516 |
| Korn Shell | 7,0685427486899925 |
| Kotlin | 6,455277973786039 |
| LD Script | 5,015594720376608 |
| LESS | 5,999999999999886 |
| Lex | 5,6996263030493495 |
| LOLCODE | 3,722656242392418 |
| LaTeX | 4,499990686770616 |
| Lean | 4,1324310302734375 |
| License | 4,7715609660297105 |
| Lisp | 6,00048828125 |
| Lua | 3,999999057474633 |
| Lucius | 3,0000303482974573 |
| Luna | 4,758178874869392 |
| MQL Header | 5,421851994469764 |
| MQL4 | 5,171874999953652 |
| MQL5 | 4,069171198975555 |
| MSBuild | 4,8931884765733855 |
| MUMPS | 4,999999672174454 |
| Macromedia eXtensible Markup Language | 3,9139365140181326 |
| Madlang | 3,625 |
| Makefile | 4,717208385332443 |
| Mako | 4,0349732004106045 |
| Markdown | 2.25 |
| Meson | 3,342019969206285 |
| Modula3 | 3,980173215190007 |
| Module-Definition | 8,875000973076205 |
| Monkey C | 3,0672508481368164 |
| Mustache | 6,000003708292297 |
| Nim | 3,7500824918105313 |
| Nix | 2,0307619677526234 |
| OCaml | 3,269392550457269 |
| Objective C | 3,526367187490962 |
| Objective C++ | 5,000000834608569 |
| Opalang | 4,500069382134143 |
| Org | 5,953919619084296 |
| Oz | 4,125 |
| Php | 7,999984720368943 |
| PKGBUILD | 4,875488281252839 |
| PSL Assertion | 5,004394620715175 |
| Pascal | 5,0781240425935845 |
| Patch | 3,999999999999819 |
| Perl | 4,691352904239976 |
| Plain text | 5,247085583343509 |
| Polly | 2,953125 |
| Pony | 2,9688720703125 |
| Powershell | 4,596205934882159 |
| Processing | 3,999931812300937 |
| Prolog | 4,4726600636568055 |
| Properties File | 3,5139240025278604 |
| Protocol Buffers | 6,544742336542192 |
| Puppet | 6,662078857422106 |
| PureScript | 4,000007774680853 |
| Python | 5,4531080610843805 |
| Q# | 3,7499999999999996 |
| QCL | 2,992309644818306 |
| QML | 7,042003512360623 |
| R | 3,0628376582587578 |
| Rakefile | 4,78515574071335 |
| Razor | 8,062499530475186 |
| ReStructuredText | 5,061766624473476 |
| Report Definition Language | 5,996573380834889 |
| Robot Framework | 4,0104638249612155 |
| Ruby | 5,1094988621717725 |
| Ruby HTML | 5,57654969021678 |
| Rust | 3,2265624976654292 |
| SAS | 4,826202331129183 |
| SKILL | 6,039547920227052 |
| SPDX | 4,000203706655157 |
| SQL | 7,701822280883789 |
| SRecode Template | 3,500030428171159 |
| Svg | 5,217570301278483 |
| Sass | 6,000000000056957 |
| Scala | 4,398563579539738 |
| Scheme | 6,999969714792911 |
| Scons | 5,010994006631478 |
| Shell | 4,988665378738929 |
| Smarty Template | 5,000527858268356 |
| Softbridge Basic | 4,87873840331963 |
| Specman e | 5,765624999999318 |
| Spice Netlist | 3,9687499998835882 |
| Standard ML (SML) | 4,031283043158929 |
| Stata | 6,27345275902178 |
| Stylus | 3,5000006667406485 |
| Swift | 3 |
| Swig | 5,246093751920853 |
| SystemVerilog | 2,9995259092956985 |
| Systemd | 3,9960937500000284 |
| TCL | 2,508188682367951 |
| TOML | 2,063069331460588 |
| TaskPaper | 2,003804363415667 |
| TeX | 3,500000000931251 |
| Thrift | 4,956119492650032 |
| Twig Template | 8,952746974652655 |
| TypeScript | 4,976589231140677 |
| TypeScript Typings | 5,832031190521718 |
| Unreal Script | 4,22499089783372 |
| Ur/Web | 4,41992186196147 |
| Ur/Web Project | 5,1147780619789955 |
| V | 4,251464832544997 |
| VHDL | 4,000000961231823 |
| Vala | 3,99804687498741 |
| Varnish Configuration | 4,006103516563625 |
| Verilog | 3,6906727683381173 |
| Verilog Args File | 8,93109059158814 |
| Vertex Shader File | 3,8789061926163697 |
| Vim Script | 3,9995117782528147 |
| Visual basic | 4,5 |
| Visual Basic for Applications | 3,6874962672526417 |
| Vue | 7,752930045514701 |
| Wolfram | 3,075198844074798 |
| Wren | four |
| XAML | 4,515627968764219 |
| XCode Config | 6,969711296260638 |
| XML | 6 |
| XML Schema | 5,807670593268995 |
| Xtend | 4,315674404631856 |
| YAML | 3,2037304108964673 |
| Zig | 3,4181210184442534 |
| Zsh | 2,0616455049940288 |
| gitignore | 2,51172685490884 |
| ignore | 10,6434326171875 |
| m4 | 3,7519528857323934 |
| nuspec | 4,109375 |
| sed | 4,720429063539986 |
YAML or YML?
There was once a “discussion” at Slack - using .yaml or .yml. Many were killed there on both sides.
Debate may finally (?) End. Although I suspect that some will still prefer to die in a dispute.
| Expansion | Number |
|---|---|
| yaml | 3,572,609 |
| yml | 14 076 349 |
Upper, lower, or mixed case?
What register is used for file names? Since there is still an extension, we can expect, mainly, a mixed case.
| Style | amount |
|---|---|
| Mixed | 9 094 732 |
| Lower | 2476 |
| Upper | 2875 |
Which, of course, is not very interesting, because usually file extensions are lowercase. What if ignore extensions?
| Style | amount |
|---|---|
| Mixed | 8 104 053 |
| Lower | 347 458 |
| Upper | 614 922 |
Not what I expected. Again, mostly mixed, but I would have thought that the bottom would be more popular.
Factories in Java
Another idea that colleagues came up with when looking at some old Java code. I thought, why not add a check for any Java code where Factory, FactoryFactory or FactoryFactoryFactory appears in the title. The idea is to estimate the number of such factories.
| Type of | amount | Share |
|---|---|---|
| not factory | 271 375 574 | 97.9% |
| factory | 5 695 568 | 2.09% |
| factoryfactory | 25,316 | 0.009% |
| factoryfactoryfactory | 0 | 0% |
So, just over 2% of the Java code turned out to be a factory or factoryfactory. Fortunately, no factoryfactoryfactory was found. Perhaps this joke will finally die, although I’m sure that at least one serious third-level recursive multifactory still works somewhere in some kind of Java 5 monolith, and it makes more money every day than I have seen in my entire career. .
.Ignore files
The idea of .ignore files was developed by burntsushi and ggreer in a discussion on Hacker News . Perhaps this is one of the best examples of "competing" open source tools that work together with good results and are completed in record time. It has become the de facto standard for adding code that tools will ignore.
scc
also fulfills the .ignore rule, but also knows how to count them. Let's see how well the idea has spread.
Full list
| .ignore | |
|---|---|
| 0 | 9 088 796 |
| one | 7848 |
| 2 | 1258 |
| 3 | 508 |
| four | 333 |
| 5 | 43 |
| 6 | 130 |
| 7 | 8 |
| 8 | fourteen |
| 9 | 83 |
| 10 | 49 |
| eleven | 35 |
| 12 | 112 |
| 13 | 736 |
| fifteen | four |
| 17 | one |
| eighteen | four |
| twenty | 2 |
| 21 | one |
| 23 | 2 |
| 24 | 3 |
| 26 | 2 |
| 27 | one |
| 34 | 31 |
| 35 | 19 |
| 36 | 9 |
| 38 | 2 |
| 39 | one |
| 43 | 12 |
| 44 | one |
| 45 | 2 |
| 46 | 5 |
| 49 | 7 |
| fifty | 7 |
| 51 | 12 |
| 52 | 2 |
Ideas for the future
I like to do some analysis for the future. It would be nice to scan things like AWS AKIA keys and the like. I would also like to expand the coverage of Bitbucket and Gitlab projects with analysis for each, to see if there may hang out development teams from different areas.
If I ever repeat the project, I would like to overcome the following shortcomings and take into account the following ideas.
- Store URLs somewhere in metadata correctly. Using a file name to store it was a bad idea, as information is lost and it can be difficult to determine the source and location of the file.
- Do not bother with S3. It makes little sense to pay for traffic if I use it only for storage. It was better from the very beginning to hammer everything into a tar file.
- , .
- -n , , , .
- scc, , . , CIDE.C C, , HTML. .
- , scc, , , . .
- I would like to add a shebang detection to scc .
- It would be nice to somehow take into account the number of stars on Github and the number of commits.
- I want to somehow add a maintainability index calculation. It would be great to see which projects are considered the most repairable depending on their size.
Why is this all?
Well, I can take some of this information and use it in my searchcode.com search engine and program
scc
. At least some useful data points. Initially, the project was conceived in many ways for the sake of this. It is also very useful to compare your project with others. It was also an interesting way to spend a few days solving some interesting problems. And a good reliability check for
scc
.
In addition, I am currently working on a tool that helps leading developers or managers analyze code, search for specific languages, large files, flaws, etc. ... with the assumption that you need to analyze several repositories. You enter some kind of code, and the tool says how maintainable it is and what skills are needed to maintain it. This is useful when deciding whether to buy some kind of code base, to service it, or to get an idea about your own product that the development team gives out. Theoretically, this should help teams scale through shared resources. Something like AWS Macie, but for code - something like this I'm working on. I myself need this for everyday work, and I suspect that others may find application for such an instrument, at least that is the theory.
Perhaps it would be worth putting here some form of registration for those interested ...
Unprocessed / processed files
If someone wants to make their own analysis and make corrections, here is a link to the processed files (20 MB). If someone wants to post raw files in the public domain, let me know. This is 83 GB tar.gz, and inside is just over 1 TB. Content consists of just over 9 million JSON files of various sizes.
UPD. Several good souls suggested placing the file, the places are indicated below:
By hosting this tar.gz file, thanks to CNCF for the server for xet7 from the Wekan project .
All Articles