Data Model Dictionary
Mikhail Konovalov, Head of Integration Projects Support Department, ICD IT Directorate
Good day, Khabrovites!
A systematic approach to managing downloads. We want to tell how to streamline and automate the filling of the repository with information, and at the same time not to get confused in the flows from various sources.
Sooner or later, a moment comes in the corporate database of any company when it grows to the size that the architect’s eye no longer captures the uncertainty (chaos) of the system, and turns into an uncontrollable mass of all kinds of downloads from various sources.
You are lucky if your system was developed from scratch (from the first table) and was run by one architect, one team of developers and analysts. And besides, this architect competently led a data warehouse model. But life is multifaceted, in most cases DWH grows spontaneously, at first there were 30 tables, then we added a little more as needed, and then we liked it and we began to add for every opportunity, and now we have more than five thousand, yes layers, staging and showcases still appeared. And all this “happiness” fell on us as a result of one, but very convenient process, which is a tough causal relationship:
But, as a rule, the last point in reality does not exist. And it appears only at a certain moment in large companies that have grown to their DWH, where a neat architect competently manages the integrity of information in the database. Such repositories represent a review of the previous structure, which was re-documented, and often re-built, with an eye on the previous (not documented) version.
So, a brief summary:
If you are the happy owner of the “correct” DWH, or are part of the team of this happy owner, this article “in theory” may seem interesting to you. And if you just have to go through a review, or (forbid you) rebuild, then this article can greatly simplify your life.
Since there can be an unimaginable amount of information sources, there are at least the same number of download and overload streams of different objects, and often much more, since each database object can go through more than one transformation before its data can be used by the end user to build business reports. But it’s for him, for business, and not for his own pleasure that this whole ecosystem was built for “transfusion from vessel to vessel”.
Oracle is used as the database of our storage. Once, at the creation stage, the central core of our database consisted of a couple of hundreds of tables. We did not think about staging and shop windows. But, as they say, “everything flows, everything changes”, and now we have grown! Business dictates new requirements, and integration has already appeared with various MS SQL, SyBASE, Vertica, Access databases. From where information does not flow to us, such exotic as XML and JSON exchange with third-party systems even appeared, and the XLS file as an information source is completely anachronistic.
Life made us go through the review and update the data model, maintain and maintain it. This is how one of the parts of the main core looks like:
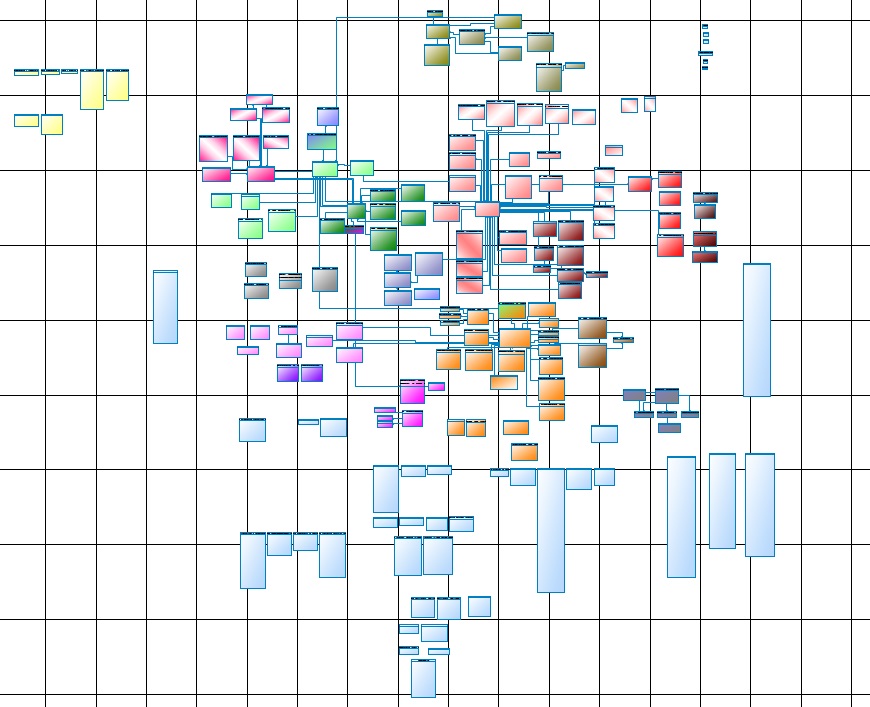
Fig. one
To whom it is, but for me - it is readable only on a Whatman paper, and A0 will be a little small, better than 4A0, on the screen it does not give in to the eye or imagination.
Now recall that this is only the core (Core Data Layer), or rather its main part, the full core consists of several subsystems that are not much inferior to the main one. Primary Data Layer and Data Mart Layer are also added to this. Further - more, the primary layer receives its information from data sources, and this, as mentioned above, various databases and files. On the other hand, to the layer of shop windows, various reporting systems are joined by the consumer.
At first, when there were few database tables and loading algorithms implemented in PL / SQL, there was no particular difficulty in understanding data updates. But with the rise of DWH, a strategic decision was to buy Informatica PowerCenter. With all the convenience of this tool, both in terms of reliability of loading and visualization of development, this tool has several disadvantages. The figure below shows a model for the startup sequence for loading a DWH.
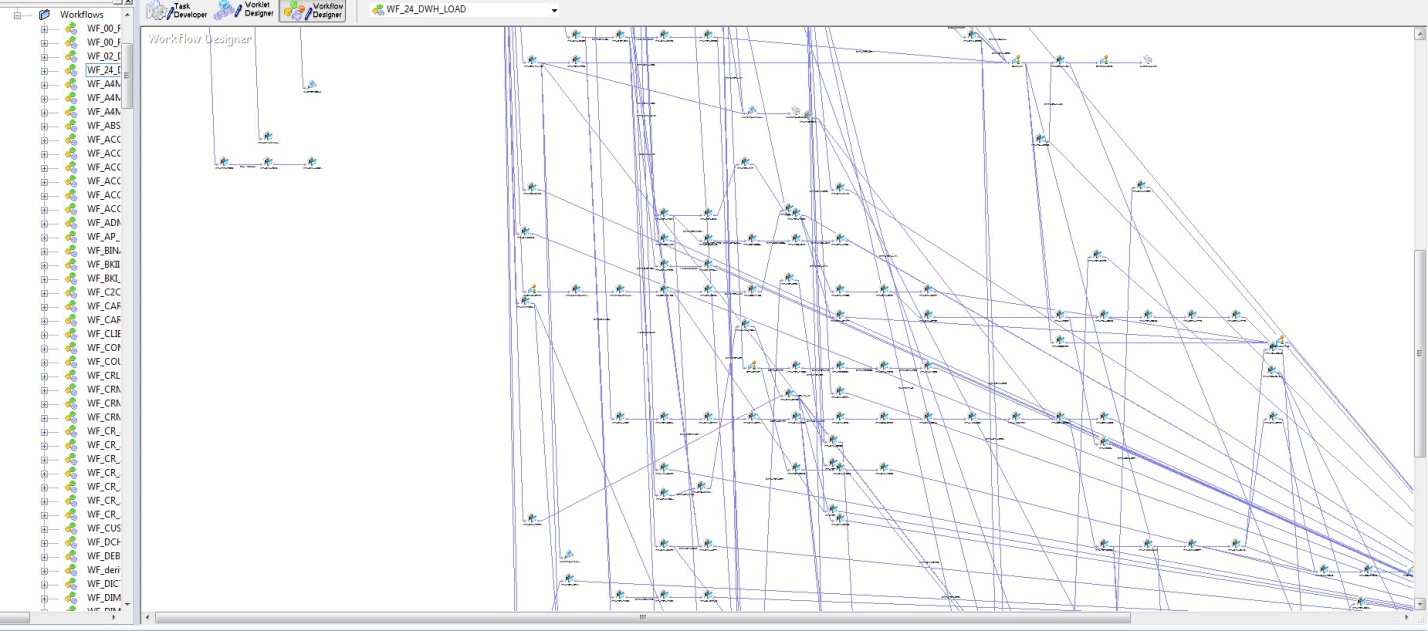
Fig. 2
The most important drawback is subjectivity, or rather, only the architect can guarantee that the postings are not loaded before the bills. Unfortunately, with the growth of DWH, the entropy of information also increases. Taking into account the physical data model (Fig. 1) and the logic of loading this data (Fig. 2), the construction is still obtained.
What to do and how to steer it, you ask. Naturally: to have a brilliant architect who is able to understand all the connections of these intricacies. Which will monitor all flows, coordinate new flows, and prevent the posting table from being loaded earlier than the account table. Of course, all this is sewn into the algorithms and regulated by the cut-offs of the downloads, but initially only the architect can understand and set the downloads a strict sequence, and with such branching the probability of mistakes is very high.
Now I will try to state the main ideas of the data model dictionary, as well as what tasks it solves.
Since the data in the storage is in tables, and the data sources are partly tables, and partly views, the latter themselves are tables. Then a simple idea follows - to create a TABLE – TABLE dependency structure. The 3NF form is the best fit for this.
Firstly, filling the DWH entity data, we call it (target) , in the most general case, can be represented as select from different tables. Whether it will be Oracle tables, SyBase, MSSQL, xls-files or something else, it is not so important, all this, we call their sources (source) . That is, we have a source that flows into target .
Secondly, each DWH entity has references to each other.
Thirdly, there is a chronology of starting downloads of various DWH entities.
It remains the case for small, to implement - how? It would seem that it’s very simple, from the foundation of your DWH, the architect, when the next table of the entity (target) appears, has to look at and put in the dictionary the entity receiver and all entities that serve as sources. Further, in the second table of the dictionary, specify the links between these entities sources in select, as well as all subordinate tables which are referenced by references. Next, you can embed the loading of this entity in the storage download chain. Only two tables - and the possibility of taking into account the sequence of filling the data with the algorithm in the algorithm has been solved.
Dictionary data model will solve the following problems:
In theory, everything is always simple and beautiful; in practice, things are somewhat different. What is written in the previous section is an ideal situation when DWH developed from scratch, when an architect was inseparably with it. If you are not lucky, all of this you have “safely” passed, there is no architect, but there is a giant set of tables, then anyway, there is a solution.
Now, in fact, I’ll tell you how we managed to catch up and make review and rebuild cheap enough. Our DWH began to evolve with a leadership decision about an imminent (DWH) need. As a tool, PL / SQL was first used. A little later switched to Informatica. Naturally, the timing was the priority. The data model in PowerDesigner appeared some time later, by the time when the confidence was clearly formed that no one could clearly imagine a complete and clear picture of DWH. We lived for some time with the model on the wall, when it became clear that we could not cope with the management of this entire system, we began to look for a solution that I will try to describe briefly here.
The data model dictionary itself is as simple as a stick. But filling it up is a problem. N-months of painstaking, and most importantly, careful consideration of the three above parts:
Fortunately, Oracle and Informatica helped us, and it turned out to be very successful that the Informatica repository is in the Oracle database. Taking as a basis that one Informatica Session is the loading atom of a DWH entity, digging a bit in the repository, we found all source and target. That is, within the framework of one Session, for all of its target (as a rule, it is one), all its source are sources. Thus, we can fill in the first condition of the problem. But do not rush to rejoice, source can be presented in the form of a very clever select, so you had to write a parser that pulls out all the tables specified in select - it was not at all difficult. But that is not all, these tables themselves can actually be representations. Using DBA_VIEWS (or through DBA_DEPENDENCIES) this issue was also resolved. We pulled the second condition of this trilogy from the data model (Fig. 1) and DBA_CONSTRAINTS. We also got the third condition from the Informatica repository based on (Fig. 2).
What came of all this?
You may have plenty more ways to apply the data model dictionary.
Thanks to all!
Good day, Khabrovites!
goal
A systematic approach to managing downloads. We want to tell how to streamline and automate the filling of the repository with information, and at the same time not to get confused in the flows from various sources.
Preamble
Sooner or later, a moment comes in the corporate database of any company when it grows to the size that the architect’s eye no longer captures the uncertainty (chaos) of the system, and turns into an uncontrollable mass of all kinds of downloads from various sources.
You are lucky if your system was developed from scratch (from the first table) and was run by one architect, one team of developers and analysts. And besides, this architect competently led a data warehouse model. But life is multifaceted, in most cases DWH grows spontaneously, at first there were 30 tables, then we added a little more as needed, and then we liked it and we began to add for every opportunity, and now we have more than five thousand, yes layers, staging and showcases still appeared. And all this “happiness” fell on us as a result of one, but very convenient process, which is a tough causal relationship:
- the business says: “We have a need for such and such data. Need a new report »
- the analyst is looking
- developer implements
- the architect coordinates and contributes to the data model
But, as a rule, the last point in reality does not exist. And it appears only at a certain moment in large companies that have grown to their DWH, where a neat architect competently manages the integrity of information in the database. Such repositories represent a review of the previous structure, which was re-documented, and often re-built, with an eye on the previous (not documented) version.
So, a brief summary:
- there is no DWH that was born immediately and previously was not a regular database with a set of tables;
- everything that exists now, and is a clearly algorithmized and documented structure, was obtained as a result of the “bitter experience” of previous developments.
If you are the happy owner of the “correct” DWH, or are part of the team of this happy owner, this article “in theory” may seem interesting to you. And if you just have to go through a review, or (forbid you) rebuild, then this article can greatly simplify your life.
Since there can be an unimaginable amount of information sources, there are at least the same number of download and overload streams of different objects, and often much more, since each database object can go through more than one transformation before its data can be used by the end user to build business reports. But it’s for him, for business, and not for his own pleasure that this whole ecosystem was built for “transfusion from vessel to vessel”.
Oracle is used as the database of our storage. Once, at the creation stage, the central core of our database consisted of a couple of hundreds of tables. We did not think about staging and shop windows. But, as they say, “everything flows, everything changes”, and now we have grown! Business dictates new requirements, and integration has already appeared with various MS SQL, SyBASE, Vertica, Access databases. From where information does not flow to us, such exotic as XML and JSON exchange with third-party systems even appeared, and the XLS file as an information source is completely anachronistic.
Life made us go through the review and update the data model, maintain and maintain it. This is how one of the parts of the main core looks like:
Fig. one
To whom it is, but for me - it is readable only on a Whatman paper, and A0 will be a little small, better than 4A0, on the screen it does not give in to the eye or imagination.
Now recall that this is only the core (Core Data Layer), or rather its main part, the full core consists of several subsystems that are not much inferior to the main one. Primary Data Layer and Data Mart Layer are also added to this. Further - more, the primary layer receives its information from data sources, and this, as mentioned above, various databases and files. On the other hand, to the layer of shop windows, various reporting systems are joined by the consumer.
At first, when there were few database tables and loading algorithms implemented in PL / SQL, there was no particular difficulty in understanding data updates. But with the rise of DWH, a strategic decision was to buy Informatica PowerCenter. With all the convenience of this tool, both in terms of reliability of loading and visualization of development, this tool has several disadvantages. The figure below shows a model for the startup sequence for loading a DWH.
Fig. 2
The most important drawback is subjectivity, or rather, only the architect can guarantee that the postings are not loaded before the bills. Unfortunately, with the growth of DWH, the entropy of information also increases. Taking into account the physical data model (Fig. 1) and the logic of loading this data (Fig. 2), the construction is still obtained.
What to do and how to steer it, you ask. Naturally: to have a brilliant architect who is able to understand all the connections of these intricacies. Which will monitor all flows, coordinate new flows, and prevent the posting table from being loaded earlier than the account table. Of course, all this is sewn into the algorithms and regulated by the cut-offs of the downloads, but initially only the architect can understand and set the downloads a strict sequence, and with such branching the probability of mistakes is very high.
Theory
Now I will try to state the main ideas of the data model dictionary, as well as what tasks it solves.
Since the data in the storage is in tables, and the data sources are partly tables, and partly views, the latter themselves are tables. Then a simple idea follows - to create a TABLE – TABLE dependency structure. The 3NF form is the best fit for this.
Firstly, filling the DWH entity data, we call it (target) , in the most general case, can be represented as select from different tables. Whether it will be Oracle tables, SyBase, MSSQL, xls-files or something else, it is not so important, all this, we call their sources (source) . That is, we have a source that flows into target .
Secondly, each DWH entity has references to each other.
Thirdly, there is a chronology of starting downloads of various DWH entities.
It remains the case for small, to implement - how? It would seem that it’s very simple, from the foundation of your DWH, the architect, when the next table of the entity (target) appears, has to look at and put in the dictionary the entity receiver and all entities that serve as sources. Further, in the second table of the dictionary, specify the links between these entities sources in select, as well as all subordinate tables which are referenced by references. Next, you can embed the loading of this entity in the storage download chain. Only two tables - and the possibility of taking into account the sequence of filling the data with the algorithm in the algorithm has been solved.
Dictionary data model will solve the following problems:
- View dependencies. You can see what data, where they are drawn from. This is convenient for analysts who are always tormented by questions: "where, what lies and where does everything come from." Present this in the application in the form of a tree, both from source to target , and vice versa: from target to source .
- Rupture of loops. When embedding the next load into an already working shared stream, without having a data model dictionary, it is quite possible to make a mistake and assign a start time for loading the next target in front of one of its source. This creates a loop. A data model dictionary will easily avoid this.
- You can write an algorithm for filling the storage, taking into account the model dictionary. In this case, there is no need to embed the next download anywhere, it is enough to reflect it in the dictionary and the algorithm will determine its place. It remains to click on the coveted “Make ALL” button. The bootloader will launch avalanche-like downloads of all storage entities - from simple (independent) to complex (dependent).
Implementation
In theory, everything is always simple and beautiful; in practice, things are somewhat different. What is written in the previous section is an ideal situation when DWH developed from scratch, when an architect was inseparably with it. If you are not lucky, all of this you have “safely” passed, there is no architect, but there is a giant set of tables, then anyway, there is a solution.
Now, in fact, I’ll tell you how we managed to catch up and make review and rebuild cheap enough. Our DWH began to evolve with a leadership decision about an imminent (DWH) need. As a tool, PL / SQL was first used. A little later switched to Informatica. Naturally, the timing was the priority. The data model in PowerDesigner appeared some time later, by the time when the confidence was clearly formed that no one could clearly imagine a complete and clear picture of DWH. We lived for some time with the model on the wall, when it became clear that we could not cope with the management of this entire system, we began to look for a solution that I will try to describe briefly here.
The data model dictionary itself is as simple as a stick. But filling it up is a problem. N-months of painstaking, and most importantly, careful consideration of the three above parts:
- what sources (source) each entity of the repository (target) consists of;
- what are the relationships between storage objects (references);
- the chronology of the start of downloads and filling the repository.
Fortunately, Oracle and Informatica helped us, and it turned out to be very successful that the Informatica repository is in the Oracle database. Taking as a basis that one Informatica Session is the loading atom of a DWH entity, digging a bit in the repository, we found all source and target. That is, within the framework of one Session, for all of its target (as a rule, it is one), all its source are sources. Thus, we can fill in the first condition of the problem. But do not rush to rejoice, source can be presented in the form of a very clever select, so you had to write a parser that pulls out all the tables specified in select - it was not at all difficult. But that is not all, these tables themselves can actually be representations. Using DBA_VIEWS (or through DBA_DEPENDENCIES) this issue was also resolved. We pulled the second condition of this trilogy from the data model (Fig. 1) and DBA_CONSTRAINTS. We also got the third condition from the Informatica repository based on (Fig. 2).
What came of all this?
- Firstly, we untangled all the loops that we managed to wind in the evolution of our DWH.
- Secondly, we got a wonderful tree for analysts:

Fig. 3 - Thirdly, our superloader, presented in fig. 2 turned into elegant (sorry, colleagues, but the blurriness of the picture is intentional, since this is working data):
Fig. four
You may have plenty more ways to apply the data model dictionary.
Thanks to all!
All Articles