2 life hacks: alternatives to classic search in Microsoft SQL Server
Hello, Habr! Our friends from Softpoint have prepared an interesting article about Microsoft SQL Server. It parses two practical examples of using full-text search:
Join now!

I give the floor to the author
An effective search in gigabytes of accumulated data is a kind of “holy grail” of accounting systems. Everyone wants to find him and gain immortal glory, but in the process of searching over and over again it turns out that there is no single miraculous solution.
The situation is complicated by the fact that users usually want to search for a substring - somewhere it turns out that the desired contract number is "buried" in the middle of the comment; somewhere, the operator does not remember exactly the name of the client, but he remembered that his name was “Alexey Evgrafovich”; somewhere, you just need to omit the recurring form of ownership of SEYUBL and search immediately by name of organization. For classic relational DBMSs, such a search is very bad news. Most often, such a substring search is reduced to the methodical scrolling of each row of the table. Not the most effective strategy, especially if the size of the table grows to several tens of gigabytes.
In search of an alternative, I often recall the “full-text search”. The joy of finding a solution usually passes quickly after a cursory review of existing practice. It quickly turns out that, according to popular opinion, full-text search:
The set of myths can be continued for a long time, but even Plato taught us to be skeptics and not blindly accept someone else's opinion on faith. Let's see if the devil is so terrible as he is painted?
And, while we are not deeply immersed in the study, we will immediately agree on an important condition . The full-text search engine can do much more than a regular string search. For example, you can define a dictionary of synonyms and use the word “contact” to find “phone”. Or search for words without regard to form and endings. These options can be very useful for users, but in this article we consider full-text search only as an alternative to the classic string search. That is, we will only search for the substring that will be specified in the search bar , without taking into account synonyms, without casting words to the “normal” form and other magic.
The full-text search functionality in MS SQL is partially removed from the main DBMS service (closer to the end of the article we will see why this can be extremely useful). For the search, a special index is formed with its structure, unlike the usual balanced trees.
It is important that in order to create a full-text search index, it is necessary that a unique index exist in the key table, consisting of only one column - it is its full-text search that will be used to identify table rows. Often the table already has such an index on the Primary Key, but sometimes it will have to be created additionally.
The full-text search index is populated asynchronously and out of transaction. After changing a table row, it is queued for processing. The process of updating the index receives from the table row (row) all the string values, "signed" to the index, and breaks them into separate words. After this, the words can be reduced to a certain “standard” form (for example, without endings), so that it is easier to search by word forms. “Stop words” are thrown out (prepositions, articles and other words that do not carry meaning). The remaining word-to-string link matches are written to the full-text search index.
It turns out that each column of the table included in the index passes through such a pipeline:
Long line -> wordbreaker -> set of parts (words) -> stemmer -> normalized words -> [optional] stop word exception -> write to index
As mentioned, the index update process is asynchronous. Therefore:
For experiments, we will create a new empty base with one table where the “counterparties” will be stored. Inside the “description” field there will be a line with the name of the contract, where the name of the counterparty will be mentioned. Something like this:
"Agreement with Borovik Demyan Emelyanovich"
Or so:
“Dog. with Borovik-Romanov Anatoly Avdeevich "
Yes, I want to shoot myself right away from such “architecture”, but, unfortunately, such an application of “comments” or “descriptions” is often among business users.
Additionally, we add a few fields “for weight”: if there are only 2 columns in the table, a simple scan will read it in moments. We need to “inflate” the table so that the scan is long. This brings us closer to real business cases: we do not only store the “description” in the table, but also a lot of other [devil] useful information.
The next question is where to get so many unique surnames, names and patronymics? I, according to an old habit, acted as a normal Russian student, i.e. went to Wikipedia:
Of course, there were strange variations among the surnames, but for the purposes of the study this was perfectly acceptable.
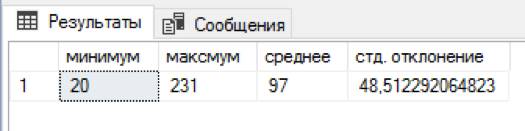
I wrote a sql script that attaches a random number of names and patronymics to each last name. 5 minutes of waiting and in a separate table there were already 4.5 million combinations. Not bad! For each surname there were from 20 to 231 combinations of the name + middle name, on average 97 combinations were obtained. The distribution by name and patronymic turned out to be slightly biased “to the left,” but it seemed redundant to come up with a more balanced algorithm.
The data is prepared, we can begin our experiments.
Create a full-text index at the MS SQL level. First, we need to create a repository for this index - a full-text catalog.
There is a catalog, we are trying to add a full-text index for our table ... and nothing works.
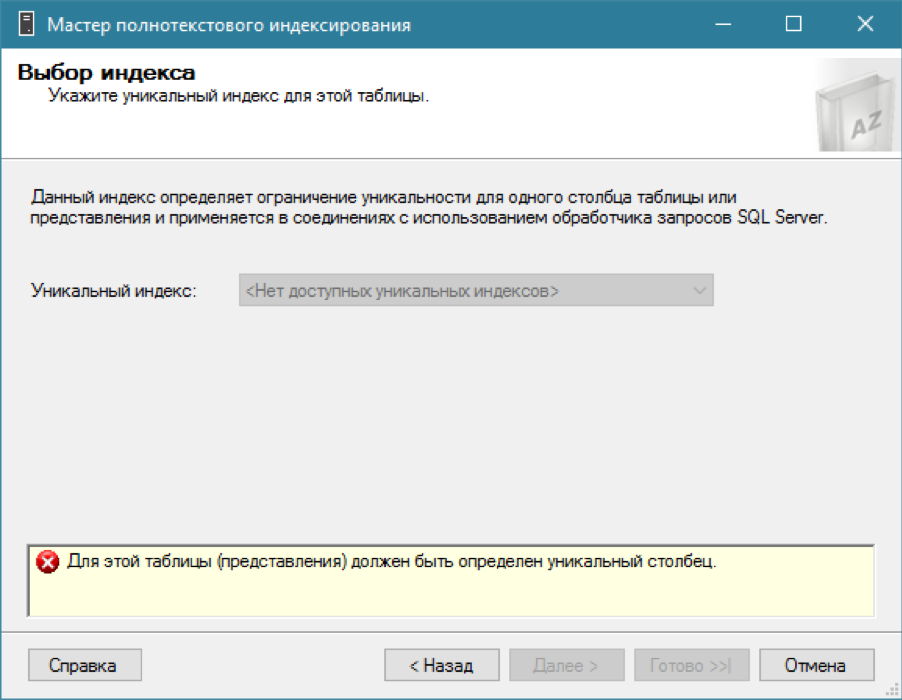
As I said, for a full-text index you need a regular index with one unique column. We recall that we already have the required field - a unique identifier id. Let's create a unique cluster index on it (although a nonclustered one would be enough):
After creating a new index, we can finally add the full-text search index. Let's wait a few minutes until the index is full (remember that it is updated asynchronously!). You can proceed to the tests.
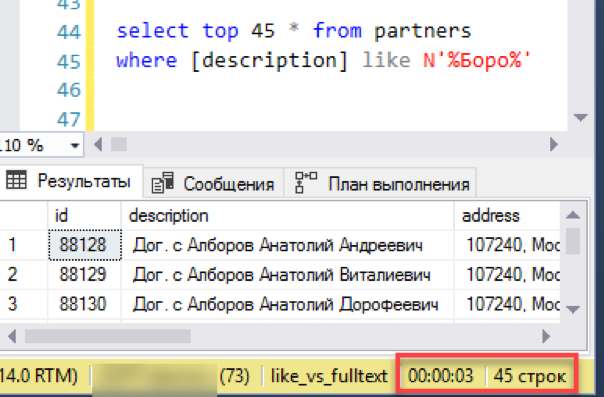
Let's start with the simplest scenario, close to the real application of the search. We simulate a “list view” - a window selection of 45 lines with selection by search mask. We execute the request with a new full-text index, we note the time - 0 seconds - excellent!
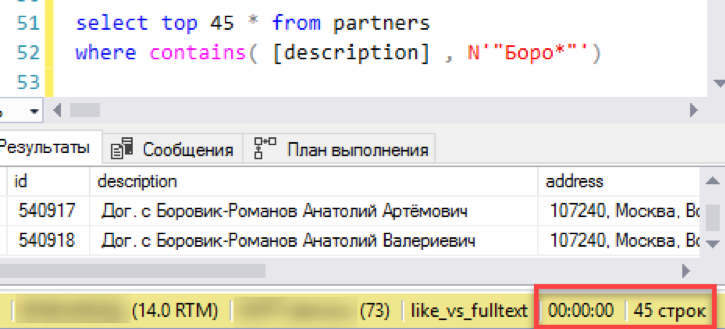
Now an old, verified search through "like". It took 3 seconds to form the result. Not so bad, total defeat did not work. Maybe then it makes no sense to configure full-text search - does everything work just fine?
In fact, we missed one important detail: the request was executed without sorting. Firstly, such a query paired with “selecting the first N records” returns an unwarranted result. Each start can return random N records and there is no guarantee that two consecutive starts will give the same data set. Secondly, if we are talking about “viewing the list with a sliding window” - usually this very “window” is sorted by any column, for example, by name. After all, the operator needs to know what he will get when he moves to the next “window”.
Correct the experiment. Add sorting, say, by phone number:
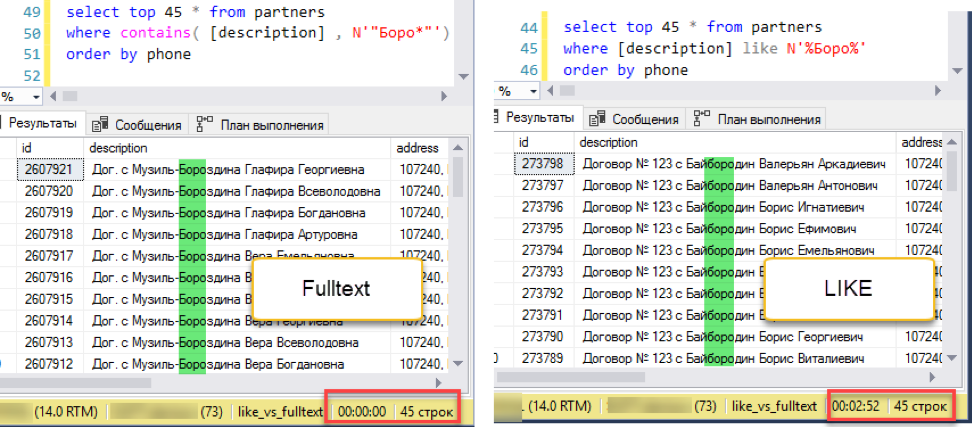
Full-text search wins with a deafening score: 0 seconds versus 172 seconds!
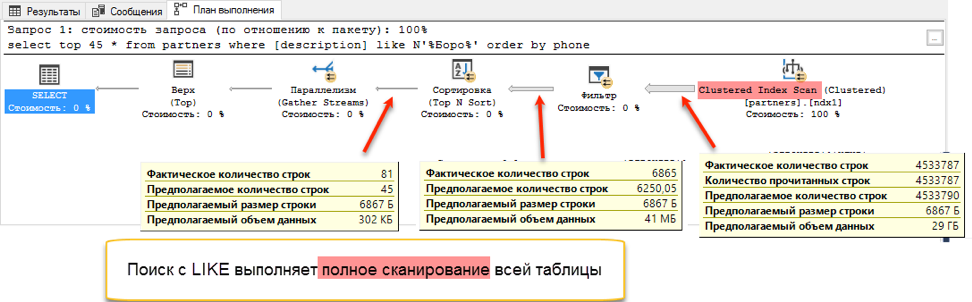
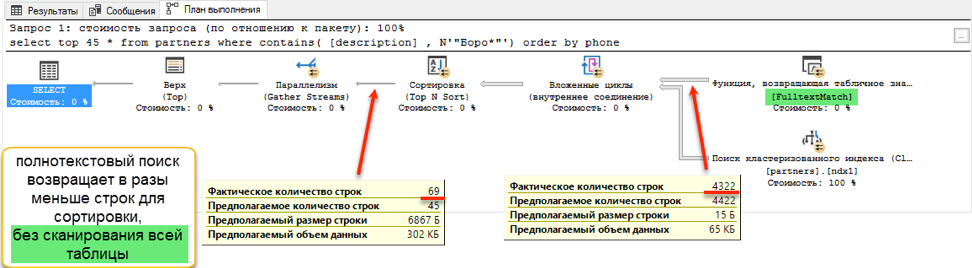
If you look at the query plans, it becomes clear why this is so. Due to the addition of ordering to the query text, a sort operation appeared during execution. This is the so-called “blocking” operation, which cannot complete the request until it receives the entire amount of data for sorting. We can’t pick up the first 45 records that we have, we need to sort the entire data set.
And at the stage of obtaining data for sorting, a dramatic difference occurs. A search with “like” has to browse through the entire available table. This takes 172 seconds. But the full-text search has its own optimized structure, which immediately returns links to all the necessary entries.
But should there be a fly in the ointment? There is one. As stated at the beginning, a full-text search can only search from the beginning of a word. And if we want to find “Ivan Poddubny” by the substring “* oak *”, a full-text search will not show anything useful.
Fortunately, for searching by name, this is not the most popular scenario.
Let's try something more complicated. The second popular use case for searching is to locate a document by part of its number. Moreover, often the document number consists of two parts: the letter prefix and the actual number containing leading zeros.
There are no spaces or service characters between these parts. At the same time, searching by the full number is monstrously inconvenient - you have to remember how many leading zeros after the prefix must be before the beginning of the significant part. It turns out that full-text search “out of the box” is simply useless in such a scenario. Let's try to fix it.
For the test, I created a new table called document, in which I added 13.5 million records with unique numbers of the “ORG” type. Numbering went in order, all numbers began with "ORG". You can start.
Full-text search is able to effectively search for words. Well, let's help him and break up the “uncomfortable” number into convenient words in advance. The action plan is as follows:
Let's see how this will work.
Add an additional column to the table.
A trigger filling a new column can be written “forehead”, ignoring possible duplicates (how many repeating triples are in the number “0000012”?) And you can add some XML magic and record only unique parts. The first implementation will be faster, the second will give a more compact result. In fact, the choice is between writing speed and reading speed, choose what is more important in your situation. Now just go through a script that processes existing numbers.
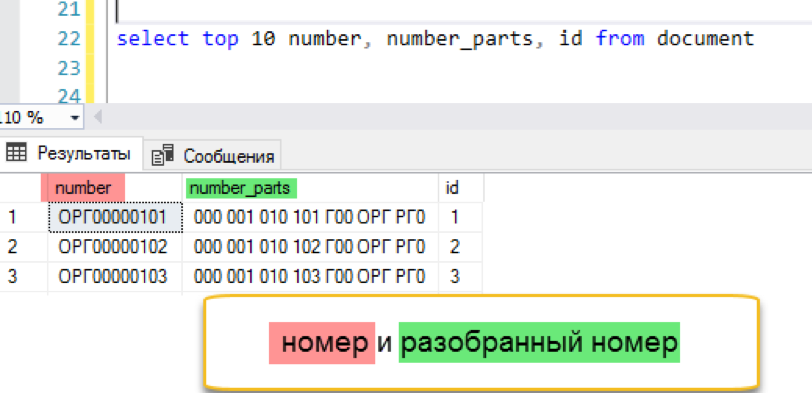
Add full-text index
And check the result. The experiment is the same - modeling a “window” selection from a list of documents. We do not repeat the previous errors and immediately execute the request with sorting, in this case by date.
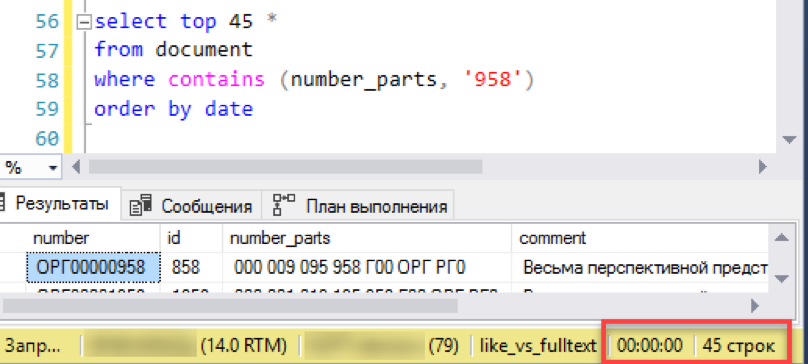
Works! Now let's try a more authentic number:
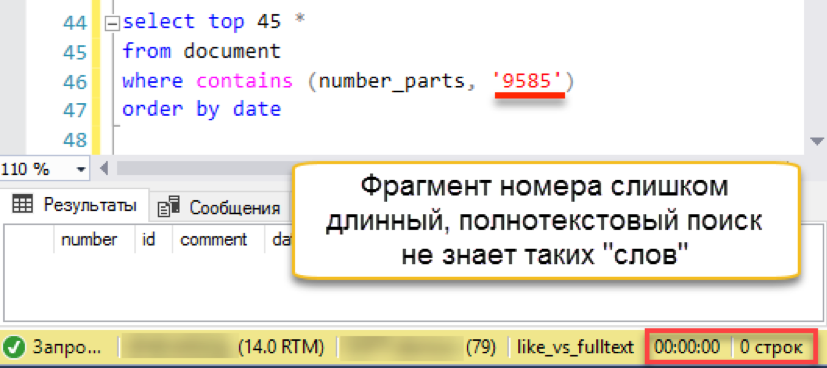
And then a misfire happens. The length of the search string is longer than the length of the stored "words". In fact, the search database simply does not have a single line of 4 characters, so it honestly returns an empty result. We’ll have to beat the search string into parts:
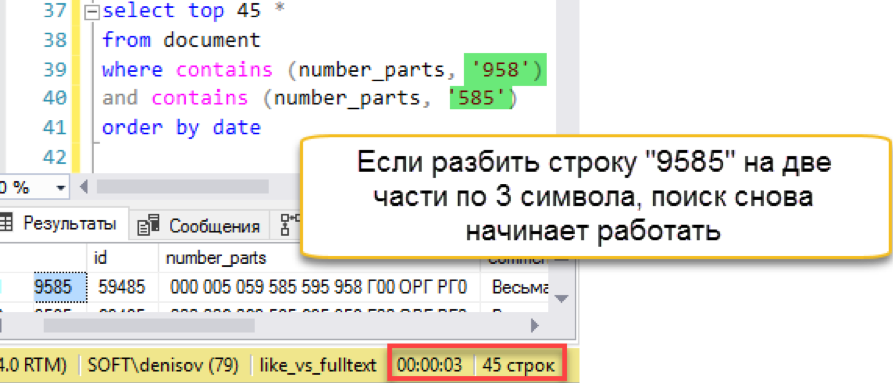
Another thing! We again have a quick search. Yes, he imposes his overhead on maintenance, but the result is hundreds of times faster than the classic search. We note the attempt counted, but try to simplify the maintenance somehow - in the next section.
In fact, who said that words should be separated by spaces? Maybe I want zeros between words! (and, if possible, the prefix so that it is also somehow ignored and does not interfere underfoot). In general, there is nothing impossible in this. Let us recall the full-text search operation scheme from the beginning of the article - a separate component, wordbreaker, is responsible for breaking into words, and, fortunately, Microsoft allows you to implement your own “word breaker”.
And here the interesting begins. Wordbreaker is a separate dll that connects to the full-text search engine. The official documentation says that making this library is very simple - just implement the IWordBreaker interface. And here are a couple of short initialization listings in C ++. Very successfully, I just found a suitable tutorial!
 ( source )
( source )
Seriously, the documentation for creating your own worbreaker on the Internet is vanishingly small. Even fewer examples and templates. But I still found a kind person’s project that wrote a C ++ implementation that breaks down words not in delimiters, but simply in triples (yes, just like in the previous section!) Moreover, the project folder already contains a carefully compiled binary, which you just need connect to the search engine.
Just plugging in ... Not really easy. Let's go through the steps:
You need to copy the library to the folder with SQL Server:

Register a new “language” in full-text search
Manually edit several keys in the registry (the author was going to automate the process, but there is no news since 2016. However, this was originally an “implementation example”, thanks for that too)
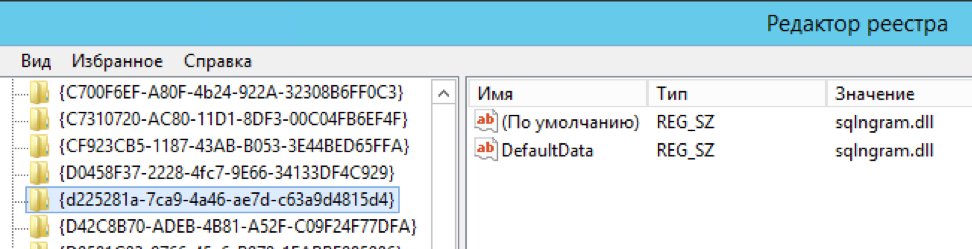
Details of the steps are described on the project page.
Done. Let's delete the old full-text index, because there cannot be two full-text indexes for one table. Create a new one and index our document numbers. As the key column, we indicate the numbers themselves, no more surrogate pre-broken columns are needed. Be sure to specify “language number 1” to use the freshly installed wordbreaker.
Check?
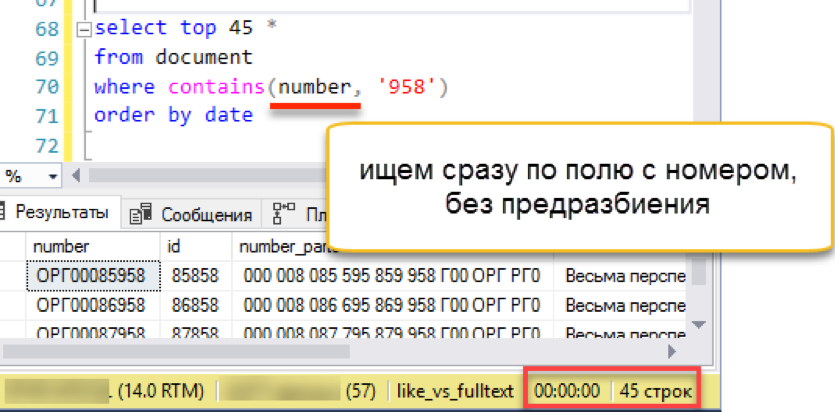
Works! It works as fast as all the examples discussed above.
Let's check the long line on which the previous option stumbled:
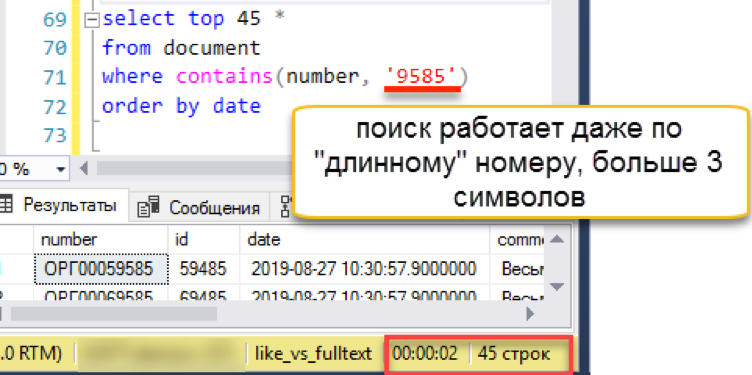
Search works transparently for the user and programmer. Wordbreaker independently breaks the search string into parts and finds the desired result.
It turns out that now we do not need additional columns and triggers, that is, the solution is simpler (read: more reliable) than our previous attempt. Well, in terms of support, such an implementation is simpler and more transparent, there is less chance of errors.
So, stop, I said "more reliable"? We just connected some third-party library to our DBMS! And what will happen if she falls? Even inadvertently drags out the entire database service!
Here you need to remember how at the beginning of the article I mentioned the full-text search service, separated from the main DBMS process. It is here that it becomes clear why this is important. The library connects to the full-text indexing service, which can operate with reduced rights. And, more importantly, if third-party components fall, only the indexing service will fall. The search will stop for a while (but it is already asynchronous), and the database engine will continue to work as if nothing had happened.
To summarize. Adding your own wordbreaker can be quite a challenge. But when playing "in the long", these efforts pay off with greater flexibility and ease of maintenance. The choice, as usual, is yours.
An inquisitive reader probably wondered more than once: “all this is great, but how can I use these features if I can’t change the search queries from my application?” Reasonable question. The inclusion of full-text MS SQL search requires changing the syntax of the queries, and often this is simply not possible in the existing architecture.
You can try to trick the application by “slipping” a table-valued function of the same name instead of a regular table, which will already perform the search the way we want. You can try to bind the search as a kind of external data source. There is another solution - Softpoint Data Cluster - a special service that installs a "forwarding" between the source application and the SQL Server service, listens for traffic and can change requests "on the fly" according to special rules. Using these rules, we can find regular queries with LIKE and convert them to CONTAINS with full-text search.
Why such difficulties? Still, the search speed is captivating. In a heavily loaded system, where operators often look for records in millions of tables, response speed is critical. Saving time on the most frequent operation results in dozens of additional processed applications, and this is real money, which any business is happy with. In the end, a few days or even weeks to study and implement the technology will pay off with increased operator efficiency.
All scripts mentioned in the article are available in the github.com/frrrost/mssql_fulltext repository
 Alexander Denisov - MS SQL Server Database Performance Analyst. Over the past 6 years, as part of the Softpoint team, I have been helping to find bottlenecks in other people's requests and squeeze the most out of clients' databases.
Alexander Denisov - MS SQL Server Database Performance Analyst. Over the past 6 years, as part of the Softpoint team, I have been helping to find bottlenecks in other people's requests and squeeze the most out of clients' databases.
- Search in “infinite” lines (eg Comments) as opposed to a regular search through LIKE;
- Search by document numbers with prefixes. Where usually full-text search cannot be used: constant prefixes interfere with it. 2 approaches are analyzed: preprocessing the document number and adding your own library-word breaker.
Join now!
I give the floor to the author
An effective search in gigabytes of accumulated data is a kind of “holy grail” of accounting systems. Everyone wants to find him and gain immortal glory, but in the process of searching over and over again it turns out that there is no single miraculous solution.
The situation is complicated by the fact that users usually want to search for a substring - somewhere it turns out that the desired contract number is "buried" in the middle of the comment; somewhere, the operator does not remember exactly the name of the client, but he remembered that his name was “Alexey Evgrafovich”; somewhere, you just need to omit the recurring form of ownership of SEYUBL and search immediately by name of organization. For classic relational DBMSs, such a search is very bad news. Most often, such a substring search is reduced to the methodical scrolling of each row of the table. Not the most effective strategy, especially if the size of the table grows to several tens of gigabytes.
In search of an alternative, I often recall the “full-text search”. The joy of finding a solution usually passes quickly after a cursory review of existing practice. It quickly turns out that, according to popular opinion, full-text search:
- Difficult to configure
- Slowly updated
- Hangs the system when updating
- Has some kind of
stupidunusual syntax - Doesn't find what they ask
The set of myths can be continued for a long time, but even Plato taught us to be skeptics and not blindly accept someone else's opinion on faith. Let's see if the devil is so terrible as he is painted?
And, while we are not deeply immersed in the study, we will immediately agree on an important condition . The full-text search engine can do much more than a regular string search. For example, you can define a dictionary of synonyms and use the word “contact” to find “phone”. Or search for words without regard to form and endings. These options can be very useful for users, but in this article we consider full-text search only as an alternative to the classic string search. That is, we will only search for the substring that will be specified in the search bar , without taking into account synonyms, without casting words to the “normal” form and other magic.
How MS SQL Full Text Search Works
The full-text search functionality in MS SQL is partially removed from the main DBMS service (closer to the end of the article we will see why this can be extremely useful). For the search, a special index is formed with its structure, unlike the usual balanced trees.
It is important that in order to create a full-text search index, it is necessary that a unique index exist in the key table, consisting of only one column - it is its full-text search that will be used to identify table rows. Often the table already has such an index on the Primary Key, but sometimes it will have to be created additionally.
The full-text search index is populated asynchronously and out of transaction. After changing a table row, it is queued for processing. The process of updating the index receives from the table row (row) all the string values, "signed" to the index, and breaks them into separate words. After this, the words can be reduced to a certain “standard” form (for example, without endings), so that it is easier to search by word forms. “Stop words” are thrown out (prepositions, articles and other words that do not carry meaning). The remaining word-to-string link matches are written to the full-text search index.
It turns out that each column of the table included in the index passes through such a pipeline:
Long line -> wordbreaker -> set of parts (words) -> stemmer -> normalized words -> [optional] stop word exception -> write to index
As mentioned, the index update process is asynchronous. Therefore:
- Update does not block user actions
- The update waits for the completion of the row change transaction and begins to apply the changes no earlier than commit
- Changes to the full-text index are applied with some delay relative to the main transaction. That is, between adding a row and the moment when it can be found, there will be a delay depending on the length of the index update queue
- The number of elements contained in the index can be monitored by the query:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
Practical tests. Search for physical persons by name
Filling the table with data
For experiments, we will create a new empty base with one table where the “counterparties” will be stored. Inside the “description” field there will be a line with the name of the contract, where the name of the counterparty will be mentioned. Something like this:
"Agreement with Borovik Demyan Emelyanovich"
Or so:
“Dog. with Borovik-Romanov Anatoly Avdeevich "
Yes, I want to shoot myself right away from such “architecture”, but, unfortunately, such an application of “comments” or “descriptions” is often among business users.
Additionally, we add a few fields “for weight”: if there are only 2 columns in the table, a simple scan will read it in moments. We need to “inflate” the table so that the scan is long. This brings us closer to real business cases: we do not only store the “description” in the table, but also a lot of other [devil] useful information.
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
The next question is where to get so many unique surnames, names and patronymics? I, according to an old habit, acted as a normal Russian student, i.e. went to Wikipedia:
- Names taken from the page Category: Russian male names
- Manually rewritten middle names from names, changing endings
- With surnames it turned out to be a little more complicated. In the end, the category "namesakes" was found. A little shamanism with Python and in a separate table turned out 46.5 thousand names. (a script for downloading names is available here)
Of course, there were strange variations among the surnames, but for the purposes of the study this was perfectly acceptable.
I wrote a sql script that attaches a random number of names and patronymics to each last name. 5 minutes of waiting and in a separate table there were already 4.5 million combinations. Not bad! For each surname there were from 20 to 231 combinations of the name + middle name, on average 97 combinations were obtained. The distribution by name and patronymic turned out to be slightly biased “to the left,” but it seemed redundant to come up with a more balanced algorithm.
The data is prepared, we can begin our experiments.
Full Text Search Setup
Create a full-text index at the MS SQL level. First, we need to create a repository for this index - a full-text catalog.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
There is a catalog, we are trying to add a full-text index for our table ... and nothing works.
As I said, for a full-text index you need a regular index with one unique column. We recall that we already have the required field - a unique identifier id. Let's create a unique cluster index on it (although a nonclustered one would be enough):
create unique clustered index ndx1 on partners (id)
After creating a new index, we can finally add the full-text search index. Let's wait a few minutes until the index is full (remember that it is updated asynchronously!). You can proceed to the tests.
Testing
Let's start with the simplest scenario, close to the real application of the search. We simulate a “list view” - a window selection of 45 lines with selection by search mask. We execute the request with a new full-text index, we note the time - 0 seconds - excellent!
Now an old, verified search through "like". It took 3 seconds to form the result. Not so bad, total defeat did not work. Maybe then it makes no sense to configure full-text search - does everything work just fine?
In fact, we missed one important detail: the request was executed without sorting. Firstly, such a query paired with “selecting the first N records” returns an unwarranted result. Each start can return random N records and there is no guarantee that two consecutive starts will give the same data set. Secondly, if we are talking about “viewing the list with a sliding window” - usually this very “window” is sorted by any column, for example, by name. After all, the operator needs to know what he will get when he moves to the next “window”.
Correct the experiment. Add sorting, say, by phone number:
Full-text search wins with a deafening score: 0 seconds versus 172 seconds!
If you look at the query plans, it becomes clear why this is so. Due to the addition of ordering to the query text, a sort operation appeared during execution. This is the so-called “blocking” operation, which cannot complete the request until it receives the entire amount of data for sorting. We can’t pick up the first 45 records that we have, we need to sort the entire data set.
And at the stage of obtaining data for sorting, a dramatic difference occurs. A search with “like” has to browse through the entire available table. This takes 172 seconds. But the full-text search has its own optimized structure, which immediately returns links to all the necessary entries.
But should there be a fly in the ointment? There is one. As stated at the beginning, a full-text search can only search from the beginning of a word. And if we want to find “Ivan Poddubny” by the substring “* oak *”, a full-text search will not show anything useful.
Fortunately, for searching by name, this is not the most popular scenario.
Search for a document by number
Let's try something more complicated. The second popular use case for searching is to locate a document by part of its number. Moreover, often the document number consists of two parts: the letter prefix and the actual number containing leading zeros.
There are no spaces or service characters between these parts. At the same time, searching by the full number is monstrously inconvenient - you have to remember how many leading zeros after the prefix must be before the beginning of the significant part. It turns out that full-text search “out of the box” is simply useless in such a scenario. Let's try to fix it.
For the test, I created a new table called document, in which I added 13.5 million records with unique numbers of the “ORG” type. Numbering went in order, all numbers began with "ORG". You can start.
Pre-splitting a number
Full-text search is able to effectively search for words. Well, let's help him and break up the “uncomfortable” number into convenient words in advance. The action plan is as follows:
- Add an additional column to the source table where the specially converted number will be stored
- Add a trigger, which when changing the number will break it into several small parts, separated by a space
- Full-text search already knows how to split a string into parts by spaces, so that it will index our modified number without problems
Let's see how this will work.
Add an additional column to the table.
alter table document add number_parts nvarchar(128) not null default ''
A trigger filling a new column can be written “forehead”, ignoring possible duplicates (how many repeating triples are in the number “0000012”?) And you can add some XML magic and record only unique parts. The first implementation will be faster, the second will give a more compact result. In fact, the choice is between writing speed and reading speed, choose what is more important in your situation. Now just go through a script that processes existing numbers.
Add full-text index
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
And check the result. The experiment is the same - modeling a “window” selection from a list of documents. We do not repeat the previous errors and immediately execute the request with sorting, in this case by date.
Works! Now let's try a more authentic number:
And then a misfire happens. The length of the search string is longer than the length of the stored "words". In fact, the search database simply does not have a single line of 4 characters, so it honestly returns an empty result. We’ll have to beat the search string into parts:
Another thing! We again have a quick search. Yes, he imposes his overhead on maintenance, but the result is hundreds of times faster than the classic search. We note the attempt counted, but try to simplify the maintenance somehow - in the next section.
We will break it into words in our own way!
In fact, who said that words should be separated by spaces? Maybe I want zeros between words! (and, if possible, the prefix so that it is also somehow ignored and does not interfere underfoot). In general, there is nothing impossible in this. Let us recall the full-text search operation scheme from the beginning of the article - a separate component, wordbreaker, is responsible for breaking into words, and, fortunately, Microsoft allows you to implement your own “word breaker”.
And here the interesting begins. Wordbreaker is a separate dll that connects to the full-text search engine. The official documentation says that making this library is very simple - just implement the IWordBreaker interface. And here are a couple of short initialization listings in C ++. Very successfully, I just found a suitable tutorial!
( source )
Seriously, the documentation for creating your own worbreaker on the Internet is vanishingly small. Even fewer examples and templates. But I still found a kind person’s project that wrote a C ++ implementation that breaks down words not in delimiters, but simply in triples (yes, just like in the previous section!) Moreover, the project folder already contains a carefully compiled binary, which you just need connect to the search engine.
Just plugging in ... Not really easy. Let's go through the steps:
You need to copy the library to the folder with SQL Server:
Register a new “language” in full-text search
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
Manually edit several keys in the registry (the author was going to automate the process, but there is no news since 2016. However, this was originally an “implementation example”, thanks for that too)
Details of the steps are described on the project page.
Done. Let's delete the old full-text index, because there cannot be two full-text indexes for one table. Create a new one and index our document numbers. As the key column, we indicate the numbers themselves, no more surrogate pre-broken columns are needed. Be sure to specify “language number 1” to use the freshly installed wordbreaker.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
Check?
Works! It works as fast as all the examples discussed above.
Let's check the long line on which the previous option stumbled:
Search works transparently for the user and programmer. Wordbreaker independently breaks the search string into parts and finds the desired result.
It turns out that now we do not need additional columns and triggers, that is, the solution is simpler (read: more reliable) than our previous attempt. Well, in terms of support, such an implementation is simpler and more transparent, there is less chance of errors.
So, stop, I said "more reliable"? We just connected some third-party library to our DBMS! And what will happen if she falls? Even inadvertently drags out the entire database service!
Here you need to remember how at the beginning of the article I mentioned the full-text search service, separated from the main DBMS process. It is here that it becomes clear why this is important. The library connects to the full-text indexing service, which can operate with reduced rights. And, more importantly, if third-party components fall, only the indexing service will fall. The search will stop for a while (but it is already asynchronous), and the database engine will continue to work as if nothing had happened.
To summarize. Adding your own wordbreaker can be quite a challenge. But when playing "in the long", these efforts pay off with greater flexibility and ease of maintenance. The choice, as usual, is yours.
Why is all this necessary?
An inquisitive reader probably wondered more than once: “all this is great, but how can I use these features if I can’t change the search queries from my application?” Reasonable question. The inclusion of full-text MS SQL search requires changing the syntax of the queries, and often this is simply not possible in the existing architecture.
You can try to trick the application by “slipping” a table-valued function of the same name instead of a regular table, which will already perform the search the way we want. You can try to bind the search as a kind of external data source. There is another solution - Softpoint Data Cluster - a special service that installs a "forwarding" between the source application and the SQL Server service, listens for traffic and can change requests "on the fly" according to special rules. Using these rules, we can find regular queries with LIKE and convert them to CONTAINS with full-text search.
Why such difficulties? Still, the search speed is captivating. In a heavily loaded system, where operators often look for records in millions of tables, response speed is critical. Saving time on the most frequent operation results in dozens of additional processed applications, and this is real money, which any business is happy with. In the end, a few days or even weeks to study and implement the technology will pay off with increased operator efficiency.
All scripts mentioned in the article are available in the github.com/frrrost/mssql_fulltext repository
about the author
Alexander Denisov - MS SQL Server Database Performance Analyst. Over the past 6 years, as part of the Softpoint team, I have been helping to find bottlenecks in other people's requests and squeeze the most out of clients' databases. All Articles