Composer with a long short-term memory
Automatically compose music

Almost immediately after I learned programming, I wanted to create software capable of composing music.
For several years I made primitive attempts to automatically compose music for Visions of Chaos . Basically, simple mathematical formulas or genetic mutations of random sequences of notes were used. Having recently achieved modest success in the study and application of TensorFlow and neural networks to search for cellular automata , I decided to try using neural networks to create music.
How it works
The composer teaches a neural network with long short-term memory (LSTM). LSTM networks are well suited for predicting what comes next in data sequences. Read more about LSTM here .

An LSTM network receives various sequences of notes (in this case, these are single-channel midi files). After enough training, she gets the opportunity to create music similar to educational materials.

LSTM internals may seem intimidating, but using TensorFlow and / or Keras greatly simplifies LSTM creation and experimentation.
Source music for model training
For such simple LSTM networks, it’s enough for us that the source compositions are a single midi channel. Great for this are midi files from solo to piano. I found midi files with piano solos on the Classical Piano Midi Page and mfiles , and used them to train my models.
I put the music of different composers in separate folders. Thanks to this, the user can select Bach, click on the Compose button and get a composition that (hopefully) will be like Bach.
LSTM Model
The model on the basis of which I wrote the code selected this example of the author Sigurður Skúli Sigurgeirsson , about whom he writes in more detail here .
I ran the lstm.py script and after 15 hours it completed the training. When I ran predict.py to generate the midi files, I was disappointed because they consisted of one repeating note. Repeating the training twice, I got the same results.
Source model
model = Sequential() model.add(CuDNNLSTM(512,input_shape=(network_input.shape[1], network_input.shape[2]),return_sequences=True)) model.add(Dropout(0.3)) model.add(CuDNNLSTM(512, return_sequences=True)) model.add(Dropout(0.3)) model.add(CuDNNLSTM(512)) model.add(Dense(256)) model.add(Dropout(0.3)) model.add(Dense(n_vocab)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='rmsprop',metrics=["accuracy"])
Having added graph output to the script, I saw why my model did not work. Accuracy did not grow over time, as it should. See below in the post for good graphs that show how the working model should look.

I had no idea why it happened. but abandoned this model and began to adjust the settings.
model = Sequential() model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True)) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(CuDNNLSTM(256)) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(Dense(128, activation="relu")) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(Dense(n_vocab)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"])
It is more compact and has fewer LSTM layers. I also added BatchNormalization, seeing it in the sentdex video . Most likely, there are better models, but this one worked quite well in all my training sessions.
Notice that in both models I replaced LSTM with CuDNNLSTM. So I achieved much faster LSTM training thanks to the use of Cuda. If you do not have a GPU with Cuda support , then you have to use LSTM. Thanks to sendtex for this tip. Learning new models and composing midi files using CuDNNLSTM is about five times faster.
How long should the model be trained?
The similarity of the results with the original music depends on the duration of the model's training (the number of eras). If there are too few eras, then the resulting result will have too many repeating notes. If there are too many eras, the model will be retrained and simply copy the original music.
But how do you know how many eras to stop?
A simple solution is to add a callback that stores a model and accuracy / loss graph every 50 eras on a training run in 500 eras. Thanks to this, after completing the training, you will get models and graphs with an increment of 50 eras, showing how the training goes.
Here are the results of the graphs of one run with saving every 50 eras, combined into one animated GIF.
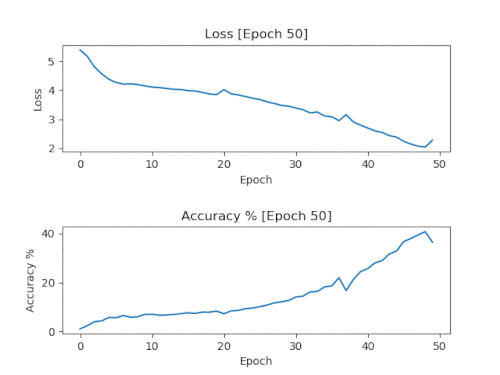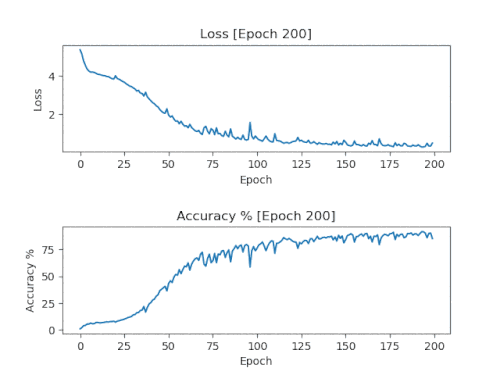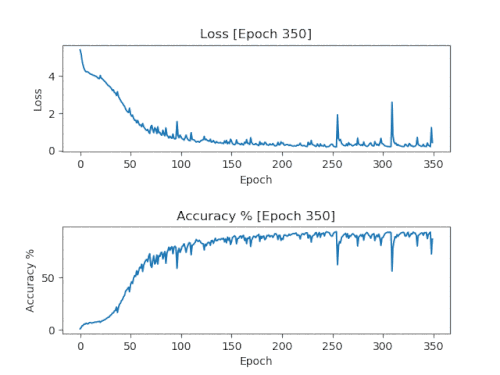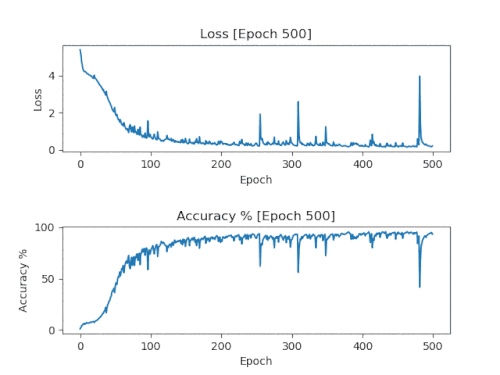
These are the graphs we want to see. Losses should fall and remain low. Accuracy should increase and remain close to 100%.
It is necessary to use a model with the number of epochs corresponding to the moment when the graphs first reached their limits. For the graph shown above, it will be 150 eras. If you use older models, they will be retrained and most likely will lead to a simple copying of the source material.
The model corresponding to these graphs was trained on midi files of the Anthems category taken from here .
Output midi data in a model with 150 eras.
Output midi data in a 100-epoch model.
Even a model with 100 eras can copy the source too accurately. This may be due to a relatively small sample of midi files for training. With more notes, learning is better.
When learning goes bad

The image above shows an example of what can sometimes happen and happens during training. Losses are reduced, and accuracy is increased, as usual, but suddenly they begin to go crazy. At this stage, it may also be worth stopping. The model will no longer (at least in my experience) learn correctly again. In this case, the saved model with 100 eras is still too random, and with 150 epochs the moment of model failure has already passed. Now I am saved every 25 eras to find the perfect moment of the model with the best training, even before she retrains and crashes.

Another example of learning error. This model was trained on midi files taken from here . In this case, she held well for a little longer than 200 eras. When using a model with 200 eras, the following result is obtained in Midi.
Without creating graphs, we would never know if the model has problems and when they arose, and also could not get a good model without starting from scratch.
Other examples
A model with 75 eras, created on the basis of Chopin's compositions.
A 50-era model based on Midi files for Christmas compositions .
A 100-epoch model based on Midi files for Christmas compositions . But are they really “Christmas”?
300-epoch model based on Bach Midi files taken from here and from here .
A 200-epoch model based on Balakirev's only Midi file taken here .
A 200-era model based on Debussy compositions.
A 175-era model based on Mozart’s compositions.
A model with 100 eras based on Schubert compositions.
A 200-era model based on Schumann compositions.
A 200-era model based on Tchaikovsky’s compositions.
A model with 175 eras based on folk songs.
Model with 100 eras based on lullabies.
A 100-era model based on wedding music.
A 200-epoch model based on my own midi files taken from my YouTube video soundtracks. It may be a bit retrained because it basically generates copies of my short one- and two-stroke midi files.
Scores
Once you get your midi files, you can use online tools like SolMiRe to convert them to scores. Below is the score of the midi Softology file with 200 eras presented above.


Where can I test the composer
LSTM Composer is now included in Visions of Chaos .

Select a style from the drop-down list and click Compose. If you have installed the minimum required Python and TensorFlow (see instructions here ), then in a few seconds (if you have a fast GPU) you will receive a new machine-written midi file that you can listen to and use for any other purpose. No copyright, no royalties. If you don’t like the results, you can click Compose again and after a few seconds a new composition will be ready.
The results can not yet be considered full-fledged compositions, but they have interesting small sequences of notes that I will use to create music in the future. In this regard, an LSTM composer can be a good source of inspiration for new compositions.
Python source
Below is the Python script code I used for LSTM training and forecasting. For these scripts to work, it is not necessary to install Visions of Chaos, and learning and generating midi will work from the command line.
Here is the training script
lstm_music_train.py
lstm_music_train.py
# based on code from https://github.com/Skuldur/Classical-Piano-Composer # to use this script pass in; # 1. the directory with midi files # 2. the directory you want your models to be saved to # 3. the model filename prefix # 4. how many total epochs you want to train for # eg python -W ignore "C:\\LSTM Composer\\lstm_music_train.py" "C:\\LSTM Composer\\Bach\\" "C:\\LSTM Composer\\" "Bach" 500 import os import tensorflow as tf # ignore all info and warning messages os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR) import glob import pickle import numpy import sys import keras import matplotlib.pyplot as plt from music21 import converter, instrument, note, chord from datetime import datetime from keras.models import Sequential from keras.layers.normalization import BatchNormalization from keras.layers import Dense from keras.layers import Dropout from keras.layers import CuDNNLSTM from keras.layers import Activation from keras.utils import np_utils from keras.callbacks import TensorBoard from shutil import copyfile # name of midi file directory, model directory, model file prefix, and epochs mididirectory = str(sys.argv[1]) modeldirectory = str(sys.argv[2]) modelfileprefix = str(sys.argv[3]) modelepochs = int(sys.argv[4]) notesfile = modeldirectory + modelfileprefix + '.notes' # callback to save model and plot stats every 25 epochs class CustomSaver(keras.callbacks.Callback): def __init__(self): self.epoch = 0 # This function is called when the training begins def on_train_begin(self, logs={}): # Initialize the lists for holding the logs, losses and accuracies self.losses = [] self.acc = [] self.logs = [] def on_epoch_end(self, epoch, logs={}): # Append the logs, losses and accuracies to the lists self.logs.append(logs) self.losses.append(logs.get('loss')) self.acc.append(logs.get('acc')*100) # save model and plt every 50 epochs if (epoch+1) % 25 == 0: sys.stdout.write("\nAuto-saving model and plot after {} epochs to ".format(epoch+1)+"\n"+modeldirectory + modelfileprefix + "_" + str(epoch+1).zfill(3) + ".model\n"+modeldirectory + modelfileprefix + "_" + str(epoch+1).zfill(3) + ".png\n\n") sys.stdout.flush() self.model.save(modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.model') copyfile(notesfile,modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.notes'); N = numpy.arange(0, len(self.losses)) # Plot train loss, train acc, val loss and val acc against epochs passed plt.figure() plt.subplots_adjust(hspace=0.7) plt.subplot(2, 1, 1) # plot loss values plt.plot(N, self.losses, label = "train_loss") plt.title("Loss [Epoch {}]".format(epoch+1)) plt.xlabel('Epoch') plt.ylabel('Loss') plt.subplot(2, 1, 2) # plot accuracy values plt.plot(N, self.acc, label = "train_acc") plt.title("Accuracy % [Epoch {}]".format(epoch+1)) plt.xlabel("Epoch") plt.ylabel("Accuracy %") plt.savefig(modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.png') plt.close() # train the neural network def train_network(): sys.stdout.write("Reading midi files...\n\n") sys.stdout.flush() notes = get_notes() # get amount of pitch names n_vocab = len(set(notes)) sys.stdout.write("\nPreparing note sequences...\n") sys.stdout.flush() network_input, network_output = prepare_sequences(notes, n_vocab) sys.stdout.write("\nCreating CuDNNLSTM neural network model...\n") sys.stdout.flush() model = create_network(network_input, n_vocab) sys.stdout.write("\nTraining CuDNNLSTM neural network model...\n\n") sys.stdout.flush() train(model, network_input, network_output) # get all the notes and chords from the midi files def get_notes(): # remove existing data file if it exists if os.path.isfile(notesfile): os.remove(notesfile) notes = [] for file in glob.glob("{}/*.mid".format(mididirectory)): midi = converter.parse(file) sys.stdout.write("Parsing %s ...\n" % file) sys.stdout.flush() notes_to_parse = None try: # file has instrument parts s2 = instrument.partitionByInstrument(midi) notes_to_parse = s2.parts[0].recurse() except: # file has notes in a flat structure notes_to_parse = midi.flat.notes for element in notes_to_parse: if isinstance(element, note.Note): notes.append(str(element.pitch)) elif isinstance(element, chord.Chord): notes.append('.'.join(str(n) for n in element.normalOrder)) with open(notesfile,'wb') as filepath: pickle.dump(notes, filepath) return notes # prepare the sequences used by the neural network def prepare_sequences(notes, n_vocab): sequence_length = 100 # get all pitch names pitchnames = sorted(set(item for item in notes)) # create a dictionary to map pitches to integers note_to_int = dict((note, number) for number, note in enumerate(pitchnames)) network_input = [] network_output = [] # create input sequences and the corresponding outputs for i in range(0, len(notes) - sequence_length, 1): sequence_in = notes[i:i + sequence_length] # needs to take into account if notes in midi file are less than required 100 ( mod ? ) sequence_out = notes[i + sequence_length] # needs to take into account if notes in midi file are less than required 100 ( mod ? ) network_input.append([note_to_int[char] for char in sequence_in]) network_output.append(note_to_int[sequence_out]) n_patterns = len(network_input) # reshape the input into a format compatible with CuDNNLSTM layers network_input = numpy.reshape(network_input, (n_patterns, sequence_length, 1)) # normalize input network_input = network_input / float(n_vocab) network_output = np_utils.to_categorical(network_output) return (network_input, network_output) # create the structure of the neural network def create_network(network_input, n_vocab): ''' """ create the structure of the neural network """ model = Sequential() model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True)) model.add(Dropout(0.3)) model.add(CuDNNLSTM(512, return_sequences=True)) model.add(Dropout(0.3)) model.add(CuDNNLSTM(512)) model.add(Dense(256)) model.add(Dropout(0.3)) model.add(Dense(n_vocab)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='rmsprop',metrics=["accuracy"]) ''' model = Sequential() model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True)) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(CuDNNLSTM(256)) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(Dense(128, activation="relu")) model.add(Dropout(0.2)) model.add(BatchNormalization()) model.add(Dense(n_vocab)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"]) return model # train the neural network def train(model, network_input, network_output): # saver = CustomSaver() # history = model.fit(network_input, network_output, epochs=modelepochs, batch_size=50, callbacks=[tensorboard]) history = model.fit(network_input, network_output, epochs=modelepochs, batch_size=50, callbacks=[CustomSaver()]) # evaluate the model print("\nModel evaluation at the end of training") train_acc = model.evaluate(network_input, network_output, verbose=0) print(model.metrics_names) print(train_acc) # save trained model model.save(modeldirectory + modelfileprefix + '_' + str(modelepochs) + '.model') # delete temp notes file os.remove(notesfile) if __name__ == '__main__': train_network()
And here is the midi
lstm_music_predict.py
generation script:
lstm_music_predict.py
# based on code from https://github.com/Skuldur/Classical-Piano-Composer # to use this script pass in; # 1. path to notes file # 2. path to model # 3. path to midi output # eg python -W ignore "C:\\LSTM Composer\\lstm_music_predict.py" "C:\\LSTM Composer\\Bach.notes" "C:\\LSTM Composer\\Bach.model" "C:\\LSTM Composer\\Bach.mid" # ignore all info and warning messages import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR) import pickle import numpy import sys import keras.models from music21 import instrument, note, stream, chord from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import Activation # name of weights filename notesfile = str(sys.argv[1]) modelfile = str(sys.argv[2]) midifile = str(sys.argv[3]) # generates a piano midi file def generate(): sys.stdout.write("Loading notes data file...\n\n") sys.stdout.flush() #load the notes used to train the model with open(notesfile, 'rb') as filepath: notes = pickle.load(filepath) sys.stdout.write("Getting pitch names...\n\n") sys.stdout.flush() # Get all pitch names pitchnames = sorted(set(item for item in notes)) # Get all pitch names n_vocab = len(set(notes)) sys.stdout.write("Preparing sequences...\n\n") sys.stdout.flush() network_input, normalized_input = prepare_sequences(notes, pitchnames, n_vocab) sys.stdout.write("Loading LSTM neural network model...\n\n") sys.stdout.flush() model = create_network(normalized_input, n_vocab) sys.stdout.write("Generating note sequence...\n\n") sys.stdout.flush() prediction_output = generate_notes(model, network_input, pitchnames, n_vocab) sys.stdout.write("\nCreating MIDI file...\n\n") sys.stdout.flush() create_midi(prediction_output) # prepare the sequences used by the neural network def prepare_sequences(notes, pitchnames, n_vocab): # map between notes and integers and back note_to_int = dict((note, number) for number, note in enumerate(pitchnames)) sequence_length = 100 network_input = [] output = [] for i in range(0, len(notes) - sequence_length, 1): sequence_in = notes[i:i + sequence_length] sequence_out = notes[i + sequence_length] network_input.append([note_to_int[char] for char in sequence_in]) output.append(note_to_int[sequence_out]) n_patterns = len(network_input) # reshape the input into a format compatible with LSTM layers normalized_input = numpy.reshape(network_input, (n_patterns, sequence_length, 1)) # normalize input normalized_input = normalized_input / float(n_vocab) return (network_input, normalized_input) # create the structure of the neural network def create_network(network_input, n_vocab): model = keras.models.load_model(modelfile) return model # generate notes from the neural network based on a sequence of notes def generate_notes(model, network_input, pitchnames, n_vocab): # pick a random sequence from the input as a starting point for the prediction start = numpy.random.randint(0, len(network_input)-1) int_to_note = dict((number, note) for number, note in enumerate(pitchnames)) pattern = network_input[start] prediction_output = [] # generate 500 notes for note_index in range(500): prediction_input = numpy.reshape(pattern, (1, len(pattern), 1)) prediction_input = prediction_input / float(n_vocab) prediction = model.predict(prediction_input, verbose=0) index = numpy.argmax(prediction) result = int_to_note[index] prediction_output.append(result) pattern.append(index) pattern = pattern[1:len(pattern)] if (note_index + 1) % 50 == 0: sys.stdout.write("{} out of 500 notes generated\n".format(note_index+1)) sys.stdout.flush() return prediction_output # convert the output from the prediction to notes and create a midi file from the notes def create_midi(prediction_output): offset = 0 output_notes = [] # create note and chord objects based on the values generated by the model for pattern in prediction_output: # pattern is a chord if ('.' in pattern) or pattern.isdigit(): notes_in_chord = pattern.split('.') notes = [] for current_note in notes_in_chord: new_note = note.Note(int(current_note)) new_note.storedInstrument = instrument.Piano() notes.append(new_note) new_chord = chord.Chord(notes) new_chord.offset = offset output_notes.append(new_chord) # pattern is a note else: new_note = note.Note(pattern) new_note.offset = offset new_note.storedInstrument = instrument.Piano() output_notes.append(new_note) # increase offset each iteration so that notes do not stack offset += 0.5 midi_stream = stream.Stream(output_notes) midi_stream.write('midi', fp=midifile) if __name__ == '__main__': generate()
Model file sizes
The disadvantage of including neural networks in Visions of Chaos is the size of the files. If the generation of the model was faster, then I would just add a button so that the end user can train the models himself. But since some of the training sessions for many models can take several days, this is not particularly practical. It seemed to me that it is better to do all the training and testing yourself, and add only the best working models. It also means that the end user just needs to press a button, and trained models will create musical compositions.
Each of the models has a size of 22 megabytes. In the conditions of the modern Internet, this is not so much, but over the years of development, Visions of Chaos has been growing in size gradually, and only recently has it suddenly increased from 70 to 91 MB (due to the cellular automaton search model). Therefore, I have so far added only one model to the main Visions of Chaos installer. For users who want more, I posted a link to another 1 GB of models. They can also use the script above to create their own models based on their midi files.
What's next?
At this stage, the LSTM composer is the simplest example of using neural networks to compose music.
I have already found other music composers on neural networks that I will experiment with in the future, so you can expect that in Visions of Chaos there will be new possibilities for automatically composing music.
All Articles