We create a dataset for recognition of counters on Yandex.Tolok

Two years ago, by accidentally turning on the TV, I saw an interesting story in the Vesti program. It was told that the Moscow Department of Information Technology is creating a neural network that will read the readings of water meters from photographs. In the story, the TV presenter asked the townspeople to help the project and send pictures of their meters to the mos.ru portal in order to train a neural network on them.
If you are a department in Moscow, then releasing a video on the federal channel and asking people to send images of meters is not a very big problem. But what if you are a small startup and you can’t advertise on the TV channel? How to get 50,000 images of counters in this case? Yandex.Toloka comes to the rescue!
Yandex.Toloka is a crowdsourcing platform on which people from all over the world perform simple tasks, receiving money for this. For example, tolokers can find pedestrians in the image, train voice assistants, and more . At the same time, not only Yandex employees, but anyone who wishes can post tasks on Toloka.
Formulation of the problem
So, we want to create a neural network that will determine the readings of counters from a photograph. Where to start, what data do we need?
After consulting with colleagues, we conclude that in order to create MVP we need 1000 counter images. Moreover, for each counter we want to know the current readings, as well as the coordinates of the window with numbers. 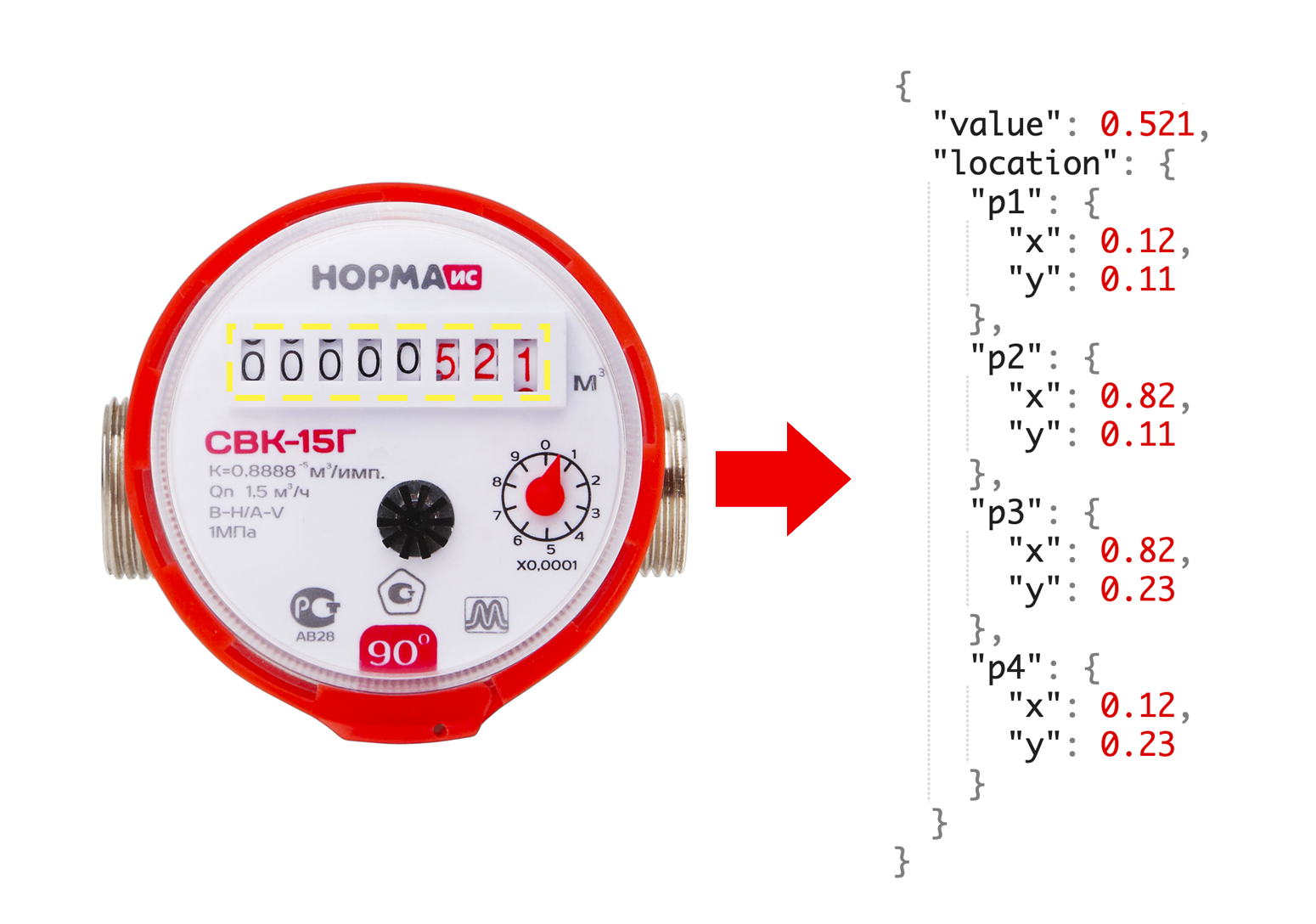
If you have never worked with Toloka, I advise you to read the article that I wrote a year ago. Since the current article will be technically more complex, I will omit some points described in detail in the previous article.
The previous article became TOP-2 in the ranking of articles from the ODS community. Thank you for commenting and putting the pros!)
Part 1. Image acquisition
What could be easier? You just need to ask the person to open the Yandex.Tolok application on their phone and take a picture of their counter. If I hadn’t worked with Toloka for several years, my instruction would have been: “You need to take a picture of your water meter (hot or cold) and send us an image . ”
Unfortunately, with such a statement of the problem, a good dataset cannot be assembled. The thing is that people can interpret this TK in different ways, since the instructions do not have clear criteria for a correctly completed task. Tolockers can send:
- blurry images;
- Images that do not show evidence
- images with multiple counters.
The Toloka blog has a great tutorial on how to write instructions. Following him, I got this instruction: 
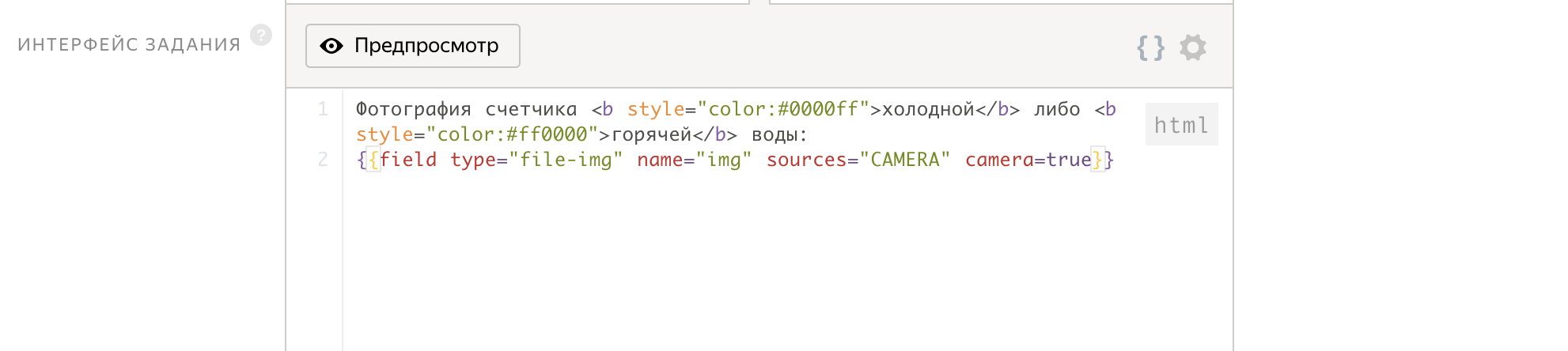
As input parameters, we pass the id of the task, and at the output we get the img file, which will contain the image of the counter.

The job interface is written in just 2 lines!
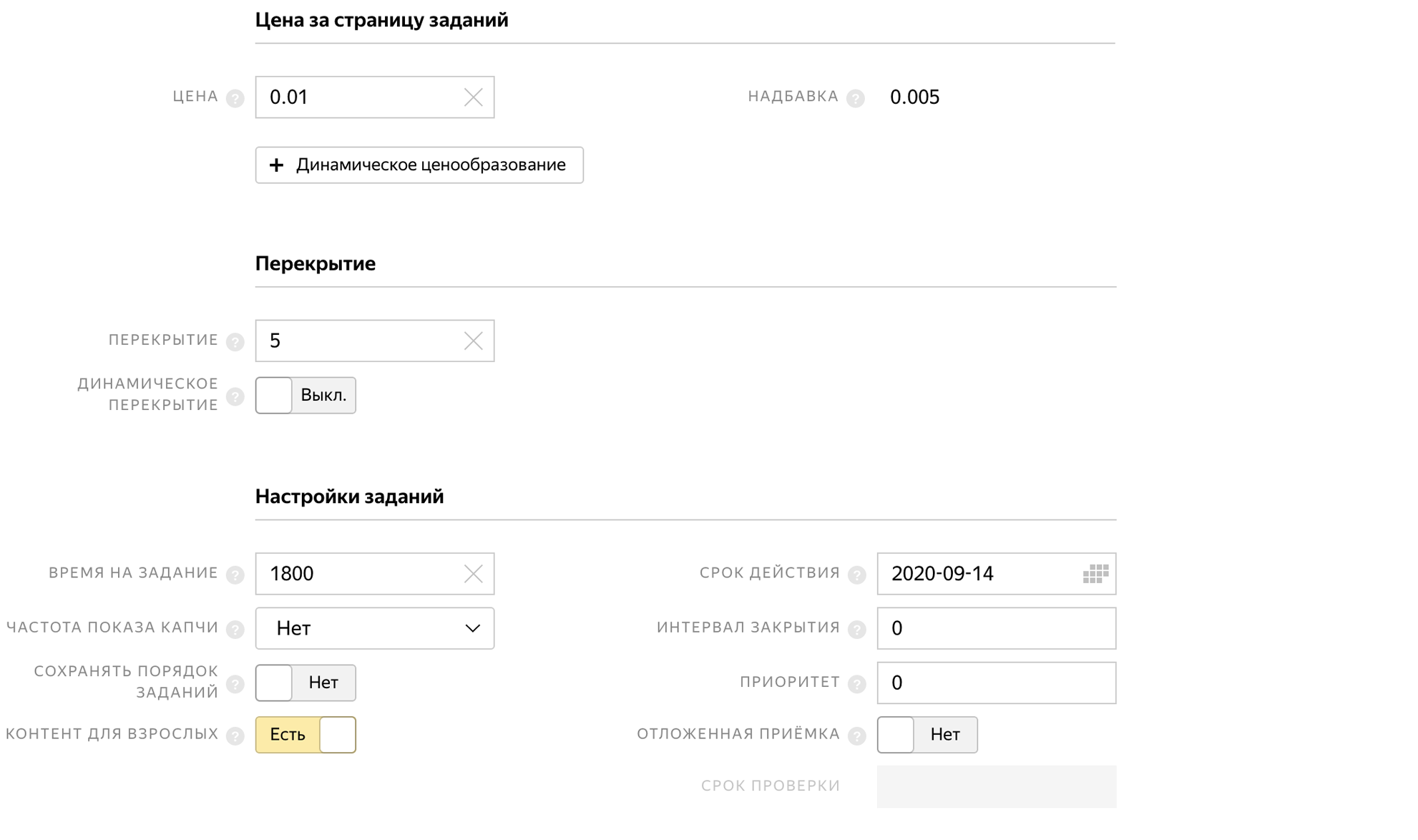
When creating a pool, we indicate the time to complete the task, the delayed acceptance and the price for the task 0.01 $.
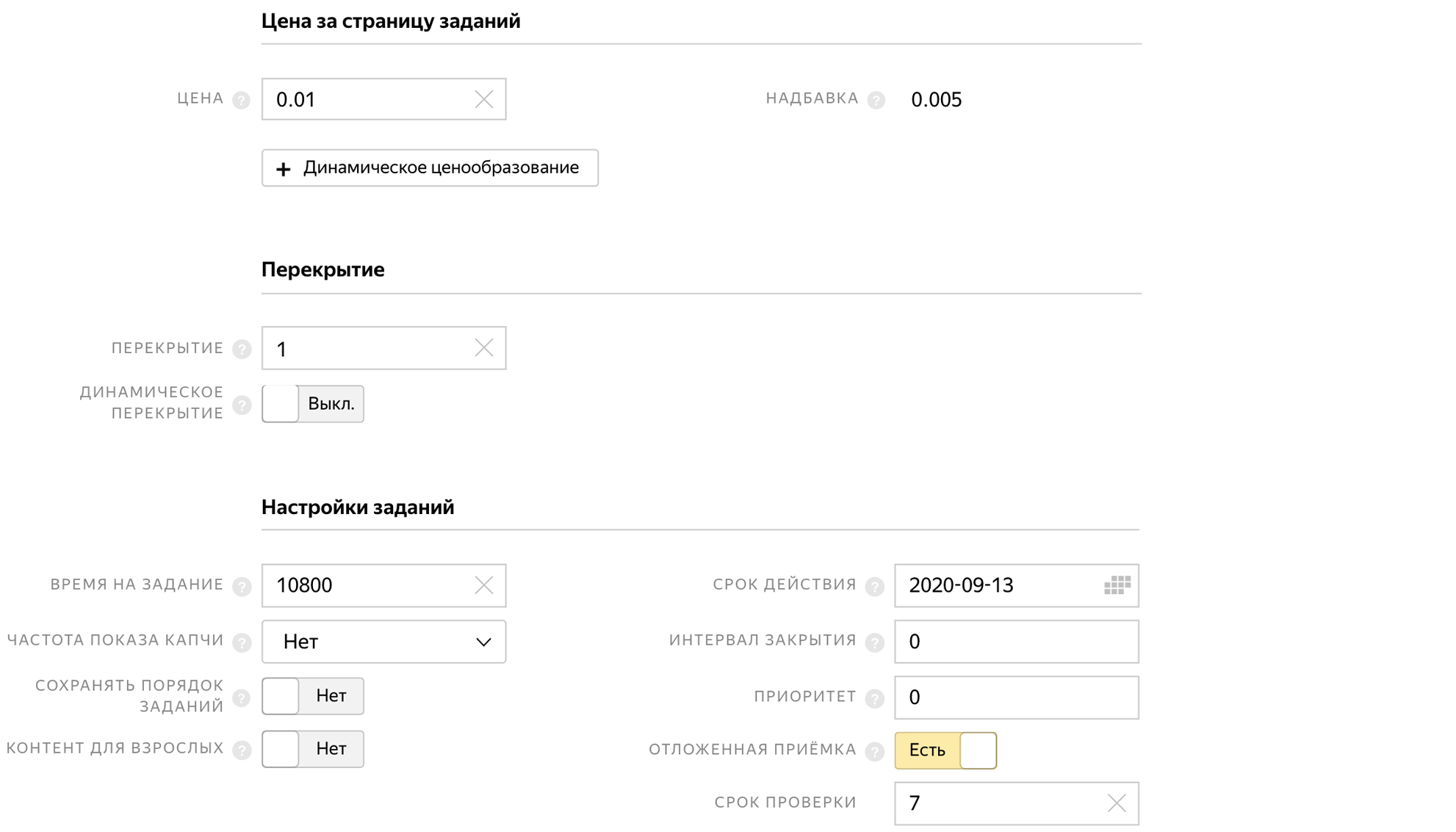
And so that people do not complete the task several times and do not send the same photos, we prohibit the repeated execution of the task in the quality control block.
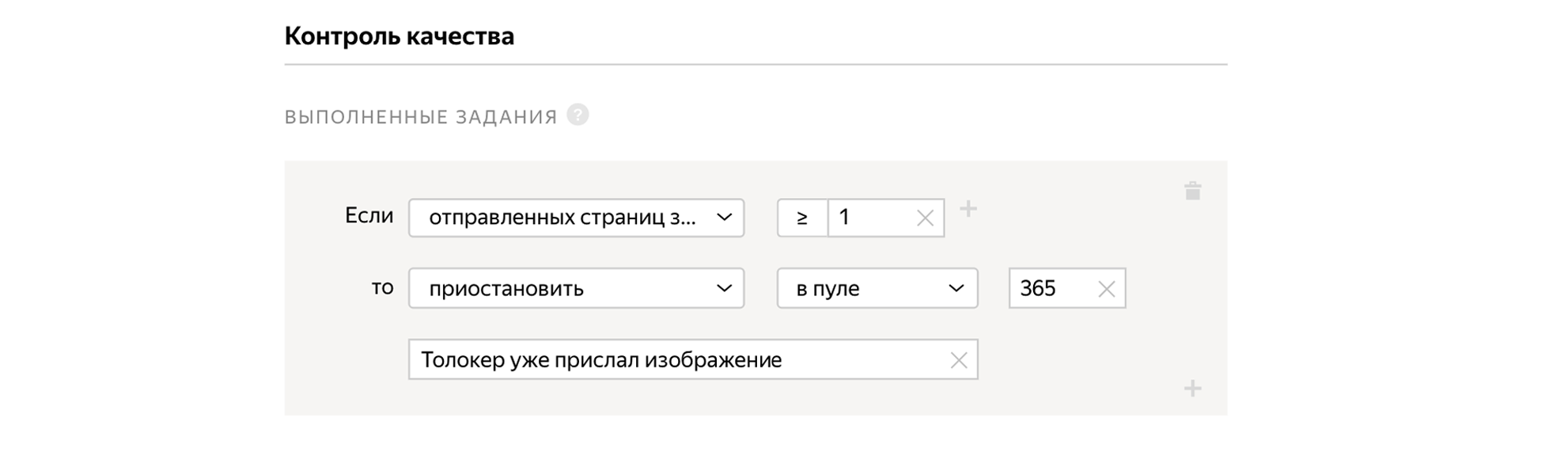
We indicate that we need Russian-speaking users who complete the task through the Yandex.Tolok mobile application.
Downloading tasks to the pool.
We start the pool, rejoice and wait for user responses! This is how our task looks from the side of the toloker:
Part 2. Acceptance of tasks
After waiting a couple of hours, we see that the tolkers completed the task. Since with delayed acceptance, the award is not paid to the contractor immediately, but is frozen on the customer’s balance sheet, now we must check all the images sent. For bona fide performers to accept tasks, and for performers who sent unsuitable images for the criteria, refuse and write the reason for the refusal.
If there weren’t a lot of images, then we could view and check all the images sent ourselves. But we want to get thousands and tens of thousands of images! Checking this volume of tasks will require a significant amount of time. Plus, this process requires our participation directly.
Toloka comes to the rescue again! We can create a new task "Checking counter images" and ask other tolkers to answer whether the image fits our criteria or not. By setting up the process once, we get fully automatic data collection and validation! At the same time, the data collection is easily scalable, and if we need to increase the size of the dataset several times, just press a couple of buttons.
Sounds amazing and grand, doesn't it?
Then it's time to put the idea into practice!
First of all, we will define the criteria by which we will consider the photo to be good.
A photo is good if:
- In the photo there is exactly one counter of cold or hot water;
- Readings on the counter are clearly visible.
In other cases, the photo is considered bad.
We sorted out the criteria, now we are writing an instruction! 
As input parameters we pass the link to the image. The output will be two flags:
- check_count - answer to the first question
- check_quality - answer to the second question
The counter will be written to the value variable.
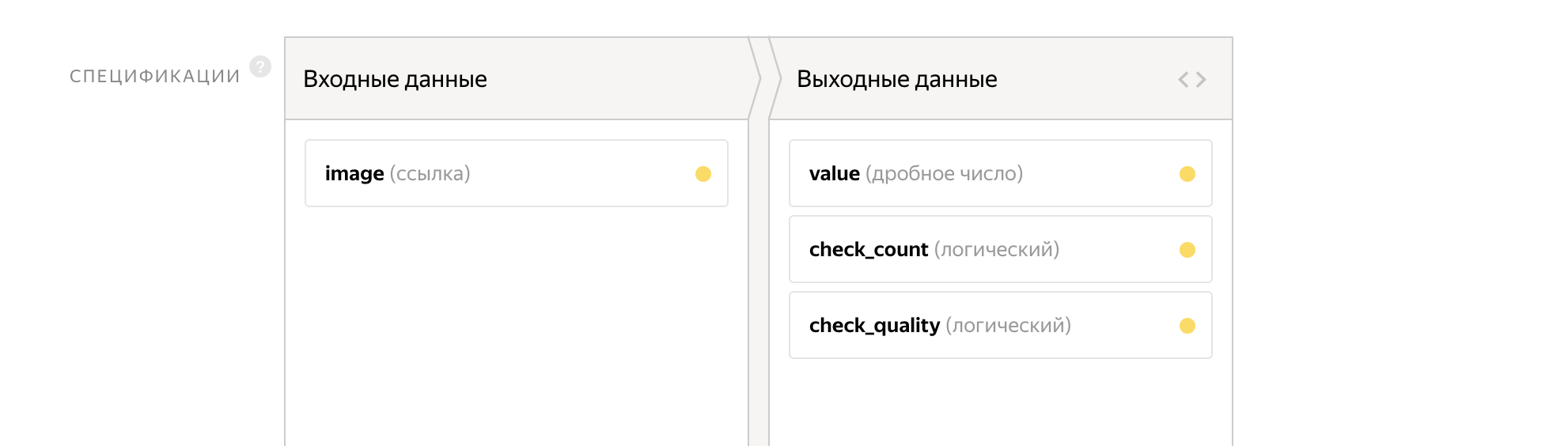
The interface of this task already takes 14 lines.
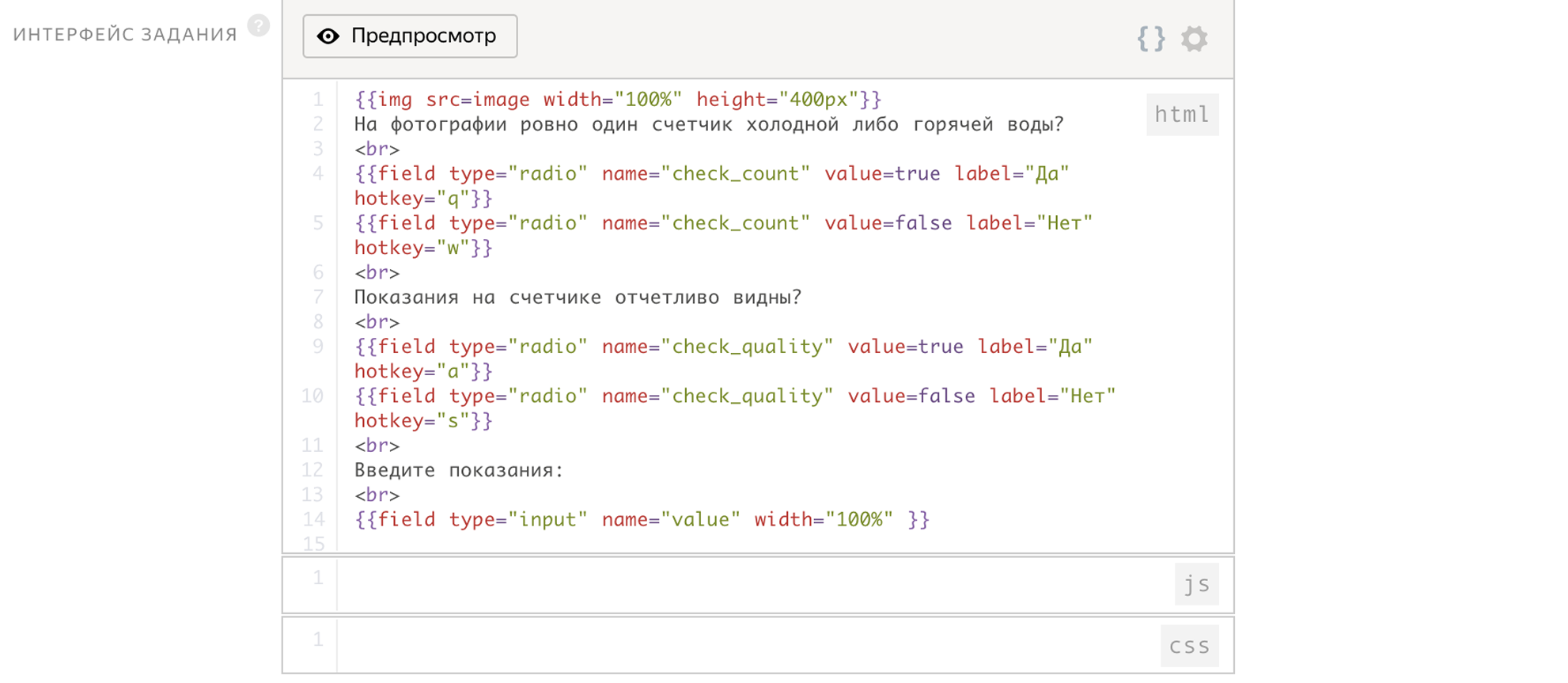
To increase accuracy, one image will be checked independently by 5 tokers, for this we will put an overlap of 5. After that, we will look at how 5 people answered and assume that the correct answer is the one for which the majority voted. This task will no longer have delayed acceptance.
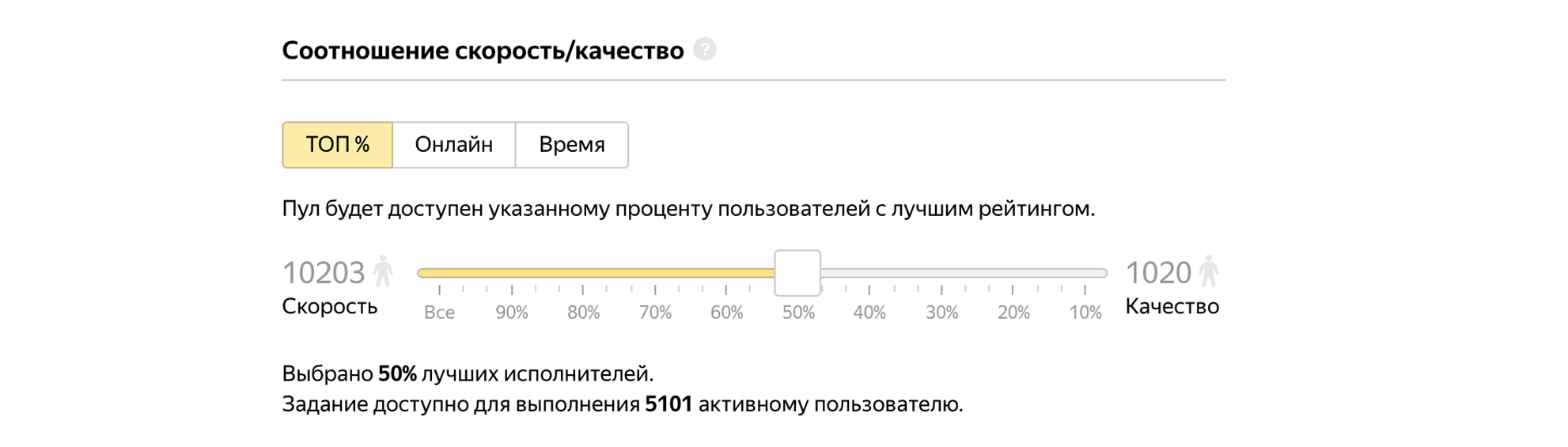
Let's admit 50% of the best performers to the task.
In tasks without delayed acceptance, everyone receives payment, regardless of whether they perform the task correctly or not. But we want the tolokers to carefully read the instructions, try and complete the task correctly. How can this be achieved?
In Tolok there are two main tools that allow you to maintain good quality:
- Training. Before completing the main task, we can ask the trainers to get trained. In the training pool, people are given tasks for which we know the correct answers in advance. If a person answered incorrectly, an error is shown to him and he is explained how to answer. After completing the training, we see what percentage of tasks the performer completed and we can only allow those who did well to the main pool of tasks.
- Quality control blocks. It may be that the training pool was excellent for the performer, we were allowed to do it, but five minutes later he left to play football, leaving his three-year-old brother at the computer. Fortunately, there are many methods in Tolok that allow you to keep track of how people complete tasks.
With the training pool, everything is simple: just add tasks, mark them in the Yandex.Tolki interface and specify the threshold for passing, starting from which we allow people to the main task.
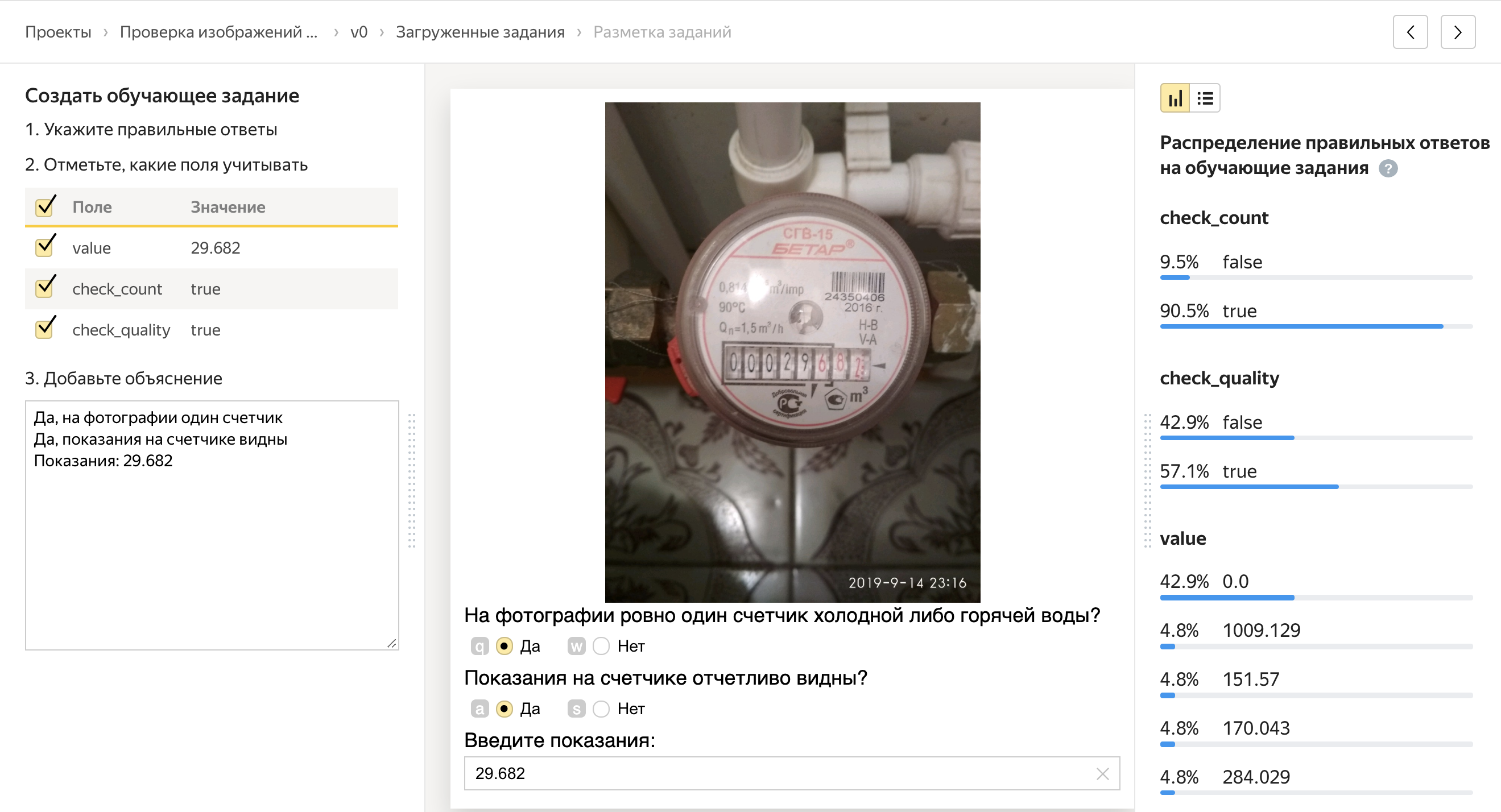
With quality control units, everything is more interesting: there are quite a lot of them, but I will focus on the two most important ones.
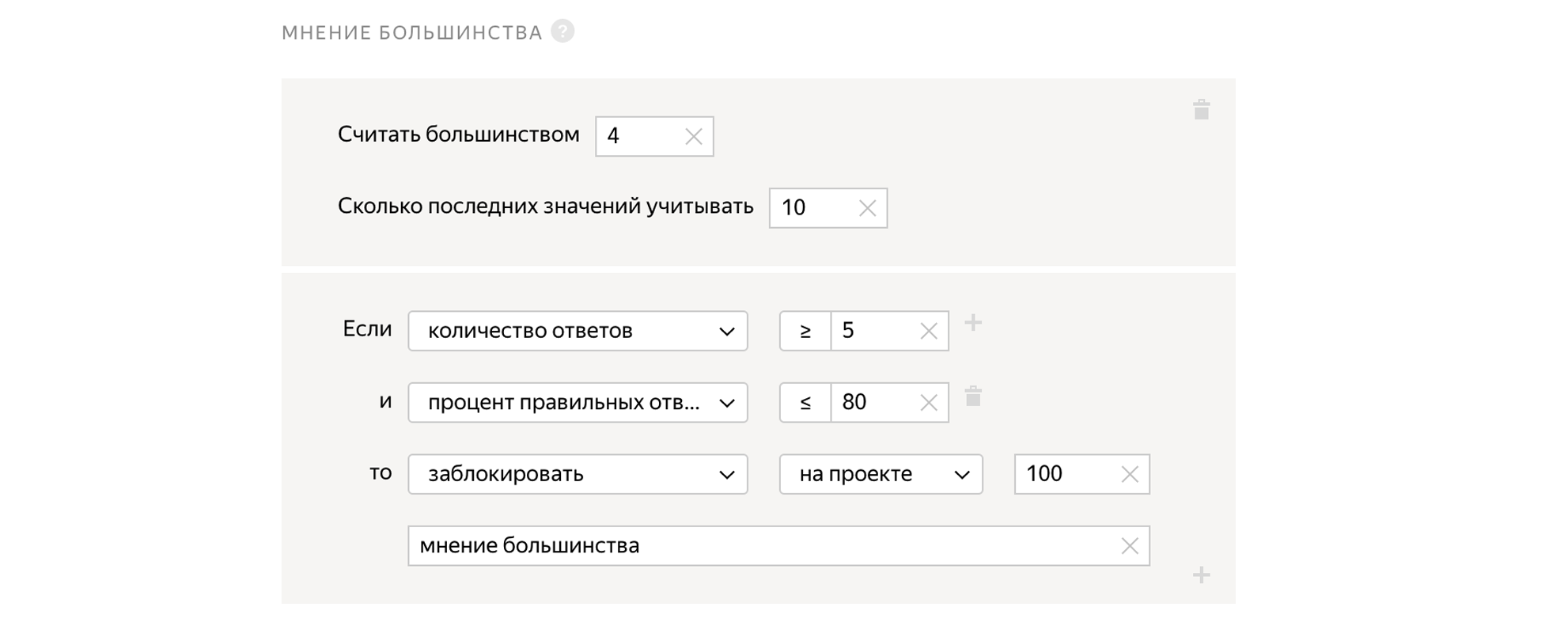
Majority opinion
We give the task to 5 independent people. And if four people answer “Yes” to the question, and the fifth answers “No,” then the fifth probably made a mistake. Thus, we can watch how the person’s answers are consistent with the answers of other people, and block users who respond differently from the others.
Control tasks
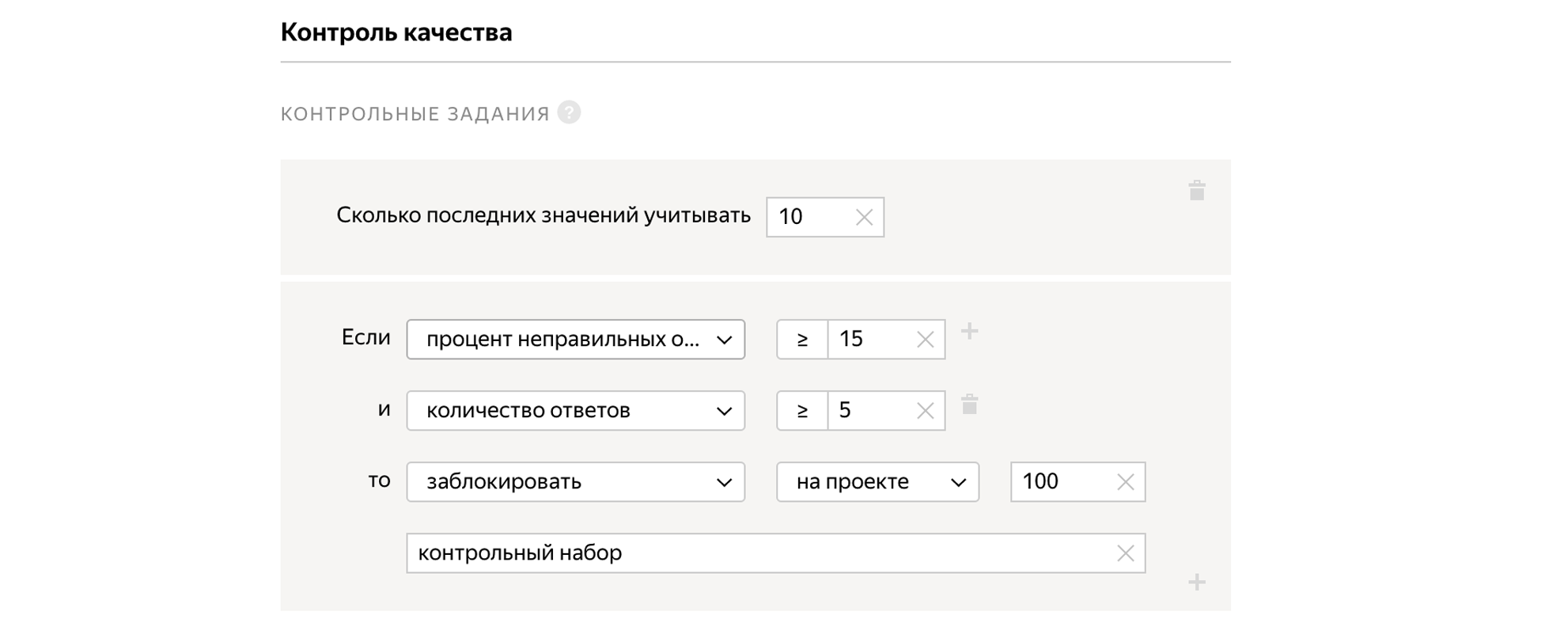
We can mix tasks into the pool, for which we know the correct answer in advance. At the same time, quality control tasks look the same as regular tasks. On the basis of whether a person answers the control tasks correctly, we can extrapolate and assume, correctly or not, that he solves all other tasks for which we do not know the answers. If a person responds poorly to control tasks, we can block him, and if it’s good, then give out a bonus.
Hooray, task created! This is how the interface looks from the side of the executor:
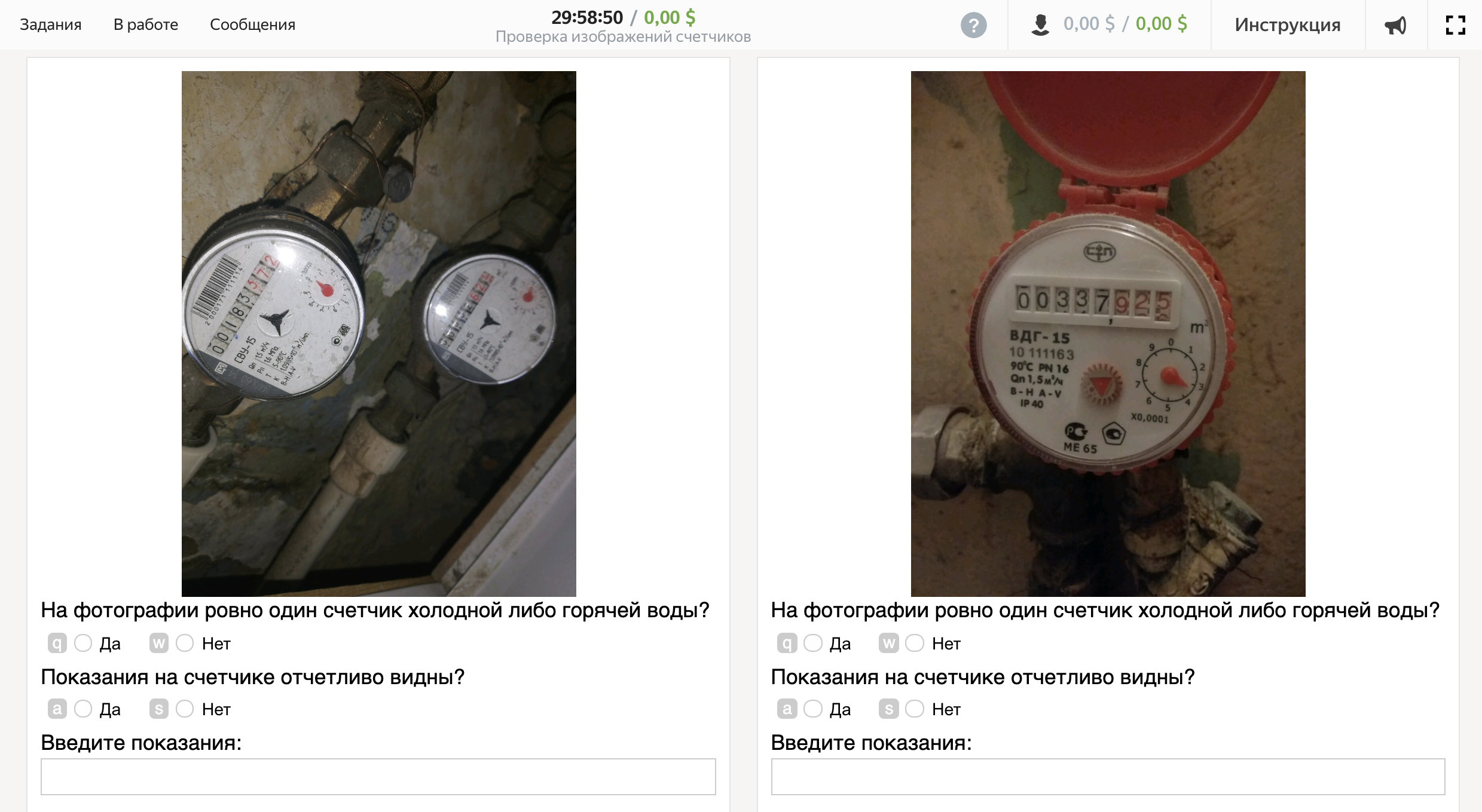
Part 3. Joining Jobs
Great, tasks are ready! But the question arises, how to connect tasks with each other? How to make the second run after the first task?
Of course, you can play with a tambourine and do it manually through the Toloka interface, but there is a simpler and faster way! Yandex.Tolok has an API , use it and write a python script!
import pandas as pd import numpy as np import requests import boto3 # , # Yandex Object Storage def load_image_on_yandex_storage(img_id): session = boto3.session.Session( region_name="us-east-1", aws_secret_access_key="", aws_access_key_id="" ) s3 = session.client( service_name="s3", endpoint_url="https://storage.yandexcloud.net" ) file = requests.get( url=URL_API + "attachments/%s/download" % img_id, headers=HEADERS ) s3.put_object(Bucket="schetchiki", Key=img_id, Body=file.content) return "https://storage.yandexcloud.net/schetchiki/%s" % img_id # API, ID TOLOKA_OAUTH_TOKEN = "" POOL_ID_FIRST = 7156932 POOL_ID_SECOND = 7006945 URL_API = "https://toloka.yandex.ru/api/v1/" HEADERS = { "Authorization": "OAuth %s" % TOLOKA_OAUTH_TOKEN, "Content-Type": "application/JSON", } # , url_assignments = ( URL_API + "assignments/?status=SUBMITTED&limit=10000&pool_id=%s" % POOL_ID_FIRST ) submitted_tasks = requests.get(url_assignments, headers=HEADERS).json()["items"] # , , id # id url_to_first_id_map = {} first_id_to_second_id_map = {} json_second_task = [] # : # * id # * Yandex Object Storage # * json for task in submitted_tasks: first_task_id = task["id"] img_id = task["solutions"][0]["output_values"]["img"] url_img = load_image_on_yandex_storage(img_id) url_to_first_id_map[url_img] = first_task_id json_second_task.append( {"input_values": {"image": url_img}, "pool_id": POOL_ID_SECOND, "overlap": 5} ) # # " , ": API , # API second_tasks_request = requests.post( url=URL_API + "tasks?open_pool=true", headers=HEADERS, json=json_second_task ).json() # id . # , for second_task in second_tasks_request["items"].values(): second_task_id = second_task["id"] img_url = second_task["input_values"]["image"] first_task_id = url_to_first_id_map[img_url] first_id_to_second_id_map[first_task_id] = second_task_id # , , # def unknown_fun(k): return list(map(lambda t: t['solutions'][np.where(np.array(list(map(lambda x: x['id'], t['tasks']))) == second_task_id)[0][0]]['output_values'][k], second_task)) # keys values first_id_to_url_map = dict((v, k) for k, v in url_to_first_id_map.items()) db = [] # , 2 for first_task_id in first_id_to_second_id_map: # 1 second_task_id = first_id_to_second_id_map[first_task_id] # 2 url_assignments = ( URL_API + "assignments/?status=ACCEPTED&task_id=%s" % second_task_id ) second_task = requests.get(url_assignments, headers=HEADERS).json()["items"] # value_list = unknown_fun("value") check_count_list = unknown_fun("check_count") check_quality_list = unknown_fun("check_quality") # «», # , # . if np.sum(check_count_list) < 3: json_check = { "status": "REJECTED", "public_comment": " ", } # , , elif np.sum(check_quality_list) < 3: json_check = { "status": "REJECTED", "public_comment": " ", } # else: json_check = { "status": "ACCEPTED", "public_comment": " ", } url = URL_API + "assignments/%s" % first_task_id result_patch_request = requests.patch(url, headers=HEADERS, json=json_check) # (values, counts) = np.unique(value_list, return_counts=True) ind = np.argmax(counts) if counts[ind] > 3 and json_check["status"] == "ACCEPTED": print( " : %s. %d 5 " % (values[ind], counts[ind]) ) # , db.append( { "first_task_id": first_task_id, "second_task_id": second_task_id, "url_img": first_id_to_url_map[first_task_id], "check_count_list": check_count_list, "check_quality_list": check_quality_list, "value_list": value_list, } ) # pd.DataFrame(db).to_csv("result.csv")
We run the code and here is the long-awaited result: a dataset of 871 counter images is ready.

Price
Let's evaluate the economic component of the project.
For the sent image in the first task, we offer $ 0.01.
Unfortunately, if we pay the performer $ 0.01, we will have to pay $ 0.018.
How is this done?
- Yandex commission is min (0.005.20%). For a task with a price of 0.01 $, the commission will be 50%;
- VAT is 20%.
For checking 10 images of counters, we pay $ 0.01. In this case, one image is checked 5 times by independent people. Total, for the verification of one image, we give: (0.01 x 5/10) x 1.2 x 1.5 = $ 0.009.
Of the 1000 submissions, 871 images were accepted, and 129 were rejected. So, to get a dataset of 871 images, we paid:
0.018 $ x 871 + 0.009 $ x 1000 = $ 25 and you need 92,000 rubles to get a dataset of 50,000 images. This is definitely cheaper than ordering ads on the federal channel!
But this figure can actually be reduced several times. Can:
- Suggest in the first task to take not one photo, but several. At the same time raise the price, then the Yandex commission will not be 50%, but 20%;
- Use dynamic overlap in the second task. If 4 out of 5 people gave the same answer, then it makes no sense to give the task to the fifth person;
- Work with Toloka as a foreign legal entity. In this case, you do not pay VAT.
Since there was so much material, I decided to split the article into two parts. Next time we’ll talk with you about how to select objects on images using the Toloka and create datasets for tasks in Computer Vision. And in order not to miss, subscribe and like!
PS
After reading the article, it may seem to you that this is a hidden advertisement of Yandex.Tolki, but no, it is not. Yandex did not pay me anything, and most likely will not pay. I just wanted to show on a fictional, but relevant and interesting example, how using this service you can quickly and inexpensively assemble a dataset for any task, be it the task of recognizing cats or training unmanned vehicles.
All Articles