Development in a monorepository. Yandex Report
My name is Azat Razetdinov, I’ve been in Yandex for 12 years, I manage the interface development service in Y. Real Estate. Today I would like to talk about a monorepository. If you have only one repository at work - congratulations, you already live in a single repository. Now about why others need it.
- We at Yandex tried different ways of working with several services and noticed - as soon as you have more than one service, inevitably common parts begin to appear: models, utilities, tools, pieces of code, templates, components. The question is: where to put all this? Of course, you can copy-paste, we can do it, but I want it beautifully.
We even tried an entity like SVN externals for those who remember. We tried git submodules. We tried npm packages when they appeared. But all this was somehow long, or something. You support any package, find an error, make corrections. Then you need to release a new version, go through the services, upgrade to this version, check that everything works, run the tests, find the error, go back to the repository with the library, fix the error, release the new version, go through the services, update and so on circle. It just turned into pain.

Then we thought about whether we should come together in one repository. Take all our services and libraries, transfer and develop in one repository. There were a lot of advantages. I’m not saying that this approach is ideal, but from the point of view of the company and even the department of several groups, significant advantages appear.
For me personally, the most important thing is the atomicity of commits, that as a developer, I can fix the library with one commit, bypass all services, make changes, run tests, verify that everything works, push it into the master, and all this with one change. No need to reassemble, publish, update anything.
But if everything is so good, why haven't everyone moved to the mono-repository yet? Of course, there are also disadvantages in it.

As Marina Pereskokova, the head of Yandex.Mart API development service, said, grandfather planted a monorepa, a monorepa has grown big, big. This is a fact, not a joke. If you collect many services in one single repository, it inevitably grows. And if we are talking about git, which pulls out all the files plus their entire history for the entire existence of your code, this is a rather large disk space.
The second problem is the injection into the master. You prepared a pool request, went through a review, you are ready to merge it. And it turns out that someone managed to get ahead of you and you need to resolve conflicts. You resolved the conflicts, again ready to pour in, and again you did not have time. This problem is being solved, there are merge queue systems, when a special robot automates this work, lays out pool requests in a queue, and tries to resolve conflicts if it can. If he can’t, he calls the author. However, such a problem exists. There are solutions that level it, but you need to keep it in mind.
These are technical points, but there are also organizational ones. Suppose you have several teams that make several different services. When they move to a single repository, their responsibility begins to erode. Because they made a release, rolled out in production - something broke. We begin the debriefing. It turns out that it is a developer from another team that has committed something to the common code, we pulled it, unreleased it, did not see it, everything broke. And it is not clear who is responsible. It is important to understand and use all possible methods: unit tests, integration tests, linter - everything that is possible to reduce this problem of the influence of one code on all other services.
Interestingly, who else besides Yandex and other players uses the mono-repository? Quite a lot of people. These are React, Jest, Babel, Ember, Meteor, Angular. People understand - it’s easier, cheaper, faster to develop and publish npm packages from a mono-repository than from several small repositories. The most interesting thing is that along with this process, tools for working with a monorepository began to develop. Just about them and I want to talk.
It all starts with creating a monorepository. The world's most famous front-end tool for this is called lerna.

Just open your repository, run npx lerna init, it will ask you some suggestive questions and add a few entities to your working copy. The first entity is the lerna.json config, which indicates at least two fields: the end-to-end version of all your packages and the location of your packages in the file system. By default, all packages are added to the packages folder, but you can configure this as you like, you can even add them to the root, lerna can pick it up too.
The next step is how to add your repositories to the mono repository, how to transfer them?
What do we want to achieve? Most likely, you already have some kind of repository, in this case A and B.

These are two services, each in its own repository, and we want to transfer them to the new mono-repository in the packages folder, preferably with a history of commits, so that you can make git blame, git log, and so on.

There is a lerna import tool for this. You simply specify the location of your repository, and lerna transfers it to your monorepo. At the same time, she, firstly, takes a list of all the commits, modifies each commit, changing the path to the files from the root to packages / package_name, and applies them one after another, imposes them in your mono-repository. In fact, each commit prepares, changing the file paths in it. Essentially, lerna does git magic for you. If you read the source code, there simply git commands are executed in a certain sequence.
This is the first way. It has a drawback: if you work in a company where there are production processes, where people are already writing some kind of code, and you are going to translate them into a monorep, you are unlikely to do it in one day. You will need to figure out, configure, verify that everything starts, tests. But people do not have work, they continue to do something.

For a smoother transition to mono-rap, there is such a tool as git subtree. This is a trickier thing, but at the same time native to git, which allows you to not only import individual repositories into a mono-repository by some kind of prefix, but also exchange changes back and forth. That is, the team that makes the service can be easily developed further in its own repository, while you can pull their changes through git subtree pull, make your own changes and push them back through git subtree push. And live like this in the transition period for as long as you like.
And when you’ve set everything up, checked that all tests are running, the deployment is working, the entire CI / CD is configured, you can say that it’s time to move on. For the transition period, a great solution, I recommend.
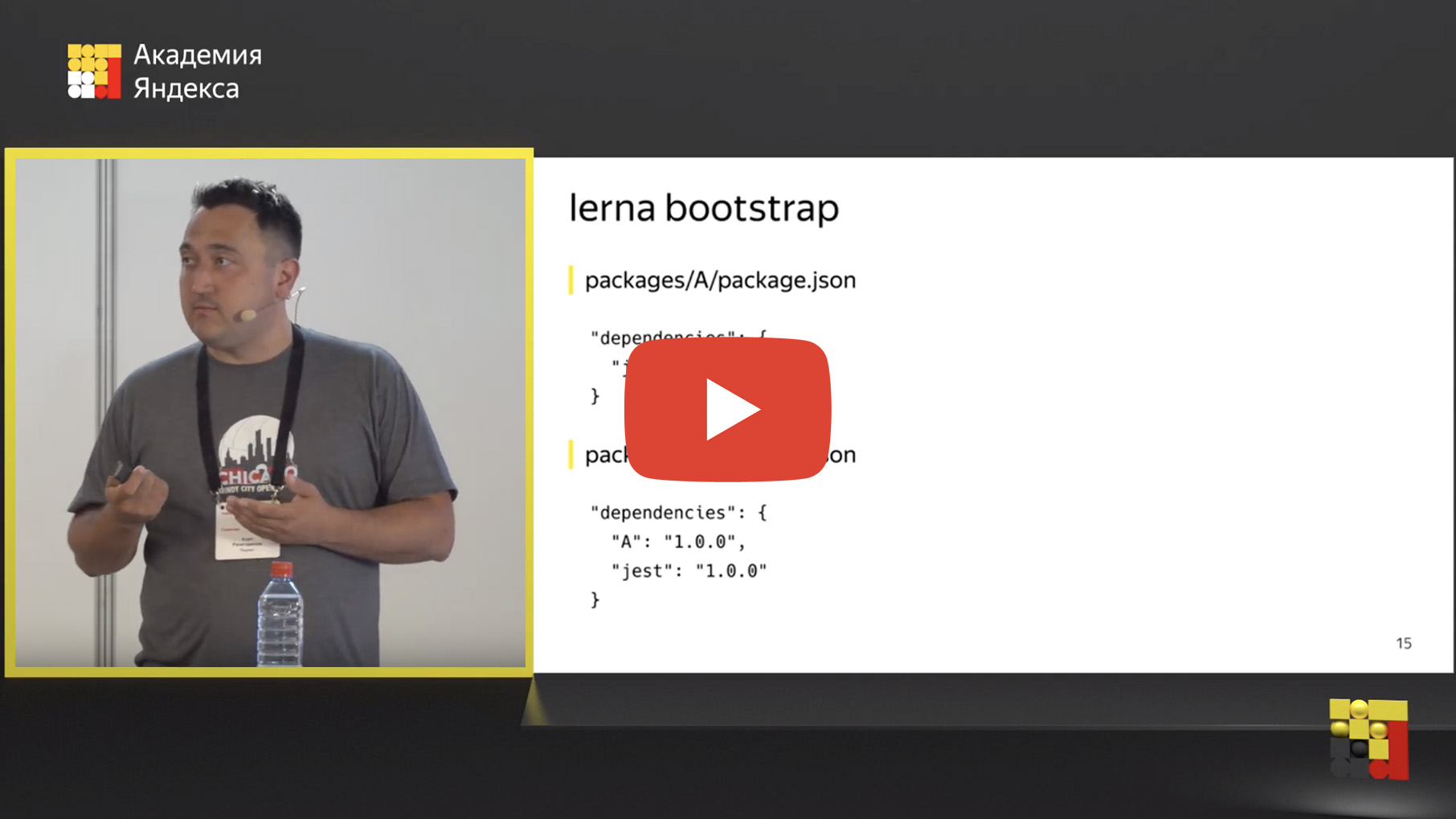
Well, we moved our repositories into one mono-repository, but where is the magic somewhere? But we want to highlight the common parts and somehow use them. And for this there is a “dependency binding” mechanism. What is dependency binding? There is a lerna bootstrap tool, this is a command that is similar to npm install, it just runs npm install in all of your packages.

But that's not all. In addition, she is looking for internal dependencies. You can use another in one package inside your repository. For example, if you have package A, which depends on Jest in this case, there is package B, which depends on Jest and package A. If package A is a common tool, a common component, then package B is a service that has it uses.
Lerna defines such internal dependencies and physically replaces this dependency with a symbolic link on the file system.


After you run lerna bootstrap, right inside the node_modules folder, instead of the physical folder A, a symbolic link appears that leads to the folder with package A. This is very convenient because you can edit the code inside package A and immediately check the result in package B , run tests, integration, units, whatever you want. Development is greatly simplified, you no longer need to rebuild package A, publish, connect package B. They just fixed it here, checked it.
Please note, if you look at the node_modules folders, and there, and there is jest, we have duplicated the installed module. In general, it is quite a long time when you start lerna bootstrap, wait until everything stops, due to the fact that there is a lot of any kind of repeated work, duplicate dependencies are obtained in each package.
To speed up the installation of dependencies, the mechanism for raising dependencies is used. The idea is very simple: you can take the general dependencies to the root node_modules.

If you specify the --hoist option (this is an upgrade from English), then almost all the dependencies will simply move to the root node_modules. And it works almost always. Noda is so arranged that if she has not found the dependencies at her level, she begins to search a level higher, if not there, another level higher and so on. Almost nothing changes. But in fact, we took and deduplicated our dependencies, transferred the dependencies to the root.
At the same time, lerna is smart enough. If there is any conflict, for example, if package A used Jest version 1, and package B used version 2, then one of them would pop up, and the second would remain at its level. This is approximately what npm is actually doing inside the normal node_modules folder, it also tries to deduplicate dependencies and to the maximum carry them to the root.
Unfortunately, this magic does not always work, especially with tools, with Babel, with Jest. It often happens that he starts, because Jest has its own system for resolving modules, Noda starts to lag, throw an error. Especially for such cases when the tool does not cope with the dependencies that have gone to the root, there is the nohoist option, which allows you to point out that these packages do not transfer to the root, leave them in place.

If you specify --nohoist = jest, then all the dependencies except jest will go to the root, and jest will remain at the packet level. Not for nothing I gave such an example - it is jest that has problems with this behavior, and nohoist helps with this.
Another plus of dependency recovery:

If before that you had separate package-lock.json for each service, for each package, then when you are hoyed, everything moves up, and the only package-lock.json remains. This is convenient from the point of view of pouring into the master, resolving conflicts. Once everyone was killed, and that’s it.
But how does lerna achieve this? She is quite aggressive with npm. When you specify hoist, it takes your package.json in the root, backs it up, substitutes another for it, aggregates all your dependencies into it, runs npm install, almost everything is put in the root. Then this temporary package.json removes, restores yours. If after that you run any command with npm, for example, npm remove, npm will not understand what happened, why all of the dependencies suddenly appeared at the root. Lerna violates the level of abstraction, she crawls into the tool, which is below her level.
The guys from Yarn were the first to notice this problem and said: what are we tormenting, let us do everything for you natively, so that everything out of the box works.

Yarn can already do the same thing out of the box: tie dependencies, if he sees that package B depends on package A, he will make a symlink for you, for free. He knows how to raise dependencies, does it by default, everything adds up to the root. Like lerna, it can leave the only yarn.lock in the root of the repository. Everyone else yarn.lock you no longer need.

It is configured in a similar way. Unfortunately, yarn assumes that all the settings are added to package.json, I know there are people who try to take away all the settings of the tools from there, leaving only a minimum. Unfortunately, yarn has not yet learned to specify this in another file, only package.json. There are two new options, one new and one mandatory. Since it is assumed that the root repository will never publish, yarn requires private = true to be specified there.
But the settings for workspaces are stored in the same key. The setting is very similar to the lerna settings, there is a packages field where you specify the location of your packages, and there is a nohoist option, very similar to the nohoist option in lerna. Just specify these settings and get the same structure as in lerna. All common dependencies went to the root, and those specified in the nohoist key remained at their level.

The best part is that lerna can work with yarn and pick up its settings. It is enough to specify two fields in lerna.json, lerna will immediately understand that you are using yarn, go into package.json, get all the settings from there and work with them. These two tools already know about each other and work together.

Why hasn’t support been made in npm so far if so many large companies use the mono-repository?

They say that everything will be, but in the seventh version. Basic support in the seventh, extended - in the eighth. This post was released a month ago, but at the same time, the date when the seventh npm will be released is still unknown. We are waiting for him to finally catch up with yarn.
When you have several services in one single repository, the question inevitably arises of how to manage them so as not to go to each folder, not run commands? There are massive operations for this.


Yarn has a yarn workspace command, followed by the name of the package and the name of the command. Since yarn from the box, unlike npm, can do all three things: run its own commands, add a dependency on jest, run scripts from package.json, like test, and also can run executable files from the node_modules / .bin folder. He will teach for you with the help of heuristics to understand what you want. It is very convenient to use yarn workspace for point operations on one package.
There is a similar command that allows you to execute a command on all packages that you have.

Indicate simply your commands with all arguments.

From the pros, it’s very convenient to run different teams. Of the minuses, for example, it is impossible to run shell commands. Suppose I want to delete all the node modules folders, I cannot run yarn workspaces run rm.
It is not possible to specify a list of packages, for example, I want to remove the dependency in only two packages, only one at a time or separately.
Well, he crashes at the very first mistake. If I want to remove the dependency from all packages - and in fact, only two of them have it, but I don’t want to think where it is, but I just want to remove it — then yarn will not allow it, it will fall at the first situation where this package is not in the dependencies. This is not very convenient, sometimes you want to ignore errors, run through all the packages.

Lerna has a much more interesting toolkit, there are two separate run and exec commands. Run can execute scripts from package.json, while unlike yarn, it can filter everything by package, you can specify --scope, you can use asterisks, globs, everything is quite universal. You can run these operations in parallel, you can ignore errors through the --no-bail switch.

Exec is very similar. Unlike yarn, it allows not only to run executable files from node_modules.bin, but to execute any arbitrary shell commands. For example, you can remove node_modules or run some make, whatever you want. And the same option is supported.

Very convenient tools, some pluses. This is the case when lerna tears yarn, is at the right level of abstraction. This is exactly what lerna needs: simplify work with several packages in monorep.
With monoreps there is one more minus. When you have a CI / CD, you can’t optimize it. The more services you have, the longer it all takes. Suppose you start testing all the services for each pool request, and the more there are, the longer the work takes. Selective operations can be used to optimize this process. I will name three different ways. The first two of them can be used not only in monorep, but also in your projects, if for some reason you do not use these methods.
The first is lint-stages, which allows you to run linter, tests, everything you want, only to files that have changed or will be commited in this commit. Run the entire lint not on your entire project, but only on the files that have changed.


The setup is very simple. Put lint-staged, husky, pre-commit-hooks and say that when changing any js-file you need to run eslint. Thus, precommit verification is greatly accelerated. Especially if you have many services, a very large mono-repository. Then running eslint on all files is too expensive, and you can optimize precommit-hooks on lint in this way.

If you write tests on Jest, it also has tools for selectively running tests.

This option allows you to give it a list of source files and find all the tests that one way or another affect these files. What can be used in conjunction with lint-staged? Please note, here I am not specifying all the js files, but only the source. We exclude the js-files themselves with tests inside, we look only at the source. We start findRelatedTests and greatly accelerate the unit run to precommit or prepush, as you wish.
And the third way is associated with monorepositories. This is lerna, which can determine which packages have changed in comparison with the base commit. Here it’s more likely not about hooks, but about your CI / CD: Travis or another service that you use.


The run and exec commands have the since option, which allows you to run any command only in those packages that have changed since some kind of commit. In simple cases, you can specify a wizard if you pour everything into it. If you want more accurately, it is better to specify the base commit of your pool request through your CI / CD tool, then this will be more honest testing.
Since lerna knows all the dependencies inside the packages, it can detect indirect dependencies as well. If you change library A, which is used in library B, which is used in service C, lerna will understand this. , . , C — , . lerna .
, : c lerna , yarn workspaces .
, . , . . Which is easier? , , , . , , . , - . , Babel. , , . . , .
: mishanga . , , . , .
According to Marina Pereskokova, the head of Yandex.Map API development service, my grandfather planted a monorepa, and a monorepa has grown big, big.
- We at Yandex tried different ways of working with several services and noticed - as soon as you have more than one service, inevitably common parts begin to appear: models, utilities, tools, pieces of code, templates, components. The question is: where to put all this? Of course, you can copy-paste, we can do it, but I want it beautifully.
We even tried an entity like SVN externals for those who remember. We tried git submodules. We tried npm packages when they appeared. But all this was somehow long, or something. You support any package, find an error, make corrections. Then you need to release a new version, go through the services, upgrade to this version, check that everything works, run the tests, find the error, go back to the repository with the library, fix the error, release the new version, go through the services, update and so on circle. It just turned into pain.
Then we thought about whether we should come together in one repository. Take all our services and libraries, transfer and develop in one repository. There were a lot of advantages. I’m not saying that this approach is ideal, but from the point of view of the company and even the department of several groups, significant advantages appear.
For me personally, the most important thing is the atomicity of commits, that as a developer, I can fix the library with one commit, bypass all services, make changes, run tests, verify that everything works, push it into the master, and all this with one change. No need to reassemble, publish, update anything.
But if everything is so good, why haven't everyone moved to the mono-repository yet? Of course, there are also disadvantages in it.
As Marina Pereskokova, the head of Yandex.Mart API development service, said, grandfather planted a monorepa, a monorepa has grown big, big. This is a fact, not a joke. If you collect many services in one single repository, it inevitably grows. And if we are talking about git, which pulls out all the files plus their entire history for the entire existence of your code, this is a rather large disk space.
The second problem is the injection into the master. You prepared a pool request, went through a review, you are ready to merge it. And it turns out that someone managed to get ahead of you and you need to resolve conflicts. You resolved the conflicts, again ready to pour in, and again you did not have time. This problem is being solved, there are merge queue systems, when a special robot automates this work, lays out pool requests in a queue, and tries to resolve conflicts if it can. If he can’t, he calls the author. However, such a problem exists. There are solutions that level it, but you need to keep it in mind.
These are technical points, but there are also organizational ones. Suppose you have several teams that make several different services. When they move to a single repository, their responsibility begins to erode. Because they made a release, rolled out in production - something broke. We begin the debriefing. It turns out that it is a developer from another team that has committed something to the common code, we pulled it, unreleased it, did not see it, everything broke. And it is not clear who is responsible. It is important to understand and use all possible methods: unit tests, integration tests, linter - everything that is possible to reduce this problem of the influence of one code on all other services.
Interestingly, who else besides Yandex and other players uses the mono-repository? Quite a lot of people. These are React, Jest, Babel, Ember, Meteor, Angular. People understand - it’s easier, cheaper, faster to develop and publish npm packages from a mono-repository than from several small repositories. The most interesting thing is that along with this process, tools for working with a monorepository began to develop. Just about them and I want to talk.
It all starts with creating a monorepository. The world's most famous front-end tool for this is called lerna.
Just open your repository, run npx lerna init, it will ask you some suggestive questions and add a few entities to your working copy. The first entity is the lerna.json config, which indicates at least two fields: the end-to-end version of all your packages and the location of your packages in the file system. By default, all packages are added to the packages folder, but you can configure this as you like, you can even add them to the root, lerna can pick it up too.
The next step is how to add your repositories to the mono repository, how to transfer them?
What do we want to achieve? Most likely, you already have some kind of repository, in this case A and B.
These are two services, each in its own repository, and we want to transfer them to the new mono-repository in the packages folder, preferably with a history of commits, so that you can make git blame, git log, and so on.
There is a lerna import tool for this. You simply specify the location of your repository, and lerna transfers it to your monorepo. At the same time, she, firstly, takes a list of all the commits, modifies each commit, changing the path to the files from the root to packages / package_name, and applies them one after another, imposes them in your mono-repository. In fact, each commit prepares, changing the file paths in it. Essentially, lerna does git magic for you. If you read the source code, there simply git commands are executed in a certain sequence.
This is the first way. It has a drawback: if you work in a company where there are production processes, where people are already writing some kind of code, and you are going to translate them into a monorep, you are unlikely to do it in one day. You will need to figure out, configure, verify that everything starts, tests. But people do not have work, they continue to do something.
For a smoother transition to mono-rap, there is such a tool as git subtree. This is a trickier thing, but at the same time native to git, which allows you to not only import individual repositories into a mono-repository by some kind of prefix, but also exchange changes back and forth. That is, the team that makes the service can be easily developed further in its own repository, while you can pull their changes through git subtree pull, make your own changes and push them back through git subtree push. And live like this in the transition period for as long as you like.
And when you’ve set everything up, checked that all tests are running, the deployment is working, the entire CI / CD is configured, you can say that it’s time to move on. For the transition period, a great solution, I recommend.
Well, we moved our repositories into one mono-repository, but where is the magic somewhere? But we want to highlight the common parts and somehow use them. And for this there is a “dependency binding” mechanism. What is dependency binding? There is a lerna bootstrap tool, this is a command that is similar to npm install, it just runs npm install in all of your packages.
But that's not all. In addition, she is looking for internal dependencies. You can use another in one package inside your repository. For example, if you have package A, which depends on Jest in this case, there is package B, which depends on Jest and package A. If package A is a common tool, a common component, then package B is a service that has it uses.
Lerna defines such internal dependencies and physically replaces this dependency with a symbolic link on the file system.
After you run lerna bootstrap, right inside the node_modules folder, instead of the physical folder A, a symbolic link appears that leads to the folder with package A. This is very convenient because you can edit the code inside package A and immediately check the result in package B , run tests, integration, units, whatever you want. Development is greatly simplified, you no longer need to rebuild package A, publish, connect package B. They just fixed it here, checked it.
Please note, if you look at the node_modules folders, and there, and there is jest, we have duplicated the installed module. In general, it is quite a long time when you start lerna bootstrap, wait until everything stops, due to the fact that there is a lot of any kind of repeated work, duplicate dependencies are obtained in each package.
To speed up the installation of dependencies, the mechanism for raising dependencies is used. The idea is very simple: you can take the general dependencies to the root node_modules.
If you specify the --hoist option (this is an upgrade from English), then almost all the dependencies will simply move to the root node_modules. And it works almost always. Noda is so arranged that if she has not found the dependencies at her level, she begins to search a level higher, if not there, another level higher and so on. Almost nothing changes. But in fact, we took and deduplicated our dependencies, transferred the dependencies to the root.
At the same time, lerna is smart enough. If there is any conflict, for example, if package A used Jest version 1, and package B used version 2, then one of them would pop up, and the second would remain at its level. This is approximately what npm is actually doing inside the normal node_modules folder, it also tries to deduplicate dependencies and to the maximum carry them to the root.
Unfortunately, this magic does not always work, especially with tools, with Babel, with Jest. It often happens that he starts, because Jest has its own system for resolving modules, Noda starts to lag, throw an error. Especially for such cases when the tool does not cope with the dependencies that have gone to the root, there is the nohoist option, which allows you to point out that these packages do not transfer to the root, leave them in place.
If you specify --nohoist = jest, then all the dependencies except jest will go to the root, and jest will remain at the packet level. Not for nothing I gave such an example - it is jest that has problems with this behavior, and nohoist helps with this.
Another plus of dependency recovery:
If before that you had separate package-lock.json for each service, for each package, then when you are hoyed, everything moves up, and the only package-lock.json remains. This is convenient from the point of view of pouring into the master, resolving conflicts. Once everyone was killed, and that’s it.
But how does lerna achieve this? She is quite aggressive with npm. When you specify hoist, it takes your package.json in the root, backs it up, substitutes another for it, aggregates all your dependencies into it, runs npm install, almost everything is put in the root. Then this temporary package.json removes, restores yours. If after that you run any command with npm, for example, npm remove, npm will not understand what happened, why all of the dependencies suddenly appeared at the root. Lerna violates the level of abstraction, she crawls into the tool, which is below her level.
The guys from Yarn were the first to notice this problem and said: what are we tormenting, let us do everything for you natively, so that everything out of the box works.
Yarn can already do the same thing out of the box: tie dependencies, if he sees that package B depends on package A, he will make a symlink for you, for free. He knows how to raise dependencies, does it by default, everything adds up to the root. Like lerna, it can leave the only yarn.lock in the root of the repository. Everyone else yarn.lock you no longer need.
It is configured in a similar way. Unfortunately, yarn assumes that all the settings are added to package.json, I know there are people who try to take away all the settings of the tools from there, leaving only a minimum. Unfortunately, yarn has not yet learned to specify this in another file, only package.json. There are two new options, one new and one mandatory. Since it is assumed that the root repository will never publish, yarn requires private = true to be specified there.
But the settings for workspaces are stored in the same key. The setting is very similar to the lerna settings, there is a packages field where you specify the location of your packages, and there is a nohoist option, very similar to the nohoist option in lerna. Just specify these settings and get the same structure as in lerna. All common dependencies went to the root, and those specified in the nohoist key remained at their level.
The best part is that lerna can work with yarn and pick up its settings. It is enough to specify two fields in lerna.json, lerna will immediately understand that you are using yarn, go into package.json, get all the settings from there and work with them. These two tools already know about each other and work together.
Why hasn’t support been made in npm so far if so many large companies use the mono-repository?
Link from the slide
They say that everything will be, but in the seventh version. Basic support in the seventh, extended - in the eighth. This post was released a month ago, but at the same time, the date when the seventh npm will be released is still unknown. We are waiting for him to finally catch up with yarn.
When you have several services in one single repository, the question inevitably arises of how to manage them so as not to go to each folder, not run commands? There are massive operations for this.
Yarn has a yarn workspace command, followed by the name of the package and the name of the command. Since yarn from the box, unlike npm, can do all three things: run its own commands, add a dependency on jest, run scripts from package.json, like test, and also can run executable files from the node_modules / .bin folder. He will teach for you with the help of heuristics to understand what you want. It is very convenient to use yarn workspace for point operations on one package.
There is a similar command that allows you to execute a command on all packages that you have.
Indicate simply your commands with all arguments.
From the pros, it’s very convenient to run different teams. Of the minuses, for example, it is impossible to run shell commands. Suppose I want to delete all the node modules folders, I cannot run yarn workspaces run rm.
It is not possible to specify a list of packages, for example, I want to remove the dependency in only two packages, only one at a time or separately.
Well, he crashes at the very first mistake. If I want to remove the dependency from all packages - and in fact, only two of them have it, but I don’t want to think where it is, but I just want to remove it — then yarn will not allow it, it will fall at the first situation where this package is not in the dependencies. This is not very convenient, sometimes you want to ignore errors, run through all the packages.
Lerna has a much more interesting toolkit, there are two separate run and exec commands. Run can execute scripts from package.json, while unlike yarn, it can filter everything by package, you can specify --scope, you can use asterisks, globs, everything is quite universal. You can run these operations in parallel, you can ignore errors through the --no-bail switch.
Exec is very similar. Unlike yarn, it allows not only to run executable files from node_modules.bin, but to execute any arbitrary shell commands. For example, you can remove node_modules or run some make, whatever you want. And the same option is supported.
Very convenient tools, some pluses. This is the case when lerna tears yarn, is at the right level of abstraction. This is exactly what lerna needs: simplify work with several packages in monorep.
With monoreps there is one more minus. When you have a CI / CD, you can’t optimize it. The more services you have, the longer it all takes. Suppose you start testing all the services for each pool request, and the more there are, the longer the work takes. Selective operations can be used to optimize this process. I will name three different ways. The first two of them can be used not only in monorep, but also in your projects, if for some reason you do not use these methods.
The first is lint-stages, which allows you to run linter, tests, everything you want, only to files that have changed or will be commited in this commit. Run the entire lint not on your entire project, but only on the files that have changed.
The setup is very simple. Put lint-staged, husky, pre-commit-hooks and say that when changing any js-file you need to run eslint. Thus, precommit verification is greatly accelerated. Especially if you have many services, a very large mono-repository. Then running eslint on all files is too expensive, and you can optimize precommit-hooks on lint in this way.
If you write tests on Jest, it also has tools for selectively running tests.
This option allows you to give it a list of source files and find all the tests that one way or another affect these files. What can be used in conjunction with lint-staged? Please note, here I am not specifying all the js files, but only the source. We exclude the js-files themselves with tests inside, we look only at the source. We start findRelatedTests and greatly accelerate the unit run to precommit or prepush, as you wish.
And the third way is associated with monorepositories. This is lerna, which can determine which packages have changed in comparison with the base commit. Here it’s more likely not about hooks, but about your CI / CD: Travis or another service that you use.
The run and exec commands have the since option, which allows you to run any command only in those packages that have changed since some kind of commit. In simple cases, you can specify a wizard if you pour everything into it. If you want more accurately, it is better to specify the base commit of your pool request through your CI / CD tool, then this will be more honest testing.
Since lerna knows all the dependencies inside the packages, it can detect indirect dependencies as well. If you change library A, which is used in library B, which is used in service C, lerna will understand this. , . , C — , . lerna .
, : c lerna , yarn workspaces .
, . , . . Which is easier? , , , . , , . , - . , Babel. , , . . , .
: mishanga . , , . , .
All Articles