Backup, part at the request of readers: UrBackup overview, BackupPC, AMANDA

This overview note continues the backup cycle , written at the request of readers, it will focus on UrBackup, BackupPC, as well as AMANDA.
Overview of UrBackup.
At the request of a VGusev2007 participant, I am adding an overview of UrBackup, a client-server system for backup. It allows you to create full and incremental backups, knows how to work with device snapshots (Win only?), And also knows how to create file backups. The client can be located on the same network as the server, or connect via the Internet. Claimed change tracking, which allows you to quickly find the differences between backups. There is also support for data storage deduplication on the server side, which saves space. Network connections are encrypted; there is also a web interface for managing the server. Let's see what she is capable of:
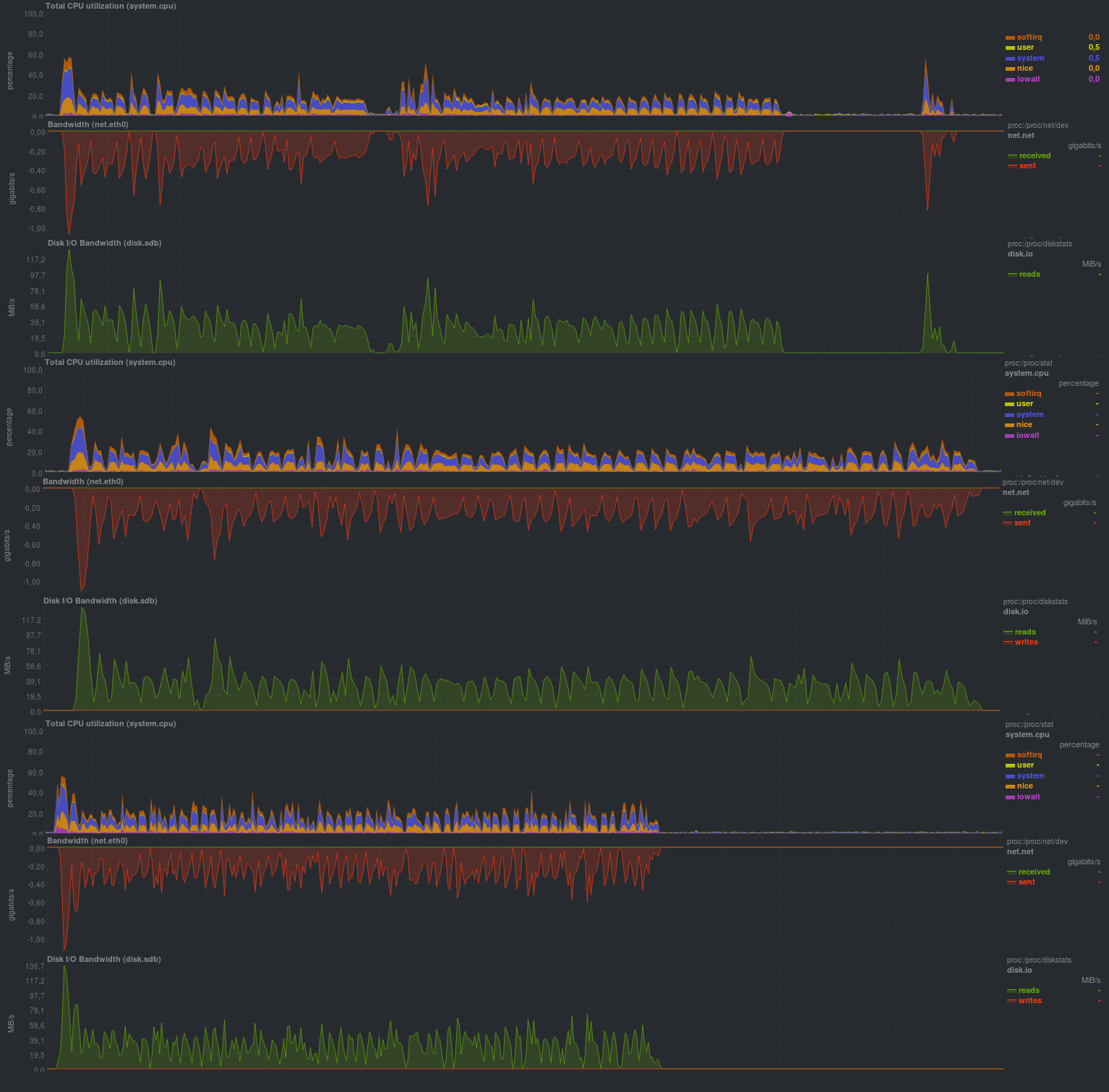
Working hours:
| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 8m20s | 8m19s | 8m24s |
| Second test | 8m30s | 8m34s | 8m20s |
| Third test | 8m10s | 8m14s | 8m12s |
In incremental backup mode:

Working hours:
| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 8m10s | 8m10s | 8m12s |
| Second test | 3m50s | 4m12s | 3m34s |
| Third test | 2m50s | 2m35s | 2m38s |
The size of the repository in both cases was approximately 14 GB, which indicates a working server-side deduplication. It should also be noted that the backup time on the server and on the client does not match, which is clearly visible in the graphs and is a very nice bonus, since the web interface shows the time of the backup process on the server side without taking into account the client status. In general, the graphs for a full and incremental copy are indistinguishable. Probably the only difference is how it is handled on the server side. Also pleased with the low processor load on the redundant system.
Overview of BackupPC
At the request of vanzhiganov , I add a review of BackupPC. This software is installed on the backup storage server, written in perl, runs on top of various backup tools - primarily rsync, tar. Ssh and smb are used as a transport, and there is also a cgi-based web interface (deployed on top of apache). The web interface has an extensive list of settings. Of the features - the ability to set the minimum time between backups, as well as the period during which backups will not be created. When choosing a file system for the backup server, you need to monitor the support of hard links. Thus, the file system for the repository cannot be split into mount points. In general, a pretty good impression, let's see what this software is capable of:

| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 12m25s | 12m14s | 12m27s |
| Second test | 7m41s | 7m44s | 7m35s |
| Third test | 10m11s | 10m0s | 9m54s |
If you use full backups and tar:
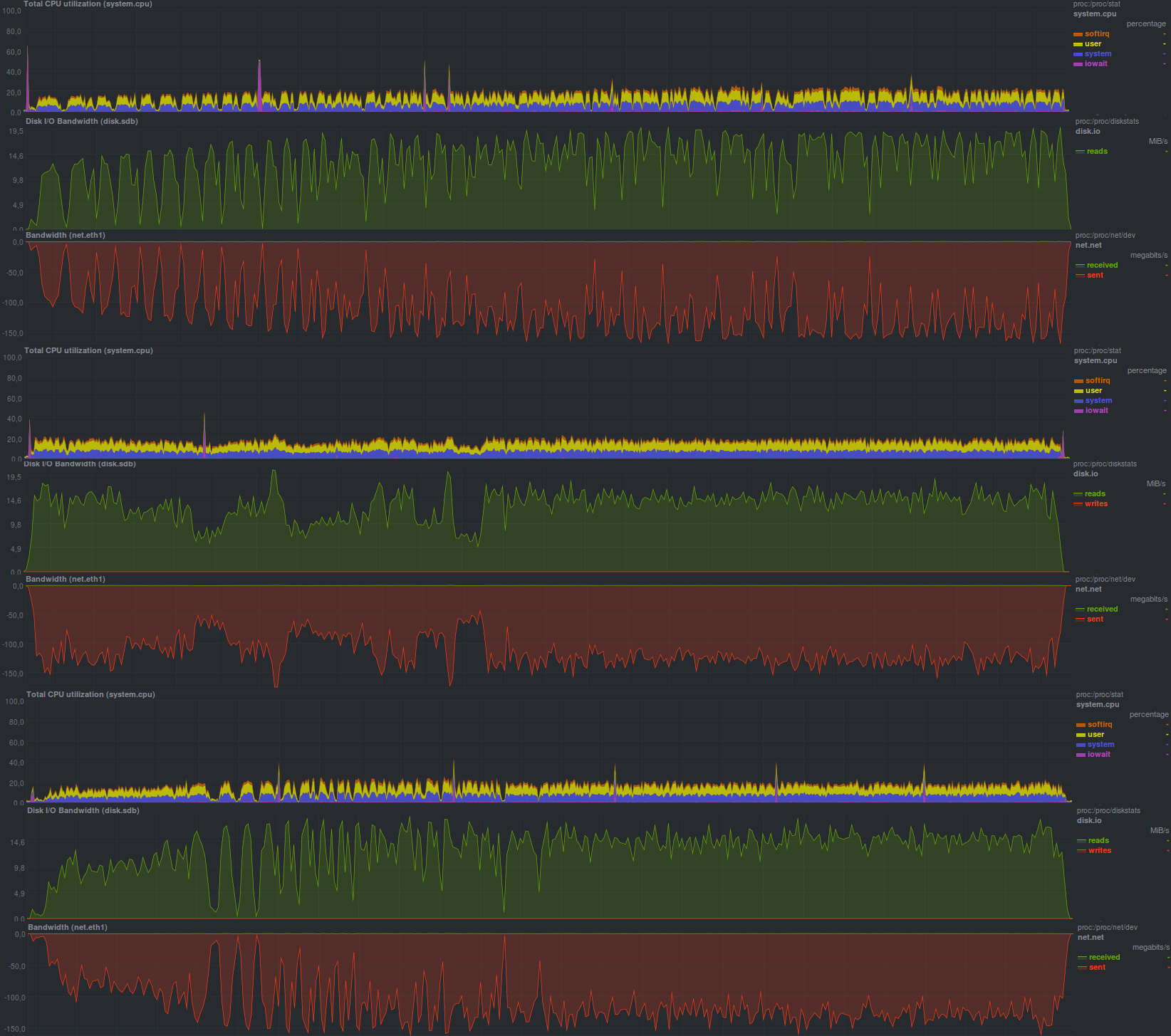
| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 12m41s | 12m25s | 12m45s |
| Second test | 12m35s | 12m45s | 12m14s |
| Third test | 12m43s | 12m25s | 12m5s |
In incremental backup mode, tar had to be abandoned because no backups were created with these settings.
The results of creating incremental backups using rsync are as follows:

| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 11m55s | 11m50s | 12m25s |
| Second test | 2m42s | 2m50s | 2m30s |
| Third test | 6m00s | 5m35s | 5m30s |
On the whole, rsync has a slight speed advantage; rsync also works more economically with the network. In part, this can be offset by the lesser use of cpu with tar as a backup program. Another advantage of rsync is working with incremental copies. The size of the repository when creating full backups is the same, is 16 GB, in the case of incremental backups - 14 GB for one run, which means working deduplication.
AMANDA Review
At the request of the oller member, I add AMANDA tests,

| First start | Second launch | Third launch | |
|---|---|---|---|
| First test | 9m5s | 8m59s | 9m6s |
| Second test | 0m5s | 0m5s | 0m5s |
| Third test | 2m40s | 2m47s | 2m45s |
The program fully loads one processor core, but due to the limited iops disk on the server side of the backup storage it cannot develop a high data transfer speed. In general, the setup delivered a little more trouble than other participants, since the author of the program does not use ssh as a transport, but implements a similar scheme with keys, creating and maintaining a full-fledged CA. It is possible to widely limit the client and the backup server: for example, if they cannot completely trust each other, then, as an option, you can prevent the server from initiating a backup restore by setting the value of the corresponding variable to zero in the settings file. It is possible to connect a web-based interface for management, but in general, a customized system can be fully automated using small bash scripts (or SCM, for example ansible). There is a somewhat non-trivial storage configuration system, which, most likely, is associated with the support of an extensive list of various data storage devices (LTO cassettes, hard drives, etc.). It is also worth noting that of all the programs discussed in this article, AMANDA is the only one that managed to detect the renaming of the directory. The size of the repository in one run was 13 GB.
Announcement
Backup, part 1: Why do you need a backup, an overview of methods, technologies
Backup, Part 2: Overview and Testing rsync-based backup tools
Backup, Part 3: Overview and Testing duplicity, duplicati
Backup, Part 4: Overview and Testing zbackup, restic, borgbackup
Backup, part 5: Testing bacula and veeam backup for linux
Backup, Part 6: Comparing Backup Tools
Backup Part 7: Conclusions
All Articles