How We Made Our Workflow Engine
At DIRECTUM, we are developing the DirectumRX ECM system. The core element of the Workflow module for the ECM system is the engine. He is responsible for changing the state of the process instance (instance) during the life cycle. Before you start developing the Workflow module, you should decide: take a ready-made engine or write your own. Initially, we went for the first option. We took the Windows Workflow Foundation (WF) engine, and overall it suited us. But over time, we realized that we needed our own engine. How this happened, and what came of it, I will tell below.
Back in 2013, when it was time to develop a Workflow module for DirectumRX, we decided to take a ready-made engine. Viewed from Windows Workflow Foundation (WF), ActiveFlow, K2.NET, WorkflowEngine.NET, cDevWorkflow, NetBpm. Some were not happy with the cost, some were raw, some, by that time, had not been supported for a long time.
As a result, the choice fell on WF. We then actively used the Microsoft stack (WCF, WPF) and decided that another W would not hurt us. Another advantage was our Microsoft Gold Application Development Partner status, which made it possible to develop products using Microsoft technologies. Well, in general, the capabilities of the engine suited us and covered almost all of our cases.
After 6 years of using WF, we have accumulated a number of problems, and the cost of solving these problems was too high. We began to think about developing our own engine. I’ll tell you about some of them.
Years passed, the number of product installations and the load grew. Bugs began to appear, the diagnosis and correction of which took a lot of resources. This was facilitated by a complex of reasons: lack of competencies, design errors when embedding the previous engine, and features of WF.
We had enough basic competencies to build in WF DirectumRX, the same level was enough to deal with simple bugs. For complex cases, competencies were not enough - analysis of logs, analysis of the state of the instance, and so on, were difficult.
It was possible to send a person to courses on WF, but they are hardly taught how to analyze the state of an instance and associate its change with the logs. And frankly, no one had a particular desire to upgrade their skills with virtually dead technology.
Another way is to hire a person with the appropriate competencies. But to find one in Izhevsk is not such a trivial task, and not the fact that its level is enough to solve our problems.
In fact, we are faced with a high entry threshold to support WF. One way or another, I think we would deal with this problem, if not for a number of other reasons.
Another problem was that when constructing process diagrams we use our own notation. It is more visual and easier to develop. For example, WF does not allow to implement a full-fledged graph, you cannot draw dead-end blocks, there are features of drawing parallel branches. The payback for this is the conversion of our circuits to WF circuits, which are not so simple and impose a number of limitations. When debugging, I had to analyze the state of the WF circuit, because of this, visibility was lost, I had to compare blocks and faces with each other to understand what step the instance was at.

Representation of the circuit in DirectumRX
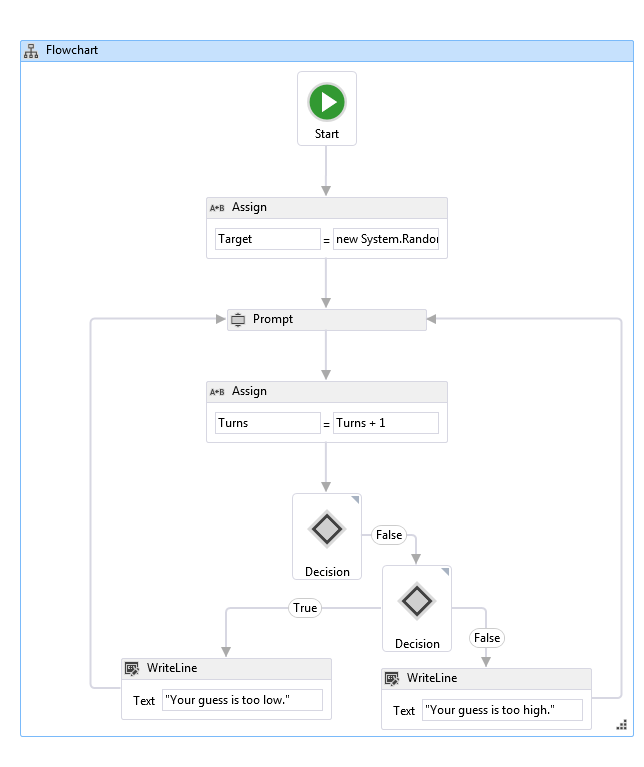
Representation of the circuit in WF
Also, we were faced with the fact that the WF documentation describes the instance repository poorly. As I wrote above, this is necessary when analyzing a bug in order to understand the state of the process instance. In addition, part of the data is encrypted, which also interferes with the analysis.
For many years now, there has been a trend in Russia for import substitution, and more and more often one of the requirements for the platform is the support of open source database management systems (DBMS) or domestic-made DBMS. Most often it is Postgres. Out of the box, WF only supports MS SQL. To work with other databases, you can use third-party providers. We chose dotConnect from DevArt.
While the load was light, everything worked well. But as soon as we drove the system under load, problems appeared. WF could suddenly stop and stop processing instances (prepared transactions ended), or all messages went to MSMQ Poisoned Queue, etc. We dealt with all these problems, but spent a lot of time on it. There was no guarantee that a new one would not appear, the solution of which would have to spend the same amount.
After Microsoft announced .Net Core, we decided that we would gradually go to it in order to achieve cross-platform for our solutions. Microsoft decided not to take WF on board, which blocked the way for us to transfer the Workflow module to .Net Core in the form in which it existed. We are aware that there are unofficial WF ports on .Net Core, and among them there are even WF developers, but all of them are not 100% compatible. Another factor was Microsoft's refusal to develop .Net. in favor of .Net Core.
Taking all this heap of problems, solution options, the complexity of refactoring and corrections, weighing all the pros and cons, we decided to switch to a new engine. We started by analyzing existing ones.
The main requirements when choosing an engine were:
In addition, it was required that the Activity (Activity) could execute application code in C #, it was possible to debug blocks, etc.
As part of the analysis of existing engines, we looked:
Having imposed all the requirements on the solutions reviewed and adding the cost of paid solutions, we considered that our engine is not very expensive, while it will be 100% suitable for our requests and it will be easy to refine.
In the previous implementation, the WF module was a WCF service to which WF libraries were connected. He was able to create process instances, start processes, execute blocks, including business logic (code written by developers). All this was hosted in the IIS application.
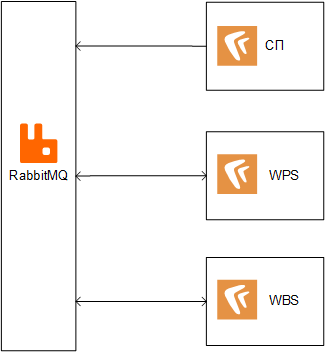
In the new implementation, following the trend of microservice architecture, we decided to immediately divide the service into two: Workflow Process Service (WPS) and Workflow Block Service (WBS), which could be hosted separately. Another link in this chain is the Application Service, which implements DirectumRX system and business logic, and clients work with it.
WPS “walks” according to the scheme, WBS processes blocks and runs business logic at every step. The command to start the process comes from the Application Server. The interaction between the services is carried out using RabbitMQ. Below I will tell you more about each of them.
Workflow Process Service is a microservice that is responsible for starting processes and bypassing the process diagram.
The service repository contains process diagrams with versioning support and serialized state of process instances. You can use MS SQL and Postgres as storage.
The service is able to process messages received from other services through RabbitMQ. Essentially, messages are a service API. Types of messages that the service can receive:
The scheme consists of blocks and connections between them (faces). Each face has an identifier, the so-called "Execution Result". There are 5 types of blocks:

WPS schema view
When a message arrives at the start of the process, the service creates an instance and begins to "walk" according to the scheme. The class responsible for the “walking” according to the scheme, we jokingly call the “Stepator”. A circuit always starts with a StartBlock. Then the strider takes all the outgoing faces and activates them. Each block works according to the principle of the “AND” block, i.e. all incoming faces must be active so that the block can be activated. The algorithm then decides which blocks can be activated and sends a WBS message to activate these blocks. WBS processes the block and returns the result of the WPS. Depending on the result of the execution, the strider selects the appropriate faces coming out of the block for activation, and the process continues.
During the development process, we came across interesting situations related to cyclic connections between blocks, which added logic when deciding which block to activate / terminate.
The service is autonomous, i.e. all you need is to send him the schema in Json format, write your own block handler, and you can exchange messages.
Workflow Block Service is a service that processes block diagrams. The service knows about the essence of business logic, such as task, task, etc. These entities can be added to the DirectumRX Development Studio (DDS) development environment. For example, our blocks have an event to start the block. The code for this event handler is written by the developer in DDS, and WBS executes this code. In fact, this is our implementation of the block handler; you can replace it with your own.
The service stores the state of the blocks. In addition to the basic properties (Id, State), the block may contain other information necessary for the execution / termination / suspension of the block.
Blocks may be in a state:
When a message arrives at the execution of the block, the block is executed, and WBS sends a message with the result of the execution of the block.
WPS and WBS can be deployed in multiple instances. At one point in time, only one WPS service can process one process instance. The same applies to processing blocks - one process instance can process only one block at a time. This is helped by locks that are put on the process during processing. If there are several messages in the queue for processing a process / blocks in one process, then the message is postponed for some time. At the same time, each service can simultaneously perform work on several process instances.
A situation may arise when several messages come in one process after another to process blocks (parallel branches). To reduce the number of situations when you have to postpone messages, WBS takes several messages at a time and runs them one after another, bypassing sending to the queue for re-execution due to blocking of the process.
After the transition to a new engine, the question arose, and what to do with existing process instances? The preferred option was their conversion, so that they continued to work on the new engine. The advantages are obvious: we support only one engine, the problems of supporting the old engine disappear (see above). But there were risks that we won’t be able to figure out how to get the data we need from serialized process instances. There was also a fallback: to give existing instances finalize on the old engine, and launch new ones on a fresh one. The disadvantages of this option follow from the advantages of the previous one, plus additional resources are needed to twist both engines.
For conversion, we needed to take the old state of the process in WF format and generate the states of processes and blocks. We wrote a utility that took the serialized state of a process instance in the database, pulled from it a list of active blocks, execution results for faces, and virtually executed the process. As a result, we got the state of the instance at the time of conversion.
Difficulties arose in how to properly deserialize process instance data in WF. The state of the process instance (instance) WF stores in the database in the form of xaml. We could not find a clear description of the structure of this xaml, we had to get to everything empirically. We parsed the data manually and pulled out the information we needed. As part of this task, we worked out another option - using WF tools to deserialize the state of the instance and try to get information from objects. But due to the fact that the structure of such objects was very complex, we abandoned this idea and settled on “manual” parsing xaml.
As a result, the conversion was successful, and all process instances began to be processed by the new engine.
So what did the Workflow engine give us? Actually, we managed to defeat all the problems voiced at the beginning of the article:
As a bonus, we got a clear and supported code that we can adapt to ourselves.
The cost of the engine turned out to be comparable to what we would have to spend on the purchase / adaptation of a third-party product. At the moment, we believe that the decision to develop your own engine turned out to be justified.
We are also waiting for load testing for 10,000+ concurrent users. Perhaps some optimization will be required, or maybe it will take off? ;-)
We recently released DirectumRX 3.2, which included the new Workflow. Let's see how the engine will show itself to customers.
Old engine
Why wf?
Back in 2013, when it was time to develop a Workflow module for DirectumRX, we decided to take a ready-made engine. Viewed from Windows Workflow Foundation (WF), ActiveFlow, K2.NET, WorkflowEngine.NET, cDevWorkflow, NetBpm. Some were not happy with the cost, some were raw, some, by that time, had not been supported for a long time.
As a result, the choice fell on WF. We then actively used the Microsoft stack (WCF, WPF) and decided that another W would not hurt us. Another advantage was our Microsoft Gold Application Development Partner status, which made it possible to develop products using Microsoft technologies. Well, in general, the capabilities of the engine suited us and covered almost all of our cases.
What is wrong with WF?
After 6 years of using WF, we have accumulated a number of problems, and the cost of solving these problems was too high. We began to think about developing our own engine. I’ll tell you about some of them.
Expensive diagnostics and bug fixes
Years passed, the number of product installations and the load grew. Bugs began to appear, the diagnosis and correction of which took a lot of resources. This was facilitated by a complex of reasons: lack of competencies, design errors when embedding the previous engine, and features of WF.
We had enough basic competencies to build in WF DirectumRX, the same level was enough to deal with simple bugs. For complex cases, competencies were not enough - analysis of logs, analysis of the state of the instance, and so on, were difficult.
It was possible to send a person to courses on WF, but they are hardly taught how to analyze the state of an instance and associate its change with the logs. And frankly, no one had a particular desire to upgrade their skills with virtually dead technology.
Another way is to hire a person with the appropriate competencies. But to find one in Izhevsk is not such a trivial task, and not the fact that its level is enough to solve our problems.
In fact, we are faced with a high entry threshold to support WF. One way or another, I think we would deal with this problem, if not for a number of other reasons.
Another problem was that when constructing process diagrams we use our own notation. It is more visual and easier to develop. For example, WF does not allow to implement a full-fledged graph, you cannot draw dead-end blocks, there are features of drawing parallel branches. The payback for this is the conversion of our circuits to WF circuits, which are not so simple and impose a number of limitations. When debugging, I had to analyze the state of the WF circuit, because of this, visibility was lost, I had to compare blocks and faces with each other to understand what step the instance was at.
Representation of the circuit in DirectumRX
Representation of the circuit in WF
Also, we were faced with the fact that the WF documentation describes the instance repository poorly. As I wrote above, this is necessary when analyzing a bug in order to understand the state of the process instance. In addition, part of the data is encrypted, which also interferes with the analysis.
Postgres as a DBMS
For many years now, there has been a trend in Russia for import substitution, and more and more often one of the requirements for the platform is the support of open source database management systems (DBMS) or domestic-made DBMS. Most often it is Postgres. Out of the box, WF only supports MS SQL. To work with other databases, you can use third-party providers. We chose dotConnect from DevArt.
While the load was light, everything worked well. But as soon as we drove the system under load, problems appeared. WF could suddenly stop and stop processing instances (prepared transactions ended), or all messages went to MSMQ Poisoned Queue, etc. We dealt with all these problems, but spent a lot of time on it. There was no guarantee that a new one would not appear, the solution of which would have to spend the same amount.
Care on .net core
After Microsoft announced .Net Core, we decided that we would gradually go to it in order to achieve cross-platform for our solutions. Microsoft decided not to take WF on board, which blocked the way for us to transfer the Workflow module to .Net Core in the form in which it existed. We are aware that there are unofficial WF ports on .Net Core, and among them there are even WF developers, but all of them are not 100% compatible. Another factor was Microsoft's refusal to develop .Net. in favor of .Net Core.
New engine
Taking all this heap of problems, solution options, the complexity of refactoring and corrections, weighing all the pros and cons, we decided to switch to a new engine. We started by analyzing existing ones.
The choice
The main requirements when choosing an engine were:
- work on .Net Core;
- scalability
- conversion of existing process instances, with the ability to continue execution after conversion
- reasonable cost of analyzing existing problems
- work with different DBMS
In addition, it was required that the Activity (Activity) could execute application code in C #, it was possible to debug blocks, etc.
As part of the analysis of existing engines, we looked:
- Core wf
- Flowwright
- K2 workflow
- Workflow core
- Zeebe
- Workflow engine
- Durable Task Framework
- Camunda
- Orleans activities
Having imposed all the requirements on the solutions reviewed and adding the cost of paid solutions, we considered that our engine is not very expensive, while it will be 100% suitable for our requests and it will be easy to refine.
Implementation / Architecture
In the previous implementation, the WF module was a WCF service to which WF libraries were connected. He was able to create process instances, start processes, execute blocks, including business logic (code written by developers). All this was hosted in the IIS application.
In the new implementation, following the trend of microservice architecture, we decided to immediately divide the service into two: Workflow Process Service (WPS) and Workflow Block Service (WBS), which could be hosted separately. Another link in this chain is the Application Service, which implements DirectumRX system and business logic, and clients work with it.
WPS “walks” according to the scheme, WBS processes blocks and runs business logic at every step. The command to start the process comes from the Application Server. The interaction between the services is carried out using RabbitMQ. Below I will tell you more about each of them.
Wps
Workflow Process Service is a microservice that is responsible for starting processes and bypassing the process diagram.
The service repository contains process diagrams with versioning support and serialized state of process instances. You can use MS SQL and Postgres as storage.
The service is able to process messages received from other services through RabbitMQ. Essentially, messages are a service API. Types of messages that the service can receive:
- StartProcess - create a new process instance and start a crawl on it;
- CompleteBlock - completion of the block, after this message, the service moves the process instance further along the scheme;
- Suspend / ResumeProcess - suspend execution of a process instance, for example, due to an error while processing a block, and resume execution after the error has been fixed;
- Abort / RestartProcess - stop the execution of the process instance and start it again;
- DeleteProcess - delete a process instance.
The scheme consists of blocks and connections between them (faces). Each face has an identifier, the so-called "Execution Result". There are 5 types of blocks:
- StartBlock
- Block
- OrBlock;
- AndBlock;
- FinishBlock.
WPS schema view
When a message arrives at the start of the process, the service creates an instance and begins to "walk" according to the scheme. The class responsible for the “walking” according to the scheme, we jokingly call the “Stepator”. A circuit always starts with a StartBlock. Then the strider takes all the outgoing faces and activates them. Each block works according to the principle of the “AND” block, i.e. all incoming faces must be active so that the block can be activated. The algorithm then decides which blocks can be activated and sends a WBS message to activate these blocks. WBS processes the block and returns the result of the WPS. Depending on the result of the execution, the strider selects the appropriate faces coming out of the block for activation, and the process continues.
During the development process, we came across interesting situations related to cyclic connections between blocks, which added logic when deciding which block to activate / terminate.
The service is autonomous, i.e. all you need is to send him the schema in Json format, write your own block handler, and you can exchange messages.
Wbs
Workflow Block Service is a service that processes block diagrams. The service knows about the essence of business logic, such as task, task, etc. These entities can be added to the DirectumRX Development Studio (DDS) development environment. For example, our blocks have an event to start the block. The code for this event handler is written by the developer in DDS, and WBS executes this code. In fact, this is our implementation of the block handler; you can replace it with your own.
The service stores the state of the blocks. In addition to the basic properties (Id, State), the block may contain other information necessary for the execution / termination / suspension of the block.
Blocks may be in a state:
- Completed - goes into this state after the successful completion of work on the block;
- Pending - is in a standby state when some work is being performed within the block, for example, some kind of response from the user is required;
- Aborted - goes into this state when the process is stopped;
- Suspended - goes into this state when the process stops when an error occurs.
When a message arrives at the execution of the block, the block is executed, and WBS sends a message with the result of the execution of the block.
Scalability
WPS and WBS can be deployed in multiple instances. At one point in time, only one WPS service can process one process instance. The same applies to processing blocks - one process instance can process only one block at a time. This is helped by locks that are put on the process during processing. If there are several messages in the queue for processing a process / blocks in one process, then the message is postponed for some time. At the same time, each service can simultaneously perform work on several process instances.
A situation may arise when several messages come in one process after another to process blocks (parallel branches). To reduce the number of situations when you have to postpone messages, WBS takes several messages at a time and runs them one after another, bypassing sending to the queue for re-execution due to blocking of the process.
Conversion
After the transition to a new engine, the question arose, and what to do with existing process instances? The preferred option was their conversion, so that they continued to work on the new engine. The advantages are obvious: we support only one engine, the problems of supporting the old engine disappear (see above). But there were risks that we won’t be able to figure out how to get the data we need from serialized process instances. There was also a fallback: to give existing instances finalize on the old engine, and launch new ones on a fresh one. The disadvantages of this option follow from the advantages of the previous one, plus additional resources are needed to twist both engines.
For conversion, we needed to take the old state of the process in WF format and generate the states of processes and blocks. We wrote a utility that took the serialized state of a process instance in the database, pulled from it a list of active blocks, execution results for faces, and virtually executed the process. As a result, we got the state of the instance at the time of conversion.
Difficulties arose in how to properly deserialize process instance data in WF. The state of the process instance (instance) WF stores in the database in the form of xaml. We could not find a clear description of the structure of this xaml, we had to get to everything empirically. We parsed the data manually and pulled out the information we needed. As part of this task, we worked out another option - using WF tools to deserialize the state of the instance and try to get information from objects. But due to the fact that the structure of such objects was very complex, we abandoned this idea and settled on “manual” parsing xaml.
As a result, the conversion was successful, and all process instances began to be processed by the new engine.
Conclusion
So what did the Workflow engine give us? Actually, we managed to defeat all the problems voiced at the beginning of the article:
- The engine is written in .NET Core;
- it is a self-host service independent of IIS;
- as a test operation, we actively use the new engine in the corporate system and managed to make sure that the analysis of bugs takes much less time;
- conducted load testing on Postgres, according to preliminary data, a bunch of WPS + WBS can cope with the load of 5000 concurrent users without problems;
- and of course, like any interesting work, this is an interesting experience.
As a bonus, we got a clear and supported code that we can adapt to ourselves.
The cost of the engine turned out to be comparable to what we would have to spend on the purchase / adaptation of a third-party product. At the moment, we believe that the decision to develop your own engine turned out to be justified.
We are also waiting for load testing for 10,000+ concurrent users. Perhaps some optimization will be required, or maybe it will take off? ;-)
We recently released DirectumRX 3.2, which included the new Workflow. Let's see how the engine will show itself to customers.
All Articles