End2 End Approach in Automatic Speech Recognition Tasks
What is End2End speech recognition, and why is it needed? What is its difference from the classical approach? And why, to train a good End2End-based model, we need a huge amount of data - in our post today.
Before talking about the End2End approach, you should first talk about the classic approach to speech recognition. What he really is?

Actually, this is not a completely linear sequence of action-blocks. Let's dwell on each block in more detail. We have some kind of input speech, it falls on the first block - Feature Extraction. This is a block that pulls signs from speech. It must be borne in mind that speech itself is a rather complicated thing. You need to be able to work with it somehow, so there are standard methods for isolating features from signal processing theory. For example, Mel-cepstral coefficients (MFCC) and so on.
The next component is the acoustic model. It can be either based on deep neural networks, or based on mixtures of Gaussian distributions and hidden Markov models. Its main goal is to obtain from one section of the acoustic signal the probability distribution of various phonemes in this section.
Next comes the decoder, which searches for the most likely path in the graph based on the result from the last step. Rescoring is the final touch in recognition, the main task of which is to re-weigh the hypotheses and produce the final result.
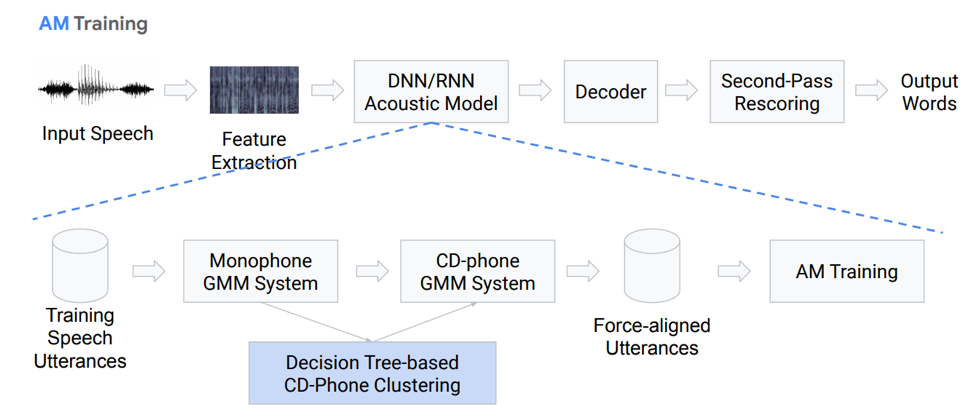
Let's dwell in more detail on the acoustic model. What is she like? We have some voice recordings that go into a certain system based on GMM (monaural gausovy mixture) or HMM. That is, we have representations in the form of phonemes, we use monophones, that is, context-independent phonemes. Further, we make mixtures of Gaussian distributions based on context-sensitive phonemes. It uses clustering based on decision trees.
Then we try to build alignment. Such a completely non-trivial method allows us to obtain an acoustic model. It doesn’t sound very simple, in fact it is even more complicated, there are many nuances, features. But as a result, a model trained on hundreds of hours is very well able to simulate acoustics.

What is a decoder? This is the module that selects the most probable transition path according to the HCLG graph, which consists of 4 parts:
H module based on HMM
C context dependency module
L pronunciation module
G language model module
We build a graph on these four components, on the basis of which we will decode our acoustic features into some verbal constructions.
Plus or minus, it is clear that the classical approach is rather cumbersome and difficult, it is difficult to train, since it consists of a large number of separate parts, for each of which you need to prepare your own data for training.
So what is End2End speech recognition and why is it needed? This is a certain system, which is designed to directly reflect the sequence of acoustic signs in the sequence of graphemes (letters) or words. You can also say that this is a system that optimizes criteria that directly affect the final metric of quality assessment. For example, our task is specifically the word error rate. As I said, there is only one motivation - to present these complex multi-stage components as one simple component that will directly display, output words or graphemes from input speech.
We immediately have a problem here: sound speech is a sequence, and at the output we also need to give a sequence. And until 2006, there was no adequate way to model this. What is the problem of modeling? There was a need for each record to create complex markup, which implies at what second we pronounce a particular sound or letter. This is a very cumbersome complex layout, and therefore a large number of studies on this topic have not been conducted. In 2006, an interesting article by Alex Graves “Connectionist temporal classification” (CTC) was published, in which this problem is, in principle, solved. But the article came out, and at that time there was not enough computing power. And real working speech recognition algorithms appeared much later.
In total, we have: the CTC algorithm was proposed by Alex Graves thirteen years ago, as a tool that allows you to train / train acoustic models without the need for this complex markup - alignment of the input and output sequence frames. Based on this algorithm, work initially appeared that was not complete end2end; phonemes were issued as a result. It is worth noting that context-sensitive phonemes based on STS achieve some of the best results in the recognition of free speech. But it is also worth noting that this algorithm, applied directly to the words, remains somewhere behind at the moment.

Now we will talk a little more in detail about what the STS is, and why it is needed, what function it performs. STS is necessary in order to train the acoustic model without the need for frame-by-frame alignment between sound and transcription. Frame-by-frame alignment is when we say that a particular frame from a sound corresponds to such a frame from transcription. We have a conventional encoder that accepts acoustic signs as an input - it gives out some kind of concealment of the state, on the basis of which we get conditional probabilities using softmax. Encoder usually consists of several layers of LSTMs or other variations of RNNs. It is worth noting that the STS operates in addition to ordinary characters with a special character called an empty character or a blank symbol. In order to solve the problem that arises due to the fact that not every acoustic frame has a frame in transcription and vice versa (that is, we have letters or sounds that sound much longer and there are short sounds, repeating sounds), and there this blank symbol.
The STS itself is intended to maximize the final probability of sequences of characters and to generalize possible alignment. Since we want to use this algorithm in neural networks, it is understood that we must understand how its forward and backward modes of operation work. We will not dwell on the mathematical justification and features of the operation of this algorithm, otherwise it will take a very long time.
What do we have: the first ASR based on the STS algorithm appears in 2014. Again, Alex Graves presented a publication based on the character-by-character STS that directly displays input speech in a sequence of words. One of the comments they made in this article is that using an external sound model is important to get a good result.
There are many different variations and improvements to the above algorithm. Here are, for example, the five most popular recently.
• The language model is included in decoding during the first pass
o [Hannun et al., 2014] [Maas et al., 2015]: Direct first-pass decoding with an LM as opposed to rescoring as in [Graves & Jaitly, 2014]
o [Miao et al., 2015]: EESEN framework for decoding with WFSTs, open source toolkit
• Large-scale training on the GPU; Data Augmentation several languages
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: Large scale GPU training; Data Augmentation; Mandarin and English
• Use of long units: words instead of characters
o [Soltau et al., 2017]: Word-level CTC targets, trained on 125,000 hours of speech. Performance close to or better than a conventional system, even without using an LM!
o [Audhkhasi et al., 2017]: Direct Acoustics-to-Word Models on Switchboard
It is worth paying attention to the implementation of DeepSpeach as a good example of an end2end CTC solution and to a variation that uses a verbal level. But there is one caveat: for training such a model, you need 125 thousand hours of labeled data, which is actually quite a lot in harsh realities.
What alternative do we have for this STS? It is probably no secret to anyone that there is such a thing as Attention or “Attention”, which revolutionized to some extent and directly went from the tasks of machine translation. And now, most of all sequence-sequence modeling decisions are based on this mechanism. What is he like? Let's try to figure it out. For the first time about Attention in speech recognition tasks, publications appeared in 2015. Someone Chen and Cherowski released two similar and dissimilar publications at the same time.
Let us dwell on the first - it is called Listen, attend and spell. In our classic simulation, in the sequence where we have an encoder and decoder, another element is added, which is called attention. The ecoder will perform the functions that the acoustic model used to perform. Its task is to turn the input speech into high-level acoustic features. Our decoder will perform the tasks that we previously performed the language model and pronunciation model (lexicon), it will autoregressively predict each output token as a function of the previous ones. And attention itself will say directly which input frame is most relevant / important in order to predict this output.
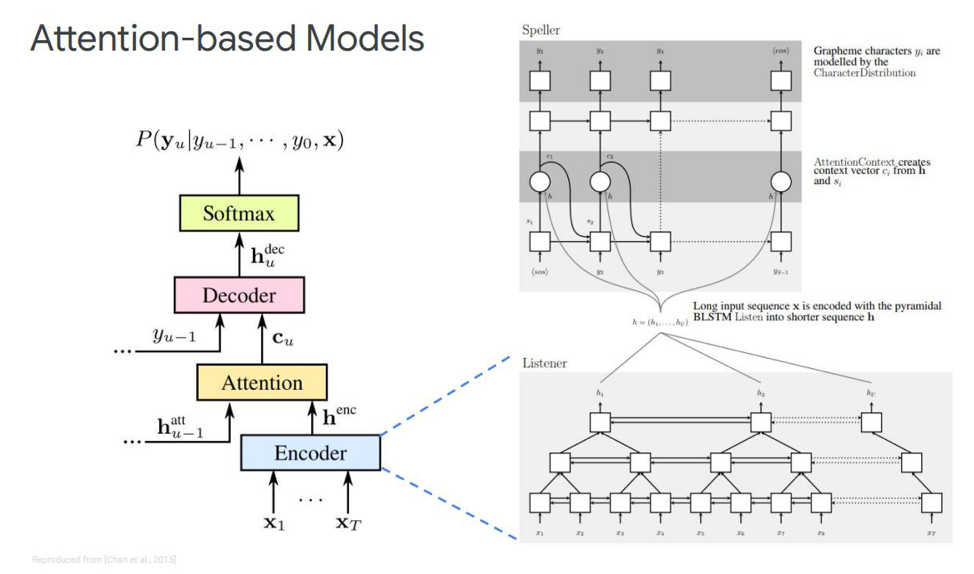
What are these blocks? The eco-encoder in the article is described as a listener, it is a classic bi-directional RNNs based on LSTMs or something else. In general, nothing new - the system simply simulates the input sequence into complex features.
Attention, on the other hand, creates a certain context vector C from these vectors, which will help decode the decoder correctly directly, the decoder itself, which is, for example, also some LSTMs that will be decoded into the input sequence from this attention layer, which has already highlighted the most important state signs, some output sequence of characters.
There are also different representations of this Attention itself - which is the difference between these two publications issued by Chen and Charowski. They use different Attention. Chen uses dot-product Attention, and Charovski uses Additive Attention.

This is a plus or minus all the major achievements received to date in matters of non-online speech recognition. What improvements are possible here? Where to go next? The most obvious is the use of a model on pieces of words instead of using graphemes directly. It can be some separate morphemes or something else.
What is the motivation for using word slices? Typically, language models of the word level have much less perplexity compared to the grapheme level. Modeling pieces of words allows you to build a stronger decoder of the language model. And modeling longer elements can improve memory efficiency in a decoder based on LSTMs. It also allows you to potentially remember the occurrence for frequency words. Longer elements allow decoding in fewer steps, which directly accelerates the inference of this model.
Also, the model on pieces of words allows us to solve the problem of OOV (out of vocabulary) words that arise in the language model, since we can model any word using pieces of words. And it is worth noting that such models are trained to maximize the likelihood of a language model over a training data set. These models are position-dependent, and we can use the greedy algorithm for decoding.
What other improvements could be other than a piece of word model? There is a mechanism called multi-head attention. It was first described in 2017 for machine translation. Multi-head attention implies a mechanism that has several so-called heads that allow you to generate a different distribution of this same attention, which improves the results directly.
We pass to the most interesting part - these are online models. It is important to note that LAS is not streaming. That is, this model cannot work in online decoding mode. We will consider the two most popular online models to date. RNN Transducer and Neural Transducer.
RNN Transducer was proposed by Graves in 2012-2017. The main idea is to complicate our STS model a bit with the help of a recursive model.
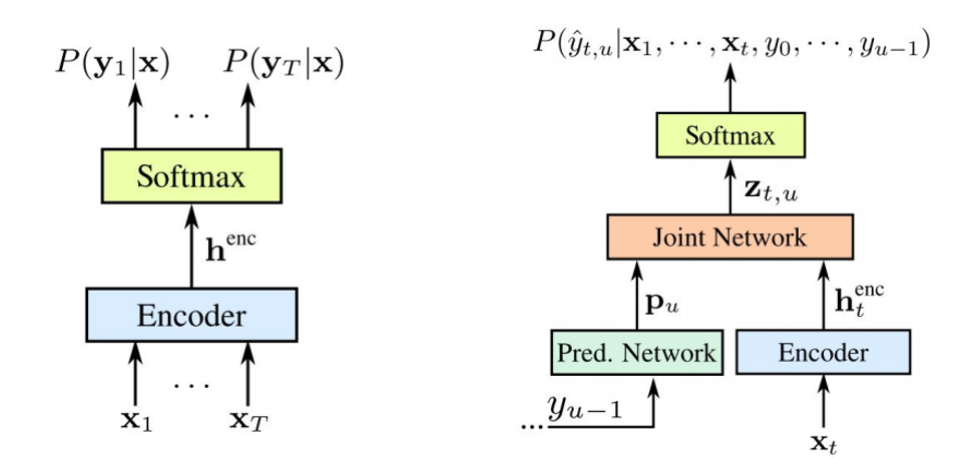
It is worth noting that both components are trained together on available acoustic data. Like STS, this approach does not require frame alignment in the training data set. As we see in the picture: on the left is our classic STS, and on the right is the RNN Transducer. And we have two new elements - the Predicted Network and Join Network .
The STS encoder is exactly the same - this is the input level RNN, which determines the distribution over all alignments with all output sequences not exceeding the length of the input sequence - this was described by Graves in 2006. However, the task of such text-to-speech conversions is also excluded, where the input sequence longer than the input sequence of the STS does not model the relationship between the outputs. Transducer expands this very STS, determining the distribution of the output sequences of all lengths and jointly modeling the dependence of the input-output and output-output.
It turns out that our model is ultimately able to handle the dependencies of the output from the input and the output from the output of the last step.
So what is a Predicted Network or a predictive network? She tries to simulate each element taking into account the previous ones, therefore, it is similar to the standard RNN with the forecasting of the next step. Only with the added ability to do null hypotheses.
As we see in the picture, we have a Predicted Network, which receives the previous value of the output, and there is an Encoder, which receives the current value of the input. And at the output we again, such has the current value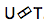 .
.
Neural Transducer . This is a complication of the classic seq-2seq approach. The input acoustic sequence is processed by the encoder to create hidden state vectors at each time step. It all seems to be as usual. But there is an additional Transducer element that receives a block of inputs at each step and generates up to M-output tokens using the model based on seq-2seq above this input. Transducer maintains its state in blocks by using periodic connections with previous time steps.
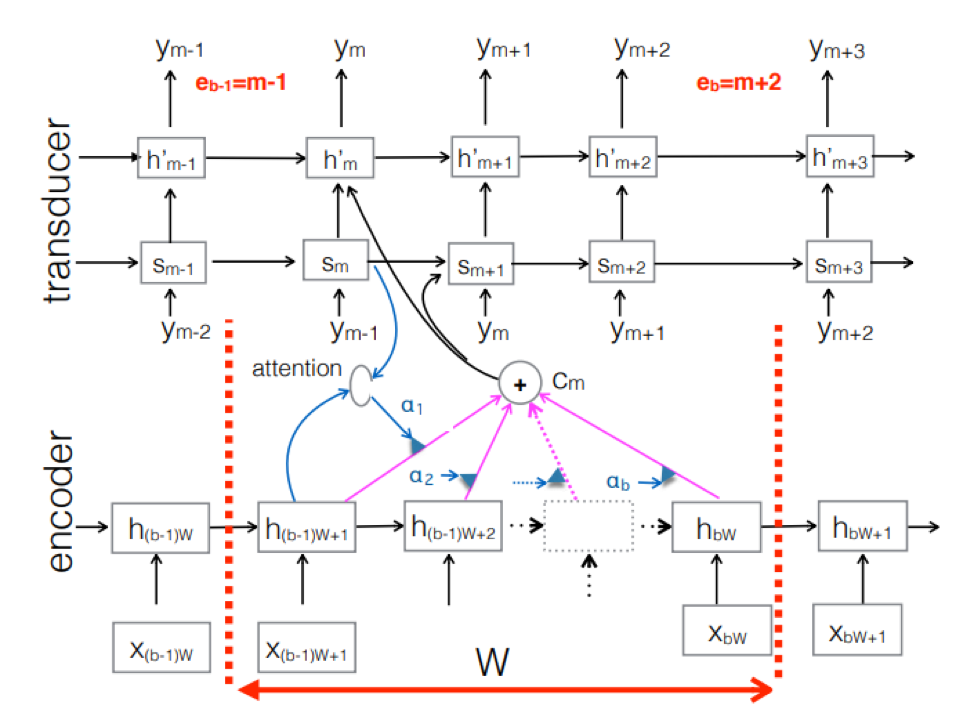
The figure shows the Transducer, producing tokens for the block for the sequence used in the block of the corresponding Ym.
So, we examined the current state of speech recognition based on the End2End approach. It is worth saying that, unfortunately, these approaches today require a large amount of data. And the real results that are achieved by the classical approach, requiring from 200 to 500 hours of sound recordings marked up for training a good model based on End2End, will require several, or maybe tens of times more data. Now this is the biggest problem with these approaches. But perhaps soon everything will change.
Leading developer of the AI MTS center Nikita Semenov.
The classic approach to speech recognition
Before talking about the End2End approach, you should first talk about the classic approach to speech recognition. What he really is?
Feature extraction
Actually, this is not a completely linear sequence of action-blocks. Let's dwell on each block in more detail. We have some kind of input speech, it falls on the first block - Feature Extraction. This is a block that pulls signs from speech. It must be borne in mind that speech itself is a rather complicated thing. You need to be able to work with it somehow, so there are standard methods for isolating features from signal processing theory. For example, Mel-cepstral coefficients (MFCC) and so on.
Acoustic model
The next component is the acoustic model. It can be either based on deep neural networks, or based on mixtures of Gaussian distributions and hidden Markov models. Its main goal is to obtain from one section of the acoustic signal the probability distribution of various phonemes in this section.
Next comes the decoder, which searches for the most likely path in the graph based on the result from the last step. Rescoring is the final touch in recognition, the main task of which is to re-weigh the hypotheses and produce the final result.
Let's dwell in more detail on the acoustic model. What is she like? We have some voice recordings that go into a certain system based on GMM (monaural gausovy mixture) or HMM. That is, we have representations in the form of phonemes, we use monophones, that is, context-independent phonemes. Further, we make mixtures of Gaussian distributions based on context-sensitive phonemes. It uses clustering based on decision trees.
Then we try to build alignment. Such a completely non-trivial method allows us to obtain an acoustic model. It doesn’t sound very simple, in fact it is even more complicated, there are many nuances, features. But as a result, a model trained on hundreds of hours is very well able to simulate acoustics.
Decoder
What is a decoder? This is the module that selects the most probable transition path according to the HCLG graph, which consists of 4 parts:
H module based on HMM
C context dependency module
L pronunciation module
G language model module
We build a graph on these four components, on the basis of which we will decode our acoustic features into some verbal constructions.
Plus or minus, it is clear that the classical approach is rather cumbersome and difficult, it is difficult to train, since it consists of a large number of separate parts, for each of which you need to prepare your own data for training.
II End2End approach
So what is End2End speech recognition and why is it needed? This is a certain system, which is designed to directly reflect the sequence of acoustic signs in the sequence of graphemes (letters) or words. You can also say that this is a system that optimizes criteria that directly affect the final metric of quality assessment. For example, our task is specifically the word error rate. As I said, there is only one motivation - to present these complex multi-stage components as one simple component that will directly display, output words or graphemes from input speech.
Simulation problem
We immediately have a problem here: sound speech is a sequence, and at the output we also need to give a sequence. And until 2006, there was no adequate way to model this. What is the problem of modeling? There was a need for each record to create complex markup, which implies at what second we pronounce a particular sound or letter. This is a very cumbersome complex layout, and therefore a large number of studies on this topic have not been conducted. In 2006, an interesting article by Alex Graves “Connectionist temporal classification” (CTC) was published, in which this problem is, in principle, solved. But the article came out, and at that time there was not enough computing power. And real working speech recognition algorithms appeared much later.
In total, we have: the CTC algorithm was proposed by Alex Graves thirteen years ago, as a tool that allows you to train / train acoustic models without the need for this complex markup - alignment of the input and output sequence frames. Based on this algorithm, work initially appeared that was not complete end2end; phonemes were issued as a result. It is worth noting that context-sensitive phonemes based on STS achieve some of the best results in the recognition of free speech. But it is also worth noting that this algorithm, applied directly to the words, remains somewhere behind at the moment.
What is STS
Now we will talk a little more in detail about what the STS is, and why it is needed, what function it performs. STS is necessary in order to train the acoustic model without the need for frame-by-frame alignment between sound and transcription. Frame-by-frame alignment is when we say that a particular frame from a sound corresponds to such a frame from transcription. We have a conventional encoder that accepts acoustic signs as an input - it gives out some kind of concealment of the state, on the basis of which we get conditional probabilities using softmax. Encoder usually consists of several layers of LSTMs or other variations of RNNs. It is worth noting that the STS operates in addition to ordinary characters with a special character called an empty character or a blank symbol. In order to solve the problem that arises due to the fact that not every acoustic frame has a frame in transcription and vice versa (that is, we have letters or sounds that sound much longer and there are short sounds, repeating sounds), and there this blank symbol.
The STS itself is intended to maximize the final probability of sequences of characters and to generalize possible alignment. Since we want to use this algorithm in neural networks, it is understood that we must understand how its forward and backward modes of operation work. We will not dwell on the mathematical justification and features of the operation of this algorithm, otherwise it will take a very long time.
What do we have: the first ASR based on the STS algorithm appears in 2014. Again, Alex Graves presented a publication based on the character-by-character STS that directly displays input speech in a sequence of words. One of the comments they made in this article is that using an external sound model is important to get a good result.
5 ways to improve the algorithm
There are many different variations and improvements to the above algorithm. Here are, for example, the five most popular recently.
• The language model is included in decoding during the first pass
o [Hannun et al., 2014] [Maas et al., 2015]: Direct first-pass decoding with an LM as opposed to rescoring as in [Graves & Jaitly, 2014]
o [Miao et al., 2015]: EESEN framework for decoding with WFSTs, open source toolkit
• Large-scale training on the GPU; Data Augmentation several languages
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: Large scale GPU training; Data Augmentation; Mandarin and English
• Use of long units: words instead of characters
o [Soltau et al., 2017]: Word-level CTC targets, trained on 125,000 hours of speech. Performance close to or better than a conventional system, even without using an LM!
o [Audhkhasi et al., 2017]: Direct Acoustics-to-Word Models on Switchboard
It is worth paying attention to the implementation of DeepSpeach as a good example of an end2end CTC solution and to a variation that uses a verbal level. But there is one caveat: for training such a model, you need 125 thousand hours of labeled data, which is actually quite a lot in harsh realities.
What is important to note about STS
- Issues or omissions. For efficiency, it is important to make assumptions about independence. That is, the STS assumes that the output of the network in different frames is conditionally independent, which is actually incorrect. But this assumption is made to simplify, without it, everything becomes much more complicated.
- To achieve good performance from the STS model, the use of an external language model is required, since direct greedy decoding does not work very well.
Attention
What alternative do we have for this STS? It is probably no secret to anyone that there is such a thing as Attention or “Attention”, which revolutionized to some extent and directly went from the tasks of machine translation. And now, most of all sequence-sequence modeling decisions are based on this mechanism. What is he like? Let's try to figure it out. For the first time about Attention in speech recognition tasks, publications appeared in 2015. Someone Chen and Cherowski released two similar and dissimilar publications at the same time.
Let us dwell on the first - it is called Listen, attend and spell. In our classic simulation, in the sequence where we have an encoder and decoder, another element is added, which is called attention. The ecoder will perform the functions that the acoustic model used to perform. Its task is to turn the input speech into high-level acoustic features. Our decoder will perform the tasks that we previously performed the language model and pronunciation model (lexicon), it will autoregressively predict each output token as a function of the previous ones. And attention itself will say directly which input frame is most relevant / important in order to predict this output.
What are these blocks? The eco-encoder in the article is described as a listener, it is a classic bi-directional RNNs based on LSTMs or something else. In general, nothing new - the system simply simulates the input sequence into complex features.
Attention, on the other hand, creates a certain context vector C from these vectors, which will help decode the decoder correctly directly, the decoder itself, which is, for example, also some LSTMs that will be decoded into the input sequence from this attention layer, which has already highlighted the most important state signs, some output sequence of characters.
There are also different representations of this Attention itself - which is the difference between these two publications issued by Chen and Charowski. They use different Attention. Chen uses dot-product Attention, and Charovski uses Additive Attention.
Where to go next?
This is a plus or minus all the major achievements received to date in matters of non-online speech recognition. What improvements are possible here? Where to go next? The most obvious is the use of a model on pieces of words instead of using graphemes directly. It can be some separate morphemes or something else.
What is the motivation for using word slices? Typically, language models of the word level have much less perplexity compared to the grapheme level. Modeling pieces of words allows you to build a stronger decoder of the language model. And modeling longer elements can improve memory efficiency in a decoder based on LSTMs. It also allows you to potentially remember the occurrence for frequency words. Longer elements allow decoding in fewer steps, which directly accelerates the inference of this model.
Also, the model on pieces of words allows us to solve the problem of OOV (out of vocabulary) words that arise in the language model, since we can model any word using pieces of words. And it is worth noting that such models are trained to maximize the likelihood of a language model over a training data set. These models are position-dependent, and we can use the greedy algorithm for decoding.
What other improvements could be other than a piece of word model? There is a mechanism called multi-head attention. It was first described in 2017 for machine translation. Multi-head attention implies a mechanism that has several so-called heads that allow you to generate a different distribution of this same attention, which improves the results directly.
Online models
We pass to the most interesting part - these are online models. It is important to note that LAS is not streaming. That is, this model cannot work in online decoding mode. We will consider the two most popular online models to date. RNN Transducer and Neural Transducer.
RNN Transducer was proposed by Graves in 2012-2017. The main idea is to complicate our STS model a bit with the help of a recursive model.
It is worth noting that both components are trained together on available acoustic data. Like STS, this approach does not require frame alignment in the training data set. As we see in the picture: on the left is our classic STS, and on the right is the RNN Transducer. And we have two new elements - the Predicted Network and Join Network .
The STS encoder is exactly the same - this is the input level RNN, which determines the distribution over all alignments with all output sequences not exceeding the length of the input sequence - this was described by Graves in 2006. However, the task of such text-to-speech conversions is also excluded, where the input sequence longer than the input sequence of the STS does not model the relationship between the outputs. Transducer expands this very STS, determining the distribution of the output sequences of all lengths and jointly modeling the dependence of the input-output and output-output.
It turns out that our model is ultimately able to handle the dependencies of the output from the input and the output from the output of the last step.
So what is a Predicted Network or a predictive network? She tries to simulate each element taking into account the previous ones, therefore, it is similar to the standard RNN with the forecasting of the next step. Only with the added ability to do null hypotheses.
As we see in the picture, we have a Predicted Network, which receives the previous value of the output, and there is an Encoder, which receives the current value of the input. And at the output we again, such has the current value
.
Neural Transducer . This is a complication of the classic seq-2seq approach. The input acoustic sequence is processed by the encoder to create hidden state vectors at each time step. It all seems to be as usual. But there is an additional Transducer element that receives a block of inputs at each step and generates up to M-output tokens using the model based on seq-2seq above this input. Transducer maintains its state in blocks by using periodic connections with previous time steps.
The figure shows the Transducer, producing tokens for the block for the sequence used in the block of the corresponding Ym.
So, we examined the current state of speech recognition based on the End2End approach. It is worth saying that, unfortunately, these approaches today require a large amount of data. And the real results that are achieved by the classical approach, requiring from 200 to 500 hours of sound recordings marked up for training a good model based on End2End, will require several, or maybe tens of times more data. Now this is the biggest problem with these approaches. But perhaps soon everything will change.
Leading developer of the AI MTS center Nikita Semenov.
All Articles