General-purpose artificial intelligence. TK, current status, prospects
Nowadays, the words “artificial intelligence” mean a lot of different systems - from a neural network for image recognition to a bot for playing Quake. Wikipedia gives a wonderful definition of AI - this is "the property of intelligent systems to perform creative functions that are traditionally considered the prerogative of man." That is, it is clearly seen from the definition - if a certain function was successfully automated, then it ceases to be considered artificial intelligence.
However, when the task of “creating artificial intelligence” was first set, AI meant something different. This goal is now called Strong AI or General Purpose AI.
Now there are two well-known formulations of the problem. The first is Strong AI. The second is a general-purpose AI (aka Artifical General Intelligence, abbreviated AGI).
Upd. In the comments, they tell me that this difference is more likely at the level of the language. In Russian, the word "intelligence" does not mean exactly what the word "intelligence" in English
A strong AI is a hypothetical AI that could do everything that a person could do. It is usually mentioned that he must pass the Turing test in the initial setting (hmm, do people pass it?), Be aware of himself as a separate person and be able to achieve his goals.
That is, it is something like an artificial person. In my opinion, the usefulness of such an AI is mainly research, because the definitions of a Strong AI do not say anywhere what its goals will be.
An AGI or general-purpose AI is a “result machine." It receives a certain goal setting at the input - and gives out some control actions on motors / lasers / network card / monitors. And the goal is achieved. At the same time, AGI initially does not have knowledge about the environment - only sensors, actuators and the channel through which it sets goals. A management system will be considered an AGI if it can achieve any goals in any environment. We put her to drive a car and avoid accidents - she will handle it. We put her in control of a nuclear reactor so that there is more energy, but does not explode - she can handle it. We will give a mailbox and instruct to sell vacuum cleaners - will also cope. AGI is a solver of “inverse problems”. To check how many vacuum cleaners are sold is a simple matter. But to figure out how to convince a person to buy this vacuum cleaner is already a task for the intellect.
In this article I will talk about AGI. No Turing tests, no self-awareness, no artificial personalities - exceptionally pragmatic AI and no less pragmatic operators.
Now there is such a class of systems as Reinforcement Learning, or reinforced learning. This is something like AGI, only without versatility. They are able to learn, and thereby achieve goals in a wide variety of environments. But still they are very far from achieving goals in any environment.
In general, how are Reinforcement Learning systems arranged and what are their problems?
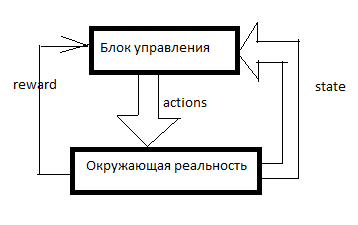
Any RL is arranged like this. There is a control system, some signals about the surrounding reality enter it through the sensors (state) and through the governing bodies (actions) it acts on the surrounding reality. Reward is a signal of reinforcement. In RL-systems, reinforcement is formed from outside the control unit and it indicates how well the AI copes with achieving the goal. How many vacuum cleaners sold in the last minute, for example.
Then a table is formed like this (I will call it the SAR table):

The axis of time is directed downward. The table shows everything that the AI did, everything that he saw and all the reinforcement signals. Usually, in order for RL to do something meaningful, he first needs to make random moves for a while, or look at the moves of someone else. In general, RL starts when there are already at least a few lines in the SAR table.
What happens next?
The simplest form of reinforcement learning.
We take some kind of machine learning model and, using a combination of S and A (state and action), we predict the total R for the next few ticks. For example, we will see that (based on the table above) if you tell a woman “be a man, buy a vacuum cleaner!”, Then the reward will be low, and if you say the same thing to a man, then high.
What specific models can be used - I will describe later, for now I will only say that this is not only neural networks. You can use decision trees or even define a function in a table form.
And then the following happens. AI receives another message or link to another client. All customer data is entered into the AI from the outside - we will consider the customer base and message counter as part of the sensor system. That is, it remains to assign some A (action) and wait for reinforcements. AI takes all possible actions and in turn predicts (using the same Machine Learning model) - what will happen if I do that? What if it is? And how much reinforcement will be for this? And then RL performs the action for which the maximum reward is expected.
I introduced such a simple and clumsy system into one of my games. SARSA hires units in the game, and adapts in the event of a change in the rules of the game.
In addition, in all types of reinforced training there is a discount of rewards and a explore / exploit dilemma.
Discounting rewards is such an approach when RL tries to maximize not the reward amount for the next N moves, but the weighted amount according to the principle "100 rubles is now better than 110 in a year." For example, if the discount factor is 0.9, and the planning horizon is 3, then we will train the model not on the total R for the next 3 clock cycles, but on R1 * 0.9 + R2 * 0.81 + R3 * 0.729. Why is this necessary? Then, that AI, creating a profit somewhere there at infinity, we do not need. We need an AI that generates profit around here and now.
Explore / exploit dilemma. If RL does what its model considers optimal, it will never know if there were any better strategies. Exploit is a strategy in which RL does what promises maximum rewards. Explore is a strategy in which RL does something to explore the environment in search of better strategies. How to implement effective intelligence? For example, you can do a random action every few measures. Or you can make not one predictive model, but several with slightly different settings. They will produce different results. The larger the difference, the greater the degree of uncertainty of this option. You can make the action be chosen so that it has the maximum value: M + k * std, where M is the average forecast of all models, std is the standard deviation of forecasts, and k is the coefficient of curiosity.
What are the disadvantages?
Let's say we have options. Go to the goal (which is 10 km from us, and the road to it is good) by car or go on foot. And then, after this choice, we have options - move carefully or try to crash into each pillar.
The person will immediately say that it is usually better to drive a car and behave carefully.
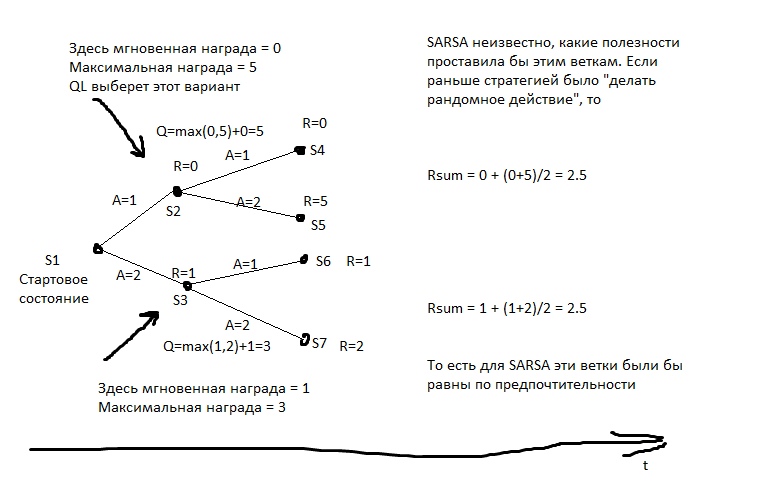
But SARSA ... He will look at what the decision to go by car led to before. And it led to this. At the stage of the initial set of statistics, the AI drove recklessly and crashed somewhere in half the cases. Yes, he can drive well. But when he chooses whether to go by car, he does not know what he will choose next move. He has statistics - then in half the cases he chose the appropriate option, and in half - suicidal. Therefore, on average, it is better to walk.
SARSA believes that the agent will adhere to the same strategy that was used to populate the table. And acts on this basis. But what if we assume otherwise - that the agent will adhere to the best strategy in the next moves?
This model calculates for each state the maximum achievable total reward from it. And he writes it in a special column Q. That is, if you can get 2 points or 1 from state S, depending on the move, then Q (S) will be equal to 2 (with a prediction depth of 1). What reward can be obtained from state S, we learn from the predictive model Y (S, A). (S - state, A - action).
Then we create a predictive model Q (S, A) - that is, what state Q will go to if we perform action A from S. And create the next column in the table - Q2. That is, the maximum Q that can be obtained from state S (we sort through all possible A).
Then we create a regression model Q3 (S, A) - that is, to the state with which Q2 we will go if we perform action A from S.
And so on. Thus, we can achieve an unlimited depth of forecasting.
In the picture, R is the reinforcement.
And then every move we choose the action that promises the greatest Qn. If we applied this algorithm to chess, we would get something like an ideal minimax. Something almost equivalent to miscalculating moves to great depths.
A common example of q-learning behavior. The hunter has a spear, and he goes with him to the bear, on his own initiative. He knows that the vast majority of his future moves have a very large negative reward (there are much more ways to lose than ways to win), he knows that there are moves with a positive reward. The hunter believes that in the future he will make the best moves (and it’s not known which ones like in SARSA), and if he makes the best moves, he will defeat the bear. That is, in order to go to the bear, it is enough for him to be able to do every element that is necessary for hunting, but it is not necessary to have experience of immediate success.
If the hunter acted in the SARSA style, he would assume that his actions in the future would be about the same as before (despite the fact that he now has a different baggage of knowledge), and he would only go to the bear if he already went to and he won, for example, in> 50% of cases (well, or if other hunters won in more than half of the cases, if he learns from their experience).
What are the disadvantages?
But what if we predict not only R or Q, but generally all sensory data? We will constantly have a pocket copy of reality and we will be able to check our plans on it. In this case, we are much less concerned about the difficulty of computing a Q-function. Yes, it requires a lot of clocks to calculate - well, so anyway, for each plan, we will repeatedly run the forecast model. Planning 10 moves forward? We launch the model 10 times, and each time we feed its outputs to its input.
What are the disadvantages?
If we have access to the test environment for AI, if we run it not in reality, but in a simulation, then we can write down in some form the strategy of our agent’s behavior. And then choose - with evolution or something else - such a strategy that leads to maximum profit.
“Choose a strategy” means that we first need to learn how to write down a strategy in such a way that it can be pushed into the evolution algorithm. That is, we can write down the strategy with program code, but in some places leave the coefficients, and let evolution pick them up. Or we can write down a strategy with a neural network - and let evolution pick up the weights of its connections.
That is, there is no forecast here. No SAR table. We simply select a strategy, and it immediately gives out Actions.
This is a powerful and effective method, if you want to try RL and do not know where to start, I recommend it. This is a very cheap way to “see a miracle”.
What are the disadvantages?
The same enumeration of strategies, but on living reality. We try 10 measures of one strategy. Then 10 measures another. Then 10 measures of the third. Then we select the one where there was more reinforcement.
The best results for walking humanoids were obtained by this method.

For me, this sounds somewhat unexpected - it would seem that the QL + Model-Based approach is mathematically ideal. But nothing like that. The advantages of the approach are about the same as the previous one - but they are less pronounced, since the strategies are not tested very long (well, we don’t have millennia on evolution), which means that the results are unstable. In addition, the number of tests, too, cannot be lifted to infinity - which means that the strategy will have to be sought in a not very complicated space of options. She will have few “pens” that can be “twisted”. Well, the experience intolerance has not been canceled. And, compared to QL or Model-Based, these models use experience inefficiently. They need a lot more interactions with reality than approaches that use machine learning.
As you can see, any attempts to create an AGI in theory should contain either machine learning for forecasting awards, or some form of parametric recording of a strategy - so that you can pick up this strategy with something like evolution.
This is a strong attack towards people who offer to create AI based on databases, logic, and conceptual graphs. If you, the proponents of the symbolic approach, read this - welcome to the comments, I will be glad to know what AGI can do without the mechanics described above.
Almost any ML model can be used for reinforced learning. Neural networks are, of course, good. But there is, for example, KNN. For each pair S and A, we look for the most similar ones, but in the past. And we are looking for what will be R. Stupid after that? Yes, but it works. There are decisive trees - here it is better to take a walk on the keywords "gradient boosting" and "decisive forest." Are trees poor at capturing complex dependencies? Use feature engeneering. Want your AI closer to General? Use automatic FE! Go through a bunch of different formulas, submit them as features for your boost, discard the formulas that increase the error, and leave the formulas that improve accuracy. Then submit the best formulas as arguments for the new formulas, and so on, evolve.
You can use symbolic regressions for forecasting - that is, simply sorting out formulas in an attempt to get something that approximates Q or R. It is possible to try sorting out algorithms - then you get a thing called Solomonov’s induction, which is theoretically optimal, but almost very difficult to train approximations of functions.
But neural networks are usually a compromise between expressiveness and complexity of learning. Algorithmic regression ideally picks up any dependence - for hundreds of years. The decision tree will work out very quickly - but already y = a + b will not be able to extrapolate. A neural network is something in between.
What are the ways to do exactly AGI now? At least theoretically.
We can create many different test environments and start the evolution of some neural network. Those configurations that score more points in total for all trials will multiply.
The neural network must have memory and it would be desirable to have at least part of the memory in the form of a tape, like a Turing machine or like on a hard disk.
The problem is that with the help of evolution, you can grow something like RL, of course. But what should the language look like in which RL looks compact - so that evolution finds it - and at the same time that evolution doesn’t find solutions like “but I’ll create a neuron for a hundred and fifty layers so that you all get nuts while I teach it!” . Evolution is like a crowd of illiterate users - it will find any flaws in the code and ditch the entire system.
You can make a Model-Based system based on a pack of many algorithmic regressions. The algorithm is guaranteed to be Turing complete - which means there will be no patterns that cannot be picked up. The algorithm is written in code - which means that its complexity can be easily calculated. So, it is possible to mathematically correctly fine your hypotheses of the world’s device for complexity. With neural networks, for example, this trick will not work - there the penalty for complexity is very indirect and heuristic.
It remains only to learn how to quickly train algorithmic regressions. So far, the best there is for this is evolution, and it is unforgivably long.
It would be cool to create an AI that will improve itself. Improve your ability to solve problems. This may seem like a strange idea, but this problem has already been solved for systems of static optimization, such as evolution . If you manage to realize this ... Is everything about the exhibitor in the know? We will get a very powerful AI in a very short time.
How to do it?
You can try to arrange that in RL some of the actions affect the settings of RL itself.
Or give the RL system some tool to create new pre- and post-data processors for yourself. Let RL be dumb, but it will be able to create calculators, notebooks and computers.
Another option is to create some kind of AI using evolution, in which part of the actions will affect its device at the code level.
But at the moment I have not seen workable options for Seed AI - albeit very limited. Are the developers hiding? Or are these options so weak that they did not deserve general attention and passed me by?
However, now both Google and DeepMind work mainly with neural network architectures. Apparently, they do not want to get involved in combinatorial enumeration and try to make any of their ideas suitable for the method of back propagating the error.
I hope this review article was helpful =) Comments are welcome, especially comments like “I know how to make AGI better”!
However, when the task of “creating artificial intelligence” was first set, AI meant something different. This goal is now called Strong AI or General Purpose AI.
Formulation of the problem
Now there are two well-known formulations of the problem. The first is Strong AI. The second is a general-purpose AI (aka Artifical General Intelligence, abbreviated AGI).
Upd. In the comments, they tell me that this difference is more likely at the level of the language. In Russian, the word "intelligence" does not mean exactly what the word "intelligence" in English
A strong AI is a hypothetical AI that could do everything that a person could do. It is usually mentioned that he must pass the Turing test in the initial setting (hmm, do people pass it?), Be aware of himself as a separate person and be able to achieve his goals.
That is, it is something like an artificial person. In my opinion, the usefulness of such an AI is mainly research, because the definitions of a Strong AI do not say anywhere what its goals will be.
An AGI or general-purpose AI is a “result machine." It receives a certain goal setting at the input - and gives out some control actions on motors / lasers / network card / monitors. And the goal is achieved. At the same time, AGI initially does not have knowledge about the environment - only sensors, actuators and the channel through which it sets goals. A management system will be considered an AGI if it can achieve any goals in any environment. We put her to drive a car and avoid accidents - she will handle it. We put her in control of a nuclear reactor so that there is more energy, but does not explode - she can handle it. We will give a mailbox and instruct to sell vacuum cleaners - will also cope. AGI is a solver of “inverse problems”. To check how many vacuum cleaners are sold is a simple matter. But to figure out how to convince a person to buy this vacuum cleaner is already a task for the intellect.
In this article I will talk about AGI. No Turing tests, no self-awareness, no artificial personalities - exceptionally pragmatic AI and no less pragmatic operators.
Current state of affairs
Now there is such a class of systems as Reinforcement Learning, or reinforced learning. This is something like AGI, only without versatility. They are able to learn, and thereby achieve goals in a wide variety of environments. But still they are very far from achieving goals in any environment.
In general, how are Reinforcement Learning systems arranged and what are their problems?
Any RL is arranged like this. There is a control system, some signals about the surrounding reality enter it through the sensors (state) and through the governing bodies (actions) it acts on the surrounding reality. Reward is a signal of reinforcement. In RL-systems, reinforcement is formed from outside the control unit and it indicates how well the AI copes with achieving the goal. How many vacuum cleaners sold in the last minute, for example.
Then a table is formed like this (I will call it the SAR table):
The axis of time is directed downward. The table shows everything that the AI did, everything that he saw and all the reinforcement signals. Usually, in order for RL to do something meaningful, he first needs to make random moves for a while, or look at the moves of someone else. In general, RL starts when there are already at least a few lines in the SAR table.
What happens next?
Sarsa
The simplest form of reinforcement learning.
We take some kind of machine learning model and, using a combination of S and A (state and action), we predict the total R for the next few ticks. For example, we will see that (based on the table above) if you tell a woman “be a man, buy a vacuum cleaner!”, Then the reward will be low, and if you say the same thing to a man, then high.
What specific models can be used - I will describe later, for now I will only say that this is not only neural networks. You can use decision trees or even define a function in a table form.
And then the following happens. AI receives another message or link to another client. All customer data is entered into the AI from the outside - we will consider the customer base and message counter as part of the sensor system. That is, it remains to assign some A (action) and wait for reinforcements. AI takes all possible actions and in turn predicts (using the same Machine Learning model) - what will happen if I do that? What if it is? And how much reinforcement will be for this? And then RL performs the action for which the maximum reward is expected.
I introduced such a simple and clumsy system into one of my games. SARSA hires units in the game, and adapts in the event of a change in the rules of the game.
In addition, in all types of reinforced training there is a discount of rewards and a explore / exploit dilemma.
Discounting rewards is such an approach when RL tries to maximize not the reward amount for the next N moves, but the weighted amount according to the principle "100 rubles is now better than 110 in a year." For example, if the discount factor is 0.9, and the planning horizon is 3, then we will train the model not on the total R for the next 3 clock cycles, but on R1 * 0.9 + R2 * 0.81 + R3 * 0.729. Why is this necessary? Then, that AI, creating a profit somewhere there at infinity, we do not need. We need an AI that generates profit around here and now.
Explore / exploit dilemma. If RL does what its model considers optimal, it will never know if there were any better strategies. Exploit is a strategy in which RL does what promises maximum rewards. Explore is a strategy in which RL does something to explore the environment in search of better strategies. How to implement effective intelligence? For example, you can do a random action every few measures. Or you can make not one predictive model, but several with slightly different settings. They will produce different results. The larger the difference, the greater the degree of uncertainty of this option. You can make the action be chosen so that it has the maximum value: M + k * std, where M is the average forecast of all models, std is the standard deviation of forecasts, and k is the coefficient of curiosity.
What are the disadvantages?
Let's say we have options. Go to the goal (which is 10 km from us, and the road to it is good) by car or go on foot. And then, after this choice, we have options - move carefully or try to crash into each pillar.
The person will immediately say that it is usually better to drive a car and behave carefully.
But SARSA ... He will look at what the decision to go by car led to before. And it led to this. At the stage of the initial set of statistics, the AI drove recklessly and crashed somewhere in half the cases. Yes, he can drive well. But when he chooses whether to go by car, he does not know what he will choose next move. He has statistics - then in half the cases he chose the appropriate option, and in half - suicidal. Therefore, on average, it is better to walk.
SARSA believes that the agent will adhere to the same strategy that was used to populate the table. And acts on this basis. But what if we assume otherwise - that the agent will adhere to the best strategy in the next moves?
Q-learning
This model calculates for each state the maximum achievable total reward from it. And he writes it in a special column Q. That is, if you can get 2 points or 1 from state S, depending on the move, then Q (S) will be equal to 2 (with a prediction depth of 1). What reward can be obtained from state S, we learn from the predictive model Y (S, A). (S - state, A - action).
Then we create a predictive model Q (S, A) - that is, what state Q will go to if we perform action A from S. And create the next column in the table - Q2. That is, the maximum Q that can be obtained from state S (we sort through all possible A).
Then we create a regression model Q3 (S, A) - that is, to the state with which Q2 we will go if we perform action A from S.
And so on. Thus, we can achieve an unlimited depth of forecasting.
In the picture, R is the reinforcement.
And then every move we choose the action that promises the greatest Qn. If we applied this algorithm to chess, we would get something like an ideal minimax. Something almost equivalent to miscalculating moves to great depths.
A common example of q-learning behavior. The hunter has a spear, and he goes with him to the bear, on his own initiative. He knows that the vast majority of his future moves have a very large negative reward (there are much more ways to lose than ways to win), he knows that there are moves with a positive reward. The hunter believes that in the future he will make the best moves (and it’s not known which ones like in SARSA), and if he makes the best moves, he will defeat the bear. That is, in order to go to the bear, it is enough for him to be able to do every element that is necessary for hunting, but it is not necessary to have experience of immediate success.
If the hunter acted in the SARSA style, he would assume that his actions in the future would be about the same as before (despite the fact that he now has a different baggage of knowledge), and he would only go to the bear if he already went to and he won, for example, in> 50% of cases (well, or if other hunters won in more than half of the cases, if he learns from their experience).
What are the disadvantages?
- The model does not cope with the changing reality. If our whole life we have been awarded for pressing the red button, and now they are punishing us, and no visible changes have occurred ... QL will master this pattern for a very long time.
- Qn can be a very complex function. For example, to calculate it, you need to scroll a cycle of N iterations - and it won’t work out faster. A predictive model usually has limited complexity - even a large neural network has a complexity limit, and almost no machine learning model can rotate cycles.
- Reality usually has hidden variables. For example, what time is it now? It is easy to find out if we look at the watch, but as soon as we look away, this is already a hidden variable. To take into account these unobservable values, it is necessary that the model takes into account not only the current state, but also some kind of history. In QL, you can do this - for example, feed not only the current S, but also several previous ones into the neuron-or-what-us-there. This is done in RL, which plays Atari games. In addition, you can use a recurrent neural network for forecasting - let it run sequentially over several frames of history and calculate Qn.
Model-based systems
But what if we predict not only R or Q, but generally all sensory data? We will constantly have a pocket copy of reality and we will be able to check our plans on it. In this case, we are much less concerned about the difficulty of computing a Q-function. Yes, it requires a lot of clocks to calculate - well, so anyway, for each plan, we will repeatedly run the forecast model. Planning 10 moves forward? We launch the model 10 times, and each time we feed its outputs to its input.
What are the disadvantages?
- Resource intensity. Suppose we need to make a choice of two alternatives at each measure. Then for 10 measures we will have 2 ^ 10 = 1024 possible plans. Each plan is 10 model launches. If we fly a plane with dozens of governing bodies? And do we simulate reality with a period of 0.1 seconds? Do you want to have a planning horizon for at least a couple of minutes? We will have to run the model many times, there are a lot of processor clock cycles for one solution. Even if you somehow optimize the enumeration of plans, all the same, there are orders of magnitude more calculations than in QL.
- The problem of chaos. Some systems are designed so that even a small inaccuracy of the input simulation leads to a huge output error. To counter this, you can run several simulations of reality - a little different. They will produce very different results, and from this it will be possible to understand that we are in the zone of such instability.
Strategy Enumeration Method
If we have access to the test environment for AI, if we run it not in reality, but in a simulation, then we can write down in some form the strategy of our agent’s behavior. And then choose - with evolution or something else - such a strategy that leads to maximum profit.
“Choose a strategy” means that we first need to learn how to write down a strategy in such a way that it can be pushed into the evolution algorithm. That is, we can write down the strategy with program code, but in some places leave the coefficients, and let evolution pick them up. Or we can write down a strategy with a neural network - and let evolution pick up the weights of its connections.
That is, there is no forecast here. No SAR table. We simply select a strategy, and it immediately gives out Actions.
This is a powerful and effective method, if you want to try RL and do not know where to start, I recommend it. This is a very cheap way to “see a miracle”.
What are the disadvantages?
- The ability to run the same experiments many times is required. That is, we should be able to rewind reality to the starting point - tens of thousands of times. To try a new strategy.
Life rarely provides such opportunities. Usually, if we have a model of the process we are interested in, we can not create a cunning strategy - we can just make a plan, as in a model-based approach, even with a dumb search. - Intolerance to experience. Do we have a SAR chart for years of experience? We can forget about it, it does not fit into the concept.
A method of enumerating strategies, but “live”
The same enumeration of strategies, but on living reality. We try 10 measures of one strategy. Then 10 measures another. Then 10 measures of the third. Then we select the one where there was more reinforcement.
The best results for walking humanoids were obtained by this method.
For me, this sounds somewhat unexpected - it would seem that the QL + Model-Based approach is mathematically ideal. But nothing like that. The advantages of the approach are about the same as the previous one - but they are less pronounced, since the strategies are not tested very long (well, we don’t have millennia on evolution), which means that the results are unstable. In addition, the number of tests, too, cannot be lifted to infinity - which means that the strategy will have to be sought in a not very complicated space of options. She will have few “pens” that can be “twisted”. Well, the experience intolerance has not been canceled. And, compared to QL or Model-Based, these models use experience inefficiently. They need a lot more interactions with reality than approaches that use machine learning.
As you can see, any attempts to create an AGI in theory should contain either machine learning for forecasting awards, or some form of parametric recording of a strategy - so that you can pick up this strategy with something like evolution.
This is a strong attack towards people who offer to create AI based on databases, logic, and conceptual graphs. If you, the proponents of the symbolic approach, read this - welcome to the comments, I will be glad to know what AGI can do without the mechanics described above.
Machine Learning Models for RL
Almost any ML model can be used for reinforced learning. Neural networks are, of course, good. But there is, for example, KNN. For each pair S and A, we look for the most similar ones, but in the past. And we are looking for what will be R. Stupid after that? Yes, but it works. There are decisive trees - here it is better to take a walk on the keywords "gradient boosting" and "decisive forest." Are trees poor at capturing complex dependencies? Use feature engeneering. Want your AI closer to General? Use automatic FE! Go through a bunch of different formulas, submit them as features for your boost, discard the formulas that increase the error, and leave the formulas that improve accuracy. Then submit the best formulas as arguments for the new formulas, and so on, evolve.
You can use symbolic regressions for forecasting - that is, simply sorting out formulas in an attempt to get something that approximates Q or R. It is possible to try sorting out algorithms - then you get a thing called Solomonov’s induction, which is theoretically optimal, but almost very difficult to train approximations of functions.
But neural networks are usually a compromise between expressiveness and complexity of learning. Algorithmic regression ideally picks up any dependence - for hundreds of years. The decision tree will work out very quickly - but already y = a + b will not be able to extrapolate. A neural network is something in between.
Development prospects
What are the ways to do exactly AGI now? At least theoretically.
Evolution
We can create many different test environments and start the evolution of some neural network. Those configurations that score more points in total for all trials will multiply.
The neural network must have memory and it would be desirable to have at least part of the memory in the form of a tape, like a Turing machine or like on a hard disk.
The problem is that with the help of evolution, you can grow something like RL, of course. But what should the language look like in which RL looks compact - so that evolution finds it - and at the same time that evolution doesn’t find solutions like “but I’ll create a neuron for a hundred and fifty layers so that you all get nuts while I teach it!” . Evolution is like a crowd of illiterate users - it will find any flaws in the code and ditch the entire system.
Aixi
You can make a Model-Based system based on a pack of many algorithmic regressions. The algorithm is guaranteed to be Turing complete - which means there will be no patterns that cannot be picked up. The algorithm is written in code - which means that its complexity can be easily calculated. So, it is possible to mathematically correctly fine your hypotheses of the world’s device for complexity. With neural networks, for example, this trick will not work - there the penalty for complexity is very indirect and heuristic.
It remains only to learn how to quickly train algorithmic regressions. So far, the best there is for this is evolution, and it is unforgivably long.
Seed AI
It would be cool to create an AI that will improve itself. Improve your ability to solve problems. This may seem like a strange idea, but this problem has already been solved for systems of static optimization, such as evolution . If you manage to realize this ... Is everything about the exhibitor in the know? We will get a very powerful AI in a very short time.
How to do it?
You can try to arrange that in RL some of the actions affect the settings of RL itself.
Or give the RL system some tool to create new pre- and post-data processors for yourself. Let RL be dumb, but it will be able to create calculators, notebooks and computers.
Another option is to create some kind of AI using evolution, in which part of the actions will affect its device at the code level.
But at the moment I have not seen workable options for Seed AI - albeit very limited. Are the developers hiding? Or are these options so weak that they did not deserve general attention and passed me by?
However, now both Google and DeepMind work mainly with neural network architectures. Apparently, they do not want to get involved in combinatorial enumeration and try to make any of their ideas suitable for the method of back propagating the error.
I hope this review article was helpful =) Comments are welcome, especially comments like “I know how to make AGI better”!
All Articles